



📢 转载信息
原文链接:https://www.kdnuggets.com/top-7-open-source-ai-coding-models-you-are-missing-out-on
原文作者:Abid Ali Awan

Image by Author
# 引言
如今,大多数使用人工智能(AI)编码助手的人都依赖于云端工具,如Claude Code、GitHub Copilot、Cursor等等。它们无疑非常强大。但一个巨大的权衡因素就隐藏在显眼之处:您的代码必须发送到别人的服务器才能使这些工具正常工作。
这意味着您的每一个函数、每一个应用程序编程接口(API)密钥、每一个内部架构选择,在您得到答案之前,都会被传输给Anthropic、OpenAI或其他提供商。即使他们承诺保护隐私,许多团队也无法承担这种风险。特别是当您处理以下内容时:
- 专有或机密代码库
- 企业客户系统
- 研究或政府工作负载
- 任何受保密协议(NDA)约束的内容
这就是本地、开源编码模型能够改变游戏规则的地方。
在本地运行您自己的AI模型可以为您带来控制权、隐私和安全性。代码不会离开您的机器。没有外部日志。无需“相信我们”。最重要的是,如果您已经拥有强大的硬件,您可以节省数千美元的API和订阅费用。
在本文中,我们将介绍七款开源权重编码模型,它们在编码基准测试中持续名列前茅,并迅速成为专有工具的真正替代品。
如果您想要简短版本,请滚动到文章底部查看所有七个模型的快速比较表。
# 1. Moonshot AI 的 Kimi-K2-Thinking
由Moonshot AI开发的Kimi-K2-Thinking是一款先进的开源思维模型,设计为一个工具使用代理,能够逐步推理,同时动态调用函数和服务。它在200到300次连续工具调用中保持稳定的长程代理能力——这比先前系统出现的30到50步的漂移有了显著改进。这使得研究、编码和写作中的自主工作流程成为可能。
