



📢 转载信息
原文作者:Curt Lockhart, Francesco Ciannella, Alick Wong, Andrew Smith, Melanie Li, Tim Ma, and Tony Trinh
本文由 NVIDIA 和作者们撰写,作者们谨此感谢 Adi Margolin、Eliuth Triana 和 Maryam Motamedi 的合作。
如今,组织面临着处理海量音频数据的挑战——包括客户电话、会议录音、播客和语音消息——以挖掘宝贵见解。自动语音识别 (ASR) 是此过程中的关键第一步,它将语音转换为文本,以便可以执行进一步的分析。然而,大规模运行 ASR 计算量大且成本高昂。这就是 Amazon SageMaker AI 上的异步推理发挥作用的地方。通过在 SageMaker AI 上使用异步端点部署最先进的 ASR 模型(如 NVIDIA Parakeet 模型),您可以高效地处理大型音频文件和批处理工作负载。借助异步推理,长时间运行的请求可以在后台处理(稍后交付结果);它还支持在没有工作负载时自动扩展到零,并在需求激增时进行处理,而不会阻塞其他作业。
在本博文中,我们将探讨如何在 SageMaker AI 上托管 NVIDIA Parakeet ASR 模型,并将其集成到异步管道中,以实现可扩展的音频处理。我们还将重点介绍 Parakeet 架构和 NVIDIA Riva 工具包在语音 AI 中的优势,并讨论如何使用 NVIDIA NIM 在 AWS 上进行部署。
NVIDIA 语音 AI 技术:Parakeet ASR 和 Riva 框架
NVIDIA 提供了一套全面的语音 AI 技术,将高性能模型与高效的部署解决方案相结合。其核心是 Parakeet ASR 模型家族,它代表了最先进的语音识别功能,实现了行业领先的准确性,具有较低的词错误率 (WER)。该模型采用 Fast Conformer 编码器和 CTC 或换能器解码器架构,在保持准确性的同时,处理速度比标准 Conformer 快 2.4 倍。
NVIDIA Speech NIM 是一系列用于构建可定制语音 AI 应用的 GPU 加速微服务。NVIDIA Speech 模型在 36 多种语言中提供准确的转录准确性和自然、富有表现力的声音——非常适合客户服务、联络中心、可访问性和全球企业工作流程。开发人员可以针对特定语言、口音、领域和词汇表对模型进行微调和定制,从而支持准确性和品牌声音的一致性。
与 LLM 和 NVIDIA Nemo Retriever 的无缝集成,使 NVIDIA 模型成为智能体 AI 应用的理想选择,帮助您的组织以更安全、高性能的语音 AI 脱颖而出。NIM 框架将这些服务作为容器化解决方案提供,通过包含必要依赖项和优化的 Docker 容器,简化了部署。
高性能模型和部署工具的这种组合为组织提供了大规模实施语音识别的完整解决方案。
解决方案概述
图中所示的架构展示了一个专为 ASR 和摘要工作负载设计的全面异步推理管道。该解决方案提供了一个强大、可扩展且经济高效的处理管道。
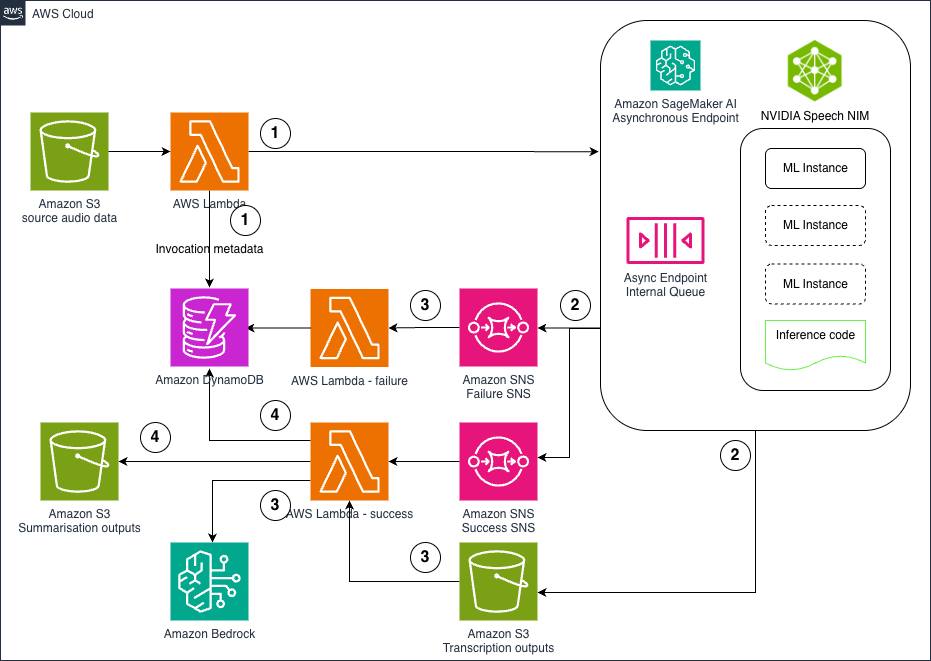
架构组件
该架构由五个关键组件协同工作,共同创建高效的音频处理管道。其核心是 SageMaker AI 异步端点,它托管 Parakeet ASR 模型,并具有自动扩展功能,在空闲时可扩展到零,以优化成本。
- 数据摄取过程始于将音频文件上传到 Amazon Simple Storage Service (Amazon S3),触发 AWS Lambda 函数来处理元数据并启动工作流程。
- 对于事件处理,SageMaker 端点通过单独的队列自动发送 Amazon Simple Notification Service (Amazon SNS) 成功和失败通知,从而能够正确处理转录内容。
