



📢 转载信息
原文链接:https://aws.amazon.com/blogs/machine-learning/generate-gremlin-queries-using-amazon-bedrock-models/
原文作者:Rachel Hanspal, Flora Wang, Jason Zhang, Mu Li, Wan Chen, Suparna Pal, and Zubair Nabi
图数据库已彻底改变了组织管理复杂、互联数据的方式。然而,像 Gremlin 这样的专用查询语言常常成为团队高效提取洞察力的障碍。与具有明确定义的模式(schema)的传统关系数据库不同,图数据库缺乏集中的模式,这需要深厚的技术专长才能有效查询。
为了解决这一挑战,我们探索了一种利用 Amazon Bedrock 模型(如 Amazon Nova Pro)将自然语言转换为 Gremlin 查询的方法。这种方法有助于业务分析师、数据科学家和其他非技术用户无缝访问和交互图数据库。
在本文中,我们概述了从自然语言生成 Gremlin 查询的方法论,比较了不同的技术,并演示了如何使用大型语言模型 (LLM) 作为裁判来评估这些生成查询的有效性。
解决方案概述
将自然语言查询转换为 Gremlin 查询需要深入了解图结构以及图数据库中封装的领域特定知识。为实现这一目标,我们将方法分为三个关键步骤:
- 理解和提取图知识
- 像处理文本到 SQL 那样构建图结构
- 生成和执行 Gremlin 查询
下图说明了此工作流程。
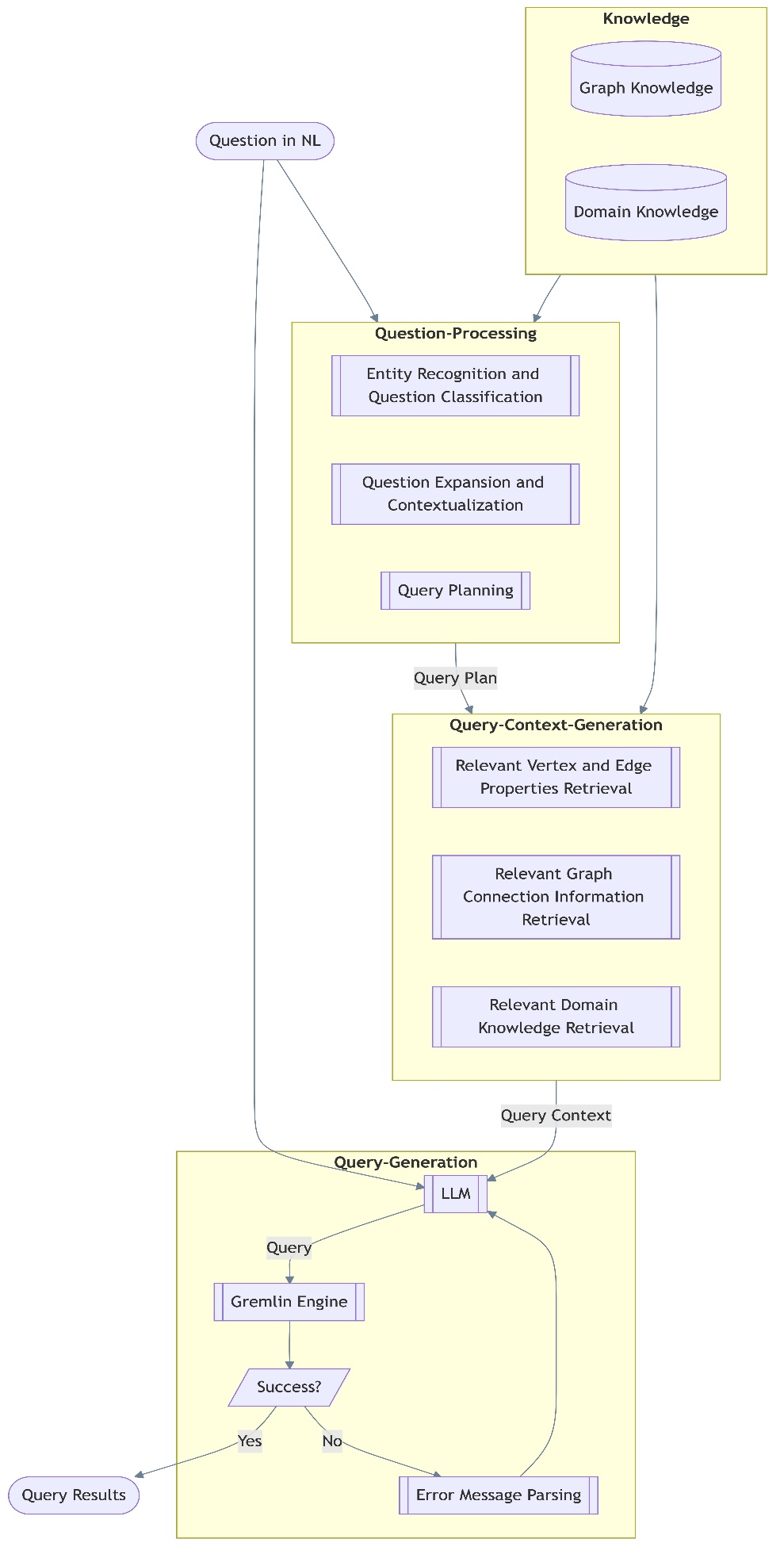
步骤 1:提取图知识
一个成功的查询生成框架必须整合图知识和领域知识,才能准确地翻译自然语言查询。图知识包含直接从图数据库中提取的结构和语义信息。具体来说,它包括:
- 顶点标签和属性 – 顶点类型、名称及其相关属性的列表
- 边标签和属性 – 关于边类型及其属性的信息
- 每个顶点的单跳邻居 – 捕获局部连接信息,例如顶点之间的直接关系
有了这些特定于图的知识,该框架就能有效地推断图数据库中固有的异构属性和复杂连接。
领域知识捕获了增强图知识并专门针对应用程序领域的附加上下文。它通过两种方式获得:
