



📢 转载信息
原文作者:Nukul Sharma, Karthik Dasani
本文由华纳兄弟探索公司(Warner Bros. Discovery)的机器学习工程经理 Nukul Sharma 和资深机器学习工程师 Karthik Dasani 撰写。
华纳兄弟探索公司(WBD)是全球领先的媒体和娱乐公司,通过电视、电影和流媒体等渠道,创作和分发世界上最具特色和最全面的内容和品牌组合。WBD 拥有 HBO、探索频道、华纳兄弟、CNN、DC 娱乐等众多知名品牌,通过多元化的系统和体验,为全球观众提供优质的故事内容。我们的流媒体服务,如 HBO Max 和 discovery+,是我们直面消费者战略的基石,为观众提供了前所未有的渠道来访问我们超过 200,000 小时的节目库。
在本文中,我们将介绍我们提供的服务规模、实时推荐系统对人工智能(AI)/机器学习(ML)推理基础设施的需求,以及我们如何利用基于 AWS Graviton 的 Amazon SageMaker AI 实例进行 ML 推理工作负载,从而在不同模型上实现了 60% 的成本节约和 7% 至 60% 的延迟改进。
华纳兄弟探索公司(WBD)品牌
在快速发展的数字娱乐世界中,卓越的内容本身是远远不够的——观众需要发现符合他们独特兴趣的节目。提供高度个性化的内容已成为吸引观众、推动观看时长和与用户建立长期关系的关键。为了有效地服务于我们遍布 100 多个国家/地区、拥有超过 1.25 亿用户的多元化基础(截至 2025 年),我们运用数据科学、用户行为分析和人工策展来预测观众会喜欢什么。我们的工作重点是构建动态推荐算法,并根据个人偏好定制推荐,同时持续测试和完善策略以提高内容相关性准确性。
挑战:在全球范围内扩大个性化规模的同时管理成本
HBO Max 的搜索和个性化基础设施横跨 9 个 AWS 区域,分布在美国、EMEA 和 APAC,旨在提供针对地区偏好量身定制的本地化推荐。这种广泛的基础设施使我们能够在服务跨不同地理区域的个性化内容推荐时,保持一致的低于 100 毫秒的延迟要求。
凭借我们喜爱的品牌庞大组合和多元化的用户群,我们面临着在不影响预算的情况下实现内容推荐个性化的挑战。推荐系统对延迟至关重要;它们需要在实时运行,这意味着对部署我们服务所需的 ML 基础设施有严格的要求。这种内容发现挑战需要复杂的推荐系统,它们必须在大规模上可靠运行,即使在主要首播期间流量在几分钟内激增高达 500% 也是如此。我们正在为 AI/ML 工作负载寻求实时性能和具有成本效益的基础设施解决方案。
我们的解决方案:利用 AWS Graviton 实现大规模、经济高效的 ML 推理
