



📢 转载信息
原文链接:https://www.deeplearning.ai/the-batch/issue-323
原文作者:DeepLearning.AI
深度学习快讯 第323期:AI智能体快速迭代的关键——评估与错误分析
亲爱的朋友们,
上周我提到,团队在构建AI智能体(Agentic Systems)时,进步速度最大的决定性因素在于其执行评估(Evals)和错误分析(Error Analysis)的严谨程度。尽管人们倾向于绕过这些“枯燥”的流程,快速尝试修复错误,但扎实的评估和错误分析工作能带来更快的进展。在这两部分系列信件的第一部分中,我将分享一些在智能体系统中发现和解决问题的最佳实践。
尽管错误分析在构建监督学习系统时一直是重要一环,但在当下,它仍不如追逐最新、最热门的工具那样受重视。识别特定错误类型的根本原因可能看似“乏味”,但回报巨大!如果你还没有被说服,让我用类比来提醒你:
- 要精通乐器演奏,你不会只从头到尾弹奏同一首曲子,而是会找出卡壳的地方并加强练习。
- 要保持健康,你不会只靠最新的营养秘诀来安排饮食,还会让医生检查你的血液指标,看看是否有异常。(我上个月刚检查过,很高兴地报告一切正常!😃)
- 要提高运动队的表现,你不会只练习花哨的技巧,而是会回顾比赛录像,发现差距并加以改进。
要改进你的AI智能体系统,不要只堆砌社交媒体上爆火的新技术(虽然我本人也喜欢实验那些时髦的AI技术!),而是要利用错误分析来弄清楚它哪里做得不好,然后集中精力攻克它。
在进行错误分析之前,我们首先需要确定什么是“错误”。所以第一步是建立评估(Evals)体系。在接下来的信件中,我将重点介绍评估,下周再讨论错误分析。

从监督学习到生成式AI:评估的挑战
如果你使用监督学习训练二元分类器,算法出错的方式是有限的:它可能输出0而不是1,反之亦然。并且有少数标准指标(如准确率、精确率、召回率、F1值、ROC等)适用于许多问题。因此,只要了解测试分布,评估就相对简单,错误分析的大部分工作在于识别算法在哪类输入上失败,这自然会导向数据中心AI技术,以获取更多数据来弥补算法的弱点。
对于生成式AI,许多来自监督学习评估和错误分析的直觉是相通的——历史不会简单重复,但会押韵(History doesn’t repeat itself, but it rhymes)。对于那些熟悉机器学习和深度学习的开发者来说,他们适应生成式AI的速度通常比从零开始的人要快。但一个新的挑战是:输出空间更加丰富,导致算法的错误方式变得更多。
以自动化处理财务发票为例,我们使用智能体工作流从收到的发票中填充财务数据库。算法会不会错误地提取到期日?还是最终金额?或者将付款方地址和收款方地址搞混?或者在财务货币上出错?亦或是调用错误的API导致验证流程失败?由于输出空间更大,失败模式的数量也随之剧增。
因此,与其预先定义一个错误度量标准,通常更有效的方法是:首先快速构建一个原型,然后手动检查少数几个智能体输出,看看它在哪里表现良好,在哪里遇到困难。这使得你可以专注于构建数据集和错误指标——有时是代码实现的客观指标,有时是使用LLM-as-judge的主观指标——来检查系统在你最关心的维度上的性能。在监督学习中,我们有时会调整错误指标以更好地反映人类的关注点。但在智能体工作流中,我发现调整评估(Evals)更具迭代性,需要更频繁地调整评估标准,以捕捉到可能出错的更广泛的可能性。
我在上周宣布的 Agentic AI 课程的第4模块中详细讨论了这些和其他最佳实践。在构建了评估体系后,你就获得了系统性能的衡量标准,这为你尝试对智能体进行不同修改奠定了基础,因为你现在可以衡量哪些改动带来了差异。下一步就是进行错误分析,以精确指出应该将开发精力集中在哪些方面。我将在下周进一步讨论这一点。
继续构建!
