



📢 转载信息
原文链接:https://machinelearningmastery.com/3-smart-ways-to-encode-categorical-features-for-machine-learning/
原文作者:Shittu Olumide
在本文中,您将学习三种可靠的技术——序数编码、独热编码和目标(均值)编码——它们可以将类别特征转换为模型就绪的数字,同时保留其含义。
我们将涵盖的主题包括:
- 何时以及如何对具有真正顺序的类别应用序数(标签式)编码。
- 安全地对名义特征使用独热编码,并了解其权衡。
- 在不泄露目标变量的情况下,将目标(均值)编码应用于高基数特征。
让我们开始工作吧。
机器学习中编码类别特征的 3 种智能方法
图片作者:Editor
引言
如果您花时间处理过真实世界的数据,就会很快意识到并非所有数据都是整洁的数字。事实上,最有趣、定义人、地点和产品的方面,都是通过类别来捕捉的。想想一个典型的客户数据集:您有城市、产品类型、教育水平,甚至是最喜欢的颜色等字段。这些都是类别特征的示例,即变量可以取有限、固定的数值之一。
问题在于?虽然我们的大脑可以无缝地处理“红色”和“蓝色”或“纽约”和“伦敦”之间的区别,但我们用来进行预测的机器学习模型却不能。像线性回归、决策树或神经网络这样的模型本质上是数学函数。它们通过乘法、加法和比较数字来工作。它们需要计算距离、斜率和概率。当您向模型输入单词“Marketing”时,它看不到一个职位名称;它只看到一串文本,这对于其方程中的计算没有数值价值。正是这种处理文本的能力缺失,导致您尝试用原始的非数字标签进行训练时,模型会立即崩溃。
特征工程,特别是编码的主要目标是充当翻译。我们的工作是将这些定性标签转换为定量、数字化的特征,同时不丢失底层含义或关系。如果我们做得正确,我们创建的数字将承载原始类别的预测能力。例如,编码必须确保代表较高教育水平的数字在数量上比代表较低教育水平的数字“更高”,或者代表不同城市的数字能够反映它们在购买习惯上的差异。
为了应对这一挑战,我们发展出了执行这种转换的智能方法。我们将从最直观的方法开始,即简单地根据等级分配数字或为每个类别创建单独的二进制标志。然后,我们将转而采用一种强大的技术,该技术利用目标变量本身来构建单个、密集的特征,从而捕获类别的真实预测影响力。通过理解这种演进,您将有能力为遇到的任何类别数据选择完美的编码方法。
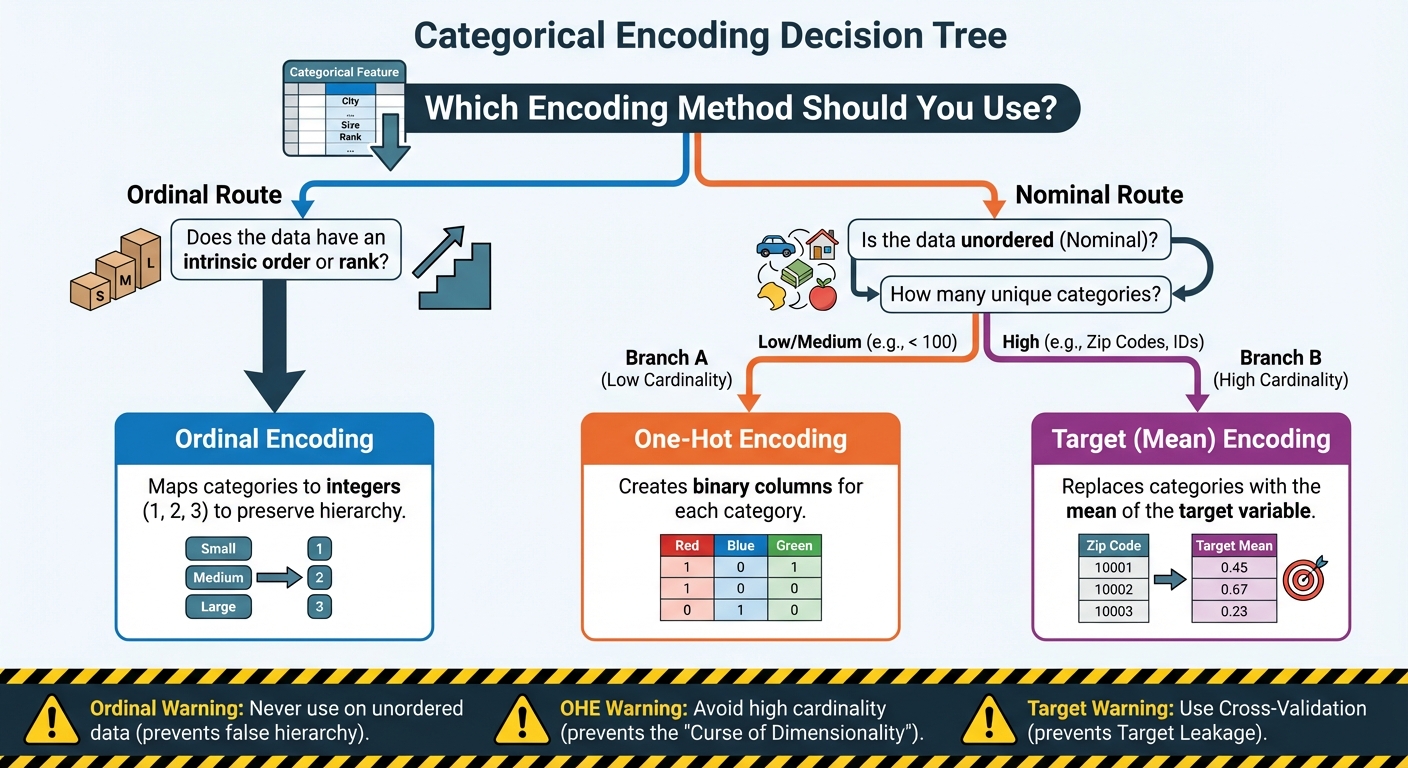
机器学习中编码类别特征的 3 种智能方法:流程图(点击放大)
图片作者:Editor
1. 保留顺序:序数编码和标签编码
第一种,也是最简单的转换技术,专为那些不仅仅是一堆随机名称,而是具有内在等级或顺序的类别数据而设计。这是关键的洞察。并非所有类别都是平等的;有些在本质上比其他的“更高”或“更多”。
最常见的示例是代表某种等级或层次结构的特征:
- 教育水平:(高中 ⇒ 大学 ⇒ 硕士 ⇒ 博士)
- 客户满意度:(非常差 ⇒ 差 ⇒ 中等 ⇒ 好 ⇒ 优秀)
- T恤尺码:(小 ⇒ 中 ⇒ 大)
当您遇到此类数据时,最有效的编码方法是使用序数编码(当将类别映射到整数时,通常非正式地称为“标签编码”)。
实现机制
过程很简单:您根据类别在层次结构中的位置将其映射到整数。您不是随机分配数字;而是明确定义顺序。
例如,如果您有 T 恤尺码,映射如下所示:
| 原始类别 | 分配的数值 |
|---|---|
| 小 (S) | 1 |
| 中 (M) | 2 |
| 大 (L) | 3 |
| 特大 (XL) | 4 |
通过这样做,您是在告诉机器 XL (4) 在数值上比 S (1) “更大”或“更重要”,这正确地反映了现实世界的关系。M (2) 和 L (3) 之间的差异在数学上与 L (3) 和 XL (4) 之间的差异相同,即尺寸增加了一个单位。这个产生的单个数字列就是您输入模型的内容。
引入错误的层次结构
尽管序数编码是处理有序数据的完美选择,但如果误用,它会带来巨大的风险。您绝不能将其应用于名义(无序)数据。
