



📢 转载信息
原文链接:https://blogs.nvidia.com/blog/gpu-cuda-scaling-laws-industrial-revolution/
原文作者:Dion Harris
英伟达加速计算平台由GPU驱动,已取代CPU成为创新的引擎,它服务于三大扩展定律,并预示着AI的未来发展方向。
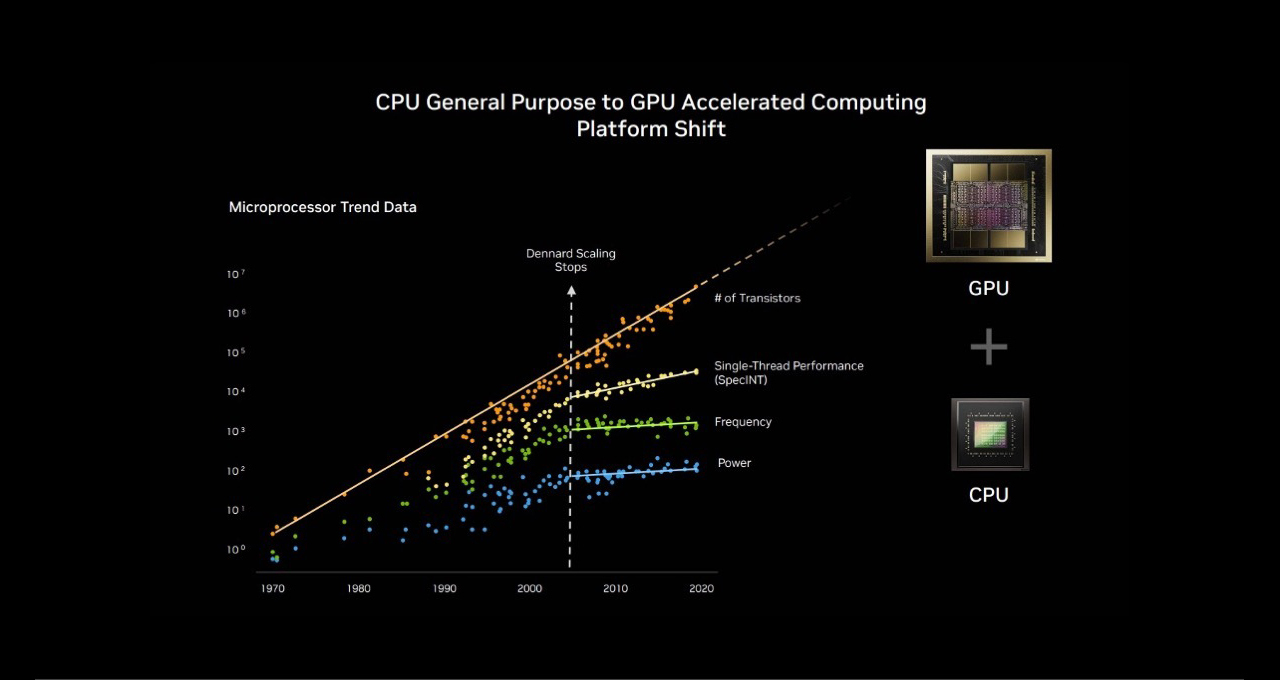
英伟达加速计算平台正在引领曾经由CPU主导的超级计算基准测试,从而在全球范围内推动人工智能、科学、商业和计算效率的发展。
摩尔定律已经走到了尽头,并行处理是未来的方向。随着这一演变,英伟达GPU平台现在独具优势,能够为从下一代推荐系统和大型语言模型(LLM)到AI智能体及更广泛的应用,提供预训练、后训练和推理计算这三大扩展定律的实现能力。
CPU到GPU的转变:计算领域的历史性飞跃 🔗
在SC25大会上,英伟达创始人兼首席执行官黄仁勋强调了格局的转变。在超级计算机TOP500榜单的一个子集——TOP100中,超过85%的系统使用GPU。这一转变标志着计算范式从CPU的串行处理模式历史性地转向了大规模并行加速架构。
![]()
在2012年之前,机器学习基于既定的逻辑。统计模型在CPU上高效运行,依赖于一套硬编码的规则。但当在游戏GPU上运行的AlexNet证明图像分类可以通过示例学习时,一切都改变了。这对AI的未来影响是巨大的,数据量的增加和GPU上的并行处理催生了新一轮的计算浪潮。
这种转变不仅仅是硬件问题。它关乎解锁新科学的平台。GPU提供了更高的每瓦特运算能力,使得在不产生不可承受的能源需求的情况下实现百亿亿次(exascale)计算成为可能。
Green500(全球最高能效超级计算机排名)的最新结果凸显了GPU与CPU在能效上的巨大差异。在该行业标准基准测试中,前五名全部是英伟达GPU,平均实现了70.1 GFLOPS/瓦特。相比之下,排名前列的纯CPU系统平均仅为15.5 FLOPS/瓦特。GPU与CPU在能效上高达4.5倍的差异,突显了将这些系统迁移到GPU所带来的巨大总体拥有成本(TCO)优势。
在能效和性能差异方面,英伟达在Graph500测试中也取得了衡量指标。英伟达取得了创纪录的每秒410万亿次边遍历,在Graph500的广度优先搜索(BFS)榜单上名列第一。
