



📢 转载信息
原文作者:Lana Zhang 和 Sharon Li
视频内容如今无处不在,从安防监控、媒体制作到社交平台和企业通讯,随处可见。然而,如何从海量视频中提取有意义的洞察依然是一个重大挑战。组织需要能够理解视频内容、叙事背景及潜在含义的解决方案。
在本文中,我们探讨了 Amazon Bedrock 的多模态基础模型(FMs)如何通过三种不同的架构方法实现可扩展的视频理解。每种方法都针对不同的应用场景及成本性能权衡进行了优化。完整的解决方案已作为开源 AWS 示例发布在 GitHub 上。
视频分析的演进
传统的视频分析依赖于人工审查或基础的计算机视觉技术,这些技术往往只能检测预定义的模式。虽然有效,但存在明显的局限性:
- 扩展性受限:人工审查耗时且昂贵
- 缺乏灵活性:基于规则的系统无法适应新场景
- 上下文缺失:传统计算机视觉缺乏语义理解能力
- 集成复杂度高:难以融入现代应用程序
Amazon Bedrock 多模态基础模型的出现改变了这一范式。这些模型能够同时处理视觉和文本信息,从而理解场景、生成自然语言描述、回答关于视频内容的问题,并检测难以通过程序定义的人类细微行为。

三种视频理解方法
视频内容本质上非常复杂,融合了必须共同分析才能获得深度洞察的视觉、听觉和时间信息。针对不同的用例(如媒体场景分析、广告插播检测、IP 摄像头跟踪或社交媒体审核),需要使用不同的工作流,并在成本、准确性和延迟之间取得平衡。
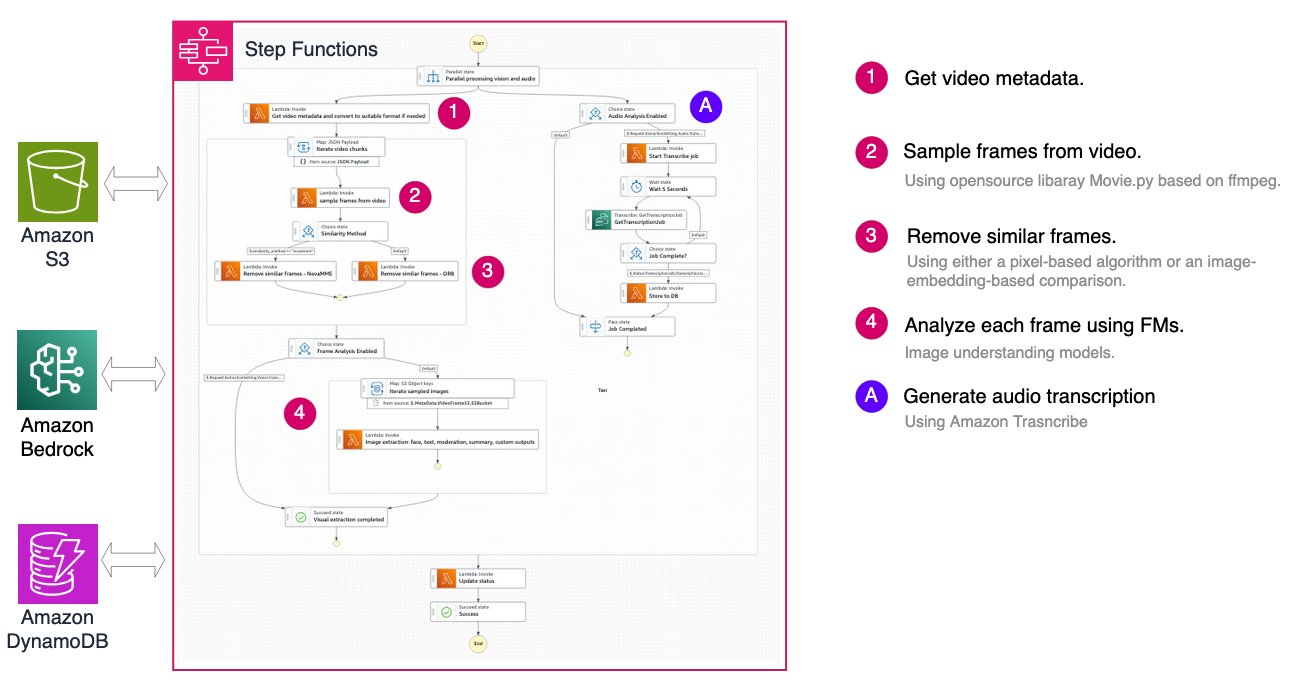
基于帧的工作流:大规模的精准度
基于帧的方法以固定间隔采样图像帧,剔除重复帧,并应用图像理解基础模型在帧级别提取视觉信息。音频转录则通过 Amazon Transcribe 分别处理。

