



📢 转载信息
原文链接:https://www.kdnuggets.com/we-tuned-4-classifiers-on-the-same-dataset-none-actually-improved
原文作者:Nate Rosidi

Image by Author
# 引入实验
超参数调优通常被吹捧为机器学习的“万能灵药”。其承诺很简单:花几个小时调整一些参数,运行网格搜索,然后看着模型的性能飙升。
但在实践中,它真的有效吗?
Image by Author
我们使用葡萄牙学生表现数据,借助四种不同的分类器和严格的统计验证来测试这一前提。我们的方法采用了嵌套交叉验证 (CV)、稳健的预处理流水线以及统计显著性测试——可以说是面面俱到。
结果如何?性能下降了 0.0005。没错——调优实际上使结果略微变差,尽管这种差异在统计学上并不显著。
然而,这不是一个失败的故事。它代表了更有价值的东西:有证据表明,在许多情况下,默认设置效果非常好。有时候,最好的举措是知道何时停止调优,并将精力集中在其他地方。
想看看完整的实验吗?请查看包含所有代码和分析的完整 Jupyter 笔记本。
# 设置数据集
Image by Author
我们使用了StrataScratch“学生表现分析”项目中的数据集。它包含 649 名学生的记录,拥有 30 个特征,涵盖人口统计、家庭背景、社会因素和学校相关信息。目标是预测学生是否通过了葡萄牙语期末考试(分数 ≥ 10)。
在此设置中的一个关键决定是排除了 G1 和 G2 这两项成绩。它们是一、二学期的成绩,与最终成绩 G3 的相关性高达 0.83–0.92。包含它们会使预测变得轻而易举,从而违背了实验的目的。我们希望确定在先前学业表现之外,什么因素能预测成功。
我们使用 pandas 库来加载和准备数据:
# 加载并准备数据
df = pd.read_csv('student-por.csv', sep=';')
# 创建通过/失败目标(成绩 >= 10)
PASS_THRESHOLD = 10
y = (df['G3'] >= PASS_THRESHOLD).astype(int)