获胜的运行将下一个最高分提高了两倍多,使用了8,192个英伟达H100 GPU来处理一个包含2.2万亿个顶点和35万亿条边的图。相比之下,榜单上第二好的结果大约需要15万个CPU来完成此工作负载。这种规模的硬件占地面积缩减节省了时间、金钱和能源。
然而,英伟达在SC25大会上展示的,其AI超级计算平台远不止GPU。网络、CUDA库、内存、存储和编排都是协同设计的,以提供一个完整的堆栈平台。

英伟达通过CUDA实现了全栈平台。CUDA-X生态系统中的开源库和框架是实现大幅加速的地方。Snowflake最近宣布集成NVIDIA A10 GPU,为数据科学工作流程提供强劲动力。Snowflake ML现在预装了英伟达cuML和cuDF库,以利用这些GPU加速流行的ML算法。
通过这种原生集成,Snowflake的用户无需任何代码更改即可轻松加速模型开发周期。英伟达的基准测试显示,与CPU相比,使用NVIDIA A10 GPU进行随机森林所需的时间减少5倍,而对于HDBSCAN则最多可加速200倍。
这次转变是一个转折点。扩展定律是前进的轨迹。在每一个阶段,GPU都是驱动AI进入下一个篇章的引擎。
但是,CUDA-X以及许多开源软件库和框架是发生很多“魔法”的地方。CUDA-X库加速了跨越各个行业和应用的工件——工程、金融、数据分析、基因组学、生物学、化学、电信、机器人技术等等。
黄仁勋在英伟达最近的财报电话会议上表示:“世界在非AI软件上投入了巨额资金。从数据处理到科学和工程模拟,每年在计算云支出上代表着数千亿美元的投资。”
许多曾经只能在CPU上运行的应用程序现在正迅速转向CUDA GPU。“加速计算已经达到了一个拐点。人工智能也达到了一个拐点,它正在改造现有应用,同时赋能全新的应用,”他说。

始于对能源效率的追求,现在已经成熟为一个科学平台:大规模的模拟与AI的融合。英伟达GPU在TOP100中的领先地位既证明了这一轨迹,也预示着下一个阶段——各个学科的突破。
因此,研究人员现在可以以CPU单独无法达到的规模来训练万亿参数模型、模拟聚变反应堆和加速药物发现。
驱动AI下一前沿的三大扩展定律 🔗
从CPU到GPU的转变不仅仅是超级计算的一个里程碑。它是三大扩展定律的基础,这些定律代表了AI下一工作流程的路线图:预训练、后训练和推理扩展。
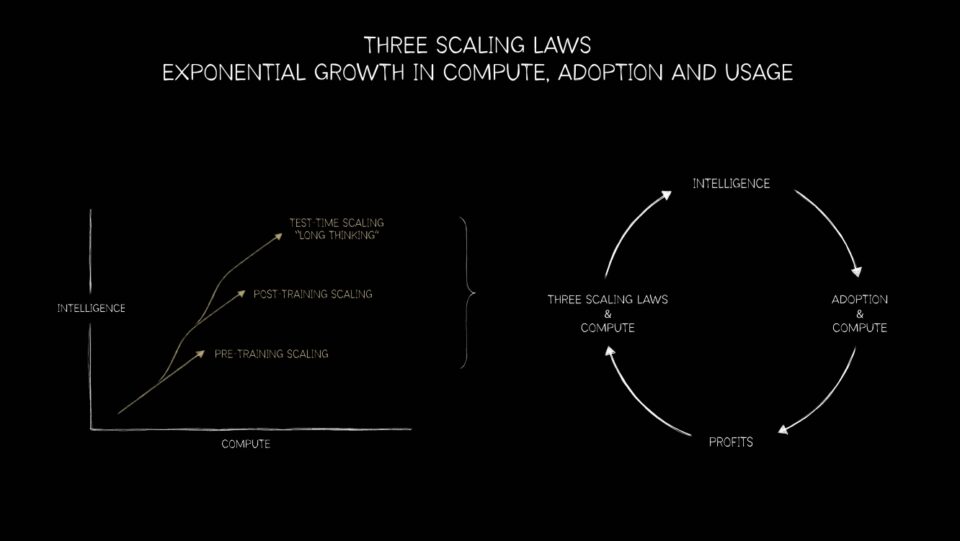
