



📢 转载信息
原文链接:https://machinelearningmastery.com/supervised-learning-the-foundation-of-predictive-modeling/
原文作者:Matthew Mayo

编者按:本文是我们关于可视化机器学习基础知识系列文章的最新一篇。
欢迎阅读我们关于可视化机器学习基础知识系列的最新文章。在本系列中,我们将致力于将重要且通常复杂的技术概念分解为直观的视觉指南,以帮助您掌握该领域的核心原理。本篇重点介绍监督学习,即预测建模的基础。
预测建模的基础
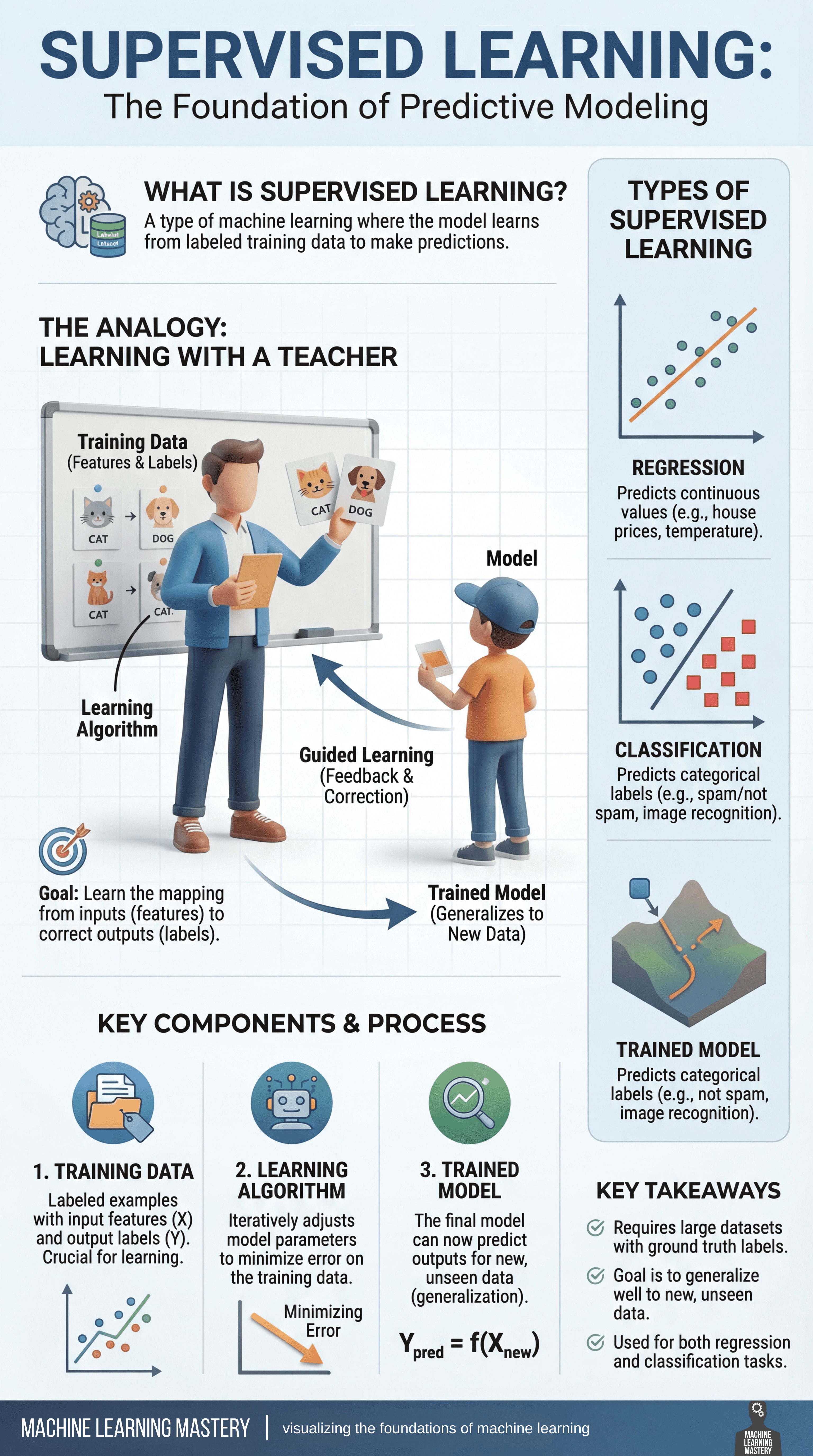
监督学习被广泛认为是机器学习中预测建模的基础。但为什么会这样呢?