- 客户提供的领域知识 – 例如,客户 kscope.ai 帮助指定了代表元数据且绝不应被查询的顶点。将此类约束编码以指导查询生成过程。
- LLM 生成的描述 – 为了增强系统对顶点名称及其与特定问题的相关性的理解,我们使用 LLM 为顶点名称、属性和边生成详细的语义描述。这些描述存储在领域知识库中,并提供额外上下文以提高生成查询的相关性。
步骤 2:将图结构化为文本到 SQL 模式
为了提高模型对图结构的理解能力,我们采用了类似于 text-to-SQL 处理的方法,在此方法中,我们构建一个代表顶点类型、边和属性的模式。这种结构化表示增强了模型解释和生成有意义查询的能力。
问题处理组件将自然语言输入转换为查询生成的结构化元素。它分三个阶段运行:
- 实体识别和分类 – 识别输入问题中的关键数据库元素(如顶点、边和属性),并根据其意图对问题进行分类
- 上下文增强 – 使用来自知识组件的相关信息丰富问题,以便正确捕获特定于图和特定于领域的上下文
- 查询规划 – 将增强后的问题映射到查询执行所需的特定数据库元素
上下文生成组件通过组装以下内容,确保生成的查询准确反映底层图结构:
- 元素属性 – 检索顶点和边的属性及其数据类型
- 图结构 – 有助于与数据库拓扑结构保持一致
- 领域规则 – 应用业务约束和逻辑
步骤 3:生成和执行 Gremlin 查询
最后一步是查询生成,LLM 根据提取的上下文构建 Gremlin 查询。该过程遵循以下步骤:
- LLM 生成初始 Gremlin 查询。
- 查询在 Gremlin 引擎中执行。
- 如果执行成功,则返回结果。
- 如果执行失败,错误消息解析机制会分析返回的错误,并使用基于 LLM 的反馈来精炼查询。
这种迭代精炼确保了生成的查询与数据库的结构和约束保持一致,从而提高了整体准确性和可用性。
提示模板
我们的最终提示模板如下:
## Request
Please write a gremlin query to answer the given question:
{{question}}
You will be provided with couple relevant vertices, together with their schema and other information.
