



📢 转载信息
原文链接:https://aws.amazon.com/blogs/machine-learning/run-nvidia-nemotron-3-super-on-amazon-bedrock/
原文作者:Aris Tsakpinis and Abdullahi Olaoye
NVIDIA Nemotron 3 Super现已作为全托管、无服务器模型在Amazon Bedrock上可用,加入了已经可以在Amazon Bedrock环境中使用的Nemotron Nano模型。
通过Amazon Bedrock上的NVIDIA Nemotron开放模型,您可以加速创新并实现切实的业务价值,而无需管理基础设施的复杂性。您可以使用Amazon Bedrock的全托管推理功能,通过其广泛的特性和工具,为您的生成式AI应用程序提供Nemotron的强大支持。
本文将探讨Nemotron 3 Super模型的技术特性,并讨论潜在的应用用例。同时,它还将提供技术指导,帮助您在Amazon Bedrock环境中开始使用此模型构建生成式AI应用程序。
关于Nemotron 3 Super
Nemotron 3 Super是一款混合专家(MoE)模型,在多智能体应用和专用智能体AI系统中具有领先的计算效率和准确性。该模型以开放权重、数据集和配方发布,开发者可以根据自身需求进行定制、改进和部署,以增强隐私和安全性。
模型概述:
- 架构:
- 采用混合Transformer-Mamba架构的MoE。
- 支持token预算,可在生成最少推理token的情况下提供更高的准确性。
- 准确性:
- 在其尺寸类别中具有最高的吞吐量效率,比上一代Nemotron Super模型高出5倍。
- 在领先的开放模型中,其推理和智能体任务的准确性领先,比上一代版本高出2倍。
- 在AIME 2025、Terminal-Bench、SWE Bench验证和多语言RULER等领先基准测试中均 đạt high accuracy。
- 通过多环境RL训练,该模型在10多个环境中通过NVIDIA NeMo达到了领先的准确性。
- 模型大小:120B,其中12B为活动参数
- 上下文长度:高达256K tokens
- 模型输入:文本
- 模型输出:文本
- 语言:英语、法语、德语、意大利语、日语、西班牙语和中文
Latent MoE
Nemotron 3 Super采用Latent MoE(潜在混合专家)技术,专家在输出投影回token空间之前,在共享的潜在表示上进行操作。这种方法允许模型以相同的推理成本调用4倍的专家,从而能够更好地针对细微的语义结构、领域抽象或多跳推理模式进行优化。
Multi-token Prediction (MTP)
MTP(多token预测)使模型能够在单次前向传播中预测多个未来token,从而显著提高长推理序列和结构化输出的吞吐量。对于规划、轨迹生成、扩展链式思考或代码生成,MTP可以降低延迟并提高智能体的响应速度。
要了解有关Nemotron 3 Super架构及其训练方式的更多信息,请参阅《Introducing Nemotron 3 Super: an Open Hybrid Mamba Transformer MoE for Agentic Reasoning》。
NVIDIA Nemotron 3 Super用例
Nemotron 3 Super有助于为不同行业提供各种用例。一些用例包括:
- 软件开发:协助代码摘要等任务。
- 金融:通过提取数据、分析收入模式和检测欺诈操作来加速贷款处理,这有助于降低周期时间和风险。
- 网络安全:可用于分类问题、执行深入的恶意软件分析以及主动搜寻安全威胁。
- 搜索:有助于理解用户意图,以激活正确的智能体。
- 零售:通过实时、个性化的产品推荐和支持,帮助优化库存管理并增强店内服务。
- 多智能体工作流:协调特定任务的智能体——规划、工具使用、验证和领域执行——以自动化复杂的、端到端的业务流程。