在架构上,K2 Thinking模型拥有1万亿个参数,其中320亿在每次处理token时是活跃的。它包含384个专家(每个token选择8个,1个共享),61层(包含1个稠密层),以及7,168个注意力维度(64个头)。它使用MLA注意力和SwiGLU激活函数。该模型支持256,000个token的上下文窗口,词汇量为160,000。它是一个原生的INT4模型,采用了训练后量化感知训练(QAT),从而在低延迟模式下实现了大约2倍的速度提升,同时也减少了GPU内存占用。
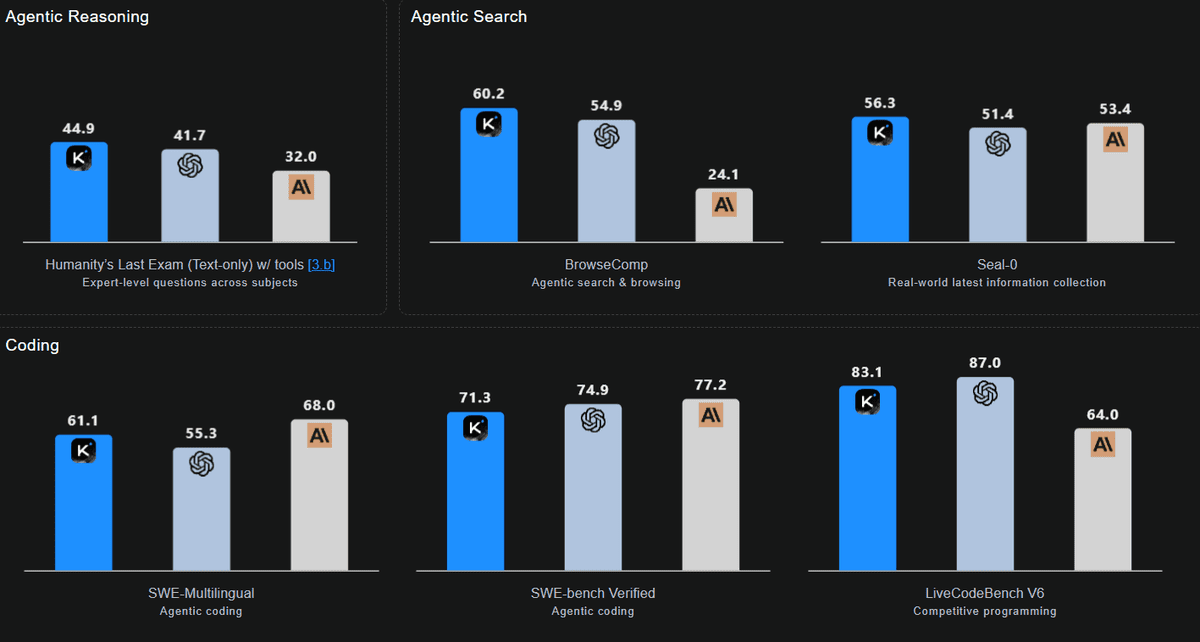
Image by Author
在基准测试中,K2 Thinking取得了令人瞩目的成果,特别是在需要长程推理和工具使用的领域。其编码性能非常均衡,得分如下:SWE-bench Verified 为 71.3,Multi-SWE 为 41.9,SciCode 为 44.8,Terminal-Bench 为 47.1。其最突出的表现体现在LiveCodeBench V6中,得分为83.1,特别证明了其在多语言和代理工作流程中的优势。
# 2. MiniMaxAI 的 MiniMax‑M2
MiniMax-M2重新定义了代理工作流的效率。它是一个紧凑、快速且具有成本效益的专家混合(MoE)模型,总参数量为2300亿,但在每次处理token时仅激活100亿。通过路由最相关的专家,MiniMax-M2实现了通常与更大模型相关的端到端工具使用性能,同时降低了延迟、成本和内存占用。这使其非常适合交互式代理和批量采样。
它旨在实现精英级的编码和代理任务,同时不牺牲通用智能,重点关注“计划 → 行动 → 验证”循环。由于其100亿的激活占用,这些循环保持了响应速度。
