



📢 转载信息
原文链接:https://machinelearningmastery.com/10-python-one-liners-for-calculating-model-feature-importance/
原文作者:Iván Palomares Carrascosa
理解机器学习模型是构建值得信赖的AI系统的基本方面。此类模型的可理解性建立在两个基本属性之上:可解释性(explainability)和可解释度(interpretability)。前者指的是我们描述模型“内部构造”(即模型如何运作和其内部结构)的程度,而后者则关注人类理解输入特征与预测输出之间捕获的关系的难易程度。正如我们所见,两者之间的差异很微妙,但有一个强大的桥梁将它们连接起来:特征重要性。
本文将揭示10个简单而有效的Python一行代码技巧,用于从不同角度计算模型特征重要性——帮助您不仅了解机器学习模型的行为方式,还了解它做出预测的原因。
1. 基于决策树模型的内置特征重要性
像随机森林和XGBoost集成这样的树模型允许您使用类似以下属性轻松获取特征重要性权重的列表:
importances = model.feature_importances_请注意,model应预先包含一个已训练的模型。结果是一个包含特征重要性的数组,但如果您想要一个更具自解释性的版本,以下代码通过整合像鸢尾花(iris)数据集中的特征名称,将前面的技巧增强为一行代码。
print("Feature importances:", list(zip(iris.feature_names, model.feature_importances_)))2. 线性模型的系数
像线性回归和逻辑回归这样更简单的线性模型也通过学习到的系数来暴露特征权重。这是一种直接且简洁地获取第一个系数的方法(要获取所有权重,请删除位置索引):
importances = abs(model.coef_[0])3. 按重要性排序特征
类似于第1点的增强版本,这个有用的技巧可以用于按重要性值降序排列特征——这可以很好地了解哪些特征是对模型预测最强大或最具影响力的贡献者。
sorted_features = sorted(zip(features, importances), key=lambda x: x[1], reverse=True)4. 模型无关的置换重要性
置换重要性是衡量特征重要性的另一种方法——即通过打乱其值并分析用于衡量模型性能的指标(例如准确率或误差)的下降程度。因此,scikit-learn中的这个模型无关的一行代码用于衡量随机置换特征值后导致的性能下降。
from sklearn.inspection import permutation_importance
result = permutation_importance(model, X, y).importances_mean5. 交叉验证置换中的平均准确率损失
这是一个在交叉验证过程中测试置换的有效技巧——分析打乱每个特征如何影响模型在K折上的性能。
import numpy as np
from sklearn.model_selection import cross_val_score
importances = [(cross_val_score(model, X.assign(**{f: np.random.permutation(X[f])}), y).mean()) for f in X.columns]6. 使用Eli5进行置换重要性可视化
Eli5——“像我对5岁小孩解释一样”(Explain like I’m 5 years old)的缩写——在Python机器学习的背景下,是一个提供清晰易懂解释的库。它提供了特征重要性的轻微可视化HTML视图,这对于Notebooks特别方便,也适用于已训练的线性或树模型。
import eli5
eli5.show_weights(model, feature_names=features)7. 全局SHAP特征重要性
SHAP是一个流行且强大的库,用于深入解释模型特征重要性。它可以用于计算每个特征的平均绝对SHAP值(SHAP中的特征重要性指标——所有这些都基于模型无关的、理论基础的测量方法。
import numpy as np
import shap
shap_values = shap.TreeExplainer(model).shap_values(X)
importances = np.abs(shap_values).mean(0)8. SHAP值的汇总图
与全局SHAP特征重要性不同,汇总图不仅提供了模型中特征的全局重要性,还显示了它们的方向,通过视觉帮助理解特征值如何推动预测值上升或下降。
shap.summary_plot(shap_values, X)让我们看一下获得结果的视觉示例:
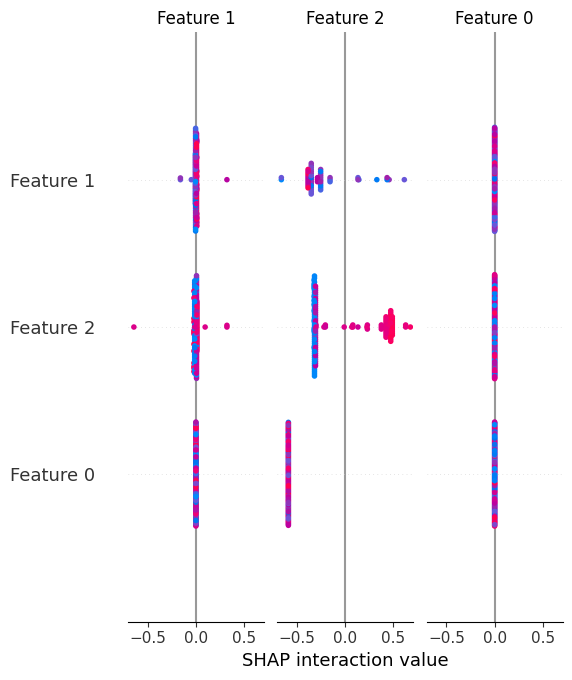
9. SHAP的单次预测解释
SHAP一个特别吸引人的方面是,它不仅有助于解释整体模型行为和特征重要性,还可以解释特征如何具体影响单个预测。换句话说,我们可以揭示或分解单个预测,解释模型如何以及为何产生该特定输出。
shap.force_plot(shap.TreeExplainer(model).expected_value, shap_values[0], X.iloc[0])10. 使用LIME进行模型无关的特征重要性
LIME是SHAP的一种替代库,它生成局部替代解释。不是非此即彼,这两个库可以很好地互补,有助于更好地近似单个预测周围的特征重要性。此示例针对先前训练的逻辑回归模型进行此操作。
from lime.lime_tabular import LimeTabularExplainer
exp = LimeTabularExplainer(X.values, feature_names=features).explain_instance(X.iloc[0], model.predict_proba)总结
本文介绍了10个有效的Python一行代码技巧,帮助您更好地理解、解释和解读机器学习模型,重点关注特征重要性。借助这些工具,了解模型内部工作原理不再是一个神秘的黑箱。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区