



📢 转载信息
原文作者:Ankur Mehrotra
随着使生成式 AI 模型可用的工具和服务的进步,企业现在可以像竞争对手一样使用相同的 基础模型 (FMs)。真正的差异化来自于构建高度定制化的 AI,这是竞争对手无法轻易复制的。尽管当今的 FM 具有广博的知识和推理能力,真正非常智能,但没有上下文的智能仅仅是潜力。模型知道如何思考,但它不知道您如何思考、您的词汇、您的数据模式或您的行业限制。
构建深入理解您业务的模型,取决于您如何让模型从您的数据和偏好中学习。模型通过模仿人类学习的逐步过程来学习:它们首先通过预训练获取一般世界知识,然后通过监督微调获得专业知识,最后通过 直接偏好优化 (DPO) 等技术学习与特定偏好保持一致。在推理阶段,模型可以将所学的一切应用于现实世界的任务,并且可以通过低秩适应 (LoRA) 等参数高效方法持续适应,而无需重新训练整个基础模型。
这个学习旅程涵盖了从预训练大规模 FM 到针对特定用例定制它们的整个过程,而 Amazon SageMaker AI 现在已覆盖这一整个范围的功能。
在 AWS re:Invent 2025 上,Amazon SageMaker AI 宣布了重大的进步,改变了组织处理模型定制和大规模训练的方式。新功能解决了两个长期存在的挑战:定制 FM 以适应特定用例所需的复杂性和时间,以及导致数周训练进度中断的昂贵的基础设施故障。
自 2017 年推出 Amazon SageMaker AI 以来,我们一直致力于使不同技能水平的构建者都能轻松进行 AI 开发。SageMaker AI 自推出以来已引入了 450 多项功能,持续消除阻碍创新的障碍。本文将探讨新的无服务器模型定制功能、弹性训练、无检查点训练和无服务器 MLflow 如何协同工作,将您的 AI 开发从数月加速到数天。
利用先进的强化学习实现无服务器 AI 模型定制
Amazon SageMaker AI 中 新的无服务器模型定制 功能,将传统上需要数月才能完成的过程转变为数天即可完成。对于希望获得最高级别抽象的 AI 开发人员,我们正在推出一个 AI 代理引导的工作流程(预览版),使先进的模型定制可以通过自然语言实现。
您不再需要精通强化学习技术,只需用通俗易懂的语言描述您的业务目标即可。AI 代理会进行多轮对话以理解您的用例,然后生成一个全面的规范,其中包括数据集指南、评估标准、相关指标以及您的团队可以在无需专业知识的情况下实施的推荐模型。
AI 代理工作流程支持监督微调 (SFT)、直接偏好优化 (DPO)、基于 AI 反馈的强化学习 (RLAIF) 和基于可验证奖励的强化学习 (RLVR)。模型可以使用这些强化学习功能从人类偏好和可验证的结果中学习,从而创建更贴合您业务目标的 AI。当真实世界数据有限时,您还可以生成合成数据,分析数据质量,并处理准确性和负责任的 AI 控制的训练和评估。这种方法完全是无服务器的,以消除基础设施复杂性。
对于希望对定制过程拥有更多控制权的 AI 开发人员,SageMaker AI 提供了一个带有内置最佳实践的简单界面。通过 SageMaker Studio,您可以从流行的模型中进行选择,包括 Amazon Nova、Meta 的 Llama、Qwen、DeepSeek 和 GPT-OSS,然后选择您首选的定制技术。
自助式工作流程在每一步都提供了灵活性。您可以上传自己的数据集或从现有数据集中进行选择,使用推荐的默认值配置超参数(如批大小和学习率),并选择参数高效微调 (LoRA) 或完全微调。该界面与新引入的 MLflow 功能集成,可自动跟踪实验,让您可以通过单一界面了解训练进度和模型性能。