该工作流适用于:
- 安防监控:跨时间跨度检测特定条件或事件
- 质量保证:监控制造或运营流程
- 合规性监控:验证是否遵守安全协议
架构使用 AWS Step Functions 来编排整个流水线:
基于镜头(Shot-based)的工作流:理解叙事流
该工作流不采样单帧,而是将视频分割为短片段(镜头)或固定持续时间的片段,并对每个片段应用视频理解基础模型。这种方法在保留处理长视频灵活性的同时,捕捉了每个片段内的时序上下文。
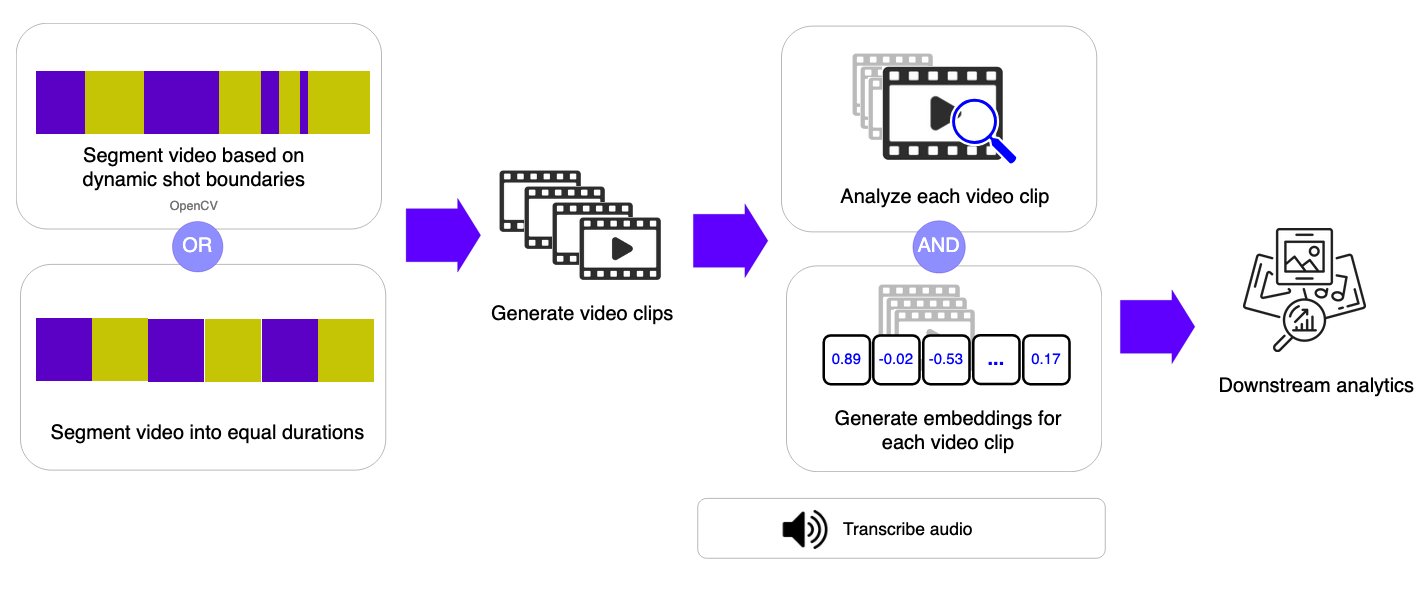
此方法擅长:
- 媒体制作:分析素材以生成章节标记和场景描述
- 内容编目:自动为视频库添加标签和整理
- 精彩片段生成:识别长篇内容中的关键时刻
多模态嵌入:语义视频搜索
多模态嵌入代表了视频理解的新兴方向,对于视频语义搜索应用尤为强大。该解决方案提供了使用 Amazon Nova Multimodal Embedding 和 TwelveLabs Marengo 模型的配套工作流。
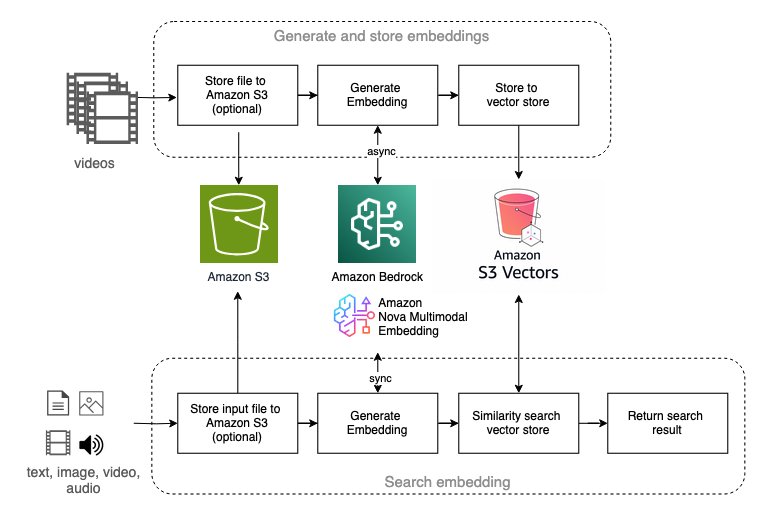
这些工作流支持:
- 自然语言搜索:使用文本查询查找视频片段
- 视觉相似度搜索:使用参考图像定位内容
- 跨模态检索:弥合文本与视觉内容之间的差距
总结
视频理解不再局限于拥有专业计算机视觉团队和基础架构的组织。Amazon Bedrock 的多模态基础模型结合 AWS 无服务器服务,使得高级视频分析变得触手可及且更具成本效益。无论你是构建安防监控系统、媒体制作工具还是内容审核平台,本文展示的三种架构方法都为你提供了灵活的起点。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区