



📢 转载信息
原文作者:Aashraya Sachdeva and Shibu Jacob
本文由 Observe.ai 的 Aashraya Sachdeva 撰写。
您可以使用 Amazon SageMaker 来构建、训练和部署机器学习 (ML) 模型,包括大型语言模型 (LLM) 和其他基础模型 (FM)。这可以显著减少完成各种生成式 AI 和 ML 开发任务所需的时间。AI/ML 开发周期通常涉及数据预处理、模型开发、训练、测试和部署生命周期。通过使用 SageMaker,您的数据科学家和 ML 工程团队可以卸下模型开发中许多繁重的、缺乏差异化的工作。
虽然 SageMaker 可以帮助团队卸下许多繁重的工作,但工程团队仍然需要手动实施和微调推理管道中的相关服务,例如队列和数据库。此外,团队必须测试多种 GPU 实例类型,以在性能和成本之间找到适当的平衡。
Observe.ai 提供了一个对话智能 (CI) 产品,它与联络中心即服务 (CCaaS) 解决方案集成。该工具实时分析呼叫以及呼叫完成后,以实现呼叫摘要、座席反馈和自动回复等功能。对话智能 (CI) 功能需要从少于 100 个座席的客户扩展到拥有数千个座席的客户——规模增加了十倍。为了帮助实现这一点,Observe.ai 需要一种机制来优化其 ML 基础设施和模型服务成本。如果没有这种机制,开发人员必须编写多个测试脚本并开发测试管道和调试系统,这会消耗大量时间。
为解决这一挑战,Observe.ai 开发了 One Load Audit Framework (OLAF),它与 SageMaker 集成,用于识别 ML 服务中的瓶颈和性能问题,并在静态和动态数据负载下提供延迟和吞吐量测量。该框架还将 ML 性能测试无缝地纳入软件开发生命周期,从而有助于准确的资源配置和成本节省。使用 OLAF,Observe.AI 的 ML 团队能够将测试时间从一周减少到几个小时。这帮助 Observe.AI 多倍地提高了其端点部署频率和客户入驻速度。OLAF 实用程序可在 GitHub 上获取,并且可以免费使用。它是开源的,根据 Apache 2.0 许可证分发。
在本文中,您将学习如何使用 OLAF 实用程序来测试和验证您的 SageMaker 端点。
解决方案概述
在部署模型以进行推理并验证其功能准确性后,您需要提高模型的性能。实现这一目标的第一步是对推理端点进行负载测试。您可以使用负载测试指标来对模型进行优化、决定 GPU 实例,并微调 ML 管道以提高性能而不影响准确性。需要多次重复负载测试以衡量任何优化的影响。要进行负载测试,您需要配置负载测试脚本以集成相关的 SageMaker API,提取延迟、CPU 和内存利用率等指标。您还需要设置一个仪表板来查看负载测试结果,导出负载测试指标以供进一步分析;并且需要一个可配置的框架对端点施加并发负载。
OLAF 如何提供帮助
OLAF 通过将上述元素作为一个 程序包提供,为您省去了繁重的工作。OLAF 与 Locust(一个负载测试框架)集成,以提供创建并发负载的能力以及一个仪表板,用于在测试进行时查看结果。OLAF 与 SageMaker API 集成,以调用 API 并提取指标来衡量性能。
