



📢 转载信息
原文链接:http://bair.berkeley.edu/blog/2025/11/01/rl-without-td-learning/
原文作者:Seohong Park (BAIR Blog)
在本文中,我将介绍一种基于“另类”范式的强化学习(RL)算法:分治法(divide and conquer)。与传统方法不同,该算法不依赖于时序差分(TD)学习(后者存在可扩展性挑战),能够很好地扩展到长时程任务中。

我们可以基于分治法而非时序差分(TD)学习来进行强化学习(RL)。
问题背景:离策略强化学习
我们关注的问题是离策略强化学习(off-policy RL)。让我们简要回顾一下它的含义。
在RL中存在两类算法:同策略RL和离策略RL。同策略RL意味着我们只能使用当前策略收集到的最新数据。换句话说,每次更新策略时,我们都必须丢弃旧数据。像PPO和GRPO这类算法通常属于这一类。
离策略RL则没有这种限制:我们可以使用任何类型的数据,包括旧经验、人类演示、互联网数据等。因此,离策略RL比同策略RL更通用、更灵活(当然也更困难!)。Q-learning是最著名的离策略RL算法。在数据收集成本高昂的领域(例如,机器人技术、对话系统、医疗保健等),我们往往别无选择,只能使用离策略RL。这就是它如此重要的原因。
截至2025年,我认为我们已经有了相当成熟的方案来扩展同策略RL(例如PPO、GRPO及其变体)。然而,我们仍然没有找到一种能够很好地扩展到复杂、长时程任务的“可扩展”离策略RL算法。让我简要解释一下原因。
价值学习中的两种范式:时序差分(TD)与蒙特卡洛(MC)
在离策略RL中,我们通常使用时序差分(TD)学习(即Q-learning)来训练价值函数,其贝尔曼更新规则如下:
Q(s, a) <- r + γ * max_a' Q(s', a')问题在于:下一个价值 Q(s’, a’) 中的误差会通过自举(bootstrapping)传播到当前价值 Q(s, a),并且这些误差会在整个时程中累积。这基本上就是导致TD学习难以扩展到长时程任务的原因。
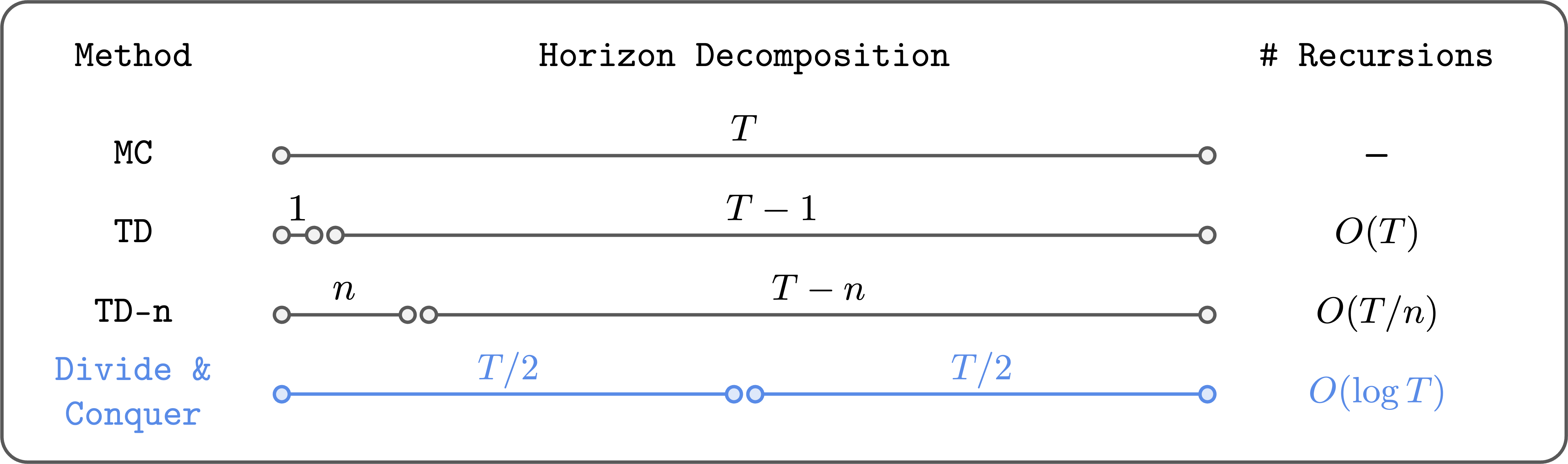
为了缓解这个问题,人们将TD学习与蒙特卡洛(MC)回报结合起来。例如,我们可以进行 n 步TD学习(TD-n):
Q(s_t, a_t) <- Σ_{i=0}^{n-1} (γ^i * r_{t+i}) + γ^n * max_a' Q(s_{t+n}, a')在这里,我们对前 n 步使用实际的蒙特卡洛回报(来自数据集),然后对剩余的时程使用自举价值。这样,我们可以将贝尔曼递归次数减少 n 倍,从而减少误差累积。在 n=∞ 的极端情况下,我们恢复了纯蒙特卡洛价值学习。
虽然这是一个合理的解决方案(并且通常效果不错),但它非常令人不满。首先,它并没有从根本上解决误差累积问题;它只是将贝尔曼递归次数减少了一个常数因子(n)。其次,随着 n 的增加,我们面临高方差和次优性的困扰。因此,我们不能简单地将 n 设置得很大,必须针对每项任务仔细调整它。
第三种范式:分治法
我的观点是,价值学习中的第三种范式——分治法,可能为离策略RL提供了一种理想的解决方案,能够扩展到任意长时程的任务。
分治法以对数级减少了贝尔曼递归的次数。
分治法的核心思想是将轨迹分为两个等长的片段,并结合它们的价值来更新完整轨迹的价值。通过这种方式,我们(在理论上)可以将贝尔曼递归次数对数级减少(而不是线性减少!)。此外,它不需要像 n 步TD学习那样选择超参数,也不一定遭受高方差或次优性的困扰。
一种实用算法:传递强化学习 (TRL)
在最近的一项工作中,我们朝着实现并扩展这一思想迈出了有意义的一步。具体来说,我们成功地将分治价值学习扩展到了高度复杂的任务中,即目标导向型RL(goal-conditioned RL)。目标导向型RL旨在学习一种能够从任何状态到达任何其他状态的策略。这提供了一种自然的分治结构。
如果我们假设动力学是确定性的,并将两个状态 s 和 g 之间的最短路径距离(“时间距离”)记为 d*(s, g),那么它满足三角不等式:d*(s, g) ≤ d*(s, w) + d*(w, g)。
这转化为以下“传递性”贝尔曼更新规则:
V(s, g) <- max_w V(s, w) * V(w, g)解决方案
我们的核心思想是:将 w 的搜索空间限制在数据集中出现的那些状态上。此外,我们使用期望分位数回归(expectile regression)来计算“软”最大值,从而避免了 max 算子带来的价值高估问题。我们将此算法称为传递强化学习(Transitive RL, TRL)。
实验效果
我们直接在 OGBench 中最具挑战性的任务上评估了 TRL。结果非常令人振奋!TRL 在大多数任务上实现了最佳性能,并且与最佳、单独调优的 TD-n 算法相匹配,而无需手动设置超参数 n。这正是我们从分治范式中所追求的目标。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区