



📢 转载信息
原文作者:Chaim Rand, Pini Reisman, and Eliyah Weinberg
本文由 Mobileye 的首席工程师 Chaim Rand、高级软件首席工程师 Pini Reisman 和性能与技术创新工程师 Eliyah Weinberg 撰写。Mobileye 团队谨此感谢 AWS 的 Sunita Nadampalli 和 Guy Almog 对此解决方案和本文的贡献。
Mobileye 致力于通过结合开创性的人工智能、丰富的现实世界经验,以及对当今先进驾驶辅助系统 (ADAS) 和未来自动驾驶的务实愿景,推动全球向更智能、更安全的出行演进。道路体验管理™ (REM™) 是 Mobileye 自动驾驶生态系统中的一个关键组成部分。REM™ 负责创建和维护全球道路网络的极高精度的众包高清 (HD) 地图。这些地图对于以下方面至关重要:
- 精确的车辆定位
- 实时导航
- 识别道路状况的变化
- 增强整体自动驾驶能力
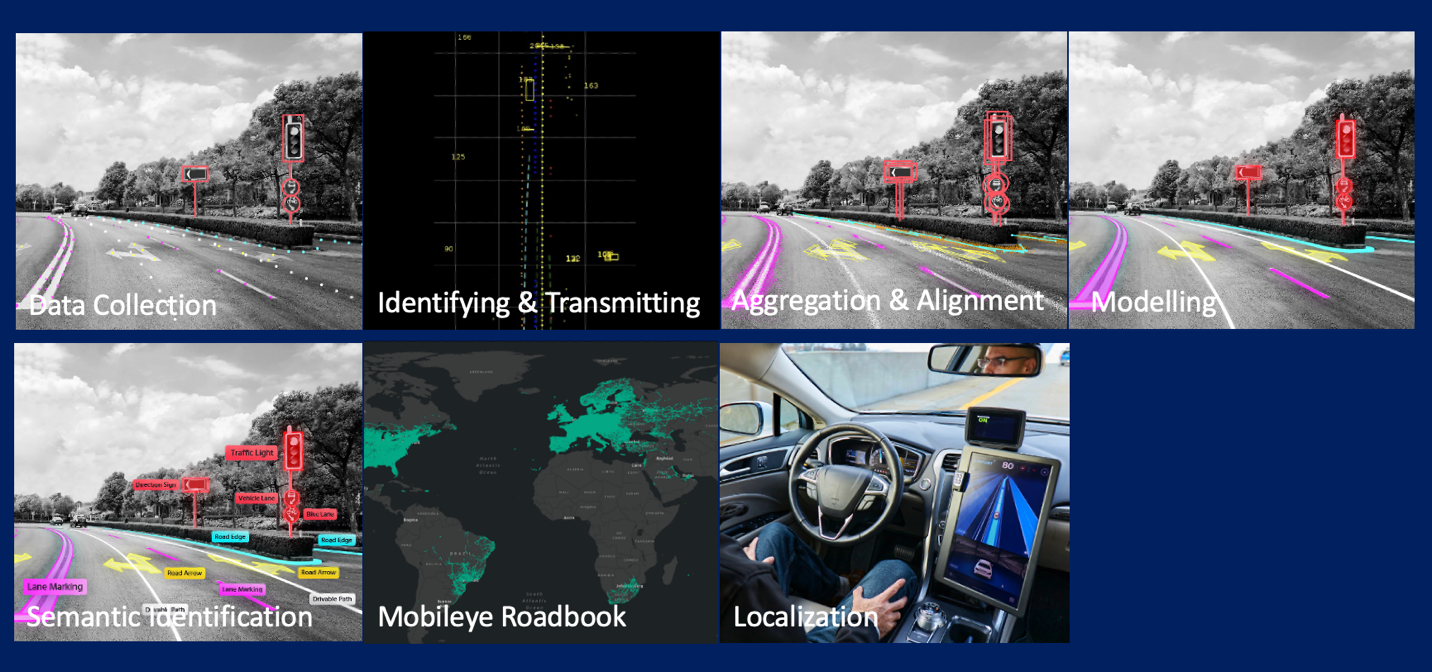
Mobileye 道路体验管理 (REM)™ (来源:https://www.mobileye.com/technology/rem/)
地图生成是一个持续的过程,需要收集和处理数百万辆配备 Mobileye 技术的车辆的数据,使其成为一项计算密集型操作,需要高效且可扩展的解决方案。
在本文中,我们将重点介绍 REM™ 系统的一部分:我们称之为 变化检测 的道路结构变化的自动识别。我们将分享我们设计和部署一个用于变化检测的解决方案的历程,该解决方案的核心是一个名为 CDNet 的深度学习模型。我们将涵盖以下几点:
- 在 GPU 与 CPU 上运行的权衡,以及我们当前的解决方案为何在 CPU 上运行。
- 使用模型推理服务器,特别是 Triton 推理服务器的影响。
- 在基于 AWS Graviton 的 Amazon Elastic Compute Cloud (Amazon EC2) 实例上运行变化检测流水线及其对部署灵活性的影响,最终实现了超过 2 倍的吞吐量提升。
我们将分享在构建和部署基于深度学习 (DL) 模型的高规模、高并行化算法流水线时做出的真实决策和权衡,重点关注效率和吞吐量。
道路变化检测
高清地图是 Mobileye 自动驾驶解决方案的众多组成部分之一,通常被自动驾驶汽车 (AV) 用于车辆定位和导航。然而,正如人类驾驶员所知,道路结构发生变化并不罕见。借用通常归功于希腊哲学家赫拉克利特的一句名言:当涉及到道路地图时——“生活中唯一不变的就是变化。” 道路变化的一个常见原因是道路施工,此时车道及其相关的车道标记可能会被添加、移除或重新定位。