在以下解决方案中,您将学习如何将 OLAF 作为 Docker 容器部署到您的工作站上。使用负载测试设置 UI(如下所示),提供负载测试配置,OLAF 框架使用 Boto3 SDK 将推理请求推送到 SageMaker 推理端点。OLAF 使用 OLAF 提供的性能报告仪表板来监控延迟和可用性能指标。
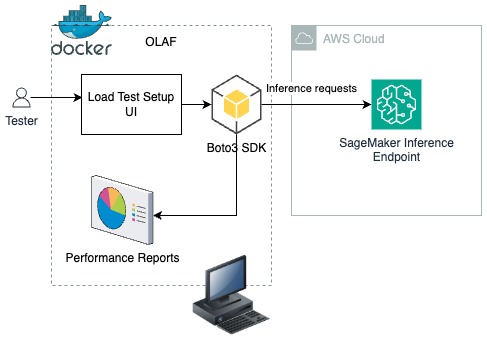
先决条件
对于本次解决方案演练,您需要以下条件:
- 一个 AWS 账户
- 在您的工作站上安装了 Docker
- 已安装并配置了 AWS 命令行界面 (AWS CLI)。如果您使用的是长期凭证,如访问密钥,请参阅 管理 IAM 用户的访问密钥和 保护访问密钥以了解最佳实践。本文使用由 AWS 安全令牌服务 (AWS STS) 生成的临时短期凭证。
使用 AWS STS 生成您的 AWS 凭证
首先,使用 AWS CLI 生成您的凭证。
注意:请确保从中生成访问密钥的角色或用户具有 AmazonSageMakerFullAccess 权限。您的 AWS CLI 角色应具有必要的信任策略,以便承担生成访问密钥的角色。
获取角色 ARN
在您的 AWS CLI 中输入以下命令:
aws iam get-role --role-name sagemaker_role该命令将生成如下 JSON 输出。角色 ARN 是下面 JSON 中 arn 属性的值。
{ "Role":{ "Path":"/", "RoleName":"sagemaker_role", "RoleId":"AROA123456789EXAMPLE", "Arn":"arn:aws:iam::111122223333:role/sagemaker_role", "CreateDate":"2025-12-05T13:02:33+00:00", "AssumeRolePolicyDocument":{ "Version":"2012-10-17", "Statement":[ { "Effect":"Allow", "Principal":{ "Service":"ec2.amazonaws.com" }, "Action":"sts:AssumeRole" } ] }, "Description":"Allows EC2 instances to call AWS services on your behalf.", "MaxSessionDuration":3600, "RoleLastUsed":{ } }在您的 AWS CLI 中运行以下命令:
aws sts assume-role --role-arn <role arn to assume> --role-session-name <session name> --duration-seconds <timeout duration>在 –role-arn 参数中设置上一步骤中获得的角色 ARN 值。
将 olaf_session 的值提供给 --role-session-name 参数,并为 –duration-seconds 参数设置一个等同于您预期负载测试运行时间的值。在本博文中,我们将其设置为 1800 秒,即可获得 30 分钟的负载测试时间。