预训练扩展是第一条定律,它为行业提供了帮助。研究人员发现,随着数据集、参数数量和计算能力的增加,模型性能会以可预测的方式提高。数据或参数翻倍,带来了准确性和通用性的飞跃。
在最新的MLPerf Training行业基准测试中,英伟达平台在每项测试中都提供了最高的性能,并且是唯一一个提交所有测试的平台。如果没有GPU,“越大越好”的AI研究时代将因功耗预算和时间限制而停滞不前。
后训练扩展延续了这个故事。一旦基础模型构建完成,就需要对其进行精炼——针对特定行业、语言或安全限制进行调整。诸如人类反馈强化学习(RLHF)、剪枝和蒸馏等技术需要巨大的额外计算量。在某些情况下,其需求可与预训练相媲美。这就像学生在基础教育后进行提高一样。GPU再次提供了动力,使得跨领域的持续微调和适应成为可能。
推理扩展(或称测试时间扩展),是最新的一条定律,可能最具变革性。由专家混合模型(Mixture-of-Experts)架构驱动的现代模型可以在实时评估多种解决方案时进行推理和规划。思维链推理(Chain-of-thought reasoning)、生成式搜索和智能体AI(Agentic AI)需要动态的、递归的计算——通常超过预训练的要求。这一阶段将推动对推理基础设施的指数级需求——从数据中心到边缘设备。
这三大定律共同解释了新AI工作负载对GPU的需求。预训练扩展使GPU变得不可或缺。后训练扩展巩固了它们在精炼中的作用。而推理扩展则确保了即使在训练结束后,GPU仍然至关重要。这是加速计算的下一篇章:一个GPU驱动AI从学习到推理再到部署所有阶段的生命周期。
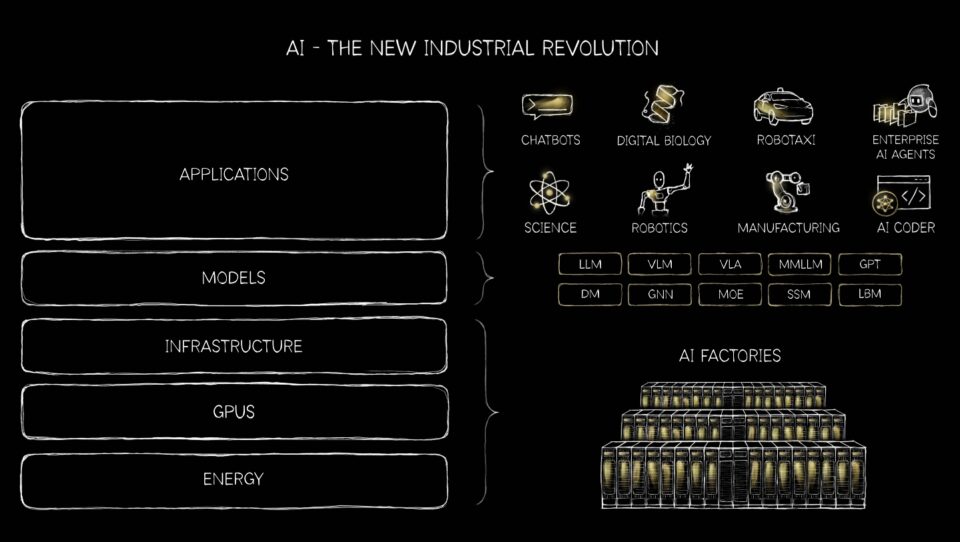
生成式、智能体式、物理AI及未来 🔗
AI的世界正在扩展到超越基本的推荐器、聊天机器人和文本生成。VLM(视觉语言模型)是将计算机视觉和自然语言处理相结合,用于理解和解释图像和文本的AI系统。推荐系统——驱动个性化购物、流媒体和社交信息流的引擎——只是大规模从CPU转向GPU重塑AI的众多例子之一。
与此同时,生成式AI正在改变从机器人技术和自动驾驶汽车到软件即服务公司的一切,代表着初创公司的一项巨大投资。
英伟达平台是唯一能够运行所有主流生成式AI模型并处理140万个开源模型的平台。
曾受限于CPU架构,推荐系统难以在大规模上捕捉用户行为的复杂性。借助CUDA GPU,预训练扩展使得模型能够从海量点击、购买和偏好数据集中学习,发现更丰富的模式。后训练扩展则针对特定领域对这些模型进行微调,从而提高零售到娱乐等行业的个性化水平。在主要的全球在线网站上,推荐相关性准确率哪怕提升1%,都能带来数十亿美元的额外销售额。