Andrew
来自 DEEPLEARNING.AI 的信息

在这个与 Google 合作的短期课程中,你将使用 Google 的智能体开发套件(Agent Development Kit)构建从简单到多智能体播客系统的实时语音智能体。免费报名
新闻 (News)

OpenAI 加强与 AMD 的合作关系
OpenAI 为了驱动其计划中的全球数据中心集群,在算力方面捉襟见肘,因此转向了英伟达的长期竞争对手 AMD。
最新动态: 在一笔不同寻常的交易中,OpenAI 同意采购可能价值数百亿美元的 AMD Instinct GPU,并获得了在满足特定条件后以几乎免费的方式购买芯片设计公司相当比例股份的权利。这笔交易将分阶段完成,从明年开始,涵盖的 GPU 算力足以消耗 6 千兆瓦的电力(约等于旧金山市平均用电需求的 6 倍),AMD 的股票比例最高可达 10%。这使得 OpenAI 能够多元化并扩展其 AI 处理器供应,以构建规模空前的庞大数据中心,而 AMD 则确保了一个顶级客户,并验证了其产品作为 GPU 巨头英伟达的竞争者地位——这对 AMD 在 AI 市场的信誉和销售是巨大的推动。
运作方式: 财务交易的完成取决于两家公司是否达成特定的、大多未公开的里程碑。OpenAI 必须达到 AMD 芯片的部署目标,同时 AMD 的股价也必须达到特定水平。
- OpenAI 计划使用 AMD 即将推出的 Instinct MI450 数据中心 GPU 进行推理(Inference)。它将从明年开始在一个新的、独立于先前宣布的数据中心部署第一批芯片(消耗 1 千兆瓦的算力)。完成该采购将解锁第一部分 AMD 股票。
- AMD 向 OpenAI 发放了一份认股权证,允许 OpenAI 以每股 0.01 美元的价格购买多达 1.6 亿股 AMD 股票,按公司当前市值计算价值超过 350 亿美元。当股价达到特定水平并最终达到每股 600 美元(约为当前股价的三倍)时,该认股权证将归属。如果 OpenAI 购买所有股票,它将拥有 AMD 10% 的股份,这可能使其能够影响公司的战略方向。
背景: OpenAI 与 AMD 的合作是其为在未来几年可能耗资数万亿美元的数据中心进行的一系列财务承诺中的最新一项。这也是大型 AI 公司确保足够处理能力以实现其宏伟目标的一项更广泛举措。亚马逊、谷歌、Meta、微软和 OpenAI 仅今年就宣布计划在数据中心上花费超过 3500 亿美元,这需要巨额支出并加剧了 AI 芯片的供应紧张。
- 大型 AI 公司的计划可能会超过英伟达最强力 GPU 的供应。在 2 月份的一篇 X(前 Twitter)帖子中,OpenAI 首席执行官 Sam Altman 表示 OpenAI “没有 GPU 了”,并准备采购数十万块。他说:“获得这些 GPU 的难度之大,怎么强调都不为过。”
- 根据投资分析师 Jefferies 的估计,截至去年底,AMD 在 AI 加速器市场的份额为 5%。自 2018 年推出 Instinct 系列以来,它一直在努力打破英伟达在数据中心 GPU 上的垄断。
- OpenAI 已经培养 AMD 作为英伟达的替代或补充有一段时间了。据路透社报道,它已经在有限的基础上使用 AMD 的 MI355X 和 MI300X GPU,并参与了 MI300x 的设计。
- 此外,OpenAI 宣布了一项计划,从 2026 年下半年开始,部署价值 10 千兆瓦的 Broadcom 定制芯片。该计划紧随早前与 Broadcom 达成的 100 亿美元协议,该协议旨在供应用于 AI 训练的定制芯片,以增强而非取代英伟达 GPU。
- OpenAI 的数据中心还需要高带宽内存芯片。本月早些时候,它与三星和 SK 海力士达成了一项交易,它们将扩大产能以服务于 Stargate(OpenAI、Oracle 和 SoftBank 之间的数据中心合作项目)。
重要性: 按照某些估计,AI 领导者正在竞相争夺一个可能达到数万亿美元的市场地位。OpenAI 正引领数据中心算力建设的浪潮。它与 AMD 的交易,AMD 一直在缓慢但稳步地蚕食英伟达在 GPU 上的主导地位,将 AMD 带上了这条注定充满波折的道路。尽管如此,这也使两家公司都面临着一些观察家担心的财务风险。OpenAI 背负了大量债务,目前的承诺预示着更多的债务。至于 AMD,它正在“赠送” 10% 的股份以换取未来的销售承诺,AMD 首席执行官 Lisa Su 表示,考虑到 OpenAI 和其他可能受此激励的客户,这价值 1000 亿美元。该交易的结构限制了风险,并确保如果市场停滞,两家公司将共同承担后果。
我们的思考: OpenAI 计划斥资数百亿美元购买推理芯片,支持了这样一种观点:对 AI 处理能力的需求正在从训练转向推理。整体使用量的增长,特别是智能体工作流的兴起,预示着推理领域将迎来大规模扩张,而拥有相对大内存的 AMD GPU 在某些场景下可能比英伟达芯片在推理方面具有优势。推理市场的竞争越激烈,token 生成的价格和速度就越有可能持续下降——这对 AI 构建者来说是一个巨大的福音!