我们的解决方案结合了两种关键的 AWS 技术:AWS Graviton 处理器和 Amazon SageMaker AI。这种集成方法使我们能够全面解决性能和成本方面的挑战。
AWS Graviton 是一系列处理器,旨在为在 Amazon Elastic Compute Cloud (Amazon EC2) 和完全托管服务中运行的云工作负载提供最佳的性价比。它们还针对 ML 工作负载进行了优化,包括 Neon 矢量处理引擎、对 bfloat16 的支持、可扩展矢量扩展(SVE)和矩阵乘法(MMLA)指令,使其成为我们延迟关键型推荐系统的理想选择。
我们决定对基于 XGBoost 和 TensorFlow 的 ML 模型进行尝试,为此我们遵循了一个两步流程。首先,我们从一个沙箱环境中开始,对工作进程和线程进行微调,以最大化单个实例的吞吐量,观察到性能明显优于我们集群中的 x86 基础实例。其次,我们转向生产流量,在其中执行影子测试(shadow testing)以确认我们在独立环境中观察到的成本和性能优势。我们注意到,即使在较高的 CPU 负载下,Graviton 实例也能几乎线性扩展。我们重新配置了自动扩展配置以提高实例利用率,并且由于 Graviton 实例能更有效地处理突发流量,我们也减少了实例的最小数量。此外,我们平衡了成本与性能,避免为其中一个过度优化而影响另一个。
SageMaker 推理推荐器(Inference Recommender)在简化我们的测试工作流程中发挥了关键作用。通过自动执行跨不同实例类型和配置的基准测试过程,该工具显著减少了识别模型最佳设置所需的时间。自动化的性能分析帮助我们对实例选择做出数据驱动的决策,并加速了我们的模型部署流程。
为了验证我们新基础设施的性能和可靠性,我们利用了 Amazon SageMaker 的影子测试功能。这种测试框架使我们的团队能够在现有生产系统旁评估新部署,提供真实的性能比较,而不会影响用户体验。对于我们的机器学习平台(MLP)团队用户来说,这种方法在评估各种基础设施修改时尤其有价值。通过并行测试不同的硬件设置和微调推理参数,我们可以在承诺更改之前彻底评估系统性能。这种战略性测试方法帮助我们在部署过程的早期预见潜在问题并优化配置。
下图重点介绍了我们在 AWS 上的端到端 ML 推理工作负载部署情况。如这里所示,我们已经在使用多个完全托管的 AWS 服务,如 Amazon SageMaker、Amazon Simple Storage Service (Amazon S3) 和 Amazon DynamoDB,以实现我们的推荐系统目标。这一次,我们向前迈进了一步,迁移到基于 AWS Graviton 的实例,从而实现了成本节约和性能提升。