- 在 Amazon S3 上成功转录的内容会移至 Amazon Bedrock LLM,用于智能摘要和分类、洞察提取等额外处理。
- 最后,一个使用 Amazon DynamoDB 的全面跟踪系统存储工作流程状态和元数据,从而能够对整个管道进行实时监控和分析。
详细实施演练
在本节中,我们将提供解决方案实施的详细演练。
SageMaker 异步端点先决条件
要运行示例笔记本,您需要一个拥有 AWS Identity and Access Management (IAM) 角色(具有最少权限来管理所创建资源的权限)的 AWS 账户。有关详细信息,请参阅创建 AWS 账户。您可能需要为相应的 SageMaker 异步托管实例请求服务配额增加。在此示例中,我们需要一个 ml.g5.xlarge SageMaker 异步托管实例和一个 ml.g5.xlarge SageMaker 笔记本实例。您也可以选择不同的集成开发环境 (IDE),但请确保该环境包含用于本地测试的 GPU 计算资源。
SageMaker 异步端点配置
当您部署自定义模型(如 Parakeet)时,SageMaker 有以下几种选择:
- 使用 NVIDIA 提供的 NIM 容器
- 使用大型模型推理 (LMI) 容器
- 使用预构建的 PyTorch 容器
我们将为所有三种方法提供示例。
使用 NVIDIA NIM 容器
NVIDIA NIM 通过容器化解决方案提供了一种简化的部署优化 AI 模型的方法。我们的实施将这一概念进一步发展,创建了一个统一的 SageMaker AI 端点,该端点可以智能地在 HTTP 和 gRPC 协议之间路由,以帮助最大限度地提高性能和功能,同时简化部署过程。
创新的双协议架构
关键创新在于结合了 HTTP + gRPC 的架构,它暴露了一个具有智能路由功能的单一 SageMaker AI 端点。此设计解决了在协议效率和功能完整性之间进行选择的常见挑战,通过自动选择最佳传输方法来实现。HTTP 路由针对小于 5MB 的文件进行简单转录任务进行了优化,为常见用例提供了更快的处理速度和更低的延迟。同时,gRPC 路由支持更大的文件(SageMaker AI 实时端点支持的最大负载为 25MB)和高级功能,如带有精确词级时间信息的说话人区分 (diarization)。系统的自动路由功能会分析传入请求以确定文件大小和请求的功能,然后自动选择最合适的协议,而无需手动配置。对于需要明确控制的应用程序,该端点还支持通过 /invocations/http 进行强制路由以进行简单转录,或在需要说话人区分时通过 /invocations/grpc 进行强制路由。这种灵活性允许根据特定的应用程序需求进行自动化优化和细粒度控制。
高级语音识别和说话人区分功能
NIM 容器支持一个全面的音频处理管道,通过 NVIDIA Riva 的集成功能,无缝地结合了语音识别与说话人识别。容器处理音频预处理,包括格式转换和分段,而 ASR 和说话人区分过程在同一音频流上并发运行。使用重叠的时间段自动对结果进行对齐,每个转录片段都会收到适当的说话人标签(例如,Speaker_0、Speaker_1)。推理处理程序通过完整的管道处理音频文件,初始化 ASR 和说话人区分服务,并行运行它们,并将转录片段与说话人标签对齐。输出以结构化的 JSON 格式包含完整的转录、带有说话人归属的时间戳片段、置信度分数和总说话人数。
实施和部署