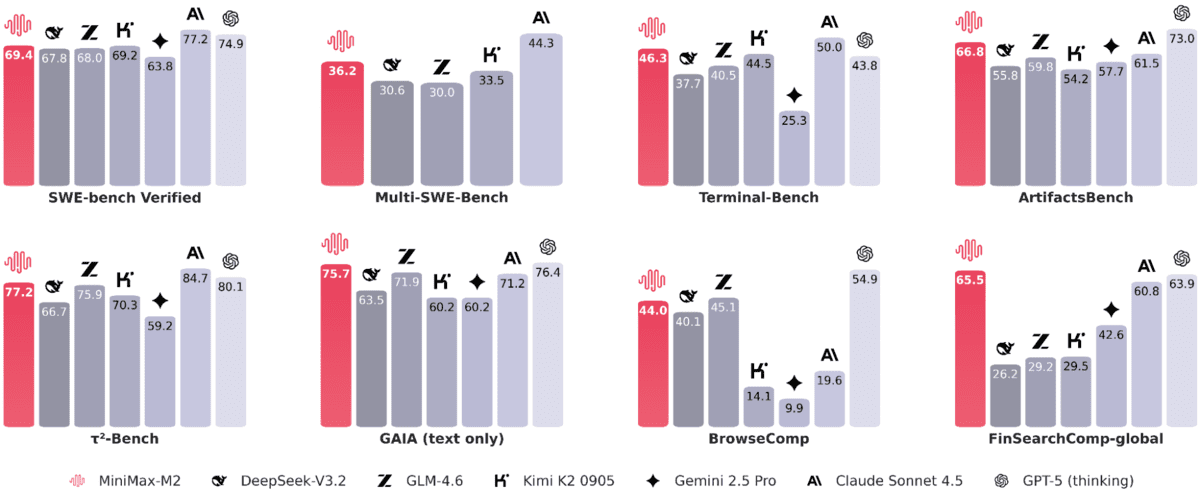
Image by Author
在实际的编码和代理基准测试中,报告的结果展示了强大的实用效果:SWE-bench 获得 69.4 分,Multi-SWE-Bench 获得 36.2 分,SWE-bench Multilingual 获得 56.5 分,Terminal-Bench 获得 46.3 分,ArtifactsBench 获得 66.8 分。对于Web和研究代理,得分如下:BrowseComp 44(中文得分为48.5),GAIA (文本) 75.7,xbench-DeepSearch 72,τ²-Bench 77.2,HLE (含工具) 31.8,以及FinSearchComp-global 65.5。
# 3. OpenAI 的 GPT‑OSS‑120B
GPT-OSS-120b是一个开源权重MoE模型,专为通用、高推理工作负载的生产环境而设计。它经过优化,可在单个80GB GPU上运行,总共有1170亿参数,每次处理token时有51亿活跃参数。
GPT-OSS-120b的关键能力包括可配置的推理努力级别(低、中、高)、用于调试的全链式思维(CoT)访问(非最终用户使用)、原生的代理工具,如函数调用、浏览、Python集成和结构化输出,以及完整的微调支持。此外,还提供了一个较小的伴随模型GPT-OSS-120b,以满足需要更低延迟和定制化本地/专业化应用的用户需求。
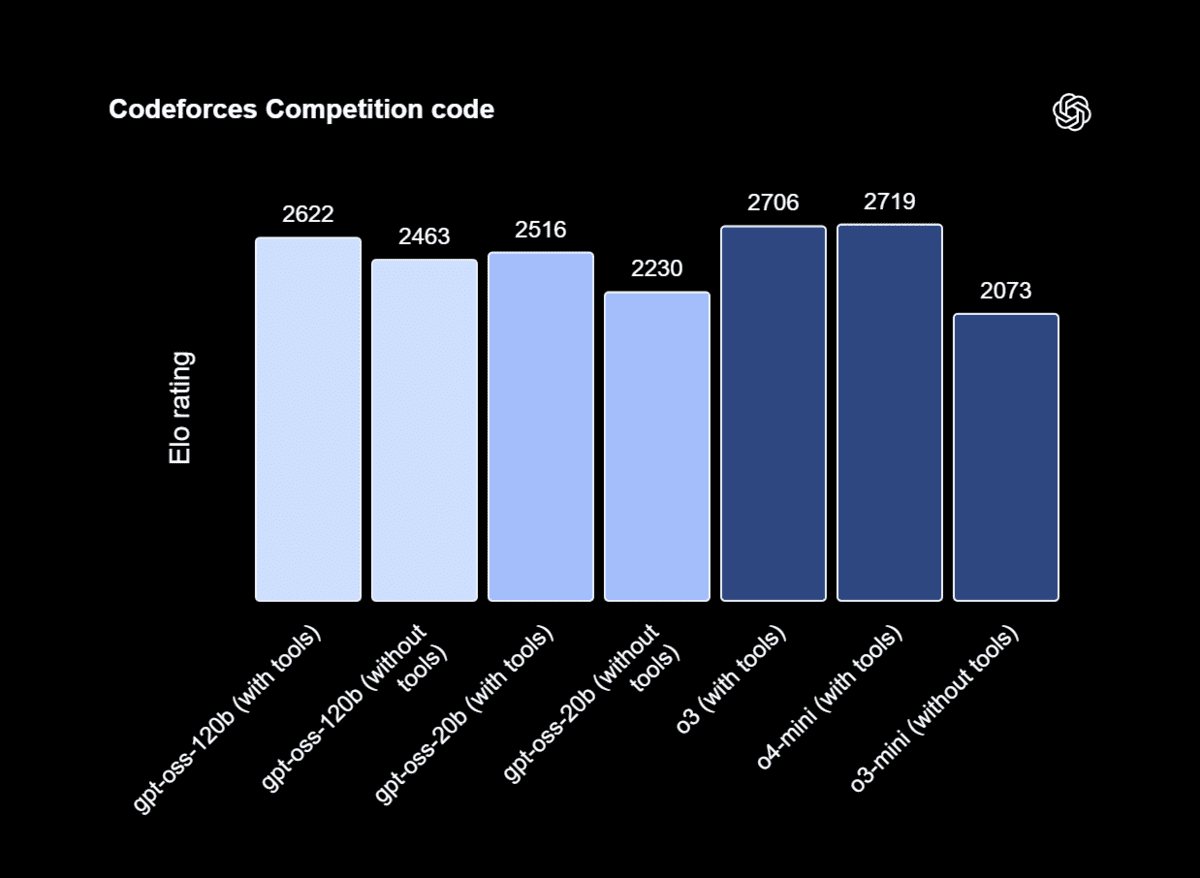
Image by Author