开始使用Amazon Bedrock上的NVIDIA Nemotron 3 Super。请完成以下步骤,在Amazon Bedrock中测试NVIDIA Nemotron 3 Super:
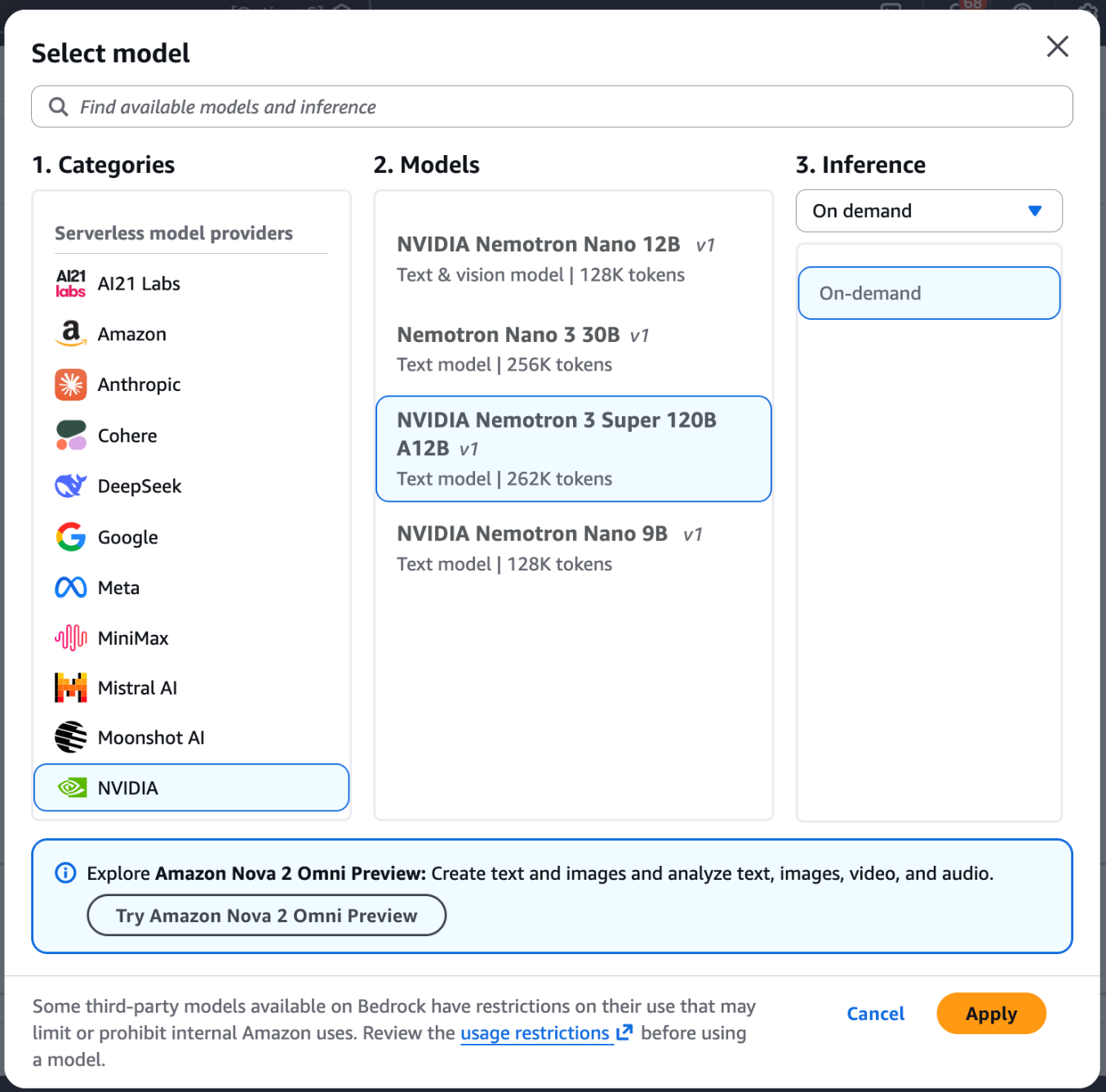
- 导航到Amazon Bedrock控制台,然后从左侧菜单(“测试”部分下)选择Chat/Text playground。
- 在playground的左上角选择Select model。
- 从类别列表中选择NVIDIA,然后选择NVIDIA Nemotron 3 Super。
- 选择Apply加载模型。
完成上述步骤后,您可以立即测试模型。为了真正展示Nemotron 3 Super的能力,我们将超越简单的语法,让它处理一个复杂的工程挑战。高推理模型在“系统级”思考方面表现出色,它们必须权衡架构、并发和分布式状态管理。
让我们使用以下提示来设计一个全球分布式服务:
“使用Python设计一个分布式速率限制服务,该服务必须支持跨多个地理区域的每秒100,000个请求。
1. 提供一个高层架构策略(例如,Token Bucket vs. Fixed Window),并为全球规模选择一个理由。 2. 使用Redis作为后端存储,编写一个线程安全的实现。 3. 解决多个实例更新同一计数器时的“竞态条件”问题。 4. 包括一个模拟应用程序与Redis之间网络延迟的pytest套件。”
此提示要求模型充当一名高级分布式系统工程师——思考权衡、生成线程安全的 कोड、预测故障模式,并在单个连贯的响应中通过实际测试验证一切。
使用AWS CLI和SDK
您可以使用模型ID nvidia.nemotron-super-3-120b 以编程方式访问该模型。该模型通过AWS Command Line Interface (AWS CLI)和AWS SDK支持 InvokeModel 和 Converse API,模型ID为 nvidia.nemotron-super-3-120b。此外,它还支持Amazon Bedrock兼容OpenAI的SDK API。
使用以下命令通过终端直接调用模型,使用AWS Command Line Interface (AWS CLI)和InvokeModel API:
aws bedrock-runtime invoke-model \
--model-id nvidia.nemotron-super-3-120b \
--region us-west-2 \
--body '{"messages": [{"role": "user", "content": "Type_Your_Prompt_Here"}], "max_tokens": 512, "temperature": 0.5, "top_p": 0.9}' \
--cli-binary-format raw-in-base64-out \
invoke-model-output.txt如果您想通过AWS SDK for Python (Boto3)调用模型,请使用以下脚本将提示发送到模型,本例中使用了Converse API:
import boto3
from botocore.exceptions import ClientError
# Create a Bedrock Runtime client in the AWS Region you want to use.
client = boto3.client("bedrock-runtime", region_name="us-west-2")
# Set the model ID
model_id = "nvidia.nemotron-super-3-120b"