该实施以 NVIDIA parakeet-1-1b-ctc-en-us NIM 容器为基础,添加了一个 Python aiohttp 服务器,该服务器通过自动启动和监控服务来无缝管理完整的 NIM 生命周期。该服务器通过将 SageMaker 推理请求转换为适当的 NIM API 来处理协议适配,实现了分析请求特征的智能路由逻辑,并为稳健的生产部署提供了详细的错误消息和回退机制的全面错误处理。容器化解决方案通过标准的 Docker 和 AWS CLI 命令简化了部署,其特点是包含必要依赖项和优化的预配置 Docker 文件。该系统接受多种输入格式,包括 multipart/form-data(推荐用于最大兼容性)、带有 base64 编码的 JSON(用于简单集成场景)和原始二进制上传(用于直接音频处理)。
有关详细的实施说明和工作示例,团队可以参考 AWS 示例仓库中完整的实施和部署笔记本,该笔记本提供了有关使用自带容器 (BYOC) 方法在 SageMaker AI 上使用 NIM 部署 Parakeet ASR 的全面指南。对于具有特定架构偏好的组织,还提供了单独的纯 HTTP 和纯 gRPC 实施,为具有明确定义用例的团队提供了更简单的部署模型,而组合实施则提供了最大的灵活性和自动优化。
AWS 客户可以将这些模型作为生产级的 NVIDIA NIM 容器直接从 SageMaker Marketplace 或 JumpStart 部署,或者部署在 Hugging Face 上的开源 NVIDIA 模型,这些模型可以通过 SageMaker 或 Amazon Elastic Kubernetes Service (Amazon EKS) 上的自定义容器进行部署。这使得组织能够在全托管、企业级的端点(具有自动扩展和安全性)与用于研究或受限用例的灵活开源开发之间进行选择。
使用 AWS LMI 容器
LMI 容器旨在简化在 AWS 上托管大型模型的过程。这些容器包含优化的推理引擎,如 vLLM、FasterTransformer 或 TensorRT-LLM,可以自动处理模型并行、量化和批处理等大型模型任务。LMI 容器本质上是一个预配置的 Docker 镜像,它运行一个推理服务器(例如带有这些优化的 Python 服务器),并允许您使用环境变量指定模型参数。
要使用 LMI 容器来部署 Parakeet,我们通常会执行以下操作:
- 选择合适的 LMI 映像:AWS 为不同框架提供不同的 LMI 映像。对于 Parakeet,我们可能会使用 DJLServing 映像以实现高效推理。或者,如果我们将模型打包为 ONNX 或 TensorRT 格式,NVIDIA Triton 推理服务器(Riva 使用的)也是一个选项。
- 指定模型配置:使用 LMI,我们通常提供一个 model_id(如果从 Hugging Face Hub 拉取)或指向我们模型的路径,以及关于如何加载模型的配置(GPU 数量、张量并行度、量化位数)。然后,容器会下载模型并使用指定的设置进行初始化。我们也可以从 Amazon S3 下载自己的模型文件,而不是使用 Hub。
- 定义推理处理程序:LMI 容器可能需要一个小的处理程序脚本或配置来告知它如何处理请求。对于 ASR,这可能涉及读取音频输入、将其传递给模型并返回文本。
AWS LMI 容器通过先进的优化技术(包括连续批处理、张量并行和最先进的量化方法)提供高性能和可扩展性。LMI 容器通过单一的统一配置集成多个推理后端(vLLM、TensorRT-LLM),帮助用户无缝地试验和切换框架,为您的特定用例找到最佳性能堆栈。
使用 SageMaker PyTorch 容器