对于人类驾驶员来说,道路变化可能很不方便,但通常是可控的。但对于自动驾驶汽车来说,如果没有得到妥善处理,这些变化可能会带来重大的挑战。道路变化的可能性要求 AV 系统必须以足够的冗余性和适应性进行编程。它还要求有适当的机制来尽快修改和部署更正后的 REM™ 地图。下图捕捉了 REM™ 中负责识别地图变化并(在检测到变化时)部署地图更新的变化检测子系统。
 REM™ 道路变化检测和地图更新流程
REM™ 道路变化检测和地图更新流程
变化检测在来自世界各地多个道路片段上并行且独立地运行。它由一种专有算法触发,该算法主动检查从配备 Mobileye 技术的车辆收集的数据。变化检测任务通常每天触发数百万次,其中每个任务都在单独的道路片段上运行。每个道路片段都会以最小的、预先确定的节奏进行评估。
变化检测任务的主要组成部分是 Mobileye 的专有 AI 模型 CDNet,它消耗来自多次近期驾驶的专有数据编码以及当前地图数据,并产生一系列输出,这些输出用于自动评估是否确实发生了道路变化,并确定是否需要重新制图。尽管完整的变化检测算法包含其他组件,但 CDNet 模型在计算和内存要求方面是最重的。在单个片段上运行的单个变化检测任务期间,CDNet 模型可能会被调用数十次。
优先考虑成本效率
考虑到变化检测系统的巨大规模,我们在为其部署设计解决方案时设定的首要目标是通过提高每美元完成的平均变化检测任务数量来最小化成本。这一目标优先于其他常见指标,例如最小化延迟或最大化可靠性。例如,部署解决方案的一个关键组成部分是依赖 Amazon EC2 Spot 实例 作为我们的计算资源,这最适合运行容错工作负载。在运行离线流程时,我们为实例被抢占和算法响应延迟的可能性做好了准备,以便受益于使用 Spot 实例带来的大幅折扣。正如我们将解释的那样,优先考虑成本效率是我们许多设计决策的动因。
架构解决方案
我们在设计架构时考虑了以下因素。
1. 在 CPU 而非 GPU 上运行深度学习推理
由于变化检测流水线的核心是 AI/ML 模型,最初的方法是设计一个基于使用 GPU 实例的解决方案。事实上,当我们仅隔离 CDNet 模型推理执行时,GPU 相较于 CPU 表现出了明显的优势。下表展示了 CPU 与 GPU 上 CDNet 推理的原始性能。
| 实例类型 | 每秒样本数 |
| CPU (c7i.4xlarge) | 5.85 |