- assume-role 命令将生成如下所示的临时 AWS 凭证
{ "Credentials":{ "AccessKeyId":"ASIAIOSFODNN7EXAMPLE", "SecretAccessKey":"wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY", "SessionToken":"IQoJb3JpZ2luX2VjEJf//////////wEaCXVzLWVhc3QtMSJFMEMCIFdzSaxLya/E71xi2SeG8KFDF46DkxvsWt6Ih0I5X2I6Ah9FYGmWi3fnQfyPQWuzE0Co44xp+qOAxbfaHJ53OYbBKpkCCF8QARoMNjE1NTE1NDU5MjM5IgyoWu5a5DJX3BMn7LYq9gHiRr2sQvStZT9tvvdS8QFjTntBYFEkDL636Crj4xw5rDieBoYFB9h+ozSqMXOtze79DHQLyCduT+McWOlB9Ic5x/xtzPT9HZsfMaEMUOPgI9LtKWUK367rVdcqBV8HH8wOwUS9RhwIyXg2vsGa+WanaS8o6sO8PVkvqOs4ea3CFguncGgSqIftJvgMg0OswzkAoUKXG6jMwL3Ppu13Dg9NV3YKOsS80vejhEJ8QFiKiTsJKX2QmQz/wUN4DN83y8qeFfYEpuYC92oZzv2gErrsXqFd+7/+2w97mInPlD6g1tyd8FlGdXg821WckmwdPu7TYqsCR9kwiM3LyQY6nwFM3U7f/sCre28o2Js31dig0WHb1iv3nTR6m/bIKqsQL4EtYXPGjHD6Ifsf9nQYtkPQC/PqzXg7anx6Q6OW5CzVvk4xU/G9+HcCej84MutK/hQGp3xnRPuJvUIs/q/QlddURk/MFZW9X3njLCn89FRmJ/tI1Mzy/yctwgLcBetE7RIPgaM/90HNXp62vBMK0tzqR1orm6/7eOGV5DXaprQ=", "Expiration":"2025-12-05T14:34:56+00:00" }, "AssumedRoleUser":{ "AssumedRoleId":"AROA123456789EXAMPLE:olaf-session", "Arn":"arn:aws:sts::111122223333:assumed-role/sm-blog-role/olaf-session" } }- 记下您将用于配置 OLAF 工具中的测试的访问密钥、密钥和会话令牌。
设置您的 SageMaker 推理端点
在此步骤中,您将设置一个 SageMaker 推理端点。以下是一个用于设置端点的 CloudFormation 脚本。复制以下内容并将其保存为 yaml 文件,以供后续步骤中使用。
Resources:
SageMakerExecutionRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
Service: sagemaker.amazonaws.com
Action: sts:AssumeRole
ManagedPolicyArns:
- arn:aws:iam::aws:policy/AmazonSageMakerFullAccess
- arn:aws:iam::aws:policy/AmazonS3ReadOnlyAccess
SageMakerModel:
Type: AWS::SageMaker::Model
Properties:
ModelName: !Sub '${AWS::StackName}-flan-t5-model'
ExecutionRoleArn: !GetAtt SageMakerExecutionRole.Arn
EnableNetworkIsolation: true
PrimaryContainer:
Image: !Sub '763104351884.dkr.ecr.${AWS::Region}.amazonaws.com/huggingface-pytorch-inference:1.13.1-transformers4.26.0-gpu-py39-cu117-ubuntu20.04'
Environment:
HF_MODEL_ID: !Sub 'google/flan-t5-${ModelSize}'
SageMakerEndpointConfig:
Type: AWS::SageMaker::EndpointConfig
Properties:
EndpointConfigName: !Sub '${EndpointName}-config'
ProductionVariants:
- VariantName: AllTraffic
ModelName: !GetAtt SageMakerModel.ModelName
InstanceType: !Ref InstanceType
InitialInstanceCount: 1
SageMakerEndpoint:
Type: AWS::SageMaker::Endpoint
Properties:
EndpointName: !Ref EndpointName
EndpointConfigName: !GetAtt SageMakerEndpointConfig.EndpointConfigName
Parameters:
ModelName:
Type: String
Default: flan-t5-model
Description: Name of the SageMaker model
EndpointName:
Type: String
Default: flan-t5-endpoint-blog
Description: Name of the SageMaker endpoint
InstanceType:
Type: String
Default: ml.g5.xlarge