# 排除 G1, G2, G3 以防止数据泄露
features_to_exclude = ['G1', 'G2', 'G3']
X = df.drop(columns=features_to_exclude)
类别分布显示,100 名学生不及格 (15.4%),而 549 名学生及格 (84.6%)。由于数据存在不平衡,我们优先优化 F1 分数,而不是简单的准确率。
# 评估分类器
我们选择了四种代表不同学习方法的分类器:
- 逻辑回归:线性基线
- 随机森林:集成方法
- XGBoost:梯度提升
- 支持向量机 (SVM):基于核的方法

Image by Author
最初,所有模型的参数均采用默认设置运行,随后通过带有 5 折 CV 的网格搜索进行调优。
# 建立稳健的方法论
许多机器学习教程展示了惊人的调优结果,原因在于它们跳过了关键的验证步骤。我们坚持高标准,以确保研究结果的可靠性。
我们的方法包括:
- 无数据泄露:所有预处理都在流水线内部执行,并且仅在训练数据上进行拟合。
- 嵌套交叉验证:我们使用内部循环进行超参数调优,使用外部循环进行最终评估。
- 适当的训练/测试拆分:我们使用了 80/20 的分层拆分,测试集在最后才单独保留(即没有“偷看”)。
- 统计验证:我们应用了McNemar 检验来验证性能差异是否具有统计显著性。
- 指标选择:我们优先考虑 F1 分数来处理不平衡类别,而不是准确率。
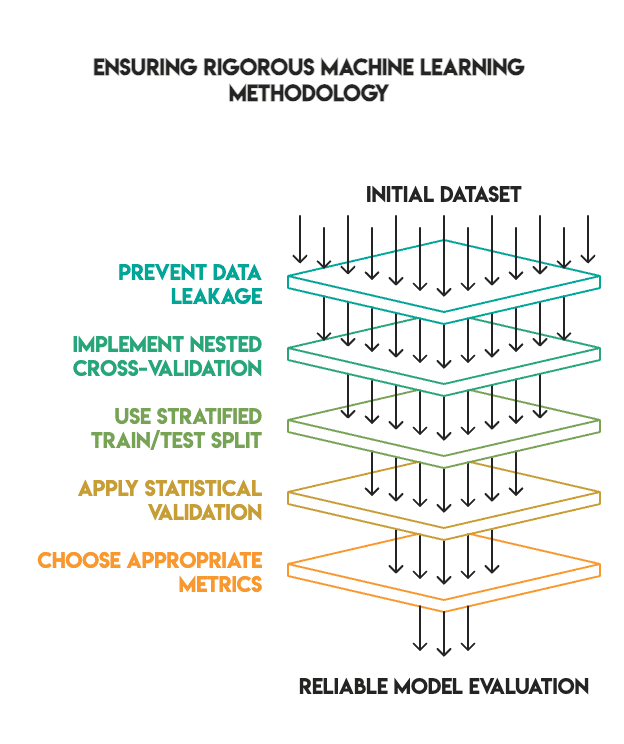
Image by Author
流水线结构如下:
# 预处理流水线 - 仅在训练折叠上拟合
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
numeric_transformer = Pipeline([
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
categorical_transformer = Pipeline([
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