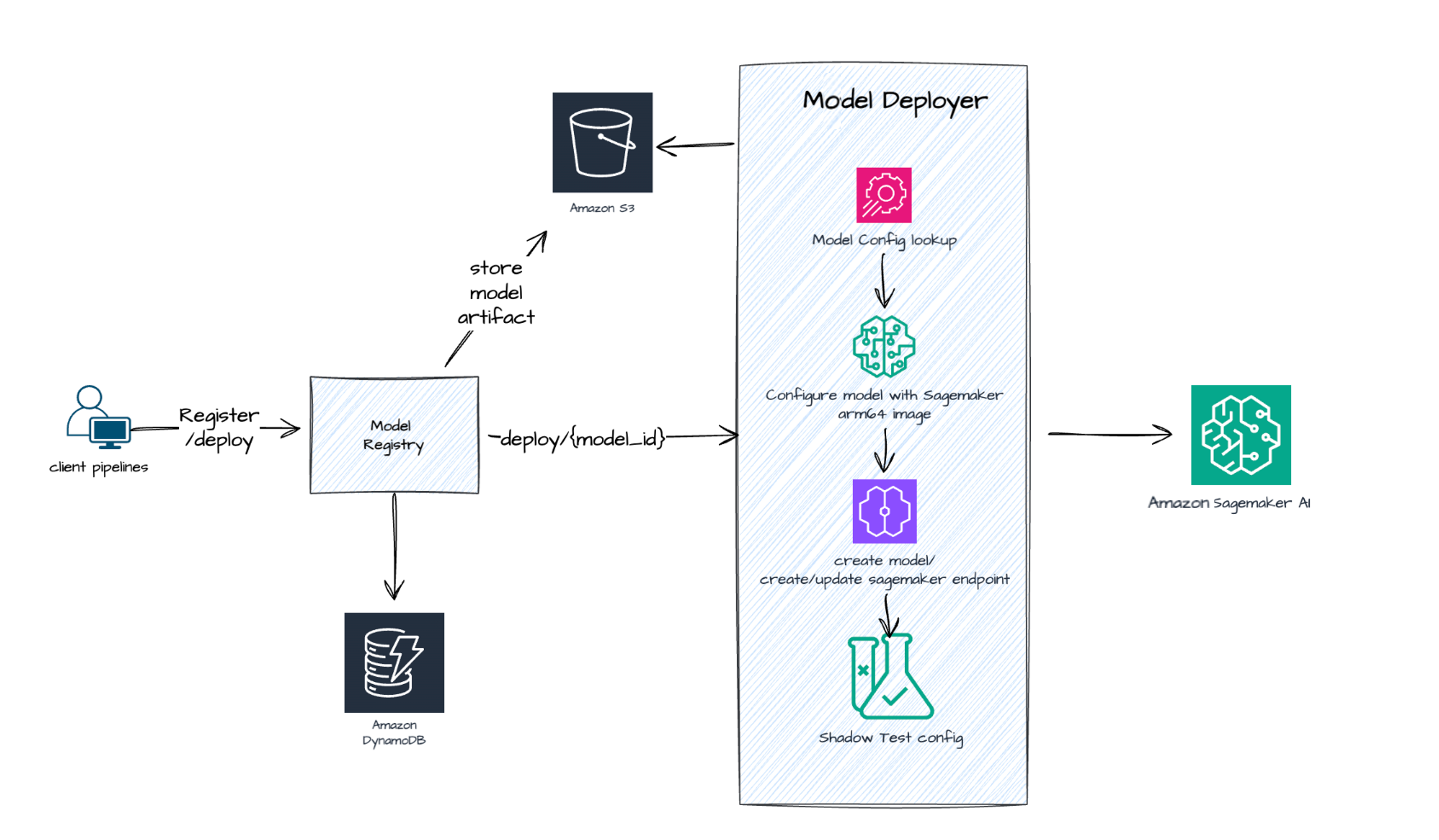
结果
向基于 AWS Graviton 的实例从 x86 基础实例的迁移在我们的推荐系统组合中带来了显著的结果。
实现 60% 的成本节约
我们的综合分析显示,个性化模型实现了显著的成本削减,平均成本节约达到 60%。在我们的目录排名模型中,改进尤为突出,成本降低幅度高达 88%。
平均和 P99 延迟提高,不同模型之间提高 7% 到 60%
除了成本节约之外,我们还实现了重大的性能提升。我们模型套件的 P99 延迟改进令人瞩目,其中 XGBoost 模型延迟急剧降低了 60%。我们产品组合中的其他模型也实现了高达 21% 的一致延迟改进。以下 A/B 测试仪表板突出显示了迁移到基于 AWS Graviton 的 ML 实例如何改善了平均和 P99 延迟,并大幅减少了实例数量。绿色(GREEN)线条来自我们集群中的 x86 基础服务器,而黄色(YELLOW)线条来自基于 AWS Graviton 的服务器。
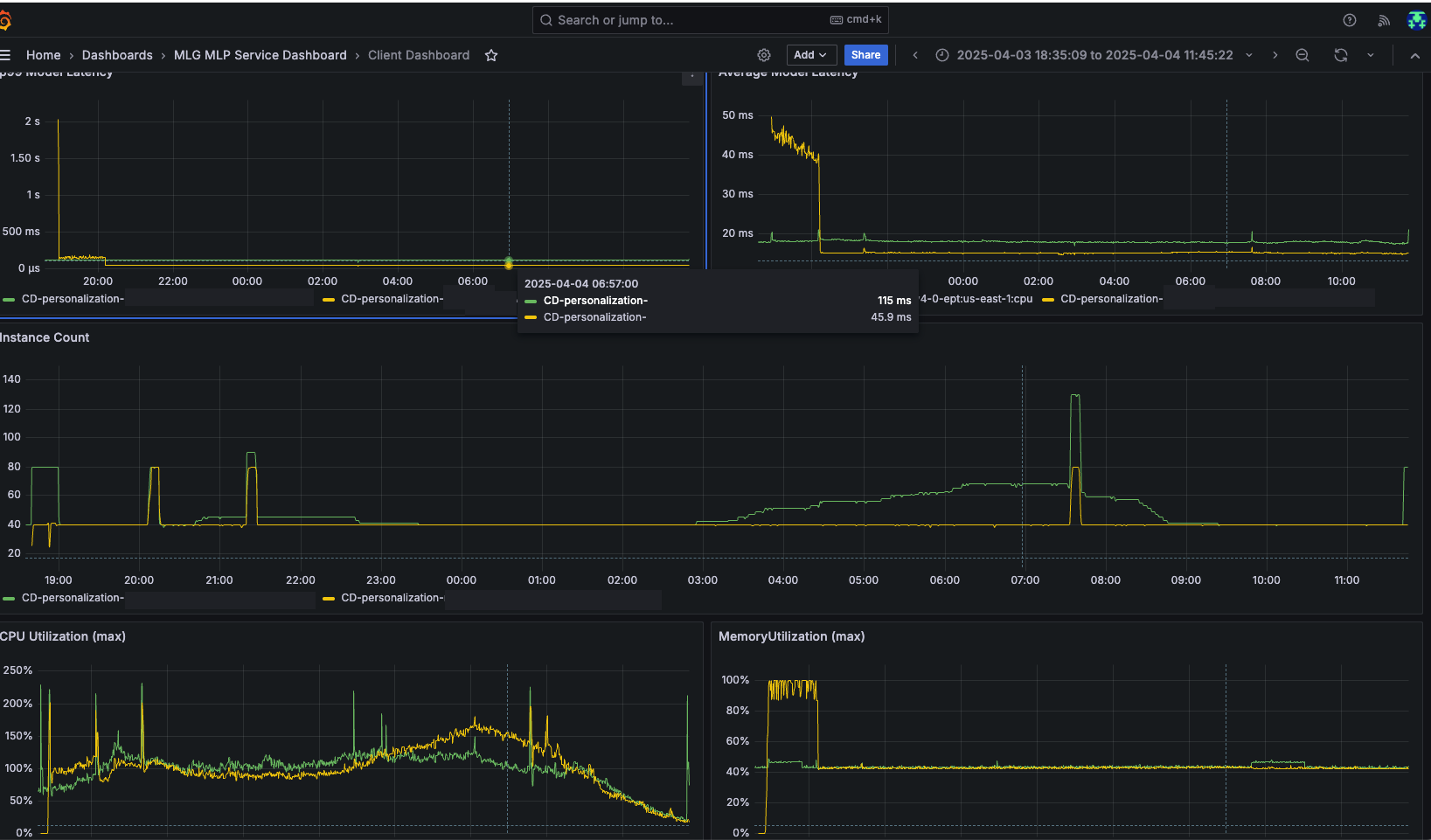
改善用户体验
通过降低延迟,我们显著提高了服务的性能以及客户的用户体验;观众体验到了更具响应性、更能匹配他们兴趣的推荐。
体验到无缝迁移
在整个项目中,我们与 AWS 客户和服务的团队进行了卓有成效的合作。迁移过程非常顺利。从初步基准测试到最终迁移,大约花费了一个月时间;而一项关于目录排名模型的概念验证(POC),它带来了 60% 的成本节约,仅用一周时间就完成了,这比我们最初估计的时间要快得多。
有动力实现 100% 的推荐系统在基于 Graviton 的实例上运行
鉴于采用 Graviton 带来的巨大成本节约,我们目前正致力于将剩余的模型迁移到 Graviton,目标是实现 100% 的推荐系统在基于 Graviton 的实例上运行。
结论
通过将我们的 ML 推理工作负载迁移到基于 AWS Graviton 的实例,我们改变了向 100 多个国家/地区的 1.25 亿多用户提供个性化内容推荐的方式。这次迁移带来了令人印象深刻的结果,我们的推荐系统平均成本降低了 60%,不同模型的延迟改进范围在 7% 到 60% 之间。这些性能提升带来了切实的业务成果:观众体验到更具响应性、更能匹配其兴趣的推荐,从而带来了更深入的参与、更长的观看时间,以及最终在我们系统上更牢固的留存率——所有这些都使我们能够有效地扩展业务运营。
总的来说,采用 AWS Graviton 处理器体现了创新云解决方案如何推动运营效率和业务价值。我们的经验表明,在快速发展的商业环境中,组织可以成功地平衡性能、成本和规模的相互竞争的需求。随着我们继续优化 ML 基础设施,这些改进将帮助我们在提供日益个性化的体验给全球观众的同时保持竞争力。