考虑对颜色列表进行编码:红、蓝、绿。如果您武断地分配:红 = 1,蓝 = 2,绿 = 3,您的机器学习模型将把这解释为一种层次结构。它会得出结论,“绿色”比“红色”大或重要两倍,并且“蓝色”和“绿色”之间的差异与“红色”和“蓝色”之间的差异相同。这几乎肯定是不正确的,并且会严重误导您的模型,迫使其学习不存在的数值关系。
这里的规则简单而明确:仅当类别之间存在清晰的、可证明的等级或顺序时,才使用序数编码。如果类别只是名称而没有内在顺序(如水果类型或城市),则必须使用其他编码技术。
实现与代码解释
我们可以使用 scikit-learn 中的 OrdinalEncoder 来实现这一点。关键在于我们必须自己明确定义类别的顺序。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
from sklearn.preprocessing import OrdinalEncoder
import numpy as np
# Sample data representing customer education levels
data = np.array([['High School'], ['Bachelor\'s'], ['Master\'s'], ['Bachelor\'s'], ['PhD']])
# Define the explicit order for the encoder
# This ensures that 'Bachelor\'s' is correctly ranked below 'Master\'s'
education_order = [
['High School', 'Bachelor\'s', 'Master\'s', 'PhD']
]
# Initialize the encoder and pass the defined order
encoder = OrdinalEncoder(categories=education_order)
# Fit and transform the data
encoded_data = encoder.fit_transform(data)
print("Original Data:\n", data.flatten())
print("\nEncoded Data:\n", encoded_data.flatten())
|
在上面的代码中,关键部分是在初始化 OrdinalEncoder 时设置 categories 参数。通过传递确切的列表 education_order,我们告诉编码器“高中”排在第一位,然后是“学士学位”,依此类推。然后编码器根据这个自定义序列分配相应的整数 (0, 1, 2, 3)。如果我们跳过这一步,编码器可能会根据字母顺序分配整数,这将破坏我们想要保留的有意义的层次结构。
2. 消除等级:独热编码 (OHE)
正如我们所讨论的,序数编码仅在类别具有清晰等级时才有效。但是,那些纯粹是名义的特征该怎么办,即它们有名称,但没有内在顺序?想想国家、最喜欢的动物或性别。是“法国”比“日本”好吗?是“狗”在数学上大于“猫”吗?绝对不是。
对于这些无序特征,我们需要一种在不引入虚假等级感的情况下将它们编码为数字的方法。解决方案是独热编码 (OHE),这是目前最广泛使用和最安全的适用于名义数据的编码技术。
实现机制
OHE 的核心思想很简单:不是用一个数字替换一个类别列,而是用多个二进制列替换它。对于原始特征中的每个唯一类别,您都会创建一个全新的列。这些新列通常称为虚拟变量。
例如,如果您的原始“颜色”特征有三个唯一类别(红、蓝、绿),OHE 将创建三个新列:Color_Red、Color_Blue 和 Color_Green。
在任何给定行中,只有其中一列会“热”(值为 1),其余的则为 0。
| 原始颜色 | Color_Red | Color_Blue | Color_Green |
|---|---|---|---|
| 红 | 1 | 0 | 0 |
| 蓝 | 0 | 1 | 0 |
| 绿 | 0 | 0 | 1 |
