



📢 转载信息
原文链接:https://blogs.nvidia.com/blog/open-source-ai-week/
原文作者:Anish Maddipoti
随着开放源代码AI周临近尾声,我们庆祝推动开源AI向前发展的创新、协作和社区精神。请关注本周的亮点,并期待下周在NVIDIA GTC 华盛顿特区的更多公告。
总结一周的开源动量 🔗
从PyTorch大会的讲台到开放源代码AI周的研讨会,本周聚焦于定义开放AI未来的创造力和进步。
以下是本次活动的一些亮点:

表彰开源贡献: 英伟达资深深度学习框架工程师Jonathan Dekhtiar荣获PyTorch贡献者奖,以表彰他在设计支持GPU加速计算的Python软件和库的发布机制和打包解决方案方面所发挥的关键作用。

Modular 首席执行官参观英伟达展台: Modular 首席执行官、开源LLVM编译器基础设施项目的创始人和首席架构师Chris Lattner正在领取NVIDIA DGX Spark。
与fast.ai创始研究员的七个问题: fast.ai创始研究员、普及深度学习的倡导者Jeremy Howard分享了他对开源AI未来的见解。
在PyTorch大会的主题演讲中,Howard还强调了开源社区日益增强的实力,并赞扬英伟达在推进公开可用、高性能AI模型方面的领导地位。
他说:“有一家公司脱颖而出,比其他公司高出一大截,实际上是两家。” “一家是Meta…… PyTorch的创造者。另一家是英伟达,它在最近几个月创建了一些世界上最好的模型——而且它们是开源的、采用开放许可的。”
vLLM 为 NVIDIA Nemotron 模型添加上游支持 🔗
开源创新正在加速。英伟达与vLLM团队正在合作,将vLLM的上游支持添加到NVIDIA Nemotron 模型中,通过闪电般的性能、高效的扩展以及跨NVIDIA GPU的简化部署,革新开放式大型语言模型服务。
vLLM的优化推理引擎使开发人员能够运行Nemotron模型,例如新的Nemotron Nano 2——一个具有混合Transformer-Mamba架构和可配置思考预算的高效小型语言推理模型。
了解更多关于vLLM如何加速开放模型创新。
英伟达扩大对 Nemotron RAG 模型的开放访问 🔗
英伟达正在Hugging Face上开放八个NVIDIA Nemotron RAG模型,将访问范围从研究扩展到包括全套商用模型。
此次发布为开发人员提供了更广泛的工具集,用于构建检索增强生成(RAG)系统、提高搜索和排序准确性,以及从复杂文档中提取结构化数据。
新发布的模型包括Llama-Embed-Nemotron-8B,它基于Llama 3.1,提供多语言文本嵌入;以及Omni-Embed-Nemotron-3B,它支持文本、图像、音频和视频的跨模态检索。
开发人员还可以访问六个用于文本嵌入、重排序和PDF数据提取的生产级模型——这些是实际检索和文档智能应用的 关键组成部分。
借助这些开源模型,开发人员、研究人员和组织可以更轻松地集成和试验基于RAG的系统。
开发人员可以在Hugging Face上开始使用Nemotron RAG。
利用最新的开放数据集构建和训练AI模型 🔗
英伟达正在扩大对高质量开放数据集的访问权限,帮助开发人员克服大规模数据收集的挑战,从而专注于构建先进的AI系统。
最新的发布包括一系列用于主权AI的Nemotron-Personas数据集。每个数据集都是完全合成的,以真实的人口统计、地理和文化数据为基础——不包含任何个人身份信息。这个不断增长的集合,包含了来自美国、日本和印度的人格画像,使模型构建者能够设计出反映其所服务国家语言、社会和情境细微差别的AI代理和系统。
英伟达今年早些时候在Hugging Face上发布了NVIDIA 物理AI开放数据集,其中包含超过700万个机器人轨迹和1,000个OpenUSD SimReady资产。这些数据集已被下载超过600万次,它结合了来自NVIDIA Cosmos、Isaac、DRIVE和Metropolis平台的真实和合成数据,以启动物理AI开发。
英伟达 Inception 初创公司凸显AI创新 🔗