如需进一步阅读,请参阅以下内容:
WBD 团队要感谢 AWS 的 Sunita Nadampalli、Utsav Joshi、Karthik Rengasamy、Tito Panicker、Sapna Patel 和 Gautham Panth 对该解决方案的贡献。
关于作者
 Nukul Sharma 是华纳兄弟探索公司(Warner Bros. Discovery)的机器学习工程经理,拥有 18 年以上领导顶级工程和 MLOps 团队的经验。他擅长开发可扩展解决方案、端到端 ML 管道、云系统和 CI/CD。他在交付推动效率和增长的个性化和 MLOps 解决方案方面有着良好的往绩。
Nukul Sharma 是华纳兄弟探索公司(Warner Bros. Discovery)的机器学习工程经理,拥有 18 年以上领导顶级工程和 MLOps 团队的经验。他擅长开发可扩展解决方案、端到端 ML 管道、云系统和 CI/CD。他在交付推动效率和增长的个性化和 MLOps 解决方案方面有着良好的往绩。
 Karthik Dasani 是华纳兄弟探索公司(Warner Bros. Discovery)的资深机器学习工程师,专长于大规模推荐系统和 ML Ops。他在将 AI 解决方案投入生产方面拥有丰富的经验,重点关注性能和成本优化。他的工作连接了应用研究与可扩展的、现实世界的机器学习系统。
Karthik Dasani 是华纳兄弟探索公司(Warner Bros. Discovery)的资深机器学习工程师,专长于大规模推荐系统和 ML Ops。他在将 AI 解决方案投入生产方面拥有丰富的经验,重点关注性能和成本优化。他的工作连接了应用研究与可扩展的、现实世界的机器学习系统。
关于 AWS 团队
 Sunita Nadampalli 是 AWS 的首席工程师和 AI/ML 专家。她领导 AWS Graviton 在 AI/ML 和 HPC 工作负载方面的软件性能优化工作。她热衷于开源软件开发,并为基于 Arm ISA 的 SoC 提供高性能和可持续的软件解决方案。
Sunita Nadampalli 是 AWS 的首席工程师和 AI/ML 专家。她领导 AWS Graviton 在 AI/ML 和 HPC 工作负载方面的软件性能优化工作。她热衷于开源软件开发,并为基于 Arm ISA 的 SoC 提供高性能和可持续的软件解决方案。
 Utsav Joshi 是 AWS 的首席技术客户经理。他居住在新泽西州,喜欢与 AWS 客户合作解决架构、运营和成本优化方面的挑战。在业余时间,他喜欢旅行、公路旅行和与孩子们一起玩耍。