这种方法非常出色,因为它完全解决了等级问题。模型现在将每个类别视为一个完全独立、分离的特征。“蓝色”不再在数值上与“红色”相关联;它只是存在于其自己的二进制列中。这是您知道类别没有顺序时最安全、最可靠的默认选择。
权衡
虽然 OHE 是具有低到中等基数(即,唯一值数量相对较少,通常低于 100)的特征的标准做法,但当处理高基数特征时,它很快就会成为一个问题。
基数指的是特征中唯一类别的数量。考虑一下美国邮政编码这样的特征,它很容易有超过 40,000 个唯一值。应用 OHE 将迫使您创建 40,000 个全新的二进制列。这导致了两个主要问题:
- 维度灾难: 您突然将数据集的宽度急剧膨胀,创建了一个巨大的、稀疏的矩阵(一个主要由零组成的矩阵)。这会大大减慢大多数算法的训练过程。
- 过拟合: 许多类别在数据集中只出现一次或两次。模型可能会为其中一个稀有、特定的列分配一个极端的权重,本质上是记忆了它的单次出现,而不是学习普遍的模式。
当一个特征有数千个唯一类别时,OHE 根本不切实际。这种限制迫使我们超越 OHE,直接引导我们了解处理大规模数据的第三种更高级的技术。
实现与代码解释
在 Python 中,scikit-learn 中的 OneHotEncoder 或 pandas 中的 get_dummies() 函数是标准工具。对于快速转换,pandas 方法通常更容易:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
import pandas as pd
# Sample data with a nominal feature: Color
data = pd.DataFrame({
'ID': [1, 2, 3, 4, 5],
'Color': ['Red', 'Blue', 'Red', 'Green', 'Blue']
})
# 1. Apply One-Hot Encoding using pandas get_dummies
df_encoded = pd.get_dummies(data, columns=['Color'], prefix='Is')
print(df_encoded)
|
在此代码中,我们传入我们的 DataFrame data 并指定要转换的列(Color)。prefix='Is' 只是为新列添加一个整洁的前缀(如“Is_Red”),以提高可读性。输出的 DataFrame 保留了 ID 列,并用三个新的、独立的二进制特征:Is_Red、Is_Blue 和 Is_Green 替换了单个 Color 列。原本是“红色”的行现在在 Is_Red 列中有 1,而在其他列中为 0,从而实现了所需的数值分离,而没有强加等级。
3. 利用预测能力:目标(均值)编码
正如我们所确定的,当一个特征具有高基数(如产品 ID、邮政编码或电子邮件域)时,独热编码会以灾难性的方式失败。创建数千个稀疏列在计算上效率低下,并导致过拟合。我们需要一种技术,能够将这数千个类别压缩成一个单一的、稠密的列,同时不丢失其预测信号。
答案在于目标编码,也经常被称为均值编码。该方法不是仅仅依赖于特征本身,而是策略性地利用目标变量 (Y) 来确定每个类别的数值。
概念与机制
核心思想是将每个类别编码为属于该类别的所有数据点目标变量的平均值。
例如,假设您正在尝试预测一笔交易是否是欺诈(Y=1 表示欺诈,Y=0 表示合法)。如果您的类别特征是城市:
- 您按城市对所有交易进行分组
- 对于每个城市,计算 Y 变量的平均值(平均欺诈率)
- “迈阿密”的平均欺诈率可能为 0.10(或 10%),而“波士顿”可能为 0.02(2%)
- 您用数字 0.10 替换所有行中类别标签“迈阿密”,用 0.02 替换“波士顿”
结果是单个、密集的数值列,它立即嵌入了该类别的预测能力。模型立即知道,编码为 0.10 的行比编码为 0.01 的行欺诈的可能性高十倍。这极大地减少了维度,同时最大限度地提高了信息密度。
优势和关键危险
目标编码的优势很明显:它通过用一个强大的密集特征替换数千个稀疏列来解决高基数问题。
然而,这种方法通常被称为“最危险的编码技术”,因为它极易受到目标泄露的影响。
当您无意中在训练数据中包含了在预测时将不可用的信息时,就会发生目标泄露,导致模型性能被人为地完美(且无用)。