SageMaker 提供PyTorch 深度学习容器 (DLC),其中预装了 PyTorch 和许多常用库。在此示例中,我们演示了如何扩展我们的预构建容器以安装模型所需的包。您可以在端点创建期间直接从 Hugging Face 下载模型,或者下载 Parakeet 模型工件,将它们与必要的配置文件一起打包到 model.tar.gz 存档中,并将其上传到 Amazon S3。除了模型工件外,还需要一个 inference.py 脚本作为入口点脚本,用于定义模型加载和推理逻辑,包括音频预处理和转录处理。当使用 SageMaker Python SDK 创建 PyTorchModel 时,SDK 会自动将模型存档重新打包,将 inference.py 脚本包含在 /opt/ml/model/code/ 中,同时将模型工件保留在 /opt/ml/model/ 中。一旦端点成功部署,就可以通过向 predict API 发送音频文件作为字节流来调用它,以获取转录结果。
对于 SageMaker 实时端点,我们目前允许的最大有效载荷大小为 25MB。请确保您已将容器设置为也允许最大请求大小。但是,如果您计划将同一模型用于异步端点,异步端点支持的最大文件大小为 1GB,响应时间最长为 1 小时。因此,您应该设置容器以准备好处理此有效载荷大小和超时。使用 PyTorch 容器时,需要考虑以下关键配置参数:
- SAGEMAKER_MODEL_SERVER_WORKERS:设置将加载模型数量(复制到 GPU 内存中)的 torch 工作线程数。
- TS_DEFAULT_RESPONSE_TIMEOUT:设置 Torch 工作线程的超时设置;对于长时间音频处理,可以将其设置为更高的数字。
- TS_MAX_REQUEST_SIZE:将请求的字节大小值设置为 1G,用于异步端点。
- TS_MAX_RESPONSE_SIZE:设置响应的字节大小值。
在示例笔记本中,我们还展示了如何利用 SageMaker Python SDK 提供的 SageMaker 本地会话。它帮助您使用 Docker 容器(而不是托管的 AWS 基础架构)在本地创建估计器并运行训练、处理和推理作业,为扩展到生产环境之前快速测试和调试机器学习脚本提供了一种快捷方式。
CDK 管道先决条件
在部署此解决方案之前,请确保您已:
- 配置了具有适当权限的AWS CLI——安装指南
- 安装了AWS Cloud Development Kit (AWS CDK)——安装指南
- 安装了 Node.js 18+ 和 Python 3.9+
- Docker – 安装指南
- 已使用您的 ML 模型(Parakeet ASR 模型或类似模型)部署的SageMaker 端点
- 已为成功和失败通知创建了 Amazon SNS 主题
CDK 管道设置
解决方案部署从使用基础架构即代码 (IaC) 原则配置必要的 AWS 资源开始。AWS CDK 创建基础组件,包括:
- DynamoDB 表:配置为按需容量,用于跟踪调用元数据、处理状态和结果。
- S3 存储桶:用于输入音频文件、转录输出和摘要结果的安全存储。
- SNS 主题:用于成功和失败事件处理的单独队列。
- Lambda 函数:用于元数据处理、状态更新和工作流程编排的无服务器函数。
- IAM 角色和策略:用于跨服务通信和资源访问的适当权限。
环境设置
克隆仓库并安装依赖项:
# 安装 degit,一个用于下载特定子目录的库 npm install -g degit # 仅克隆特定文件夹 npx degit aws-samples/genai-ml-platform-examples/infrastructure/automated-speech-recognition-async-pipeline-sagemaker-ai/sagemaker-async-batch-inference-cdk sagemaker-async-batch-inference-cdk # 导航到文件夹 cd sagemaker-async-batch-inference-cdk # 安装 Node.js 依赖项 npm install # 设置 Python 虚拟环境 python3 -m venv .venv source .venv/bin/activate # 在 Windows 上: .venv\Scripts\activate pip install -r requirements.txt配置
在 bin/aws-blog-sagemaker.ts 中更新 SageMaker 端点配置:
vim bin/aws-blog-sagemaker.ts # 更改端点名称 sageMakerConfig: { endpointName: 'your-sagemaker-endpoint-name', enableSageMakerAccess: true }如果您已按照笔记本的说明部署了端点,则应该创建了两个 SNS 主题。否则,请确保使用 CLI 创建正确的 SNS 主题:
# 创建 SNS 主题 aws sns create-topic --name success-inf aws sns create-topic --name failed-inf构建和部署
在部署 AWS CloudFormation 模板之前,请确保 Docker 正在运行。
# 编译 TypeScript 为 JavaScript npm run build # 引导 CDK(仅首次) npx cdk bootstrap # 部署堆栈 npx cdk deploy验证部署
成功部署后,请记下输出值:
- 用于状态跟踪的 DynamoDB 表名称
- 用于处理和状态更新的 Lambda 函数 ARN
- 用于通知的 SNS 主题 ARN
提交音频文件进行处理
处理音频文件
更新 upload_audio_invoke_lambda.sh
LAMBDA_ARN="YOUR_LAMBDA_FUNCTION_ARN" S3_BUCKET="YOUR_S3_BUCKET_ARN"运行脚本:
AWS_PROFILE=default ./scripts/upload_audio_invoke_lambda.sh
此脚本将:
- 下载一个示例音频文件
- 将音频文件上传到您的 S3 存储桶
- 将存储桶路径发送到 Lambda 并触发转录和摘要管道
监控进度
您可以使用以下命令在 DynamoDB 表中查看结果:
aws dynamodb scan --table-name YOUR_DYNAMODB_TABLE_NAME在 DynamoDB 表中检查处理状态:
- submitted:已成功排队等待推理
- completed:转录成功完成
- failed:处理过程中出现错误
音频处理和工作流程编排
核心处理工作流程遵循事件驱动模式:
初始处理和元数据提取:当音频文件上传到 S3 时,触发的 Lambda 函数会分析文件元数据,验证格式兼容性,并在 DynamoDB 中创建详细的调用记录。这有助于从音频内容进入系统的那一刻起进行全面跟踪。
异步语音识别:音频文件通过 SageMaker 端点使用优化的 ASR 模型进行处理。异步过程可以处理各种文件大小和持续时间,而无需担心超时问题。每个处理请求都会分配一个唯一的标识符用于跟踪。
成功路径处理:成功转录后,系统会自动启动摘要工作流程。转录的文本被发送到 Amazon Bedrock,高级语言模型会根据可配置的参数(如摘要长度、关注点和输出格式)生成上下文适当的摘要。
错误处理和恢复:处理失败的尝试会触发专用的 Lambda 函数,这些函数会记录详细的错误信息,更新处理状态,并可以针对瞬时故障启动重试逻辑。这种强大的错误处理可以最大限度地减少数据丢失,并为处理问题提供清晰的可见性。
实际应用
客户服务分析:组织可以处理数千个客户服务呼叫录音,以生成转录和摘要,从而能够大规模地进行情感分析、质量保证和洞察提取。
会议和会议处理:企业团队可以自动转录和摘要会议录音,为参与者和利益相关者创建可搜索的档案和可操作的摘要。