根据Emarketer的数据,2025年全球电子商务销售额预计将达到6.4万亿美元。
全球超大规模云服务商(一个万亿美元的行业)正在将搜索、推荐和内容理解从经典机器学习转变为生成式AI。英伟达CUDA在两者上都表现出色,是推动数千亿美元基础设施投资的理想平台。
现在,推理扩展正在改变推理本身:推荐引擎可以动态推理,实时评估多个选项以提供情境感知的建议。结果是精度和相关性的飞跃——推荐感觉不再像静态列表,而更像是智能指导。GPU和扩展定律正在将推荐从一个后台功能转变为智能体AI的前线能力,使数十亿人能够轻松地在互联网上梳理数万亿的事物,否则这将是不可行的。
始于由LLM驱动的对话界面,现在正演变为智能、自主系统,有望重塑全球经济的几乎所有部门。
我们正在经历一次基础性的转变——AI从一种虚拟技术转变为进入物理世界。这一转变要求计算基础设施实现爆炸式增长,并需要人与机器之间形成新的协作形式。
生成式AI不仅能创造新的文本和图像,还能创造代码、设计甚至科学假设。现在,智能体AI正在到来——能够自主感知、推理、规划和行动的系统。这些智能体表现得更像数字同事,而不是工具,在各个行业执行复杂的多步骤任务。从法律研究到物流,智能体AI有望通过充当自主数字工人来提高生产力。
也许最具变革性的飞跃是物理AI——智能在各种形式的机器人中的体现。构建物理AI实体机器人需要三台计算机:NVIDIA DGX GB300用于训练推理视觉语言动作模型(VLA),NVIDIA RTX PRO用于在Omniverse构建的虚拟世界中进行模拟、测试和验证模型,以及Jetson Thor用于实时运行推理VLA。
预计在未来几年内,随着自主移动机器人、协作机器人和人形机器人在制造、物流和医疗保健领域掀起变革,机器人技术将迎来突破性时刻。摩根士丹利估计,到2050年,将有10亿台人形机器人,创造5万亿美元的收入。
这仅仅是AI将如何深度嵌入物理经济的一小部分。

AI不再仅仅是一个工具。它正在执行工作,并有望改变全球100万亿美元的所有市场。一场良性的AI循环已经到来,从根本上改变了整个计算堆栈,将所有计算机转变为服务于更大机遇的新型超级计算平台。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区