| GPU (g6e.2xlarge) | 54.8 |
然而,我们很快得出结论,尽管 CDNet 推理会变慢,但在 CPU 实例上运行它可以在不影响端到端速度的情况下提高整体成本效率,原因如下:
- GPU 实例的定价通常远高于 CPU 实例。再加上由于需求量大,GPU 实例的 Spot 可用性比 CPU 实例低得多,并且遭受更频繁的 Spot 抢占。
- 虽然 CDNet 是主要组件,但变化检测算法包含许多更适合在 CPU 上运行的组件。尽管 GPU 在运行 CDNet 方面速度极快,但在变化检测流水线的大部分时间里,它将保持空闲状态,从而降低了效率。此外,在 CPU 上运行整个算法可以减少管理和在不同计算资源之间传递数据的开销(使用 CPU 实例处理非推理工作,使用 GPU 实例处理推理工作)。
对于我们最初的方法,我们设计了一个基于多核 EC2 CPU Spot 实例的自动缩放解决方案,这些实例处理从 Amazon Simple Queue Service (Amazon SQS) 流式传输的任务。随着变化检测任务的接收,它们将在一个空闲的 CPU 实例槽位上被调度、分发并在新进程中运行。实例将根据任务负载进行扩展和缩减。
下图说明了这种配置的架构。
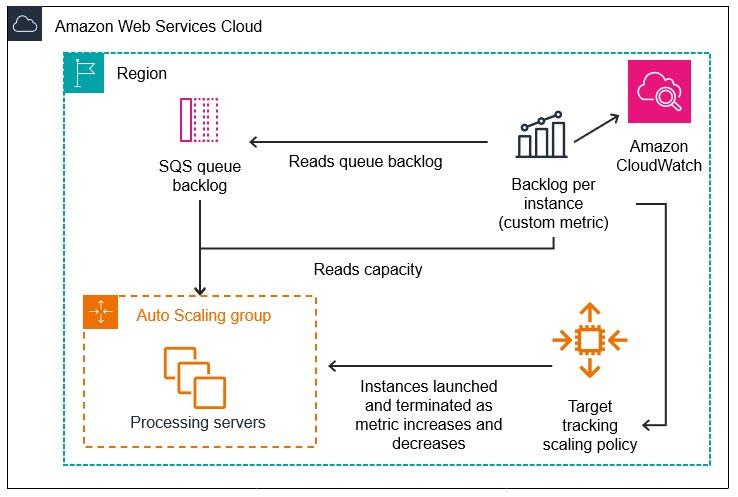
在开发这个阶段,每个进程都会加载并管理自己的 CDNet 副本。然而,这最终成为了一个重大且限制性的瓶颈。每个进程加载和运行其 CDNet 副本所需的内存资源为 8.5 GB。假设例如,我们的实例类型是具有 256 GB 内存的 r6i.8xlarge,这意味着我们仅限于每个实例运行 30 个任务。此外,我们发现变化检测任务的总时间中大约有 50% 用于下载模型权重和初始化模型。
2. 使用 Triton 推理服务器提供模型推理服务
我们应用的第一项优化是通过模型推理服务器解决方案来集中模型推理执行。每个 CPU 工作实例不再维护自己的 CDNet 副本,而是通过推理服务器加载一个 CDNet 的单个(容器化)副本,为实例上运行的变化检测进程提供服务。我们选择使用 Triton 推理服务器作为我们的推理服务器,因为它是一个开源项目,部署简单,并支持多种运行时环境和 AI/ML 框架。
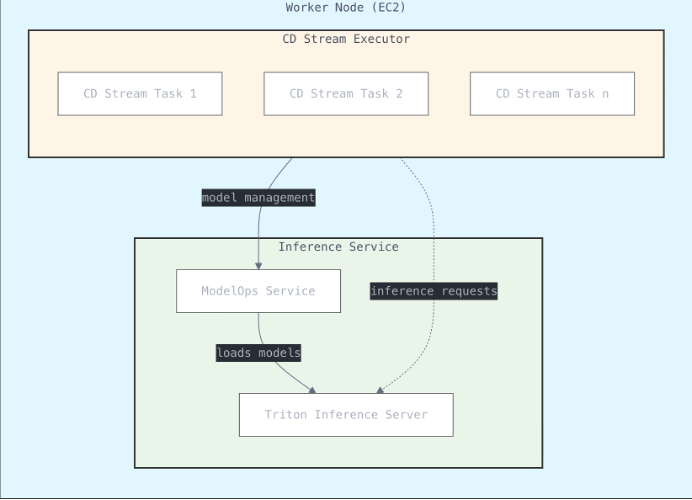