与 AI 代理方法一样,自助式定制是完全无服务器的。SageMaker AI 自动处理计算配置、扩展和优化,因此您可以专注于模型开发,而不是基础设施管理。通过按代币付费的定价模式,您可以避免选择实例类型或管理集群的开销。
Collinear AI 使用 SageMaker AI 的无服务器模型定制功能,将其实验周期从数周缩短到数天。Collinear AI 联合创始人 Soumyadeep Bakshi 表示:
“在 Collinear,我们为前沿 AI 实验室和《财富》500 强企业构建策划的数据集和模拟环境,以改进他们的模型。微调 AI 模型对于创建高保真模拟至关重要,它过去需要为训练、评估和部署拼接不同的系统。现在,借助新的 Amazon SageMaker AI 无服务器模型定制功能,我们有了一个统一的方式,使我们能够将实验周期从数周缩短到数天。这种端到端的无服务器工具帮助我们专注于重要的事情:为客户构建更好的训练数据和模拟,而不是维护基础设施或处理不同的平台。”
弥合模型定制与预训练之间的鸿沟
虽然无服务器模型定制通过微调和强化学习加速了特定用例的开发,但组织也在快速扩展生成式 AI 在业务的许多方面的应用。需要深度领域知识或特定业务背景的应用,需要真正理解其专有知识、工作流程和独特要求的模型。像提示工程和 检索增强生成 (RAG) 这样的技术对许多用例都很有效,但在将专业知识嵌入到模型的核心理解方面存在根本性限制。当组织尝试使用专有数据进行更深层次的定制(如持续预训练 (CPT))时,它们通常会遇到灾难性遗忘,即模型在学习新内容时会失去其基础能力。
Amazon SageMaker AI 支持模型开发的整个谱系,从具有先进强化学习的无服务器定制,到从早期检查点构建前沿模型。对于拥有专有数据、需要超越定制所能提供的深度领域专业知识的组织,我们最近引入了一项新功能,解决了传统方法的局限性,同时保留了基础模型的能力。
上周,我们推出了 Amazon Nova Forge。该新服务可在 Amazon SageMaker AI 上使用,使 AI 开发人员有机会使用 Amazon Nova 构建自己的前沿模型。您可以使用 Nova Forge 从预训练、中训练和后训练阶段的早期检查点开始模型开发——这意味着您可以在最佳阶段进行干预,而无需等到训练完成。您可以在 SageMaker AI 的完全托管基础设施上,使用演示的配方,在整个训练阶段将您的专有数据与 Amazon Nova 策划的数据混合。这种数据混合方法与仅使用原始数据训练相比,可显著减少灾难性遗忘。这有助于在纳入您的专业知识的同时,保留基础技能,包括核心智能、通用指令遵循能力和安全优势。Nova Forge 是构建您自己的前沿模型最简单、最具成本效益的方式。
以下视频介绍了 Amazon Nova Forge。
Nova Forge 专为拥有专有或行业特定数据的组织设计,希望构建真正理解其领域的 AI,包括:
- 制造与自动化 – 构建理解专业流程和设备数据的模型
- 研究与开发 – 创建基于专有研究数据训练的模型
- 内容与媒体 – 开发理解品牌声音和内容标准模型
- 专业行业 – 针对行业特定术语、法规和最佳实践进行训练的模型
像野村综合研究所 (Nomura Research Institute) 这样的公司正在使用 Amazon Nova Forge,通过结合 Amazon Nova 策划的数据和他们的专有数据集,来构建行业特定的 大型语言模型 (LLMs)。
野村综合研究所人工智能主管兼董事总经理 Inaba Takahiko 表示:
“Nova Forge 使我们能够构建行业特定的 LLM,作为开源模型的一个引人注目的替代方案。在 SageMaker AI 上运行并使用托管训练基础设施,我们可以通过结合 Amazon Nova 策划的数据和我们的专有数据集,高效地开发像我们的日本金融服务 LLM 这样的专业模型。”
弹性训练,实现大规模智能资源管理
随着推理工作负载随流量模式扩展、完成的实验释放资源以及新训练作业的优先级发生变化,对 AI 加速器的需求不断波动。传统的训练工作负载仍然锁定在其初始计算分配中,如果没有手动干预,就无法利用空闲容量——这个过程每周会消耗工程师数小时的时间。
Amazon SageMaker HyperPod 上的弹性训练 改变了这种动态。训练作业现在根据计算资源的可用性自动扩展,扩展以吸收空闲的 AI 加速器并最大限度地提高基础设施利用率。当需要更高优先级的负载(如推理或评估)时,训练会优雅地缩减规模以用更少的资源继续,而不是完全停止。

技术架构通过在不同的数据并行配置中保持全局批大小和学习率,在整个缩放转换中保持训练质量。这支持了无论当前规模如何,都能实现一致的收敛特性。SageMaker HyperPod 训练运算符通过与 Kubernetes 控制平面的集成来协调缩放决策,持续监控集群状态,包括 Pod 生命周期事件、节点可用性变化和资源调度器优先级信号。
入门非常简单。针对 Meta 的 Llama 和 GPT-OSS 等公开可用的 FM 的新的弹性 SageMaker HyperPod 配方,只需要 YAML 配置更新来指定弹性策略,而无需代码更改。
Salesforce 正在使用弹性训练来自动扩展工作负载并吸收空闲的 GPU,他们解释说,弹性训练“将使我们的工作负载能够自动扩展以吸收可用的空闲 GPU,并无缝释放资源,所有这些都不会中断开发周期。最重要的是,它将为我们节省手动重新配置作业以匹配可用计算所花费的时间,我们可以将这些时间重新投入到创新中。”
通过无检查点训练最大限度地减少恢复停机时间
基础设施故障一直是大型训练中进步的敌人。可能需要数周的训练运行可能因单个节点故障而中断,迫使您从上一个检查点重新开始,损失数小时甚至数天的昂贵 GPU 时间。传统的基于检查点的恢复涉及顺序阶段——作业终止和重启、进程发现和网络设置、检查点检索、GPU 上下文重新初始化以及训练循环恢复。当发生故障时,整个集群必须等待所有阶段完成后才能恢复训练。
Amazon SageMaker HyperPod 上的无检查点训练消除了这一瓶颈。系统在分布式集群中维护连续的模型状态保存,自动替换有故障的组件,并通过健康 AI 加速器的模型状态的点对点传输来恢复训练。当基础设施出现故障时,恢复在数秒内完成,无需任何手动干预。以下视频介绍了无检查点训练。
这在拥有数千个 AI 加速器的集群上实现了高达 95% 的训练良好率,意味着计算基础设施高达 95% 的时间都在积极用于训练作业。现在您可以专注于创新,而不是基础设施管理,将上市时间缩短数周。
Intercom 已经将其无检查点训练集成到其管道中,以消除手动检查点恢复,他们表示:
“在 Intercom,我们不断训练新模型来改进 Fin,我们非常高兴将无检查点训练集成到我们的管道中。这将完全消除手动检查点恢复的需要。结合弹性训练,它将使我们能够以更低的成本更快地为 Fin 带来改进。”
无服务器 MLflow:为每位 AI 开发人员提供可观测性
无论是在定制模型还是大规模训练,您都需要跟踪实验、观察行为和评估性能的功能。然而,管理 MLflow 基础设施传统上要求管理员持续维护和扩展跟踪服务器、做出复杂的容量规划决策,并为数据隔离部署单独的实例。这种基础设施负担将资源从核心 AI 开发中分散开来。