# 组合转换器
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, X.select_dtypes(include=['int64', 'float64']).columns),
('cat', categorical_transformer, X.select_dtypes(include=['object']).columns)
])
# 包含模型的完整流水线
pipeline = Pipeline([
('preprocessor', preprocessor),
('classifier', model) # model 是指循环中的具体分类器
])
# 分析结果
完成调优过程后,结果令人惊讶:
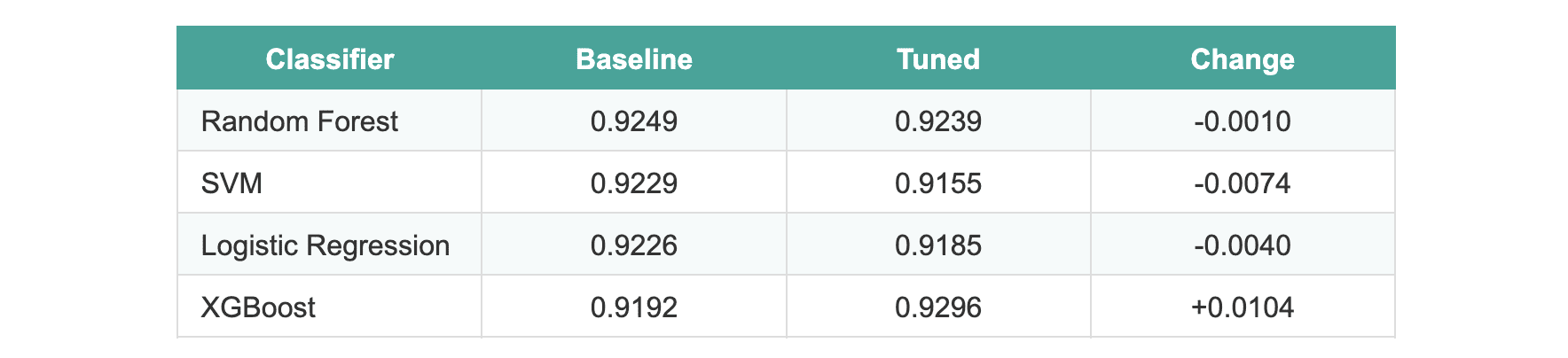
所有模型的平均改进为 -0.0005。
有三个模型在调优后实际上表现略有下降。XGBoost 显示了大约 1% 的提升,这看起来很有希望,直到我们应用统计检验。当在保留的测试集上进行评估时,所有模型的性能差异在统计学上都不显著。
我们运行了McNemar 检验来比较性能最好的两个模型(随机森林与 XGBoost)。p 值为 1.0,这意味着默认版本和调优版本之间没有显著差异。
# 解释调优失败的原因
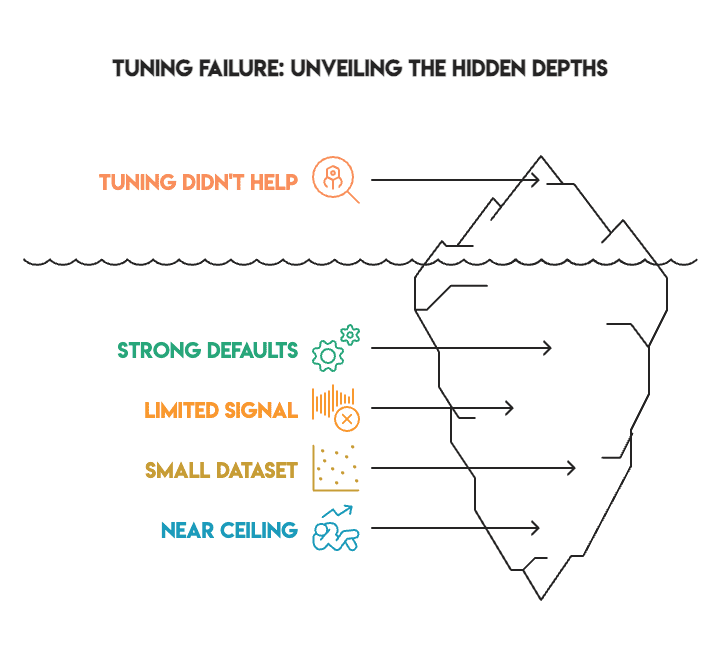
Image by Author
以下几个因素可以解释这些结果:
- 强大的默认设置。 scikit-learn 和 XGBoost 附带了高度优化的默认参数。库的维护者多年来改进了这些值,以确保它们能有效地应用于各种数据集。
- 信号有限。 在排除了 G1 和 G2 成绩(会导致数据泄露)后,剩余特征的预测能力有所减弱。可供超参数优化利用的信号本来就不多。
- 数据集规模小。 训练折叠中只有 649 个样本,数据量不足以让网格搜索识别出真正有意义的模式。网格搜索需要大量数据才能可靠地区分不同的参数集。
- 性能天花板。 大多数基线模型的 F1 分数已经在 92%–93% 之间。在不引入更好特征或更多数据的情况下,性能提升的空间自然有限。