在外部基准测试中,GPT-OSS-120b在Artificial Analysis Intelligence Index中排名第三。基于Artificial Analysis对质量、输出速度和延迟的跨模型比较,它在性能和速度方面相对于其大小表现最佳。
GPT-OSS-120b在竞争性编码(Codeforces)、通用问题解决(MMLU、HLE)和工具使用(TauBench)等方面超越了o3-mini,并与o4-mini的能力相匹配或超越。此外,它在健康评估(HealthBench)和竞赛数学(AIME 2024和2025)方面优于o4-mini。
# 4. DeepSeek AI 的 DeepSeek‑V3.2‑Exp
DeepSeek-V3.2-Exp是DeepSeek AI下一代架构的实验性中间步骤。它建立在V3.1-Terminus之上,引入了DeepSeek稀疏注意力(DSA),这是一种细粒度的稀疏注意力机制,旨在提高长上下文场景下的训练和推理效率。
本次发布的主要重点是验证在扩展序列长度的同时保持模型行为稳定性的效率提升。为了隔离DSA的影响,训练配置特意与V3.1保持一致。结果表明,输出质量几乎没有变化。
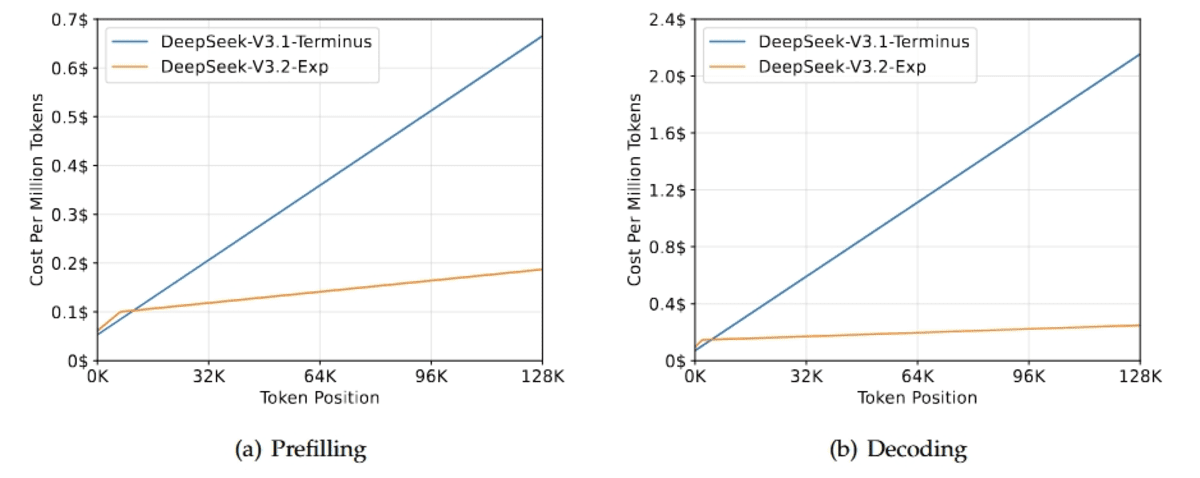
Image by Author
在公共基准测试中,V3.2-Exp的性能与V3.1-Terminus相似,仅在性能上略有波动:它在MMLU-Pro上匹配85.0分,在LiveCodeBench上接近74分,在GPQA(79.9对比80.7)和HLE(19.8对比21.7)上略有差异。此外,在AIME 2025(89.3对比88.4)和Codeforces(2121对比2046)上有所提升。
# 5. Z.ai 的 GLM‑4.6
与GLM‑4.5相比,GLM‑4.6将上下文窗口从128K扩展到了200K token。这一增强使得更复杂和长程的工作流程成为可能,而不会丢失信息。