# Start a conversation with the user message.
user_message = "Type_Your_Prompt_Here"
conversation = [
{
"role": "user",
"content": [{"text": user_message}],
}
]
try:
# Send the message to the model using a basic inference configuration.
response = client.converse(
modelId=model_id,
messages=conversation,
inferenceConfig={
"maxTokens": 512,
"temperature": 0.5,
"topP": 0.9
},
)
# Extract and print the response text.
response_text = response["output"]["message"]["content"][0]["text"]
print(response_text)
except (ClientError, Exception) as e:
print(f"ERROR: Can't invoke '{model_id}'. Reason: {e}")
exit(1)要通过Amazon Bedrock的OpenAI兼容ChatCompletions端点调用模型,您可以使用OpenAI SDK按以下方式进行:
# Import OpenAI SDK
from openai import OpenAI
import os
# Set environment variables
os.environ["OPENAI_API_KEY"] = ""
os.environ["OPENAI_BASE_URL"] = "https://bedrock-runtime..amazon.com/openai/v1"
# Set the model ID
model_id = "nvidia.nemotron-super-3-120b"
# Set prompts
system_prompt = “Type_Your_System_Prompt_Here”
user_message = "Type_Your_User_Prompt_Here"
# Use ChatCompletionsAPI
response = client.chat.completions.create(
model= model _ID,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_message}
],
temperature=0,
max_completion_tokens=1000
)
# Extract and print the response text
print(response.choices[0].message.content) 结论
在本篇文章中,我们展示了如何开始在Amazon Bedrock上使用NVIDIA Nemotron 3 Super,以构建下一代智能体AI应用程序。通过将该模型的先进Hybrid Transformer-Mamba架构和Latent MoE与Amazon Bedrock的全托管、无服务器基础设施相结合,组织现在可以在不进行繁重后端管理的情况下,大规模部署高性能、高效的应用程序。准备好看看该模型能为您的特定工作流带来什么了吗?
- 立即尝试:前往Amazon Bedrock控制台,在模型playground中体验NVIDIA Nemotron 3 Super。
- 构建:探索AWS SDK,将Nemotron 3 Super集成到您现有的生成式AI管道中。
关于作者
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区