这项优化的结果是深远的:每个进程的内存占用从 8.5 GB 一直下降到 2.5 GB,而平均每次变化检测任务的运行时间从四分钟缩短到两分钟。随着 CPU 内存瓶颈的消除,我们可以将每个实例的任务数量增加到充分利用 CPU。在变化检测的情况下,对于一个 32 vCPU 实例,最佳任务数被证明是 32 个。总而言之,这项优化使效率提高了 2 倍以上。
下表说明了使用集中的 Triton 推理服务器托管后 CDNet 推理性能的提升。
| 每个任务所需的内存 | 每个实例的任务数 | 平均运行时间 | 每分钟任务数 | |
| 独立推理 | 8.5 GB | 30 | 4 分钟 | 7.5 |
| 集中推理 | 2.5 GB | 32 | 2 分钟 | 16 |
我们还考虑了另一种架构,其中一个可扩展的推理服务器将在单独的单元和独立的实例上运行,可能在 GPU 上运行。然而,由于以下几个原因,此选项被否决了:
- 延迟增加:通过网络调用 CDNet 而不是在同一设备上调用会增加显著的延迟。
- 网络流量增加:CDNet 相对较大的有效载荷显著增加了网络流量,从而进一步增加了延迟。
我们发现,我们解决方案中固有的推理容量自动扩展(为每个 CPU 工作实例使用额外的服务器),非常适合推理需求。
优化 Triton 推理服务器:减小 Docker 镜像大小以实现更精简的部署
默认的 Triton 镜像支持多种机器学习后端以及 CPU 和 GPU 执行,导致镜像大小高达约 15 GB。为了简化这一点,我们重建了 Docker 镜像,仅包含我们所需的 ML 后端并将执行限制为仅限 CPU。结果是将镜像大小大幅减少到仅 2.7 GB。这有助于进一步减少内存利用率并增加额外变化检测进程的容量。更小的镜像尺寸意味着更快的容器启动时间。
3. 增加实例多样性:利用 AWS Graviton 实例获得更好的性价比
在峰值容量时,大量 Spot 实例上有数千个变化检测任务同时运行。不可避免地,每个实例的 Spot 可用性会波动。跟上需求的关键是支持大量的实例类型。我们强烈倾向于更新、更强的 CPU 实例,这些实例在速度和成本效益方面比其他同类实例显示出显著的优势。这时 AWS Graviton 提供了一个重大的机会。
AWS Graviton 是一系列处理器,旨在为在 Amazon EC2 中运行的云工作负载提供最佳的性价比。它们还针对 ML 工作负载进行了优化,包括 Neon 向量处理引擎、对 bfloat16 的支持、可扩展向量扩展 (SVE) 和矩阵乘法 (MMLA) 指令,使其成为运行我们变化检测系统的批量深度学习推理工作负载的理想选择。PyTorch、TensorFlow 和 ONNX 等主流机器学习框架都已针对 Graviton 处理器进行了优化。