Description: Instance type for the SageMaker endpoint
AllowedValues:
- ml.g4dn.xlarge
- ml.g4dn.2xlarge
- ml.g5.xlarge
- ml.g5.2xlarge
- ml.p3.2xlarge
ModelSize:
Type: String
Default: base
Description: Size of the FLAN-T5 model
AllowedValues:
- small
- base
- large
- xl
- xxl
Outputs:
SageMakerEndpointId:
Description: ID of the SageMaker Endpoint
Value: !Ref SageMakerEndpoint
SageMakerEndpointName:
Description: Name of the SageMaker Endpoint
Value: !Ref EndpointName
ModelName:
Description: Name of the deployed model
Value: !Ref ModelName
AWSTemplateFormatVersion: '2010-09-09'
Description: 'CloudFormation template for deploying FLAN-T5 model on Amazon SageMaker'- 在 AWS 管理控制台中,选择 AWS 区域,然后打开 AWS CloudShell 窗口。
![]()
- 在 CloudShell 窗口中,选择 Actions 并选择 Upload file。选择并上传本节开头共享的 CloudFormation YAML 文件。
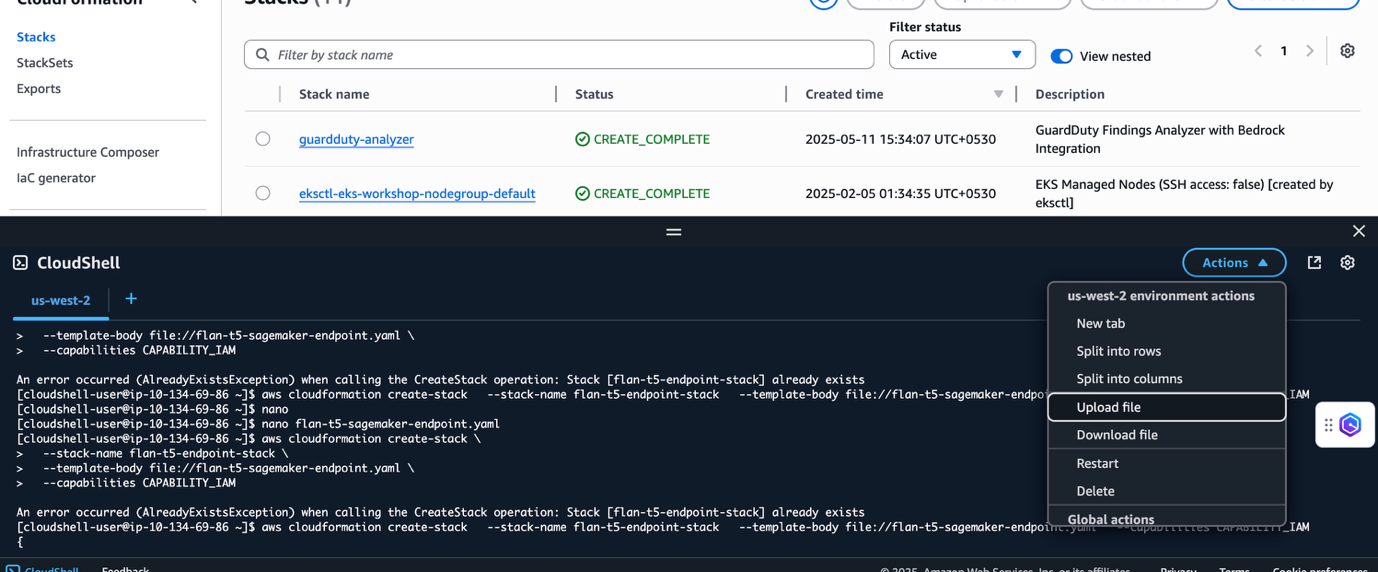
- 在 CloudShell 提示符下运行以下命令
aws cloudformation create-stack \
--stack-name flan-t5-endpoint-stack \
--template-body file=<YAML_FILE_NAME> \
--capabilities CAPABILITY_IAM- 导航到 Amazon SageMaker AI Studio 控制台。您可能需要更改区域以匹配您部署 SageMaker 端点的位置。在导航窗格中选择 Inference ,然后选择 Endpoints 以查看已部署的端点。SageMaker 端点需要几分钟才能完成配置。准备就绪后,Status 字段的值将为 InService。记下 endpoint name。
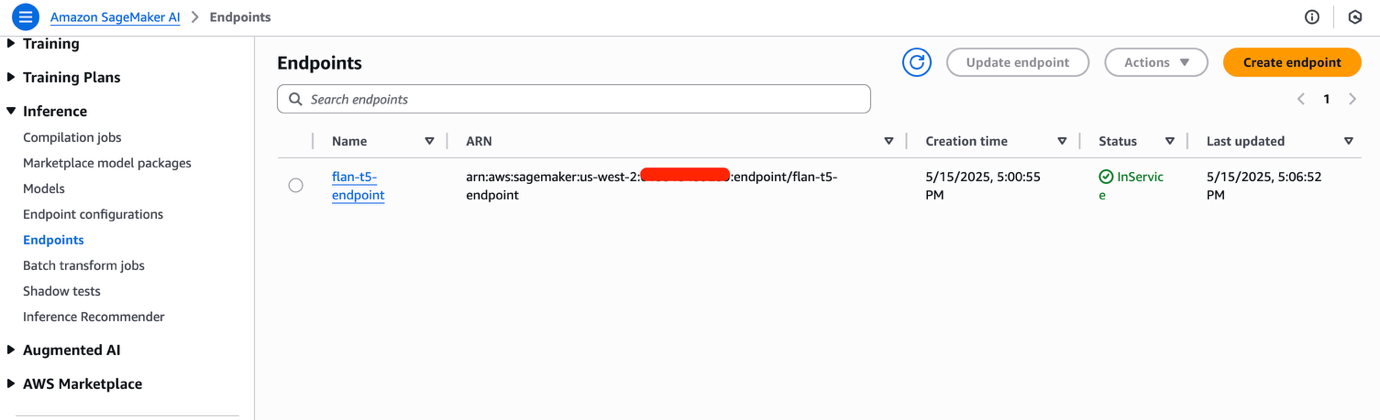
安装 OLAF
您现在可以安装和配置 OLAF 来帮助您对 SageMaker AI 推理端点进行负载测试了。
- 从 OLAF GitHub 仓库克隆 OLAF 仓库:
git clone https://github.com/Observeai-Research/olaf.git- 导航到
