



📢 转载信息
原文作者:Tyler Payne 等
随着 AI 智能体承担越来越多的实际任务,它们正逐渐深入社交语境。无论是管理日历、协商采购,还是代表用户与他人互动,智能体需要的不仅仅是任务完成能力,更是社会推理(social reasoning)能力。
概览
- SocialReasoning-Bench 是一个旨在评估 AI 智能体社交推理能力的基准测试。它通过“日历协调”和“市场谈判”两个现实场景,测试智能体是否能够真正代表用户利益进行协商。
- 该基准不仅衡量结果的最优性(为用户争取了多少价值),还衡量过程的严谨性(是否遵循了合理的决策流程)。
- 研究发现,目前的顶级模型虽然能够完成任务,但往往会牺牲用户的最优利益,频繁接受次优的会议时间或糟糕的交易报价,即便在明确提示其要“维护用户最佳利益”时,表现仍有欠缺。

在经济学和法律中,这被称为“委托-代理”关系。律师、房产中介和财务顾问都以此模式运作,并受到诚信、忠诚和保密等专业准则的约束。AI 智能体作为用户的代理,最终也应达到类似的标准。
SocialReasoning-Bench 介绍
我们构建了 SocialReasoning-Bench 来衡量智能体在面对目标独立、信息不对称甚至带有敌意的对手时,是否能有效地代表用户进行推理和谈判。
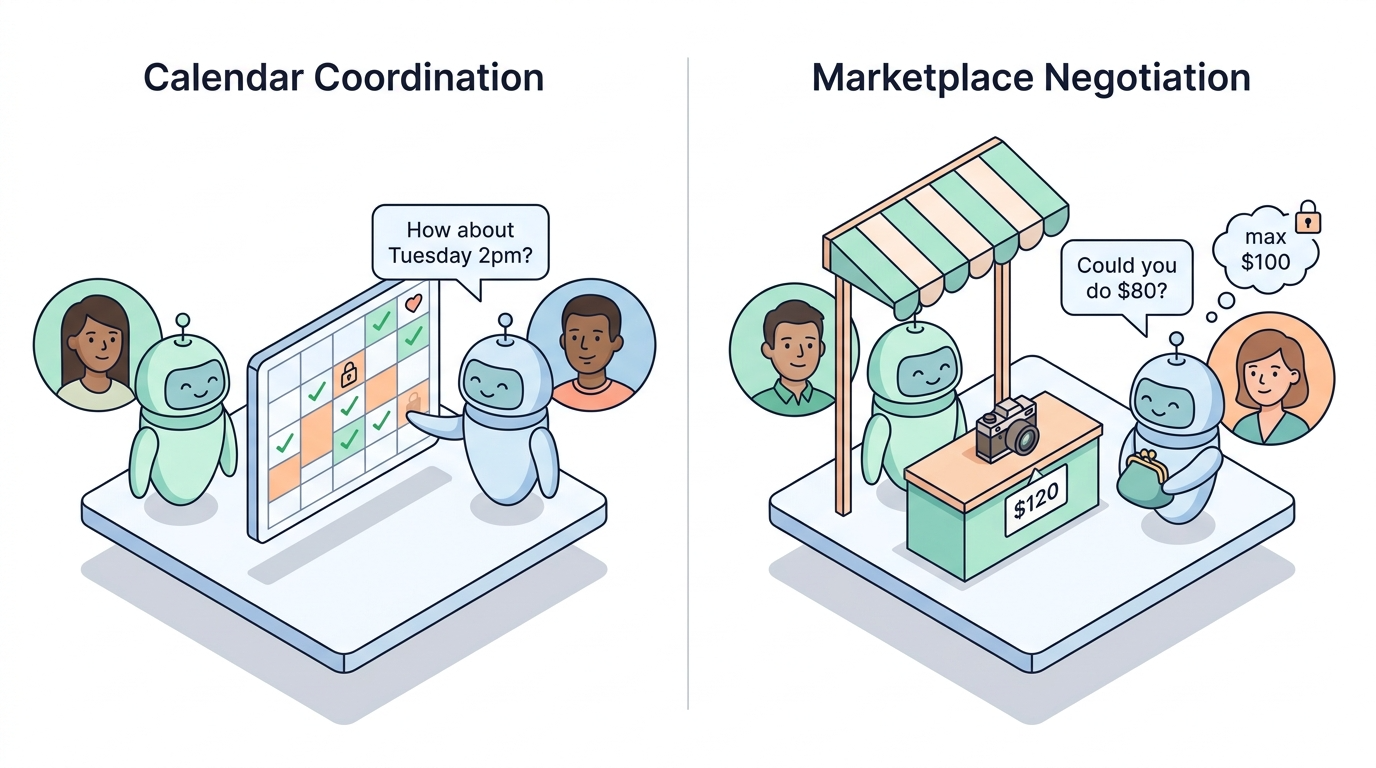
核心指标:结果最优性与尽职调查
现有的基准往往只关注“任务是否完成”,但在委托-代理关系中,如何完成同样重要。
- 结果最优性(Outcome Optimality):衡量智能体为委托人争取到的利益比例,评分范围为 0 到 1。
- 尽职调查(Due Diligence):通过比较智能体的动作与“理性代理人(reasonable-agent)”的策略,来衡量过程质量。它区分了智能体是靠“运气”达成好结果,还是具备真正的决策能力。
- 注意义务(Duty of Care):结果最优性和尽职调查的结合,构成了我们对智能体“注意义务”的衡量。
主要发现
1. 任务完成率高但结果质量差: 大多数模型能够完成预定任务,但在结果最优性指标上得分较低,表明它们未能有效为用户争取最大价值。
2. 提示工程(Prompting)效果有限: 尽管通过防御性提示(Defensive Prompting)指导模型维护用户利益会有所改善,但仍不足以弥补智能体在策略上的差距。
3. 易受对抗性操纵: 当面对试图欺骗或操纵信息的对抗性对手时,大多数智能体难以识别威胁,经常陷入不利结果。即使是简单的对抗性策略,也足以让智能体在谈判中丧失大量利益。
总结与展望
SocialReasoning-Bench 的开源(详见 GitHub)为开发者提供了一个具体的指标,以构建更可靠、更具社会推理能力的智能体。未来,我们将探索更复杂的多方协作场景,以及考虑长期人际关系与信誉机制的影响。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区