事实证明,将我们的解决方案适配到 Graviton 上运行非常简单。大多数现代 AI/ML 框架,包括 Triton 推理服务器,都内置了对 AWS Graviton 的支持。为了适配我们的解决方案,我们需要进行以下更改:
- 创建一个专用于在 AWS Graviton(ARM 架构)上运行变化检测流水线的新 Docker 镜像。
- 为 Graviton 重新编译精简版的 Triton 推理服务器。
- 将 Graviton 实例添加到节点池中。
结果
通过使变化检测能够在 AWS Graviton 实例上运行,我们提高了变化检测子系统的整体成本效率,并大幅增加了我们的实例多样性和 Spot 实例可用性。
1. 吞吐量增加
为了量化影响,我们可以分享一个例子。假设当前的任务负载需要 5,000 个计算实例,其中只有一半可以用现代非 Graviton CPU 实例来满足。在将 AWS Graviton 添加到我们的资源池之前,我们需要用运行速度慢 3 倍的旧一代 CPU 来填补其余需求。在我们的实例多样化优化之后,我们可以用 AWS Graviton Spot 可用性来满足这些需求。在我们的例子中,这使整体效率翻了一番。最后,在这个例子中,吞吐量提升超过了 2 倍,因为 CDNet 在 AWS Graviton 实例上的运行时性能通常比同类 EC2 实例更快。
下表说明了使用 AWS Graviton 实例后 CDNet 推理性能的提升。
| 实例类型 | 每秒样本数 |
| AWS Graviton 基于的 EC2 实例 – r8g.8xlarge | 19.4 |
| 同类非 Graviton CPU 实例 – 8xlarge | 13.5 |
| 旧一代非 Graviton CPU 实例 – 8xlarge | 6.64 |
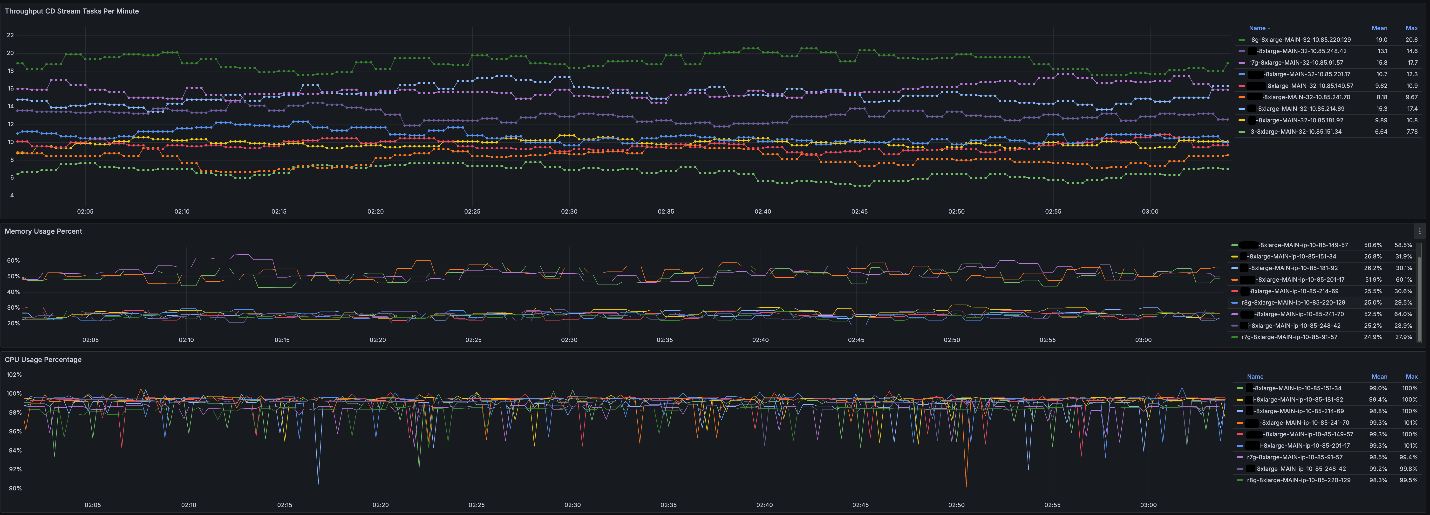
使用 AWS Graviton 实例,我们可以看到以下 CDNet 推理性能。
2. 改善用户体验
通过 Triton 推理服务器的部署以及车队多样性和实例可用性的增加,我们极大地提高了变化检测系统的吞吐量,从而为我们的客户提供了增强的用户体验。
3. 体验无缝迁移
大多数现代 AI/ML 框架,包括 Triton 推理服务器,都内置了对 AWS Graviton 的支持,这使得我们的解决方案适配到 Graviton 上运行变得很直接。
结论