GLM‑4.6还提供了卓越的编码性能,在代码基准测试中取得了更高的分数,并在Claude Code、Cline、Roo Code和Kilo Code等工具中提供了更强的实际效果,包括更精细的前端生成。
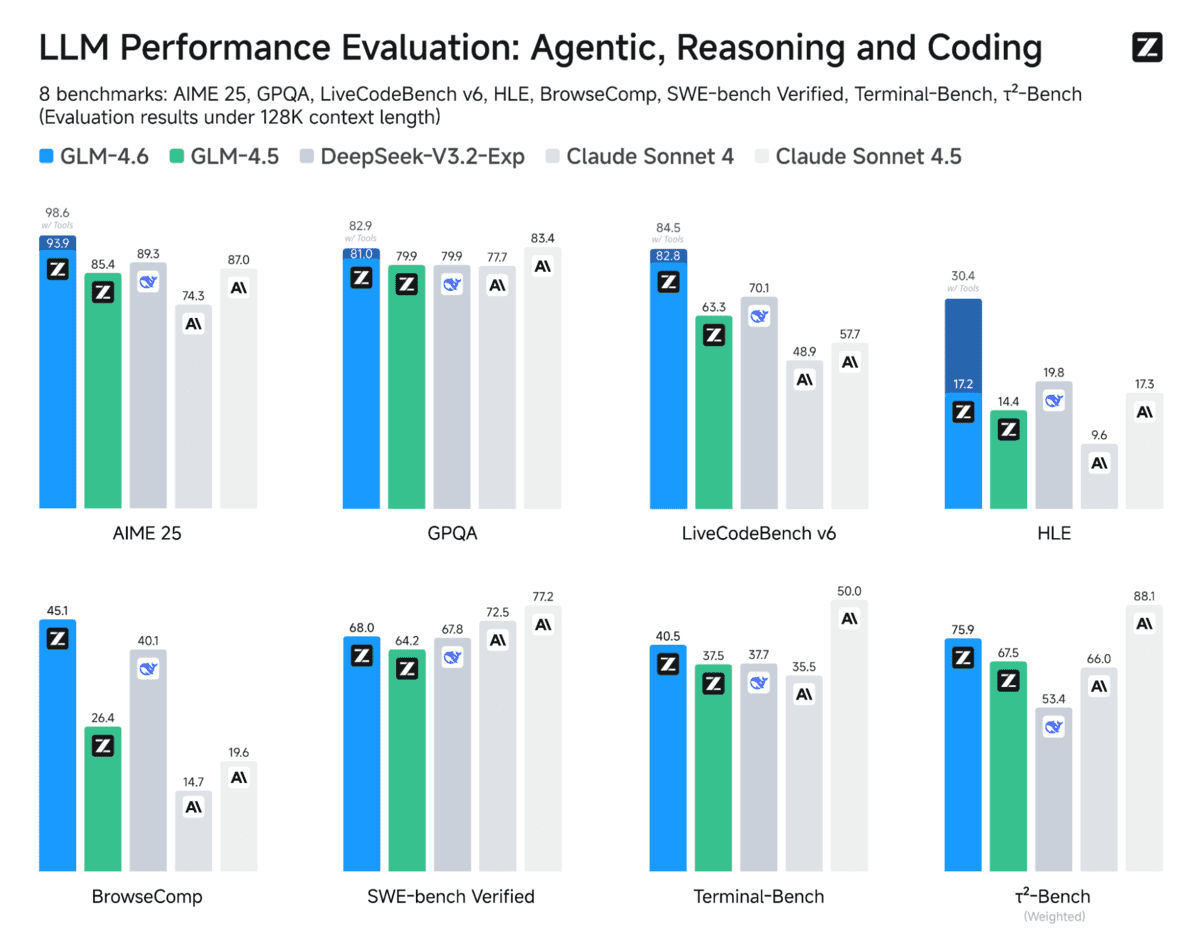
Image by Author
此外,GLM‑4.6在推理过程中引入了先进的推理能力和工具使用,从而提升了其整体性能。此版本拥有功能更强大的代理,增强了工具使用和搜索代理的性能,并与代理框架进行了更紧密的集成。
在涵盖代理、推理和编码的八个公共基准测试中,GLM‑4.6相对于GLM‑4.5显示出明显的改进,并与DeepSeek‑V3.1‑Terminus和Claude Sonnet 4等模型保持竞争优势。
# 6. 阿里云 的 Qwen3‑235B‑A22B‑Instruct‑2507
Qwen3-235B-A22B-Instruct-2507是阿里云旗舰模型的非思考(non-thinking)变体,专为实际应用设计,无需揭示其推理过程。它在通用能力方面带来了显著的升级,包括指令遵循、逻辑推理、数学、科学、编码和工具使用。此外,它在多种语言的长尾知识方面取得了实质性进展,并展示出与用户对主观和开放式任务偏好的更好对齐。
作为一个非思考模型,其主要目标是生成直接答案,而不是提供推理痕迹,侧重于日常工作流程的帮助性和高质量文本。
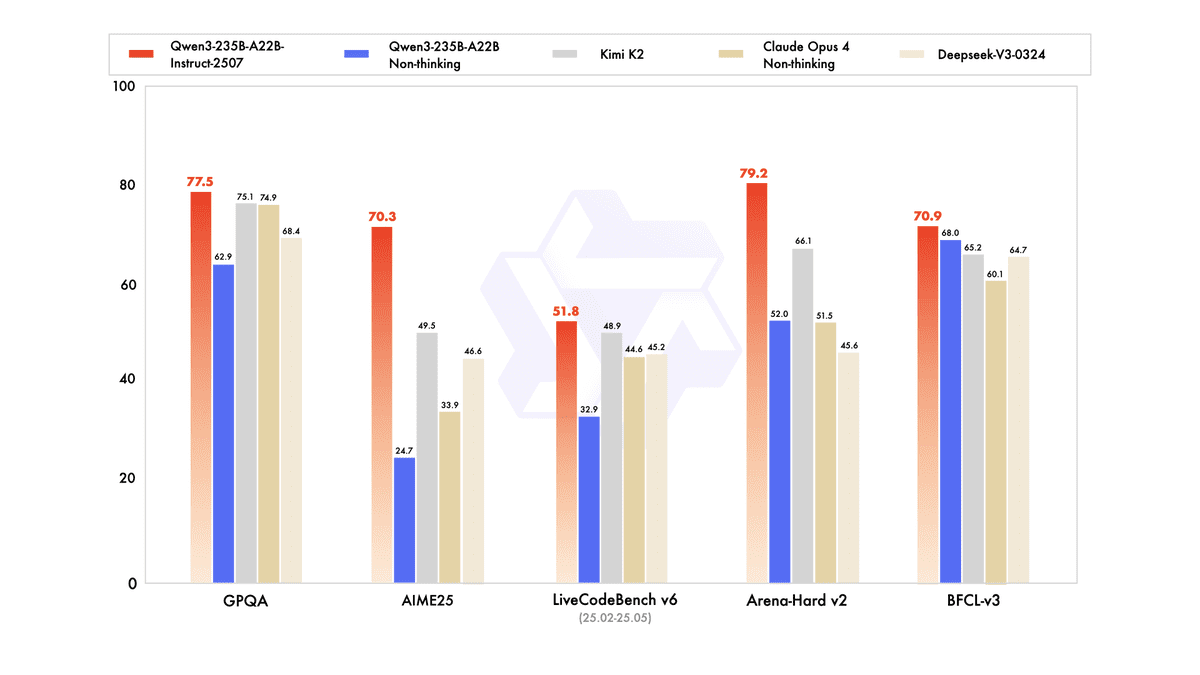
Image by Author
在与代理、推理和编码相关的公开评估中,它显示出相对于先前版本(如Kimi-K2、DeepSeek-V3-0324和Claude-Opus4-Non-thinking)的明显改进,并如第三方报告所述,相对于领先的开源和专有模型保持了竞争优势。