Utsav Joshi 是 AWS 的首席技术客户经理。他居住在新泽西州,喜欢与 AWS 客户合作解决架构、运营和成本优化方面的挑战。在业余时间,他喜欢旅行、公路旅行和与孩子们一起玩耍。
 Karthik Rengasamy 是 AWS 的高级解决方案架构师,专注于帮助媒体和娱乐客户设计和扩展其云架构。他专注于媒体供应链、存档和视频流解决方案,与客户紧密合作,推动媒体工作负载在 AWS 上的创新和优化。他的热情在于构建安全、可扩展且经济高效的解决方案,以改变媒体管理和向全球受众交付的方式。
Karthik Rengasamy 是 AWS 的高级解决方案架构师,专注于帮助媒体和娱乐客户设计和扩展其云架构。他专注于媒体供应链、存档和视频流解决方案,与客户紧密合作,推动媒体工作负载在 AWS 上的创新和优化。他的热情在于构建安全、可扩展且经济高效的解决方案,以改变媒体管理和向全球受众交付的方式。
 Tito Panicker 是一位高级全球解决方案架构师,帮助最大的企业客户在云中构建安全、可扩展和有弹性的解决方案。他的主要关注领域是媒体和娱乐垂直行业,专注于直面消费者(D2C)流媒体、数据/分析、AI/ML 和生成式 AI。
Tito Panicker 是一位高级全球解决方案架构师,帮助最大的企业客户在云中构建安全、可扩展和有弹性的解决方案。他的主要关注领域是媒体和娱乐垂直行业,专注于直面消费者(D2C)流媒体、数据/分析、AI/ML 和生成式 AI。
 Sapna Patel 是 AWS 的首席客户解决方案经理,她通过战略指导和关系管理帮助媒体和娱乐客户优化其云之旅。她专注于通过将 AWS 解决方案与业务目标相结合来推动客户成功,确保客户在实现其技术和运营目标的同时,最大限度地利用其云投资。
Sapna Patel 是 AWS 的首席客户解决方案经理,她通过战略指导和关系管理帮助媒体和娱乐客户优化其云之旅。她专注于通过将 AWS 解决方案与业务目标相结合来推动客户成功,确保客户在实现其技术和运营目标的同时,最大限度地利用其云投资。
 Gautham Panth 是 AWS 的首席产品经理,专注于构建开创性的云基础设施解决方案。凭借在云计算、企业基础设施和软件方面超过 20 年的跨学科专业知识,Gautham 利用他对客户挑战的全面理解,来推动 AWS 产品未来的方向和功能。
Gautham Panth 是 AWS 的首席产品经理,专注于构建开创性的云基础设施解决方案。凭借在云计算、企业基础设施和软件方面超过 20 年的跨学科专业知识,Gautham 利用他对客户挑战的全面理解,来推动 AWS 产品未来的方向和功能。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区