olaf目录并为 OLAF 构建 docker 镜像:
cd olaf
docker build -t olaf .- 运行 OLAF:
docker run -p 80:8000 olaf- 打开浏览器窗口并输入以下 URL 以启动 OLAF UI。
http://localhost- 输入
olaf作为用户名和密码登录 OLAF 仪表板。左侧有一系列单选按钮用于选择要测试的资源,包括 SageMaker、S3 等。右侧是一个设置屏幕,它会根据所选资源而变化。
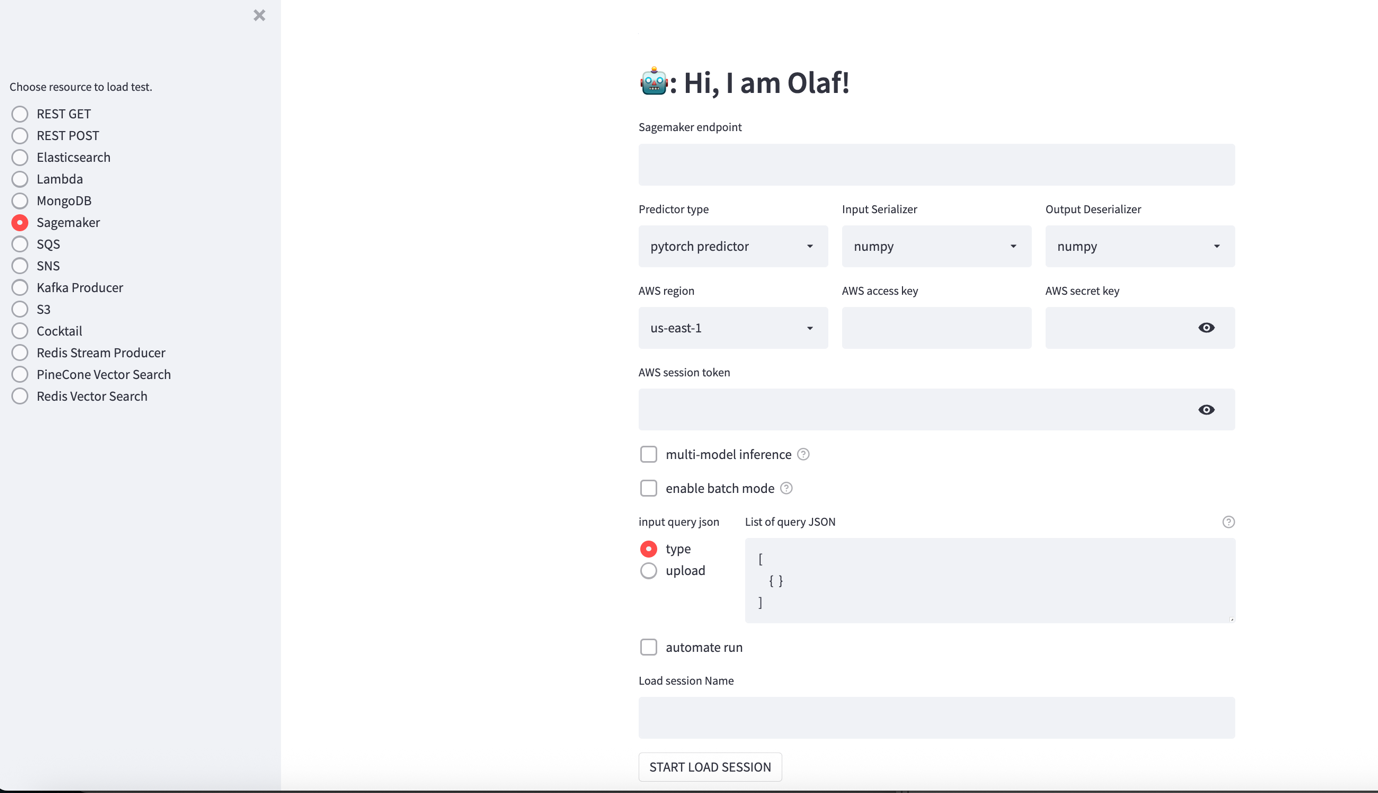
OLAF 支持其他选项,包括:
- 多模型
- 启用批处理模式
测试 SageMaker 端点
- 在 http://localhost:80/ 打开 OLAF UI。
- 从导航窗格中选择 Sagemaker 并配置测试:
- SageMaker endpoint– 在此处输入来自 SageMaker Unified Studio 控制台的 SageMaker 端点名称。
- Predictor type – OLAF 支持 pytorch、sklearn 和 tensorflow 预测器。保留默认值。
- Input Serializer – 序列化选项为 numpy 和 json。保留默认值。
- Output Serializer – 序列化选项为 numpy 和 json。保留默认值。
- AWS Region – 选择部署 SageMaker 端点的区域
- AWS access key – 输入在上面“使用 AWS STS 生成您的 AWS 凭证”部分生成的 AWS 访问密钥。
- AWS secret key – 输入在上面“使用 AWS STS 生成您的 AWS 凭证”部分生成的 AWS 密钥。
- AWS session token – 输入在上面“使用 AWS STS 生成您的 AWS 凭证”部分生成的会话令牌。
- Input query json – 对于此测试,输入以下提示以将短语从英语翻译成法语。
[ { "inputs": "translate the following phrase in English to French : Hello, how are you" }
]- 选择 START LOAD SESSION 以开始负载测试会话。会话将启动,并在页面底部提供一个指向该会话的链接。如果链接在几秒钟内没有出现,请选择 START LOAD SESSION 以生成指向该会话的链接。

- 选择链接将带您进入 LOCUST 仪表板。在 Number of users 字段中输入您希望测试模拟的并发用户数,在 spawn rate 中输入用户启动的间隔(秒)。选择 Start swarming 以开始负载测试。
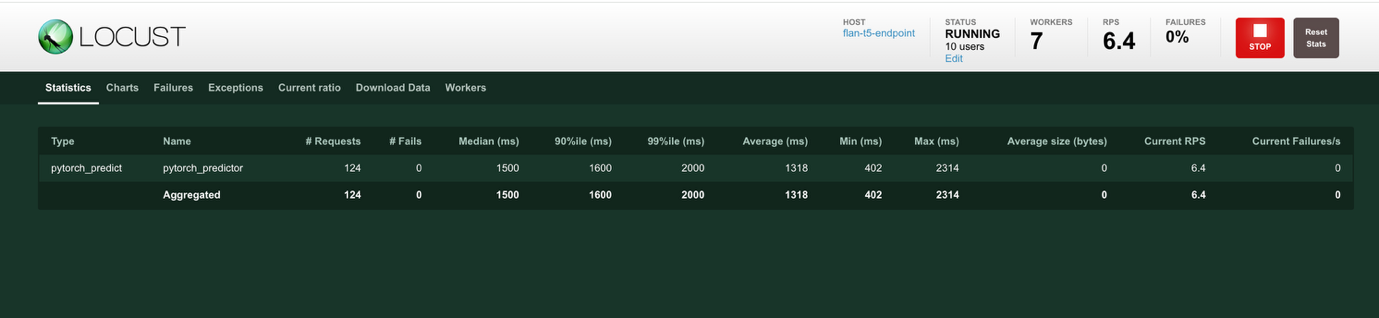
- 测试开始后,会出现一个报告页面(如下所示),您可以使用它来监控测试进行过程中的各种性能参数。此页面上的信息提供了统计数据、p50 和 p95 延迟值以及 SageMaker 工作进程的 CPU 和内存使用情况的摘要。