媒体和内容处理:媒体公司可以处理播客、访谈和视频内容,以生成转录和摘要,从而提高可访问性和内容可发现性。
合规性和法律文件:法律和合规团队可以处理录制的证词、听证会和访谈,以创建准确的转录和摘要,用于案件准备和文档编制。
清理
使用完解决方案后,请移除 SageMaker 端点以避免产生额外费用。您可以使用提供的代码分别删除实时和异步推理端点:
# 删除实时推理 endpointreal_time_predictor.delete_endpoint() # 删除异步推理 endpointasync_predictor.delete_endpoint()您还应该删除 CDK 堆栈创建的所有资源。
# 删除 CDK 堆栈 cdk destroy结论
强大的 NVIDIA 语音 AI 技术与 AWS 云基础设施的集成,为大规模音频处理创建了一个全面的解决方案。通过将 Parakeet ASR 行业领先的准确性和速度与 NVIDIA Riva 在 Amazon SageMaker 异步推理管道上的优化部署框架相结合,组织可以实现高性能的语音识别和成本效益高的扩展。该解决方案利用 AWS 的托管服务(SageMaker AI、Lambda、S3 和 Bedrock)来创建用于处理音频内容的自动化、可扩展管道。凭借自动扩展到零、全面的错误处理以及通过 DynamoDB 进行的实时监控等功能,组织可以专注于从音频内容中提取业务价值,而不是管理基础设施的复杂性。无论是处理客户服务电话、会议录音还是媒体内容,这种架构都能提供可靠、高效且经济高效的音频处理功能。要体验此解决方案的全部潜力,我们鼓励您探索该解决方案,如果您有任何特定的业务需求并希望定制解决方案,请与我们联系。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
关于作者
 Melanie Li 博士是 AWS 驻悉尼的高级生成式 AI 解决方案架构师,专注于与客户合作,使用最先进的 AI/ML 工具构建解决方案。她一直积极参与 APJ 地区的多个生成式 AI 计划,利用 LLM 的强大功能。在加入 AWS 之前,李博士曾在金融和零售行业担任数据科学职位。
Melanie Li 博士是 AWS 驻悉尼的高级生成式 AI 解决方案架构师,专注于与客户合作,使用最先进的 AI/ML 工具构建解决方案。她一直积极参与 APJ 地区的多个生成式 AI 计划,利用 LLM 的强大功能。在加入 AWS 之前,李博士曾在金融和零售行业担任数据科学职位。
 Tony Trinh 是 AWS 的高级 AI/ML 专家架构师。Tony 在 IT 行业拥有 13 年以上的经验,专注于架构可扩展、合规性驱动的 AI 和 ML 解决方案——特别是在生成式 AI、MLOps 和云原生数据平台方面。作为其博士研究的一部分,他对多模态 AI 和空间 AI 进行了研究。在业余时间,Tony 喜欢远足、游泳和试验家庭装修。
Tony Trinh 是 AWS 的高级 AI/ML 专家架构师。Tony 在 IT 行业拥有 13 年以上的经验,专注于架构可扩展、合规性驱动的 AI 和 ML 解决方案——特别是在生成式 AI、MLOps 和云原生数据平台方面。作为其博士研究的一部分,他对多模态 AI 和空间 AI 进行了研究。在业余时间,Tony 喜欢远足、游泳和试验家庭装修。
 Alick Wong 是亚马逊网络服务 (AWS) 的高级解决方案架构师,他帮助初创公司和数字原生企业实现平台的现代化、优化和扩展...... [内容被截断]
Alick Wong 是亚马逊网络服务 (AWS) 的高级解决方案架构师,他帮助初创公司和数字原生企业实现平台的现代化、优化和扩展...... [内容被截断]
评论区