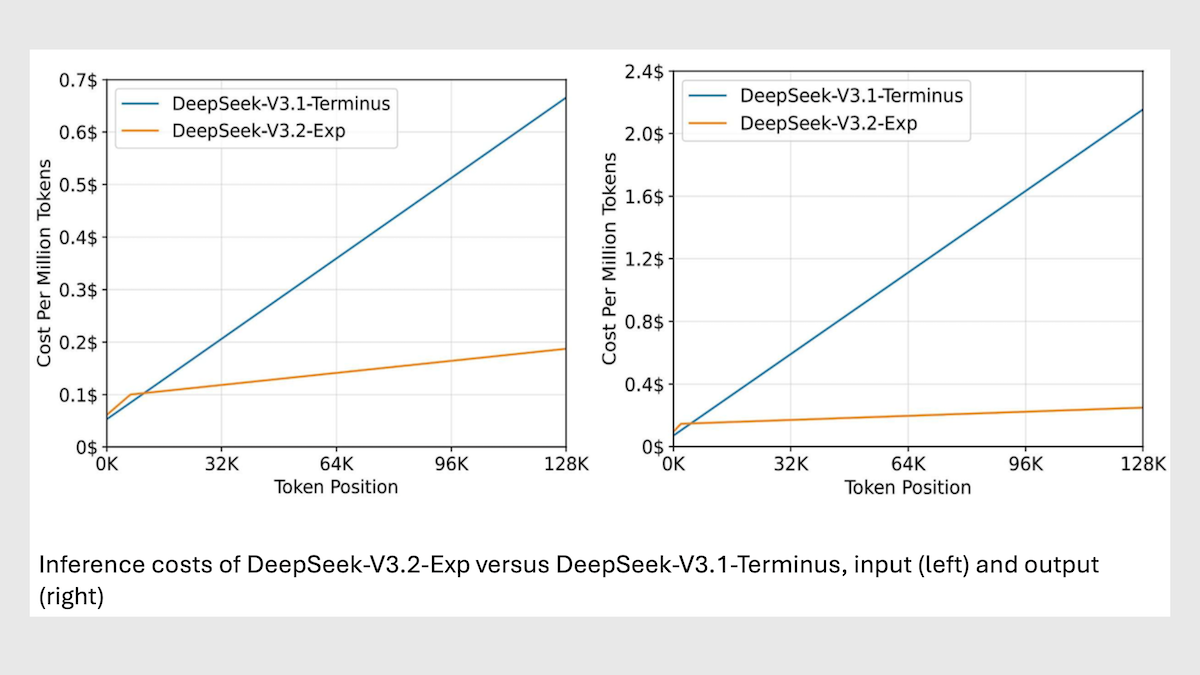
DeepSeek 降低推理成本
DeepSeek 最新的大语言模型相比其前代产品,可以将推理成本降低一半以上,并且处理长上下文的速度得到显著提升。
最新动态: DeepSeek 发布了DeepSeek-V3.2-Exp的权重,它是 9 月底发布的 DeepSeek-V3.1-Terminus 的一个变体。它通过一种动态的、基于稀疏注意力(sparse attention)的机制来优化处理流程,使得推理速度与输入长度呈线性关系。该代码支持华为设计的 AI 芯片,并且其他中国芯片设计公司也已将其适配到自己的产品上,这帮助中国开发者能够使用国产替代方案来替代美国设计的英伟达 GPU。
- 输入/输出: 文本输入(最多 128,000 tokens),文本输出(最多 8,000 tokens)
- 架构: 混合专家(MoE)Transformer,总共 6850 亿参数,每个 token 约 370 亿活跃参数
- 可用性: 通过网页界面或应用免费使用;权重在 MIT 许可下可用于非商业和商业用途(可下载);通过 API 价格为每百万输入/缓存/输出 tokens 分别为 $0.28 / $0.028 / $0.42(查看定价)
- 性能: 在许多基准测试中与 DeepSeek-V3.1-Terminus 相当,处理超过 7,000 tokens 的输入速度快 2 到 3 倍。
运作方式: 团队通过引入稀疏注意力机制修改了 DeepSeek-V3.1-Terminus,该机制不是关注整个输入上下文,而是有选择地处理最相关的 token。
- 在训练过程中,一个“闪电索引器”(一个加权相似性函数)通过 21 亿 tokens 的文本学习来预测 DeepSeek-V3.1-Terminus 的密集注意力机制会关注哪些 token。然后,团队在约 1000 亿 tokens 的文本上对所有参数进行了微调,使其能够与索引器选择的稀疏 token 配合工作。
- 团队通过蒸馏五个专家模型(针对推理、数学、编程、智能体编程和智能体搜索微调的 DeepSeek-V3.2 基础版本)到 DeepSeek-V3.2-Exp 中,进一步对模型进行了微调。
- 团队应用了GRPO(一种合并技术)在一个阶段内融合了推理、智能体和对齐训练。这种方法避免了在多阶段强化学习中通常困扰的多阶段灾难性遗忘问题。
- 在推理时,索引器对当前输入上下文中每个历史 token 与正在生成的 token 的相关性进行评分。它使用简单的操作和 FP8(8位浮点数,精度相对较低但计算量小)来快速计算这些分数。
- 基于这些分数,模型不计算当前输入上下文中所有 token 的注意力,而是选择并计算前 2,048 个得分最高的 token 的注意力,从而大大降低了计算成本。
结果: 在 DeepSeek 的基准测试中,与 DeepSeek-V3.1-Terminus 相比,DeepSeek-V3.2-Exp 在效率方面取得了显著的提升,而性能上的权衡很小。
- 与 DeepSeek-V3.1 Terminus 相比,DeepSeek-V3.2-Exp 降低了长输入上下文的推理成本的 6 到 7 倍。在处理 32,000 tokens 的上下文时,DeepSeek-V3.2-Exp 的成本约为每百万 tokens $0.10,而 Terminus 为 $0.60。在处理 128,000 tokens 的上下文时,成本为 $0.30,而 Terminus 为 $2.30。