在PyTorch大会的初创企业展示环节,11家初创公司——包括英伟达Inception计划的成员——正在分享他们开发实用AI应用的工作,并与投资者、潜在客户和同行建立联系。
Runhouse,一家优化模型部署和编排的AI基础设施初创公司,荣获2025年PyTorch初创企业展示奖。社区选择奖授予了CuraVoice,其首席执行官Sakhi Patel、首席技术官Shrey Modi和顾问Rahul Vishwakarma代表团队领奖。
CuraVoice为医疗保健学生和专业人士提供了一个由NVIDIA Riva(用于语音识别和文本到语音)和NVIDIA NeMo(用于对话式AI模型)驱动的AI语音模拟平台,提供互动练习和自适应反馈,以提高患者沟通技巧。

除了CuraVoice之外,其他Inception成员,包括Backfield AI、Graphsignal、Okahu AI、Snapshot AI和XOR,也是初创企业展示环节的特色参与者。
Snapshot AI利用递归检索增强生成(RAG)、Transformer和多模态AI,为工程团队提供可操作的实时见解。该公司的平台利用NVIDIA CUDA Toolkit以规模化提供高性能分析和快速洞察。
XOR是一家网络安全初创公司,提供AI代理,可以自动修复其他AI供应链中的漏洞。该公司帮助企业在满足监管要求的同时消除漏洞。XOR的代理技术使用NVIDIA cuVS向量搜索进行索引、实时检索和代码分析。该公司还使用基于GPU的机器学习来训练模型,以检测隐藏的后门模式并优先考虑高价值的安全成果。

开放源代码AI周亮点 🔗
开放源代码AI周的与会者正在一睹塑造开放技术未来的最新进展和创新项目。
以下是现场发生的事情一览:
世界上最小的AI超级计算机: NVIDIA DGX Spark代表了企业和研究应用AI计算硬件的前沿技术。

近距离接触人形机器人和机器狗: Unitree 机器人正在展出,以由最新机器人技术驱动的先进移动性吸引与会者。
为什么开源很重要: 了解开源如何赋能开发人员构建更强大的社区、迭代功能,并无缝集成最佳的开源AI。
通过开放模型加速AI研究 🔗
今天发布的一项来自乔治城大学安全与新兴技术中心(CSET)的研究表明,开放模型权重如何为全球研究社区解锁更多实验、定制和协作的机会。
该报告概述了开放模型正在发挥作用的七个高影响力研究用例——包括微调、持续预训练、模型压缩和可解释性。
通过访问权重,开发人员可以为新领域调整模型,探索新架构,并扩展功能以满足其特定需求。这也有助于建立信任和可复现性。当团队可以在自己的硬件上运行实验、分享更新和回顾早期版本时,他们就能获得对其结果的控制和信心。
此外,研究发现,几乎所有开放模型用户都会共享他们的数据、权重和代码,从而建立起一个快速发展的协作文化。这种工具和知识的开放交流加强了学术界、初创企业和企业之间的伙伴关系,促进了创新。
英伟达致力于通过NVIDIA Nemotron系列开放模型来赋能研究界——不仅提供开放权重,还提供预训练和后训练数据集、详细的训练方案以及分享最新突破的研究论文。
阅读完整的CSET研究,了解开放模型如何帮助AI社区向前发展。
通过开源创新推进具身智能 🔗