# 7. ServiceNow‑AI 的 Apriel‑1.5‑15B‑Thinker
Apriel-1.5-15b-Thinker是ServiceNow AI推出的Apriel小型语言模型(SLM)系列中的多模态推理模型。它在先前的文本模型基础上引入了图像推理能力,重点在于稳健的中期训练方案,包括在文本和图像上进行广泛的持续预训练,随后进行仅文本的监督微调(SFT),而没有进行任何图像SFT或强化学习(RL)。尽管其参数量仅为150亿,可以运行在单个GPU上,但它声称的上下文长度约为131,000个token。该模型旨在实现与比其大十倍的模型的性能和效率相当的水平,尤其是在推理任务上。
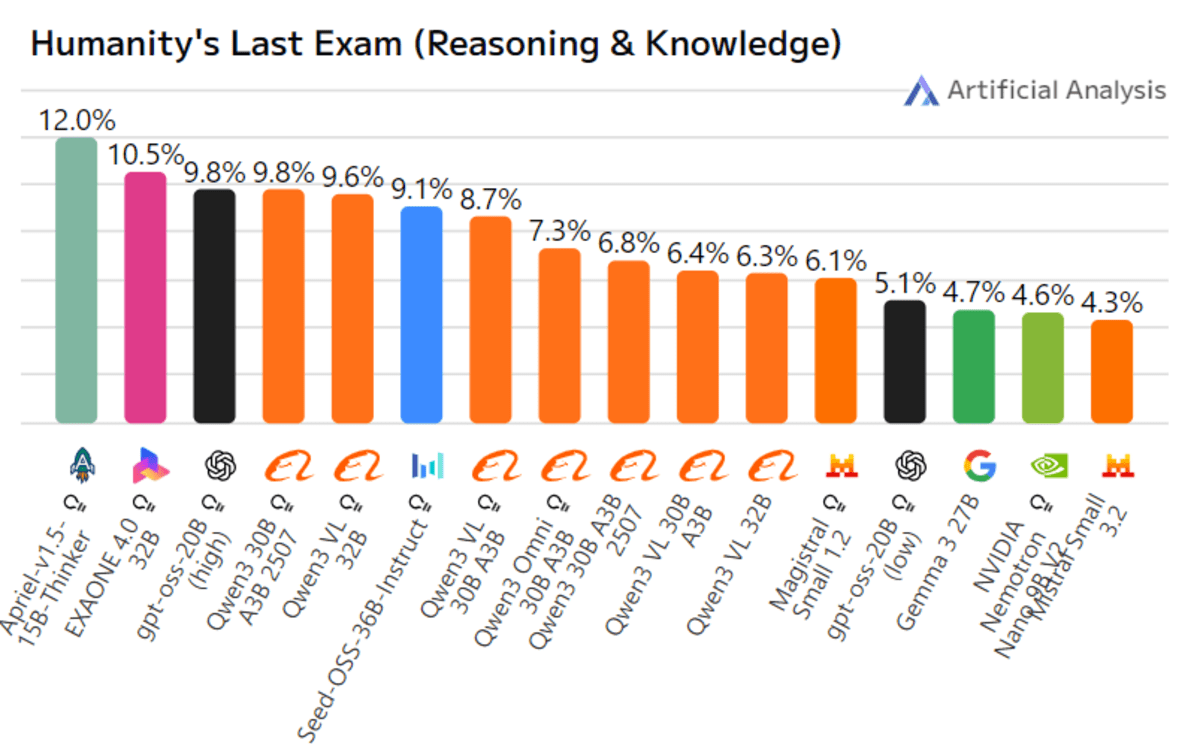
Image by Author
在公开基准测试中,Apriel-1.5-15B-Thinker在Artificial Analysis Intelligence Index上获得52分,与DeepSeek-R1-0528和Gemini-Flash等模型具有竞争力。据称,它是得分高于50的模型的十分之一大小。此外,它作为一个企业代理表现出色,在Tau2 Bench Telecom上获得68分,在IFBench上获得62分。
# 总结表
以下是针对您特定用例的开源模型摘要:
| 模型 | 大小 / 上下文 | 关键优势 | 最适合 |
|---|---|---|---|
| Kimi-K2-Thinking
(MoonshotAI) |
1T / 32B 活跃, 256K ctx | 稳定的长程工具使用(约200–300次调用);强大的多语言和代理编码能力 | 需要持续规划的自主研究/编码代理 |
| MiniMax-M2