在优化运行时效率方面,工作尚未完成。通常还有更多的参数需要调整,更多的标志需要应用。AI/ML 框架和库正在不断增强和优化它们对许多不同端点实例类型的支持,特别是 AWS Graviton。我们预计通过进一步的努力,我们将继续改进我们的优化工作。我们期待在未来的帖子中分享我们旅程的下一步。有关更多阅读,请参阅以下内容:
关于作者
 Chaim Rand 是 Mobileye 自动驾驶解决方案中从事深度学习和计算机视觉技术的首席工程师和机器学习算法开发人员。
Chaim Rand 是 Mobileye 自动驾驶解决方案中从事深度学习和计算机视觉技术的首席工程师和机器学习算法开发人员。
 Pini Reisman 是 REM(Mobileye 的地图组)工程组中的软件高级首席工程师,负责性能工程和技术创新。
Pini Reisman 是 REM(Mobileye 的地图组)工程组中的软件高级首席工程师,负责性能工程和技术创新。
 Eliyah Weinberg 是 Mobileye REM 的性能与规模优化和技术创新工程师。
Eliyah Weinberg 是 Mobileye REM 的性能与规模优化和技术创新工程师。
 Sunita Nadampalli 是 AWS 的首席工程师和 AI/ML 专家。她负责领导 AWS Graviton 针对 AI/ML 和 HPC 工作负载的软件性能优化。她热衷于开源软件开发,并为基于 Arm ISA 的 SoC 提供高性能和可持续的软件解决方案。
Sunita Nadampalli 是 AWS 的首席工程师和 AI/ML 专家。她负责领导 AWS Graviton 针对 AI/ML 和 HPC 工作负载的软件性能优化。她热衷于开源软件开发,并为基于 Arm ISA 的 SoC 提供高性能和可持续的软件解决方案。
 Guy Almog 是 AWS 的高级解决方案架构师,专注于计算和机器学习。他与大型企业 AWS 客户合作,设计和实施可扩展的云解决方案。他的工作涉及提供有关 AWS 服务的技术指导、开发高级解决方案,并提供侧重于安全性、性能、弹性、成本优化和运营效率的架构建议。
Guy Almog 是 AWS 的高级解决方案架构师,专注于计算和机器学习。他与大型企业 AWS 客户合作,设计和实施可扩展的云解决方案。他的工作涉及提供有关 AWS 服务的技术指导、开发高级解决方案,并提供侧重于安全性、性能、弹性、成本优化和运营效率的架构建议。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区