Amazon SageMaker AI 现在提供无服务器 MLflow 功能,消除了这种复杂性。您可以开始跟踪、比较和评估实验,而无需等待基础设施设置。MLflow 动态扩展以提供对要求苛刻且不可预测的模型开发任务的快速性能,然后在空闲时缩减规模。以下屏幕截图显示了 SageMaker AI UI 中的 MLFlow 应用程序。
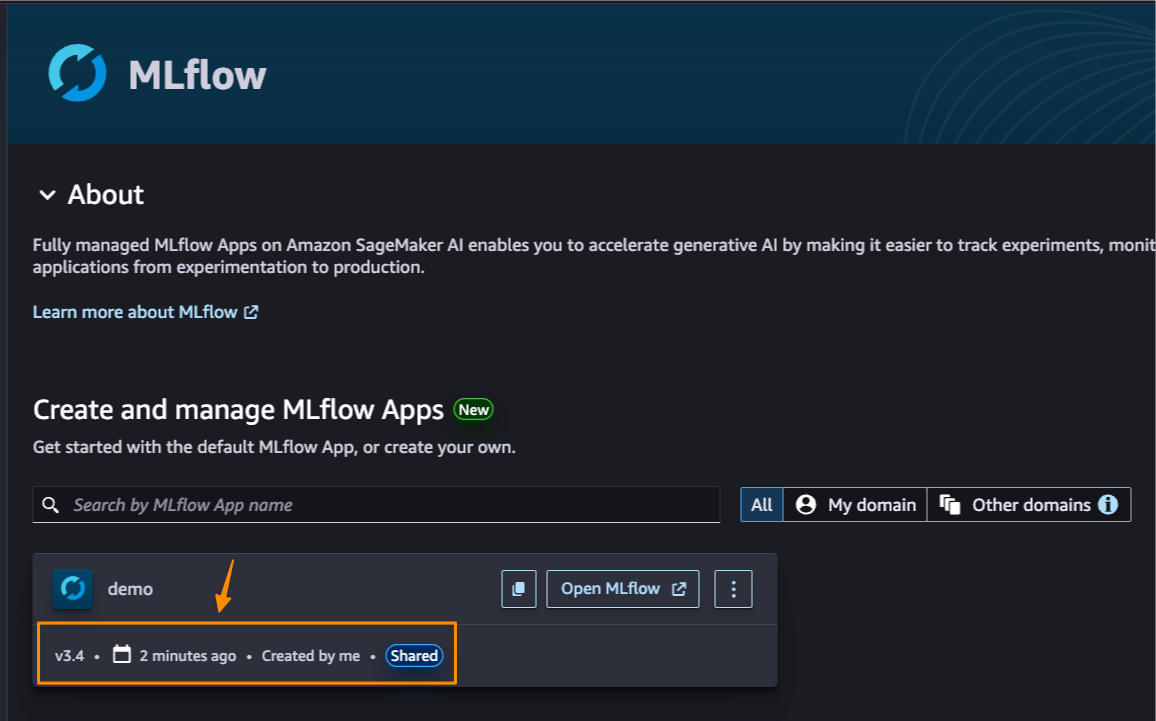
该功能与 Amazon SageMaker AI 无服务器模型定制原生集成,因此您可以通过单一界面可视化正在进行的训练作业和评估。高级跟踪功能有助于快速识别代理工作流和多步骤应用程序中的错误或意外行为。团队可以使用 MLflow Prompt Registry 在组织内对提示进行版本控制、跟踪和重用,从而保持一致性并改善协作。
与 SageMaker 模型注册表的集成提供了无缝的模型治理,自动将 MLflow 中注册的模型与生产生命周期同步。当模型达到所需的准确性和性能目标后,只需单击几下,即可将其部署到 SageMaker AI 推理端点。
管理员可以通过使用 AWS 资源访问管理器 (AWS RAM) 设置跨账户访问来帮助提高生产力,从而简化跨组织边界的协作。无服务器 MLflow 功能免费提供,并自动升级到最新版本的 MLflow,让您可以在没有维护窗口或迁移工作的情况下使用最新功能。
世界自然基金会 (Wildlife Conservation Society) 正在使用这项新功能来提高生产力并加快洞察获取速度。WCS 的 MERMAID 首席软件工程师 Kim Fisher 表示:
“WCS 正在通过 MERMAID 推进全球珊瑚礁保护工作,MERMAID 是一个开源平台,利用 ML 模型分析来自世界各地科学家的珊瑚礁照片。Amazon SageMaker 与 MLflow 合作,通过消除配置 MLflow 跟踪服务器或在我们基础设施需求变化时管理容量的需要,提高了我们的生产力。通过让我们的团队完全专注于模型创新,我们正在加速部署时间,从而向海洋科学家和管理者提供关键的云驱动见解。”
加速各个级别的 AI 创新
这些公告不仅仅是个别的功能改进——它们建立了一个全面的 AI 模型开发系统,可以在构建者旅程的任何阶段满足他们的需求。从自然语言引导的定制到自主指导的工作流程,从智能资源管理到容错训练,从实验跟踪到生产部署,Amazon SageMaker AI 提供了将 AI 想法转化为生产现实的完整工具集。
开始使用
新的 SageMaker AI 模型定制和 SageMaker HyperPod 功能现已在 AWS 区域全球范围内提供。现有的 SageMaker AI 客户可以通过 SageMaker AI 控制台访问这些功能,新客户可以利用 AWS 免费套餐开始。
有关 Amazon SageMaker AI 最新功能的更多信息,请访问 aws.amazon.com/sagemaker/ai。
关于作者
 Ankur Mehrotra 于 2008 年加入亚马逊,目前担任 Amazon SageMaker AI 的总经理。在加入 Amazon SageMaker AI 之前,他曾致力于构建 Amazon.com 的广告系统和自动化定价技术。
Ankur Mehrotra 于 2008 年加入亚马逊,目前担任 Amazon SageMaker AI 的总经理。在加入 Amazon SageMaker AI 之前,他曾致力于构建 Amazon.com 的广告系统和自动化定价技术。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区