其核心在于,这是一种学习范式,其中模型在标记数据上进行训练——即输入特征和正确输出(地面实况/Ground Truth)均已知的示例。通过从这些标记示例中学习,模型便能够在新的、未见过的数据上做出准确的预测。
理解监督学习的一个有益类比是“在老师指导下学习”。在训练过程中,模型会看到示例以及正确的答案,就像学生从指导者那里获得指导和纠正一样。模型的每一次预测都会与地面实况标签进行比较,系统会提供反馈并进行调整,以减少未来的错误。随着时间的推移,这个有指导的过程有助于模型内化输入与输出之间的关系。
监督学习的目标是学习一个可靠的从特征到标签的映射关系。这一过程围绕三个基本组成部分展开:
- 首先是训练数据,它由标记示例组成,是学习的基础;
- 其次是学习算法,它会迭代地调整模型参数,以最小化在训练数据上的预测误差;
- 最后,这个过程会产生训练好的模型,它具备将所学知识泛化到新数据上进行预测的能力。
监督学习问题通常分为两大主要类别:回归(Regression)任务侧重于预测连续值,例如房价或温度读数;而分类(Classification)任务则涉及预测离散类别,例如识别垃圾邮件或识别图像中的物体。尽管存在差异,两者都依赖于从标记示例中学习这一核心原则。
监督学习在许多现实世界的机器学习应用中起着核心作用。它通常需要带有可靠地面实况标签的大型、高质量数据集,其成功与否取决于训练好的模型在训练数据之外泛化得有多好。当得到有效应用时,监督学习能够让机器在广泛的领域内做出准确、可操作的预测。
下面的可视化图表对这些信息进行了简洁的总结,方便快速参考。您可以在此处下载高分辨率的信息图PDF。
监督学习:可视化机器学习基础知识(点击放大)
图片来源:作者
机器学习精通资源
以下是一些关于监督学习的精选资源供您深入学习:
- 机器学习中的监督与无监督算法 – 这篇入门级文章解释了监督学习、无监督学习和半监督学习之间的区别,概述了标记数据与非标记数据的使用方式,并重点介绍了每种方法的常见算法。
关键收获: 了解何时使用标记数据与非标记数据是选择正确学习范式的根本。 - 机器学习中的简单线性回归教程 – 这个实用、对初学者友好的教程介绍了简单线性回归,解释了如何使用直线模型来描述和预测单个输入变量与数值输出之间的关系。
关键收获: 简单线性回归模型使用由学习到的系数定义的直线来描述关系。 - 机器学习中的线性回归 – 这篇介绍性文章提供了对线性回归的更广泛概述,涵盖了该算法的工作原理、关键假设及其在现实世界机器学习工作流中的应用。
关键收获: 线性回归是数值预测任务的一个核心基准算法。 - 机器学习中的4种分类任务类型 – 本文使用清晰的解释和实用的例子,解释了四种主要的分类问题类型——二元分类、多类分类、多标签分类和不平衡分类。
关键收获: 正确识别分类问题的类型可以指导模型选择和评估策略。 - 多类分类中的一对余(One-vs-Rest)和一对一(One-vs-One) – 这个实用教程解释了如何使用一对余和一对一策略将二元分类器扩展到多类问题,并指导何时使用每种方法。
关键收获: 多类问题可以通过将其分解为多个二元分类任务来解决。
敬请期待我们关于可视化机器学习基础知识系列的后续文章。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区