Please choose the most relevant vertex according to its schema and other information to make the gremlin query correct. ## Instructions
1. Here are related vertices and their details:
{{schema}}
2. Don't rename properties.
3. Don't change lines (using slash n) in the generated query. ## IMPORTANT
Return the results in the following XML format: <Results> <Query>INSERT YOUR QUERY HERE</Query> <Explanation> PROVIDE YOUR EXPLANATION ON HOW THIS QUERY WAS GENERATED AND HOW THE PROVIDED SCHEMA WAS LEVERAGED </Explanation>
</Results>将 LLM 生成的查询与基准进行比较
我们使用 Amazon Bedrock 上的 Anthropic 的 Claude 3.5 Sonnet 实现了基于 LLM 的评估系统,作为裁判来评估 Amazon Nova Pro 和基准模型的查询生成和执行结果。该系统在两个关键领域运行:
- 查询评估 – 评估正确性、效率和与基准查询的相似性;计算精确匹配组件百分比;并根据与领域专家一起制定的预定义规则提供总体评级。
- 执行评估 – 最初使用单阶段方法将生成的结果与基准进行比较,然后增强为两阶段评估过程:
- 逐项与基准进行验证
- 计算总体匹配百分比
对 120 个问题的测试证明了该框架能够有效区分正确和不正确的查询。两阶段方法通过在评分前进行彻底比较,特别提高了执行结果评估的可靠性。
实验和结果
在本节中,我们将讨论我们进行的实验及其结果。
查询相似度
在查询评估案例中,我们提出了两个指标:查询精确匹配和查询总体评级。通过识别生成查询和基准查询之间匹配和不匹配的组件来计算精确匹配分数。下表总结了查询精确匹配的分数。
| 简单 | 中等 | 困难 | 总体 | |
| Amazon Nova Pro | 82.70% | 61% | 46.60% | 70.36% |
| 基准模型 | 92.60% | 68.70% | 56.20% | 78.93% |
在考虑查询正确性、效率和完整性等因素后,根据提示中的指示,提供总体评级。总体评级范围为 1-10。下表总结了查询总体评级分数。
| 简单 | 中等 | 困难 | 总体 | |
| Amazon Nova Pro | 8.7 | 7 | 5.3 | 7.6 |
| 基准模型 | 9.7 | 8 | 6.1 | 8.5 |
当前查询评估设置的一个局限性在于,我们完全依赖 LLM 的能力来将基准与 LLM 生成的查询进行比较并得出最终分数。因此,LLM 可能会未能与人类偏好保持一致,从而对生成的查询进行惩罚过低或过高。为解决此问题,我们建议与主题领域专家合作,将特定领域的规则纳入评估提示中。