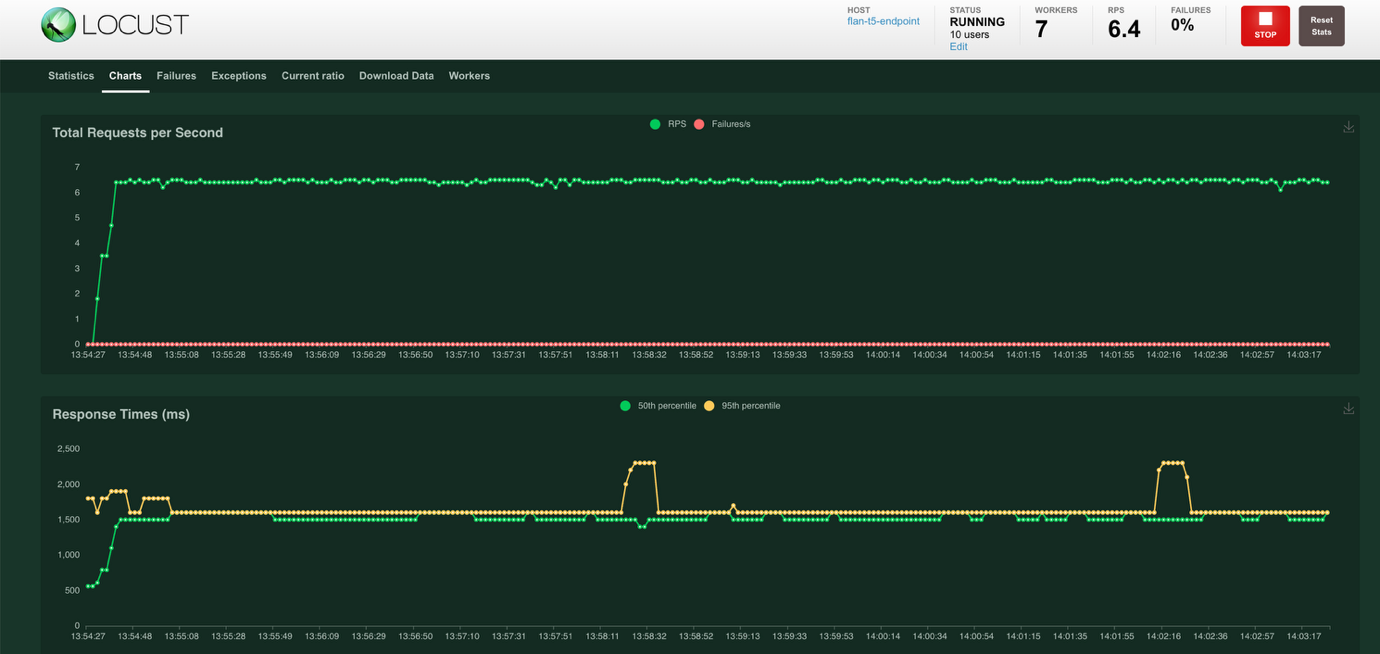
- 选择屏幕顶部的 Charts 以查看显示每秒总请求数和响应时间(毫秒)的图表。每秒总请求数图表以绿色显示成功请求,以红色显示失败请求。响应时间图表以绿色显示第五百分位响应时间,以黄色显示第九十五百分位响应时间。
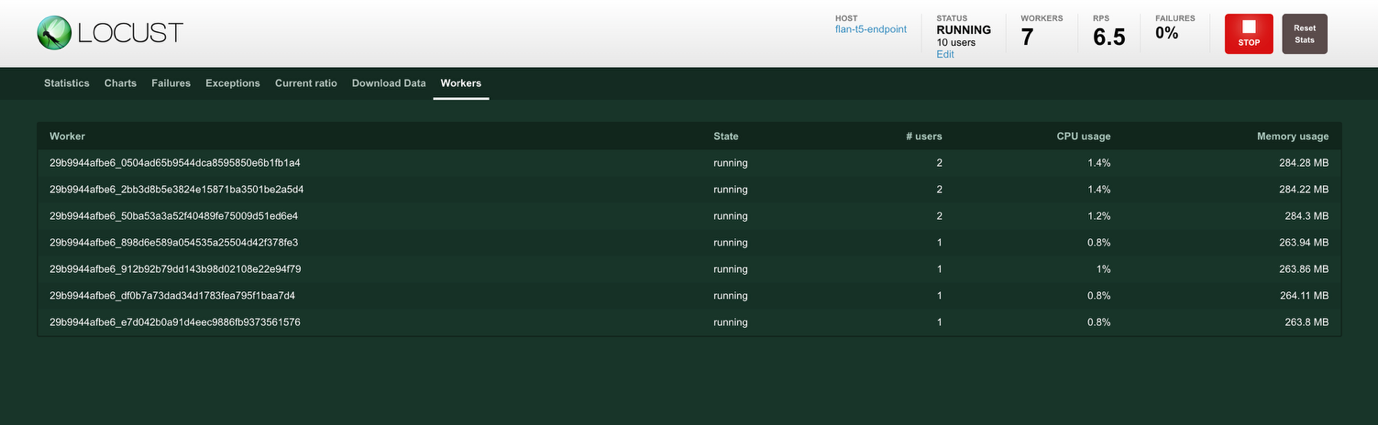
- 选择屏幕顶部的 Workers 以查看工作进程统计信息。创建工作进程以生成所需的负载。# users 显示工作进程生成的用户数,CPU usage 和 Memory Usage 显示工作进程的资源利用率。
- 您可以查看和下载最终统计数据以供分析。选择屏幕顶部的 Download Data 以查看数据下载选项。您可以从 Statistics、Failures、Exceptions 和 Charts 报告页面将数据下载为 CSV 文件。

- 在执行新会话之前,您必须停止当前的负载会话。选择 STOP RUNNING LOAD SESSION 以停止会话。如果已配置,数据可以上传到指定的 Amazon Simple Storage Service (Amazon S3) 存储桶中。请按照 高级 OLAF 用法第 3 项“负载测试报告的自动备份”中的说明操作,以配置将测试结果上传到 Amazon S3。
托管客户端
对于本文中描述的解决方案,您使用了桌面来托管 OLAF 容器并设置负载测试。选择使用您的桌面还是 Amazon Elastic Compute Cloud (Amazon EC2) 实例可能会影响延迟,因为往返时间会受到影响。网络带宽也会影响延迟。关键是根据客户使用端点的方式来标准化您用于运行测试的环境。
清理
完成此演示后,请移除任何不再需要的资源,以避免产生额外费用。
- 在 CloudShell 终端中运行以下命令以删除 SageMaker 端点:
aws cloudformation delete-stack --stack-name flan-t5-endpoint-stack- 运行以下命令以列出正在运行的 Docker 镜像
docker ps- 记下
container_id,然后运行以下命令停止 Docker 镜像。
docker stop <container_id>结论
在本文中,您学习了如何通过几个基本步骤设置 OLAF 并使用它来负载测试 SageMaker 端点。OLAF 代表了简化 ML 基础设施和模型服务成本优化的重要一步。通过本次演示,您已经看到了 OLAF 如何与 SageMaker 无缝集成,从而提供有关各种负载条件下端点性能的宝贵见解。OLAF 的主要优势包括:
- 设置简单,并与现有 SageMaker 端点集成
- 实时监控性能指标,包括延迟和吞吐量
- 详细的统计数据和可下载报告供分析
- 测试不同负载模式和并发级别的能力
- 支持多种模型类型和序列化选项
