



📢 转载信息
原文作者:Josh Longenecker and Mohammad Tahsin
尽管强大的大型语言模型(LLM)可以通过 API 调用变得非常容易集成到应用程序中,但仍有相当数量的企业选择自托管自己的模型。这样做需要承担基础设施管理、服务堆栈中 GPU 的成本以及保持模型更新的挑战。选择自托管通常是出于两个 API 无法解决的关键因素。首先是数据主权:无论是因为监管要求、竞争考虑还是与客户的合同义务,都需要确保敏感信息不会离开基础设施。其次是模型定制:能够根据专有数据集对模型进行微调,以适应行业特定的术语和工作流程,或创建通用 API 无法提供的专业功能。
Amazon SageMaker AI 通过抽象化操作负担来解决自托管的基础设施复杂性。通过托管端点,SageMaker AI 负责 GPU 资源的预配、扩展和监控,使团队能够专注于模型性能而非基础设施管理。该系统提供了带有流行框架(如 vLLM)的推理优化容器,预先配置以实现最大吞吐量和最小延迟。例如,大型模型推理(LMI)v16 容器镜像使用了 vLLM v0.10.2,它使用 V1 引擎并支持新的模型架构和新的硬件,例如 Blackwell/SM100 一代。这种托管方法将通常需要专门的机器学习运维(MLOps)专业知识的部署过程,转变为只需几行代码即可完成的部署过程。
即使在使用这些托管容器时,实现最佳性能也需要仔细的配置。诸如张量并行度、批处理大小、最大序列长度和并发限制等参数会急剧影响延迟和吞吐量,而为特定工作负载和成本限制找到正确的平衡是一个迭代过程,可能非常耗时。
BentoML 的 LLM-Optimizer 通过实现跨不同参数配置的系统化基准测试来解决这一挑战,用自动搜索过程取代了手动试错。该工具允许您定义约束,例如特定的延迟目标或吞吐量要求,从而可以轻松识别满足服务水平目标(SLO)的配置。您可以使用 LLM-Optimizer 在本地或开发环境中为 vLLM 查找最佳服务参数,然后将相同的配置直接应用于 SageMaker AI 端点,从而无缝过渡到生产环境。本文通过在 Amazon SageMaker AI 端点上查找 Qwen-3-4B 模型的最佳部署来说明这一过程。
本文面向已经将模型部署在 Amazon SageMaker 或类似基础设施上的实践中的 ML 工程师、解决方案架构师和系统构建者。我们假设您熟悉 GPU 实例、端点和模型服务,并专注于实际的性能优化。对推理指标的解释并非作为初学者教程,而是为了建立共同的直觉,特别是关于批处理大小和张量并行度等特定参数,以及它们如何直接影响生产中的成本和延迟。
解决方案概述
分步细分如下:
- 在 Jupyter Notebook 中定义约束: 过程从 SageMaker AI Studio 内开始,用户打开一个 Jupyter Notebook 来定义用例的部署目标和约束。这些约束可以包括目标延迟、所需的吞吐量和输出令牌数。
- 使用 BentoML LLM-Optimizer 运行理论和实证基准测试: LLM-Optimizer 首先运行理论 GPU 性能估算,以识别所选硬件(在本例中为
ml.g6.12xlarge)的可行配置。它使用 vLLM 服务引擎跨多种参数组合(如张量并行度、批处理大小和序列长度)执行基准测试,以实证衡量延迟和吞吐量。基于这些基准测试,优化器会自动确定满足所提供约束的最有效服务配置。 - 生成优化的配置并在 SageMaker 端点中部署: 基准测试完成后,优化器会返回一个包含最佳参数值的 JSON 配置文件。此 JSON 从 Jupyter Notebook 传递到 SageMaker 端点配置,后者使用最佳运行时参数以托管 HTTP 端点形式部署 LLM(在本例中,使用基于 vLLM 的 LMI 容器的
Qwen/Qwen3-4B模型)。
下图是贯穿本文的工作流程概述。
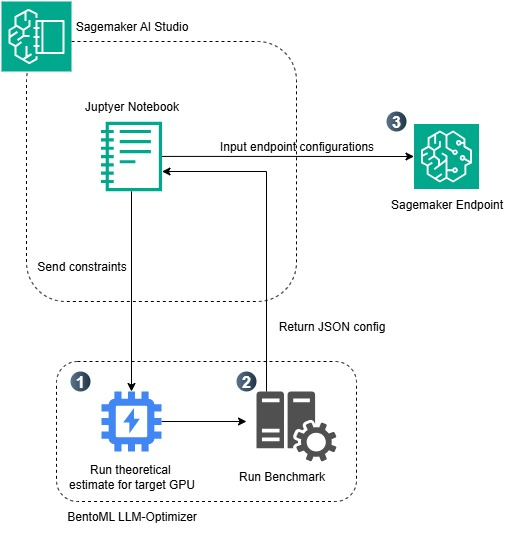
在深入研究推理优化的理论基础之前,值得说明这些概念在实际部署中的重要性。当团队从基于 API 的模型转向自托管端点时,他们就继承了调整性能参数的责任,这些参数直接影响成本和用户体验。通过 GPU 架构和算术强度来理解延迟和吞吐量如何相互作用,使工程师能够有意识地进行这些权衡,而不是通过反复试验。
LLM 性能简要概述
在深入了解此工作流程的实际应用之前,我们介绍一些关键概念,以帮助理解为什么推理优化对 LLM 驱动的应用程序至关重要。以下入门知识不是学术性的,而是为了提供解释 LLM-Optimizer 输出和理解为什么某些配置能产生更好结果所需的思维模型。
关键性能指标
吞吐量(请求/秒):您的系统每秒完成的请求数。更高的吞吐量意味着可以同时为更多用户提供服务。
延迟(秒):从请求到达直到返回完整响应的总时间。更低的延迟意味着更快的用户体验。
算术强度:执行的计算与移动的数据的比率。这决定了您的工作负载是:
- 内存受限:受数据移动速度限制(低算术强度)
- 计算受限:受原始 GPU 处理能力限制(高算术强度)
吞吐量-延迟权衡
在实践中,优化 LLM 推理遵循一个基本权衡:随着吞吐量的增加,延迟也会增加。这是因为:
- 更大的批处理大小 → 一起处理的请求更多 → 吞吐量更高
- 更多的并发请求 → 更长的队列等待时间 → 延迟更高
- 张量并行 → 将模型分布到 GPU 上 → 以不同方式影响这两个指标
挑战在于跨多个相互依赖的参数找到最佳配置:
- 张量并行度(使用多少个 GPU)
- 批处理大小(一起处理的最大令牌数)