- DeepSeek-V3.2-Exp 在涉及编码和智能体行为的任务以及一些数学问题上显示出优势。它在 Codeforces 编程挑战赛(Elo 分数分别为 2121 对 2046)和 BrowseComp 浏览器智能体任务(分别为 40.1% 对 38.5%)中超越了 DeepSeek-V3.1-Terminus。它还在 AIME 2025 的高中数学竞赛题(分别为 89.3% 对 88.4%)中超过了前代产品,这些题目的结构性更强,解决方案比 HMMT(见下文)中的问题更清晰。
- 然而,在几项任务上,其性能相比 DeepSeek-V3.2-Terminus 有轻微下降。在 GPQA-Diamond 的研究生级别科学问题(分别为 79.9% 对 80.7%)、HLE 的抽象思维挑战(分别为 19.8% 对 21.7%)、HMMT 2025 的竞赛高中数学问题(分别为 83.6% 对 86.1%)以及 Aider-Polyglot 的编码任务(分别为 74.5% 对 76.1%)上均落后于前代产品。
背景: DeepSeek-V3.2-Exp 是首批针对国产芯片进行优化而推出的(而非事后添加)大语言模型之一。该软件已适配到华为、寒武纪和海光(Hygon)的芯片上,这遵循了中国政府对国内 AI 公司不要使用英伟达芯片的命令。该命令是在有报道称中国 AI 公司在尝试使用国产芯片而非受美国出口限制的英伟达芯片时遇到困难之后发布的。
重要性: 尽管 LLM token 处理价格已经下跌,但处理 LLM 输出 token 的成本仍然可能使执行长上下文任务(如分析大量文档、长时间对话和重构大型代码库)变得非常昂贵。DeepSeek 对稀疏注意力的实现,在一定程度上解决了这个问题。
我们的思考: DeepSeek-V3.2-Exp 与Qwen3-Next一样,都在尝试使用自注意力机制的替代方案来提高大型 Transformer 的效率。虽然 Qwen3-Next 结合了门控 DeltaNet 层和门控注意力层,但 DeepSeek-V3.2-Exp 使用了动态稀疏注意力,这表明通过调整 Transformer 架构,仍有更多的效率有待挖掘。

微调(Fine-Tuning)简化
前 OpenAI 首席技术官 Mira Murati 创立的初创公司 Thinking Machines Lab 推出了首个产品,旨在简化并普及 AI 模型微调的过程。
最新动态: Tinker 是一个 API,它简化了使用多个 GPU 对大型语言模型进行微调的工作。用户控制他们的算法,而代码在后台处理调度、资源分配以及 GPU 崩溃后的恢复工作。你可以加入等候名单免费使用,但该公司计划在未来几周内开始收费。Tinker 目前提供一系列预训练的 Qwen3 和 Llama 3 模型,后续还将提供其他开源权重选项。
运作方式: API 让你感觉好像是在单设备上进行微调。你可以选择一个模型并编写一个微调脚本来加载你的数据,然后...
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区