执行准确性
为了计算准确性,我们将 LLM 生成的 Gremlin 查询的结果与基准查询的结果进行比较。如果两个查询的结果完全匹配,我们则将该实例计为正确;否则,则视为不正确。然后将准确性计算为正确查询执行次数与测试查询总数的比率。此指标提供了一种直接评估模型生成的查询从图数据库中检索预期信息的程度的方法,有助于与预期查询逻辑保持一致。
下表总结了执行结果计数匹配的分数。
| 简单 | 中等 | 困难 | 总体 | |
| Amazon Nova Pro | 80% | 50% | 10% | 60.42% |
| 基准模型 | 90% | 70% | 30% | 74.83% |
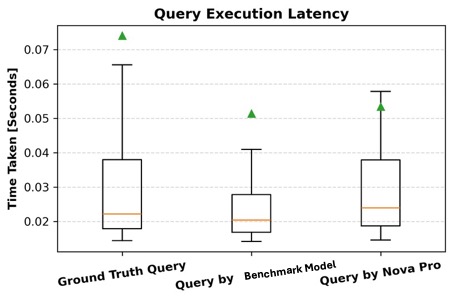
查询执行延迟
除了准确性,我们还通过测量生成查询的运行时并将其与基准查询进行比较来评估其效率。对于每个查询,我们记录毫秒级的运行时,并分析生成查询与相应基准查询之间的差异。运行时越短表示查询越优化,而显著偏差可能表明查询结构或执行规划存在效率低下。通过同时考虑准确性和运行时,我们对查询质量获得了更全面的评估,确保生成的查询在图数据库中是正确且高性能的。下图展示了相对于基准查询和 Amazon Nova Pro 生成的查询的查询执行延迟情况。如图所示,所有三种类型的查询都表现出可比的运行时,具有相似的中值延迟和重叠的四分位距。尽管基准查询的范围略宽,异常值较高,但所有三组的中值保持接近。这表明模型生成的查询在执行效率方面与人工编写的查询处于同一水平,支持了 AI 生成的查询质量相似且不会产生额外延迟开销的主张。
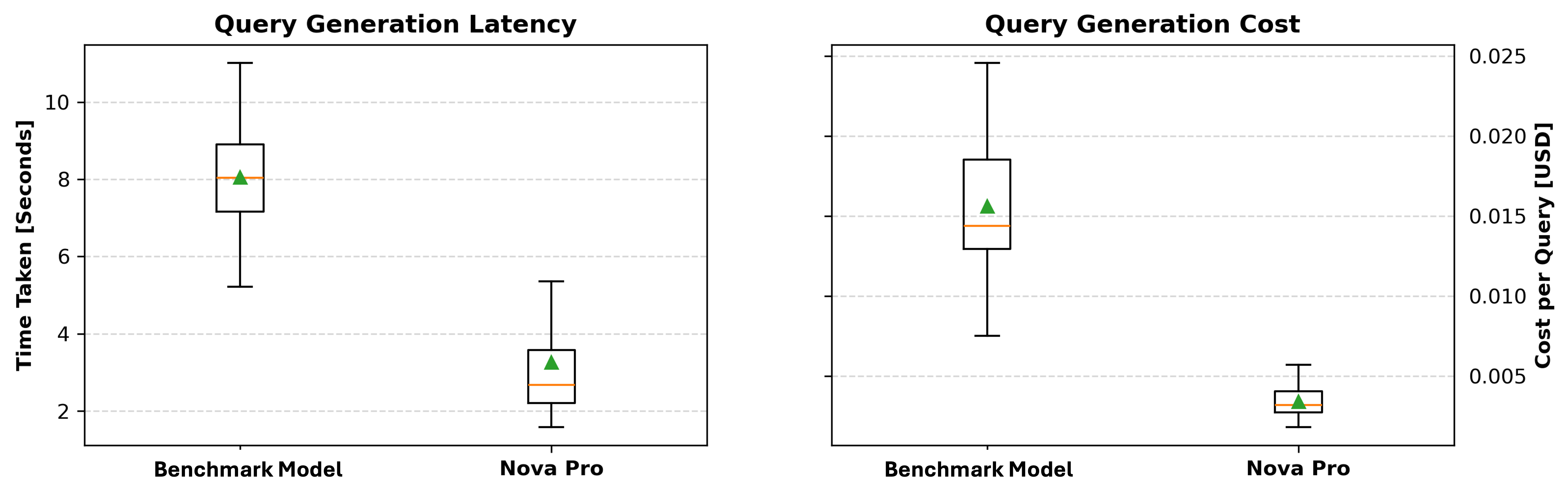
查询生成延迟和成本
最后,我们比较了生成每个查询所需的时间,并根据令牌消耗计算成本。更具体地说,我们测量查询生成时间并跟踪使用的令牌数量,因为大多数基于 LLM 的 API 按令牌使用收费。通过分析生成速度和令牌成本,我们可以确定模型在效率和成本效益方面是否理想。这些结果为选择在查询准确性、执行效率和经济可行性之间取得平衡的最佳模型提供了见解。
如下方图表所示,Amazon Nova Pro 在生成延迟和成本方面始终优于基准模型。在左侧的查询生成延迟图中,Amazon Nova Pro 表现出明显更低的中值生成时间,大多数值集中在 1.8–4 秒之间,而基准模型的范围更广,约为 5–11 秒。右侧的查询生成成本图显示,Amazon Nova Pro 保持着远低于 0.005 美元的单次查询成本——而基准模型的成本更高且波动更大,在某些情况下高达 0.025 美元。这些结果凸显了 Amazon Nova Pro 在速度和可负担性方面的优势,使其成为时间敏感型或大规模部署的有力候选者。
结论
我们对 kscope.ai 提供的所有 120 个基准查询进行了实验,在生成正确结果方面实现了 74.17% 的总体准确率。所提出的框架通过有效应对图查询生成的独特挑战,展示了其潜力,这些挑战包括处理异构的顶点和边属性、对复杂图结构进行推理以及整合领域知识。框架的关键组成部分,如图知识和领域知识的集成、使用检索增强生成 (RAG) 进行查询计划创建,以及用于查询精炼的迭代错误处理机制,对于实现这一性能至关重要。