在PyTorch大会上,英伟达机器人技术总监兼杰出研究科学家Jim Fan讨论了“物理图灵测试”——一种衡量智能机器在物理世界中性能的方法。
随着对话式AI现在能够进行流畅、逼真的交流,Fan指出,下一个挑战是让机器能够以类似的自然性进行操作。物理图灵测试提出了这样一个问题:一个智能机器能否如此流畅地完成一项现实世界任务,以至于人类无法分辨是人还是机器人完成的?
Fan强调,具身智能和物理AI的进步取决于生成大量的多样化数据、获取开放机器人基础模型和仿真框架——并概述了一个用于开发具身AI的统一工作流程。
通过像NVIDIA Isaac GR00T-Dreams这样的合成数据工作流程——它建立在NVIDIA Cosmos世界基础模型之上——开发人员可以从图像和提示中生成虚拟世界,从而加快创建大规模、多样化且物理准确的数据集。
然后,这些数据可用于后训练NVIDIA Isaac GR00T N开放基础模型,以实现通用人形机器人推理和技能。但在模型部署到现实世界之前,这些新的机器人技能需要在仿真中进行测试。
像NVIDIA Isaac Sim和Isaac Lab这样的开放仿真和学习框架允许机器人在真实世界运行之前,在数百万个虚拟环境中进行无数次的“练习”,从而极大地加速学习和部署周期。
此外,借助Newton——一个基于NVIDIA Warp和OpenUSD构建的开源、可微分物理引擎——开发人员可以将高保真仿真引入复杂的机器人动力学,如运动、平衡和接触,从而缩小仿真到现实的差距。
这加速了物理能力强的AI系统的创建,这些系统学习更快、运行更安全,并在现实环境中有效运行。
然而,扩展具身智能不仅仅是计算问题——它是关于访问权。Fan重申了英伟达对开源的承诺,强调公司如何共享其框架和基础模型,以赋能全球的开发人员和研究人员。
开发人员可以在Hugging Face上开始使用英伟达的开放具身和物理AI模型。
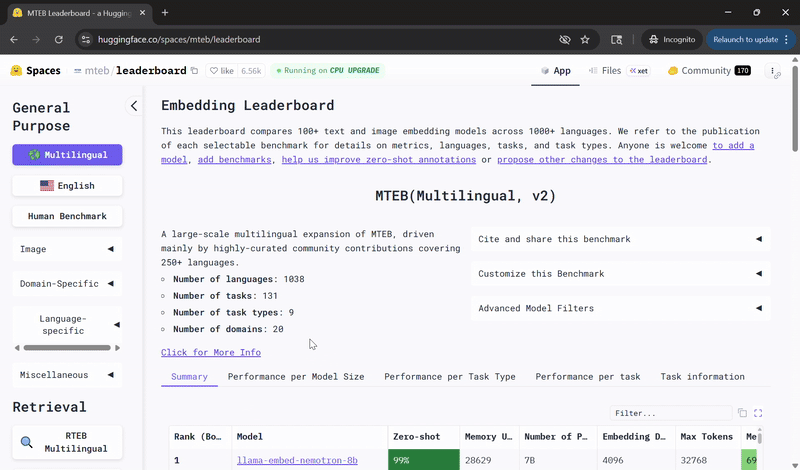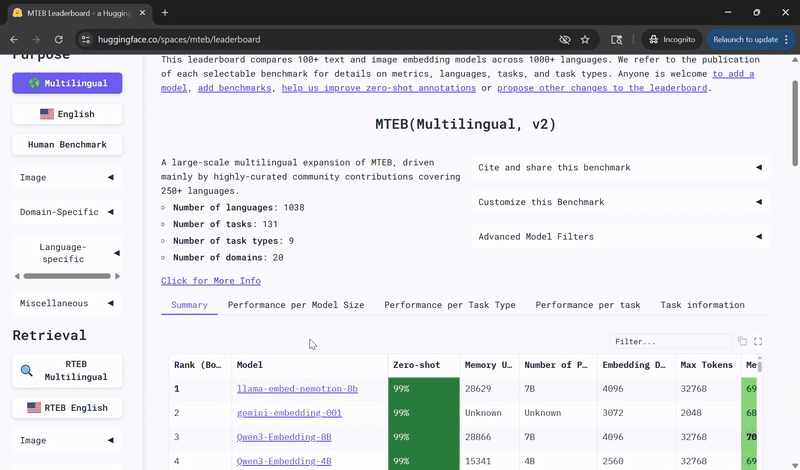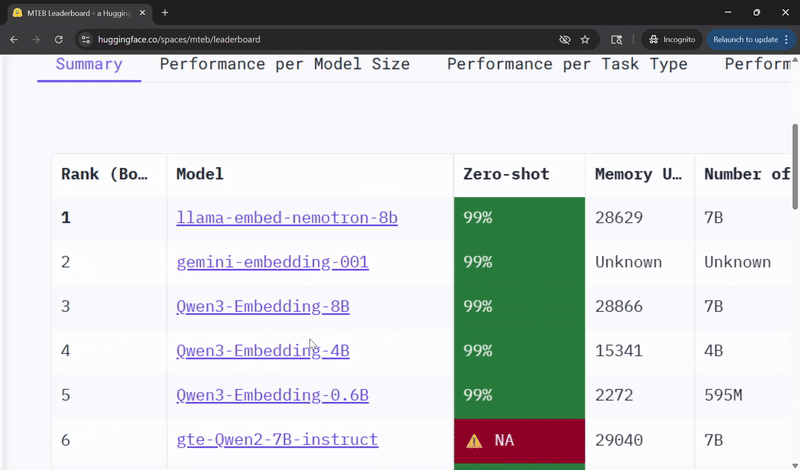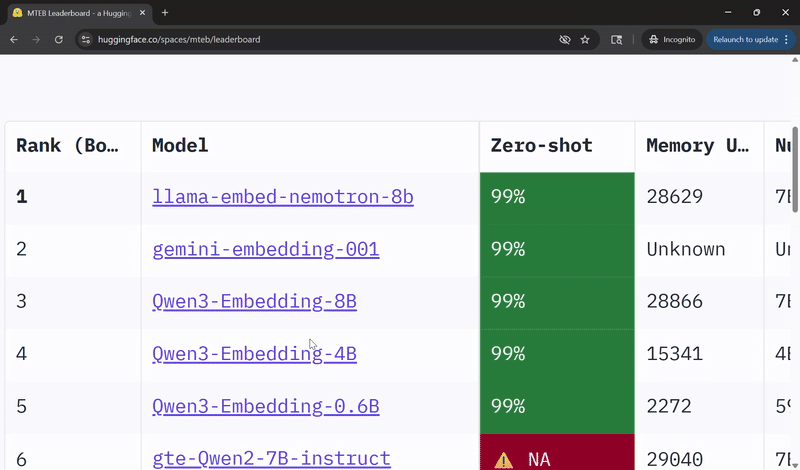
Llama‑Embed‑Nemotron‑8B 在多语言检索的开放模型中名列前茅 🔗
英伟达的Llama‑Embed‑Nemotron‑8B模型在多语言文本嵌入基准测试排行榜上被评为排名第一的开放且可移植的模型。
Llama‑Embed‑Nemotron‑8B基于meta‑llama/Llama‑3.1‑8B架构,是一个研究性文本嵌入模型,可将文本转换为4,096维的向量表示。它专为灵活性而设计,支持广泛的用例,包括超过1000种语言的检索、重排序、语义相似性和分类。
该模型在一个包含1600万个查询-文档对(一半来自公共来源,一半为合成生成)的多样化集合上进行训练,受益于精炼的数据生成技术、硬负例挖掘和模型合并方法,这些都有助于其广泛的泛化能力。