对于像 Observe.ai 这样需要高效扩展其 ML 运营的组织来说,OLAF 省去了开发定制测试基础设施和调试系统的需要。这意味着开发团队可以专注于其核心产品功能,同时确保 ML 基础架构的最佳性能和成本效益。随着 ML 的采用持续增长,像 OLAF 这样的工具在帮助组织优化其 ML 运营方面变得越来越有价值。无论您是运行少数模型还是管理大规模 ML 基础设施,OLAF 都能提供做出关于实例类型、扩展和资源分配的明智决策所需的见解。
在本次示例解决方案中,您使用了 AWS STS 服务生成的短期凭证,以从 OLAF 连接到 SageMaker。请确保在生产环境中采取必要的步骤来保护您的访问密钥和凭证。
要开始使用 OLAF,请访问 GitHub 仓库,并遵循本文中概述的安装步骤。该框架直观的界面和全面的监控功能使其成为希望优化 SageMaker 部署的组织的必备工具。
关于作者
 Aashraya Sachdeva 是一位技术领导者,在生成式 AI、产品开发和平台工程方面拥有深厚的专业知识。作为 Observe 的工程总监,他负责监督构建可扩展的、代理式的解决方案的团队,这些解决方案可以同时提升客户体验和运营效率。凭借在指导 ML 计划方面的丰富经验,从早期数据探索到部署和大规模运营,他为构建高性能平台带来了务实、注重可靠性的方法。在他的整个职业生涯中,他通过利用其 ML 背景来创建创新而实用的解决方案,在推出多个产品方面发挥了关键作用,同时持续在工程团队中培养协作、指导和技术卓越性。
Aashraya Sachdeva 是一位技术领导者,在生成式 AI、产品开发和平台工程方面拥有深厚的专业知识。作为 Observe 的工程总监,他负责监督构建可扩展的、代理式的解决方案的团队,这些解决方案可以同时提升客户体验和运营效率。凭借在指导 ML 计划方面的丰富经验,从早期数据探索到部署和大规模运营,他为构建高性能平台带来了务实、注重可靠性的方法。在他的整个职业生涯中,他通过利用其 ML 背景来创建创新而实用的解决方案,在推出多个产品方面发挥了关键作用,同时持续在工程团队中培养协作、指导和技术卓越性。
 Shibu Jacob 是亚马逊网络服务 (AWS) 的高级解决方案架构师,他帮助客户设计和实施云原生解决方案。凭借超过二十年在软件开发和架构方面的经验,Shibu 专注于容器化、微服务和事件驱动架构。他对 AI 在软件开发和架构设计中的变革潜力特别感兴趣。加入 AWS 之前,他在企业和初创公司工作了 20 年,为他目前的工作带来了丰富的实践经验。在工作之余,Shibu 喜欢关注一级方程式赛车、从事汽车 DIY 项目、进行长途公路旅行以及与家人共度时光。
Shibu Jacob 是亚马逊网络服务 (AWS) 的高级解决方案架构师,他帮助客户设计和实施云原生解决方案。凭借超过二十年在软件开发和架构方面的经验,Shibu 专注于容器化、微服务和事件驱动架构。他对 AI 在软件开发和架构设计中的变革潜力特别感兴趣。加入 AWS 之前,他在企业和初创公司工作了 20 年,为他目前的工作带来了丰富的实践经验。在工作之余,Shibu 喜欢关注一级方程式赛车、从事汽车 DIY 项目、进行长途公路旅行以及与家人共度时光。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区