- 并发限制(同时进行的请求最大数量)
- KV 缓存分配(注意力状态的内存)
每个参数以不同的方式影响吞吐量和延迟,同时尊重 GPU 内存和计算带宽等硬件限制。这个多维度的优化问题正是 LLM-Optimizer 有价值的原因——它系统地探索配置空间,而不是依赖于手动反复试验。

有关 LLM 推理的整体概述,BentoML 在其 LLM 推理手册中提供了宝贵的资源。
实际应用:在 Amazon SageMaker AI 上查找 Qwen3-4B 的最佳部署
在接下来的部分中,我们将分步介绍识别和应用 LLM 部署的最佳服务配置的过程。具体来说,我们:
- 使用 vLLM 在
ml.g6.12xlarge实例(每台 4 个 NVIDIA L4 GPU,24GB VRAM)上部署Qwen/Qwen3-4B模型。 - 定义现实的工作负载约束:
- 目标:每秒 10 个请求 (RPS)
- 输入长度:1024 个令牌
- 输出长度:512 个令牌
- 探索多种服务参数组合:
- 张量并行度(1、2 或 4 个 GPU)
- 最大批处理令牌数(4K、8K、16K)
- 并发级别(32、64、128)
- 使用以下方法分析结果:
- 理论 GPU 内存计算
- 基准测试数据
- 吞吐量与延迟的权衡
最后,您将看到理论分析、实证基准测试和托管端点部署如何协同工作,以提供一个平衡延迟、吞吐量和成本的、可用于生产的 LLM 设置。
先决条件
运行此示例所需的先决条件如下:
- 对 SageMaker Studio 的访问权限。这使得部署和推理变得简单,或者像 PyCharm 或 Visual Studio Code 这样的交互式开发环境(IDE)。
- 要对模型进行基准测试和部署,请检查推荐的实例类型是否可用,具体取决于模型大小。要验证所需的 服务配额,请完成以下步骤:
- 在“服务配额”控制台中,在AWS 服务下,选择Amazon SageMaker。
- 验证所需实例类型用于“端点部署”的配额是否充足(在正确的区域)。
- 如有需要,请求配额增加/联系 AWS 支持。
以下代码详细说明了如何安装必要的包:
pip install vllm
pip install git+https://github.com/bentoml/llm-optimizer.git 运行 LLM-Optimizer
要开始使用,必须根据目标工作负载定义示例约束。
示例约束:
- 输入令牌:1024
- 输出令牌:512
- 端到端延迟:<= 60 秒
- 吞吐量:>= 5 RPS
运行估算
使用 llm-optimizer 的第一步是运行估算。运行估算会分析 4x L4 GPU 上的 Qwen/Qwen3-4b 模型,并估算输入长度为 1024 个令牌、输出为 512 个令牌的性能。运行后,会通过数学计算出延迟和吞吐量的理论最佳值并返回。返回的屋顶线分析确定了工作负载的瓶颈,并返回了许多服务器和客户端参数,供下一步运行实际基准测试使用。
在底层,LLM-Optimizer 执行屋顶线分析来估算 LLM 服务性能。它首先从 HuggingFace 获取模型架构,以提取隐藏维度、层数、注意力头数和总参数等参数。利用这些架构细节,它计算预填充(处理输入令牌)和解码(生成输出令牌)阶段所需的理论 FLOPs,同时考虑注意力操作、MLP 层和 KV 缓存访问模式。它将每个阶段的算术强度(每字节移动的 FLOPs)与 GPU 的硬件特性(特别是计算能力(TFLOPs)与内存带宽(TB/s)的比率)进行比较,以确定预填充和解码是内存受限还是计算受限。通过这种分析,该工具可以估算在不同并发级别下的 TTFT(首次令牌时间)、ITL(令牌间延迟)和端到端延迟。它还计算三个理论并发限制:KV 缓存内存容量、预填充计算能力和解码吞吐量能力。最后,它生成用于经验性基准测试的调整命令,以跨越不同的张量并行配置、批处理大小和并发级别进行扫描,以验证理论预测。
以下代码详细说明了如何根据所选约束运行初始估算:
llm-optimizer estimate \
--model Qwen/Qwen3-4B \
--input-len 1024 \
--output-len 512 \
--gpu L40 \
--num-gpus 4预期输出:
Auto-detected 4 GPU(s)
💡 Inferred precision from model config: bf16 === Configuration ===
Model: Qwen/Qwen3-4B
GPU: 4x L40
Precision: bf16
Input/Output: 1024/512 tokens
Target: throughput Fetching model configuration...
Model: 3668377600.0B parameters, 36 layers === Performance Analysis ===
Best Latency (concurrency=1):
TTFT: 16.8 ms
ITL: 1.4 ms
E2E: 0.72 s Best Throughput (concurrency=1024):
Output: 21601.0 tokens/s
Input: 61062.1 tokens/s
Requests: 24.71 req/s
Bottleneck: Memory === Roofline Analysis ===
Hardware Ops/Byte Ratio: 195.1 ops/byte