除了提高准确性外,我们还在积极进行几项改进工作。这些包括完善评估方法以更有效地处理深度嵌套的查询结果,以及进一步优化 LLM 在查询生成中的使用。此外,我们正在使用 RAGAS-faithfulness 指标来改进查询结果的自动化评估,从而提高评估框架输出的可靠性和一致性。
关于作者
 Mengdie (Flora) Wang 是 AWS 生成式 AI 创新中心的数据科学家,她与客户合作设计和实施可扩展的生成式 AI 解决方案,以应对他们独特的业务挑战。她专注于模型定制技术和基于代理的 AI 系统,帮助组织充分利用生成式 AI 技术的潜力。在加入 AWS 之前,Flora 获得了明尼苏达大学计算机科学硕士学位,在那里她培养了在机器学习和人工智能方面的专业知识。
Mengdie (Flora) Wang 是 AWS 生成式 AI 创新中心的数据科学家,她与客户合作设计和实施可扩展的生成式 AI 解决方案,以应对他们独特的业务挑战。她专注于模型定制技术和基于代理的 AI 系统,帮助组织充分利用生成式 AI 技术的潜力。在加入 AWS 之前,Flora 获得了明尼苏达大学计算机科学硕士学位,在那里她培养了在机器学习和人工智能方面的专业知识。
 Jason Zhang 在机器学习、强化学习和生成式 AI 方面拥有专业知识。他于 2014 年获得机械工程博士学位,研究重点是将强化学习应用于实时最优控制问题。他的职业生涯始于特斯拉,将机器学习应用于车辆诊断,随后在苹果和亚马逊 Alexa 从事先进的 NLP 研究。在 AWS,他担任高级数据科学家,为客户提供生成式 AI 解决方案。
Jason Zhang 在机器学习、强化学习和生成式 AI 方面拥有专业知识。他于 2014 年获得机械工程博士学位,研究重点是将强化学习应用于实时最优控制问题。他的职业生涯始于特斯拉,将机器学习应用于车辆诊断,随后在苹果和亚马逊 Alexa 从事先进的 NLP 研究。在 AWS,他担任高级数据科学家,为客户提供生成式 AI 解决方案。
 Rachel Hanspal 是 AWS 生成式 AI 创新中心的深度学习架构师,专注于端到端 GenAI 解决方案,重点是前端架构和 LLM 集成。她擅长将复杂的业务需求转化为创新应用,利用自然语言处理、自动化可视化和安全云架构方面的专业知识。
Rachel Hanspal 是 AWS 生成式 AI 创新中心的深度学习架构师,专注于端到端 GenAI 解决方案,重点是前端架构和 LLM 集成。她擅长将复杂的业务需求转化为创新应用,利用自然语言处理、自动化可视化和安全云架构方面的专业知识。
 Zubair Nabi 是 Kscope 的首席技术官兼联合创始人,该公司是一家集成安全态势管理 (ISPM) 平台。他的专业知识位于大数据、机器学习和分布式系统交叉领域,拥有十多年构建软件、数据和 AI 平台的经验。Zubair 还是乔治华盛顿大学的兼职教员,是《Pro Spark Streaming: The Zen of Real-Time Analytics Using Apache Spark》的作者。他拥有剑桥大学的 MPhil 学位。