致命错误: 如果您使用所有数据(包括当前正在编码的行)来计算迈阿密的平均欺诈率,那么您就在泄露答案。模型学习了编码特征与目标变量之间的完美相关性,本质上是记住了训练数据,而不是学习可推广的模式。当部署到新的、看不见的数据上时,模型将惨败。
防止泄露
要安全地使用目标编码,您必须确保用于生成行特征值的目标值不包含该行本身的目标值。这需要先进的技术:
- 交叉验证 (K 折): 最稳健的方法是使用交叉验证方案。您将数据分成 K 个折叠。在对一个折叠(“保留集”)进行编码时,您仅使用来自其他 K-1 个折叠(“训练集”)中的数据来计算目标均值。这确保了特征是从折叠外数据生成的。
- 平滑处理: 对于数据点很少的类别,计算出的均值可能不稳定。平滑处理用于将稀有类别的均值“收缩”到目标变量的全局平均值,使特征更加稳健。一种常见的平滑公式通常涉及根据样本量加权类别均值和全局均值。
实现与代码解释
实现安全的、目标编码通常需要自定义函数或像 category_encoders 这样的高级库,因为 scikit-learn 的核心工具没有提供内置的泄露保护。关键原则是在主要编码数据之外计算均值。
为了演示,我们使用一个概念性示例,重点关注计算结果:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
import pandas as pd
# Sample data
data = pd.DataFrame({
'City': ['Miami', 'Boston', 'Miami', 'Boston', 'Boston', 'Miami'],
# Target (Y): 1 = Fraud, 0 = Legitimate
'Fraud_Target': [1, 0, 1, 0, 0, 0]
})
# 1. Calculate the raw mean (for demonstration only — this is UNSAFE leakage)
# Real-world use requires out-of-fold means for safety!
mean_encoding = data.groupby('City')['Fraud_Target'].mean().reset_index()
mean_encoding.columns = ['City', 'City_Encoded_Value']
# 2. Merge the encoded values back into the original data
df_encoded = data.merge(mean_encoding, on='City', how='left')
# Output the calculated means for illustration
miami_mean = df_encoded[df_encoded['City'] == 'Miami']['City_Encoded_Value'].iloc[0]
boston_mean = df_encoded[df_encoded['City'] == 'Boston']['City_Encoded_Value'].iloc[0]
print(f"Miami Encoded Value: {miami_mean:.4f}")
print(f"Boston Encoded Value: {boston_mean:.4f}")
print("\nFinal Encoded Data (Conceptual Leakage Example):\n", df_encoded)
|
在此概念示例中,“迈阿密”有三条记录,目标值为 [1, 1, 0],平均值为 0.6667。“波士顿”有三条记录 [0, 0, 0],平均值为 0.0000。原始的城市名称被这些浮点值所取代,极大地增强了特征的预测能力。要在一个真实项目中使用它,City_Encoded_Value 将需要...
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区