Prefill Arithmetic Intensity: 31846.2 ops/byte
Decode Arithmetic Intensity: 31.1 ops/byte
Prefill Phase: Compute Bound
Decode Phase: Memory Bound === Concurrency Analysis ===
KV Cache Memory Limit: 1258 concurrent requests
Prefill Compute Limit: 21 concurrent requests
Decode Capacity Limit: 25 concurrent requests
Theoretical Overall Limit: 21 concurrent requests
Empirical Optimal Concurrency: 16 concurrent requests === Tuning Commands === --- VLLM ---
Simple (concurrency + TP/DP):
llm-optimizer --framework vllm --model Qwen/Qwen3-4B --gpus 4 --host 127.0.0.1 --server-args "tensor_parallel_size*data_parallel_size=[(1, 4), (2, 2), (4, 1)]" --client-args "dataset_name=random;random_input_len=1024;random_output_len=512;random_range_ratio=0.95;num_prompts=3072;max_concurrency=[512, 1024, 1536]" --output-dir tuning_results --output-json tuning_results/config_1_vllm.json
Advanced (additional parameters):
llm-optimizer --framework vllm --model Qwen/Qwen3-4B --gpus 4 --host 127.0.0.1 --server-args "tensor_parallel_size*data_parallel_size=[(1, 4), (2, 2), (4, 1)];max_num_batched_tokens=[16384, 24576, 32768]" --client-args "dataset_name=random;random_input_len=1024;random_output_len=512;random_range_ratio=0.95;num_prompts=3072;max_concurrency=[512, 1024, 1536]" --output-dir tuning_results --output-json tuning_results/config_1_vllm.json运行基准测试
在获得估算输出后,可以根据先前定义的约束对要用于基准测试的参数做出明智的决定。在底层,LLM-Optimizer 从理论估算过渡到实证验证,它启动一个分布式基准测试循环,以评估目标硬件上的实际服务性能。对于服务器和客户端参数的每一种排列,该工具都会自动使用指定的张量并行度、批处理大小和令牌限制启动一个 vLLM 实例,然后使用合成或基于数据集的请求生成器(例如 ShareGPT)驱动负载。每次运行都会捕获低级别指标——首次令牌时间 (TTFT)、令牌间延迟 (ITL)、端到端延迟、每秒令牌数和 GPU 内存利用率——跨越并发请求模式。将这些测量结果汇总到帕累托前沿(Pareto frontier),使 LLM-Optimizer 能够在用户的约束范围内识别出在延迟和吞吐量之间取得最佳平衡的配置。本质上,此步骤将早期的理论屋顶线分析与真实性能数据相结合,产生直接影响部署调优的可重现指标。
以下代码运行基准测试,使用了来自估算的信息:
llm-optimizer \
--framework vllm \
--model Qwen/Qwen3-4B \
--server-args "tensor_parallel_size=[1,2,4];max_num_batched_tokens=[4096,8192,16384]" \
--client-args "max_concurrency=[32,64,128];num_prompts=1000;dataset_name=sharegpt" \
--output-json vllm_results.json此命令会输出以下排列到 vLLM 引擎中进行测试。以下是对基准测试运行的不同客户端和服务器参数组合的简单计算:
- 3 个
tensor_parallel_sizex 3 个max_num_batched_tokens设置 = 9 - 3 个
max_concurrencyx 1 个num prompts= 3 - 9 * 3 = 27 种不同的测试
完成后,将生成三个工件:
- 包含结果帕累托仪表板的 HTML 文件: 一个交互式可视化,突出显示跨经过测试的配置的延迟和吞吐量之间的权衡。
- 总结基准测试结果的 JSON 文件: 这个紧凑的输出汇总了每个测试排列的关键性能指标(例如,延迟、吞吐量、GPU 利用率),用于程序化分析或下游自动化。
- 包含单个基准测试运行完整记录的 JSONL 文件: 每一行代表一种配置了详细元数据的单个测试配置,便于进行细粒度检查、过滤或自定义绘图。