- 严格的方法论。 当您消除数据泄露并利用嵌套 CV 时,不当验证中常见的虚高改进就会消失。
# 从结果中学习
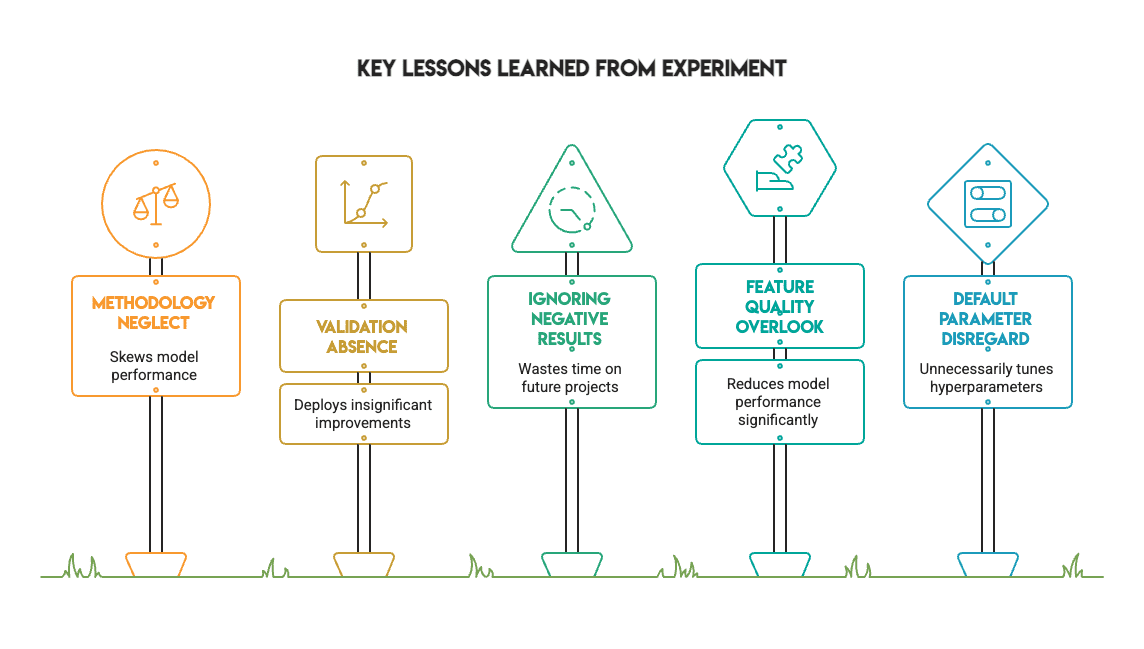
Image by Author
该实验为任何从业者提供了几点宝贵的经验:
- 方法论比指标更重要。 修复数据泄露和使用正确的验证会改变实验结果。当流程处理得当时,通过不当验证获得的惊人分数就会消失。
- 统计验证至关重要。 如果没有 McNemar 检验,我们可能会根据名义上的 1% 提升错误地部署 XGBoost。检验揭示这仅仅是噪声。
- 负面结果具有巨大价值。 并非所有实验都需要显示出巨大的改进。知道何时调优没有帮助,可以节省未来项目的时间,这也是成熟工作流程的标志。
- 默认超参数被低估了。 默认参数通常足以应对标准数据集。不要一开始就假设需要调整每个参数。
# 总结发现
我们试图通过在四种不同模型上遵循行业最佳实践并应用统计验证,来提升模型性能。
结果是:没有统计学上的显著改进。
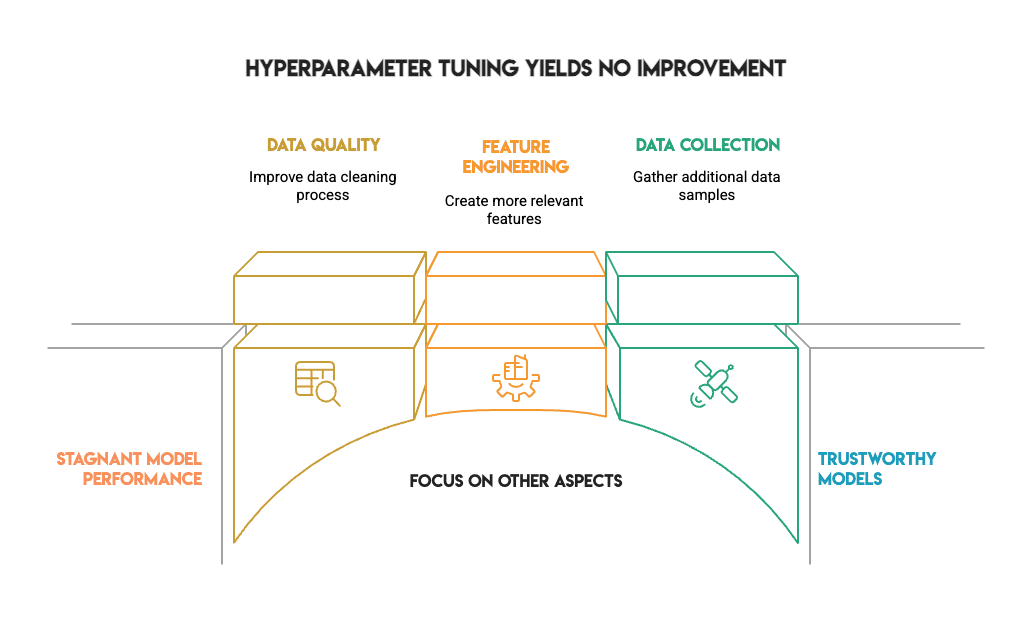
Image by Author
这不是一次失败。相反,它代表了能在现实世界项目工作中帮助您做出更好决策的诚实结果。它告诉您何时应该停止超参数调优,何时应该将重点转移到其他关键方面,例如数据质量、特征工程或收集更多样本。
机器学习不是通过任何手段实现尽可能高的数字;而是要构建您可以信任的模型。这种信任源于构建模型的方法论过程,而不是追逐边际收益。机器学习中最难的技能是知道何时停止。
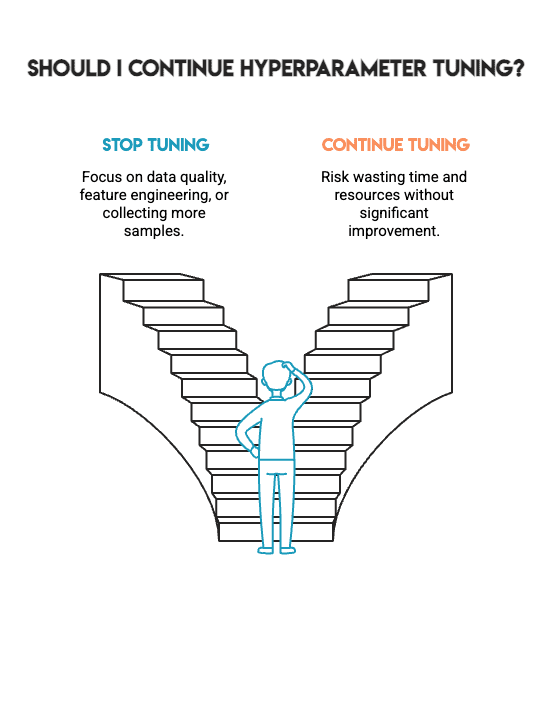
Image by Author
Nate Rosidi 是一位数据科学家,从事产品战略工作。他还是一名教授分析课程的兼职教授,并且是 StrataScratch 的创始人。StrataScratch 是一个帮助数据科学家准备面试的平台,提供来自顶级公司的真实面试问题。Nate 撰写有关职业市场最新趋势、提供面试建议、分享数据科学项目以及涵盖 SQL 的所有内容。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区