(MiniMaxAI) |
230B / 10B 活跃, 128k ctx | 高效率 + 低延迟的“计划→行动→验证”循环 | 关注成本和速度的可扩展生产代理 |
| GPT-OSS-120B
(OpenAI) |
117B / 5.1B 活跃, 128k ctx | 原生工具支持下的通用高推理能力;完全可微调 | 企业/私有部署、竞赛编码、可靠的工具使用 |
| DeepSeek-V3.2-Exp | 671B / 37B 活跃, 128K ctx | DeepSeek稀疏注意力(DSA),高效的长上下文推理 | 需要长文档效率的开发/研究管道 |
| GLM-4.6
(Z.ai) |
355B / 32B 活跃, 200K ctx | 强大的编码+推理;推理过程中工具使用得到改进 | 编码助手、代理框架、Claude Code风格的工作流 |
| Qwen3-235B
(阿里云) |
235B, 256K ctx | 高质量的直接回答;多语言;无需CoT输出的工具使用 | 大规模代码生成和重构 |
| Apriel-1.5-15B-Thinker
(ServiceNow) |
15B, ~131K ctx | 紧凑的多模态(文本+图像)推理,面向企业级应用 | 设备上/私有云代理、DevOps自动化 |
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学家专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的博客。Abid拥有技术管理硕士学位和电信工程学士学位。他的愿景是构建一个使用图神经网络的产品,帮助与心理健康作斗争的学生。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区