示例基准测试记录输出:
{"config": {"client_args": {"max_concurrency": 32, "num_prompts": 1000, "dataset_name": "sharegpt"}, "server_args": {"tensor_parallel_size": 4, "max_num_batched_tokens": 8192}, "server_cmd_args": ["--tensor-parallel-size=4", "--max-num-batched-tokens=8192"]}, "results": {"backend": "vllm", "dataset_name": "sharegpt", "max_concurrency": 32, "duration": 178.69010206999883, "completed": 1000, "total_input_tokens": 302118, "total_output_tokens": 195775, "total_output_tokens_retokenized": 195764, "request_throughput": 5.5962808707125085, "input_throughput": 1690.7371840979215, "output_throughput": 1095.6118874637414, "mean_e2e_latency_ms": 5516.473195931989, "median_e2e_latency_ms": 3601.3218250000136, "std_e2e_latency_ms": 6086.249975393793, "p95_e2e_latency_ms": 17959.23558074991, "p99_e2e_latency_ms": 23288.202798799084, "mean_ttft_ms": 134.24923809297798, "median_ttft_ms": 75.87540699933015, "std_ttft_ms": 219.7887602629944, "p95_ttft_ms": 315.9690581494033, "p99_ttft_ms": 1222.5397153301492, "mean_tpot_ms": 28.140094508604655, "median_tpot_ms": 27.28665116875758, "std_tpot_ms": 7.497764233364623, "p95_tpot_ms": 36.30593537913286, "p99_tpot_ms": 48.05242155004177, "mean_itl_ms": 27.641122410215683, "median_itl_ms": 21.38108600047417, "std_itl_ms": 28.983685761892183, "p95_itl_ms": 64.98022639971161, "p99_itl_ms": 133.48110956045272, "concurrency": 30.871733420192484, "accept_length": null}, "cmd": "vllm serve Qwen/Qwen3-4B --host 127.0.0.1 --port 8000 --tensor-parallel-size=4 --max-num-batched-tokens=8192", "constraints": [], "metadata": {"gpu_type": "NVIDIA L4", "gpu_count": 4, "model_tag": "Qwen/Qwen3-4B", "input_tokens": -1, "output_tokens": -1}}解包基准测试结果后,我们可以使用各种并发级别下的 p99 端到端延迟和请求吞吐量指标来做出明智的决定。基准测试结果显示,跨可用 GPU 的张量并行度为 4 时,性能始终优于较低的并行度设置,最佳配置为 tensor_parallel_size=4、max_num_batched_tokens=8192 和 max_concurrency=128,实现了 7.51 请求/秒和 2,270 输入令牌/秒——比朴素的单 GPU 基线(2.74 req/s)提高了 2.7 倍的吞吐量。虽然此配置实现了峰值吞吐量,但在高负载下,p99 端到端延迟升高到 61.4 秒;对于延迟敏感的工作负载,最佳点是张量并行度为 4 且 max_num_batched_tokens=4096 的中等并发(32),该配置在保持低于 24 秒的 p99 延迟的同时,吞吐量仍然达到了 5.63 req/s——是基线吞吐量的两倍多。数据显示,从朴素的单 GPU 设置迁移到具有调整后批处理大小的优化 4 路张量并行,可以释放出巨大的性能提升,具体配置选择取决于部署是优先考虑最大吞吐量还是延迟保证。
为了可视化结果,LLM-Optimizer 提供了一个方便的函数来在帕累托仪表板中查看绘制的输出。可以使用以下代码行显示帕累托仪表板:
llm-optimizer visualize --data-file vllm_results.json...🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区