这一成果建立在英伟达在开放、高性能AI模型方面的持续研究之上。在Llama NeMo Retriever ColEmbed模型早前获得排行榜认可之后,Llama‑Embed‑Nemotron‑8B的成功凸显了在推进面向开发人员社区的AI方面,开放性、透明度和协作的价值。
在Hugging Face上查看Llama-Embed-Nemotron-8B,并了解更多关于该模型的信息,包括架构亮点、训练方法和性能评估。
开放源代码教会我们如何改进AI
开放模型正在塑造AI的未来,使开发人员、企业和政府能够以透明、可定制和可信赖的方式进行创新。在最新一期的NVIDIA AI播客中,英伟达的Bryan Catanzaro和Jonathan Cohen讨论了开放模型、数据集和研究如何为整个AI生态系统的共同进步奠定基础。
NVIDIA Nemotron系列开放模型代表了AI开发的完整堆栈方法,将模型设计与驱动它的底层硬件和软件连接起来。通过公开发布Nemotron模型、数据和训练方法,英伟达旨在帮助他人改进、适应和构建在其工作之上,从而实现更快速的思想交流和更高效的系统。
Catanzaro在播客中说:“当我们作为一个社区聚集在一起——贡献想法、数据和模型时——我们所有人都进步得更快。” “开放技术使这一切成为可能。”
本周在开放源代码AI周还有更多活动,包括PyTorch大会的开始——汇集了推动开放AI界限的开发人员、研究人员和创新者。
与会者可以收听英伟达机器人技术总监兼杰出研究科学家Jim Fan的特别主题演讲,了解机器人技术的最新进展——从仿真和合成数据到加速计算。本次主题演讲题为“物理图灵测试:解决通用机器人技术问题”,将于太平洋时间周三(10月22日)上午9:50至10:05举行。
Andrej Karpathy 的 Nanochat 教会开发者如何在四小时内训练 LLM 🔗
计算机科学家Andrej Karpathy最近推出了Nanochat,称其为“100美元能买到的最好的ChatGPT”。Nanochat是一个开源的全栈大型语言模型(LLM)实现,旨在实现透明度和实验性。它使用大约8000行极简、轻依赖的代码,通过一个简单的Web用户界面运行整个LLM管道——从分词和预训练到微调、推理和聊天。
英伟达通过发布两个NVIDIA Launchables来支持Karpathy的开源Nanochat项目,使开发人员可以轻松地在各种NVIDIA GPU上部署和实验Nanochat。
借助NVIDIA Launchables,开发人员只需单击一下即可在数小时内训练和交互自己的对话模型。Launchables可以动态支持不同大小的GPU——包括NVIDIA H100和L40S GPU——在各种云平台上运行,无需修改。它们还可以自动在NVIDIA Brev上的任何八GPU实例上工作,因此开发人员可以立即获得计算访问权限。
前10位用户部署这些Launchables还将免费获得NVIDIA H100或L40S GPU的计算访问权限。
通过部署Launchable开始使用Nanochat进行训练:

Andrej Karpathy 的下一批实验从 NVIDIA DGX Spark 开始
今天,Karpathy 收到了一台NVIDIA DGX Spark——这是世界上最小的AI超级计算机,旨在将Blackwell的强大能力直接带到开发人员的桌面上。DGX Spark 采用紧凑的外形设计,提供高达每秒浮点运算(petaflop)的AI处理能力和128GB的统一内存,赋能像Karpathy这样的创新者在本地进行实验、微调和运行大型模型。
利用 PyTorch 和 NVIDIA 构建 AI 的未来 🔗
PyTorch是增长最快的AI框架,其性能来源于NVIDIA CUDA平台,并使用Python编程语言来释放开发者的生产力。今年,英伟达向CUDA平台添加了Python作为一等语言,使PyTorch开发者社区能更方便地访问CUDA。
CUDA Python包含了使Python中的GPU加速变得前所未有的简单的关键组件,内置支持内核融合、扩展模块集成以及用于快速部署的简化打包。
遵循PyTorch的开放协作模式,CUDA Python可在GitHub和PyPI上获取。

每月全球开发人员都会下载数亿个英伟达库——包括CUDA、cuDNN、cuBLAS和CUTLASS——其中大部分在Python和PyTorch环境中。CUDA Python提供了nvmath-python,这是一个充当Python代码与这些高度优化GPU库之间桥梁的新库。
此外,内核增强和对下一代框架的支持,使NVIDIA加速计算更高效、更灵活和更易于普及。
英伟达通过开源贡献和技术领导力,与PyTorch社区保持着长期合作关系,并通过赞助和参与社区活动来深化合作。
在2025年旧金山PyTorch大会上,英伟达将举办一次主题演讲、五场技术会议和九个海报演示。
英伟达将在开放源代码AI周现场。请继续关注,我们将庆祝推动开源AI向前发展的创新、协作和社区精神。请在社交媒体上关注NVIDIA AI Developer以获取更多新闻和见解。
英伟达聚焦开源创新 🔗
开放源代码AI周于周一开始,举办一系列黑客马拉松、研讨会和见面会,聚焦AI、机器学习和开源创新的最新进展。
本次活动汇集了领先的组织、研究人员和开源社区,共同分享知识、协作开发工具,并探讨开放性如何加速AI发展。
英伟达通过提供旨在赋能开发人员的开源工具、模型和数据集,持续扩大对先进AI创新的访问权限。目前,英伟达在NVIDIA GitHub仓库中拥有超过1000个开源工具,在NVIDIA Hugging Face集合中拥有超过500个模型和100个数据集,正在加速开放、协作的AI开发步伐。
在过去的一年里,英伟达已成为Hugging Face仓库的最大贡献者,这反映了其对分享模型、框架和研究以赋能社区的坚定承诺。
开放的模型、工具和数据集对于推动创新和进步至关重要。通过赋能任何人使用、修改和共享技术,可以促进透明度并加速发现,从而带来有利于行业和社区的突破。这就是为什么英伟达致力于支持开源生态系统。
我们将全周保持现场报道——请继续关注,我们将庆祝推动开源AI向前发展的创新、协作和社区精神,其中PyTorch大会是旗舰活动。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区