Zubair Nabi 是 Kscope 的首席技术官兼联合创始人,该公司是一家集成安全态势管理 (ISPM) 平台。他的专业知识位于大数据、机器学习和分布式系统交叉领域,拥有十多年构建软件、数据和 AI 平台的经验。Zubair 还是乔治华盛顿大学的兼职教员,是《Pro Spark Streaming: The Zen of Real-Time Analytics Using Apache Spark》的作者。他拥有剑桥大学的 MPhil 学位。
 Suparna Pal – kscope.ai 的首席执行官兼联合创始人 – 在 PTC、GE 和思科拥有超过 20 年构建工业、医疗保健和 IT 运营创新平台和解决方案的经验。
Suparna Pal – kscope.ai 的首席执行官兼联合创始人 – 在 PTC、GE 和思科拥有超过 20 年构建工业、医疗保健和 IT 运营创新平台和解决方案的经验。
 Wan Chen 是 AWS 生成式 AI 创新中心的机器学习应用科学家经理。作为科技行业的机器学习/人工智能资深人士,她在传统机器学习、推荐系统、深度学习和生成式 AI 方面拥有广泛的专业知识。她坚信超级智能,并热衷于推动 AI 研究和应用的边界,以增强人类生活并推动业务增长。她拥有英属哥伦比亚大学应用数学博士学位,并曾在牛津大学担任博士后研究员。
Wan Chen 是 AWS 生成式 AI 创新中心的机器学习应用科学家经理。作为科技行业的机器学习/人工智能资深人士,她在传统机器学习、推荐系统、深度学习和生成式 AI 方面拥有广泛的专业知识。她坚信超级智能,并热衷于推动 AI 研究和应用的边界,以增强人类生活并推动业务增长。她拥有英属哥伦比亚大学应用数学博士学位,并曾在牛津大学担任博士后研究员。
 Mu Li 是 AWS 能源部门的首席解决方案架构师。他还是 AWS 能源和公用事业技术现场社区 (TFC) 的全球技术负责人,该社区拥有 300 多名行业和技术专家。李热衷于与客户合作,利用技术实现业务成果。李曾协助客户将所有内容从本地和 Azure 迁移到 AWS,启动了生产监控和监督行业解决方案,在 AWS 上部署了 ION/OpenLink Endur,并实施了基于 AWS 的物联网和机器学习工作负载。在工作之余,李喜欢与家人共度时光、投资、关注休斯顿体育队以及了解商业和技术动态。
Mu Li 是 AWS 能源部门的首席解决方案架构师。他还是 AWS 能源和公用事业技术现场社区 (TFC) 的全球技术负责人,该社区拥有 300 多名行业和技术专家。李热衷于与客户合作,利用技术实现业务成果。李曾协助客户将所有内容从本地和 Azure 迁移到 AWS,启动了生产监控和监督行业解决方案,在 AWS 上部署了 ION/OpenLink Endur,并实施了基于 AWS 的物联网和机器学习工作负载。在工作之余,李喜欢与家人共度时光、投资、关注休斯顿体育队以及了解商业和技术动态。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区