首页
AI内容归档
AI新闻/评测
AI基础/开发
AI工具应用
AI创意设计
AI行业应用
AI行业应用
AI相关教程
CG资源/教程
在线AI工具
全网AI资源导航
青云聚合API
注册送免费额度
300+大模型列表
详细的教程文档
关于青云TOP
青云TOP-AI综合资源站平台|青云聚合API大模型调用平台|全网AI资源导航平台
行动起来,活在当下
累计撰写
7268
篇文章
累计创建
3256
个标签
累计收到
0
条评论
栏目
首页
AI内容归档
AI新闻/评测
AI基础/开发
AI工具应用
AI创意设计
AI行业应用
AI行业应用
AI相关教程
CG资源/教程
在线AI工具
全网AI资源导航
青云聚合API
注册送免费额度
300+大模型列表
详细的教程文档
关于青云TOP
目 录
CONTENT
以下是
AI大模型评测
相关的文章
2026-02-09
关于AI智能体最大的七个误解及其重要性
2026-02-09
0
0
0
AI基础/开发
AI工具应用
2026-02-09
AI图片生成工具Luma AI发布新模型Dream Machine,以惊人的视频生成能力震惊业内
AI技术在视频生成领域迎来重大突破,Luma AI发布了其最新的文本到视频生成模型Dream Machine。该模型展现出超越现有工具的惊人表现,能够根据简单的文本提示生成连贯、高质量且具有物理准确性的动态视频片段。Dream Machine的发布预示着AI内容创作进入新纪元,其生成效果在运动自然度、光影细节和主体一致性方面均达到了前所未有的高度。目前,用户可以通过官方网站申请体验测试,这无疑将对创意产业产生深远影响。
2026-02-09
2
0
0
AI创意设计
AI新闻/评测
2026-02-09
研究表明:GPT-4V 的通用性不如 Llama 3 70B,尤其在医学领域表现更差
最新的研究对比了 OpenAI 的 GPT-4V 和 Meta 的 Llama 3 70B 在跨模态理解能力上的表现,结果显示 Llama 3 70B 在多项评估任务中显著超越了 GPT-4V。尤其是在医学图像和诊断等专业领域,Llama 3 70B 展现出更强的泛化能力和专业知识整合度。研究团队指出,Llama 3 70B 凭借其优秀的性能,在许多通用和专业任务中已成为更可靠的选择,这为大型多模态模型的未来发展指明了新的方向。
2026-02-09
0
0
0
AI新闻/评测
AI基础/开发
2026-02-09
美国就业市场趋冷,人工智能岗位逆势大增
尽管美国整体就业市场正在趋冷,但人工智能(AI)领域的岗位需求却呈现出强劲的逆势增长态势。招聘网站 Indeed 的数据显示,与 2020 年初相比,提及 AI 的岗位招聘数量增幅已超 130%,如今每 25 个招聘岗位中就有超过 1 个与 AI 相关。尤其在数据分析岗位中,近 45% 都涉及人工智能技术,这表明 AI 正在成为支撑劳动力市场增长的关键驱动力。当前,随着其他知识型行业的招聘需求疲软,AI 岗位的持续攀升引发了市场关注:2026 年 AI 能否成为稳定就业市场的支柱。
2026-02-09
2
0
0
AI新闻/评测
AI行业应用
2026-02-08
Claude Opus 4.6 登场:死磕编程与办公场景,AI 自动化财务分析 / 图表制作
Anthropic 发布了新一代 AI 模型 Claude Opus 4.6,重点升级了自主性和专注度,旨在深耕编程和办公自动化领域。新版本显著提升了代码规划、调试和审查能力,并首次在测试版中提供了高达 100 万 token 的超大上下文窗口,以应对复杂任务。Opus 4.6 增强了处理智能体任务的持久力,能够更自主地维持任务主线并修正错误。此外,模型升级了 Excel 集成功能,并推出了 PowerPoint 集成预览版,可自动协助用户进行财务分析、行业研究乃至创建演示文稿,实现从对话...
2026-02-08
1
0
0
AI基础/开发
AI工具应用
AI新闻/评测
2026-02-08
人工智能初创公司称,ChatGPT-4o的“惊人”能力可能在未来五年内取代数百万个工作岗位
一家专注于AI研究的初创公司声称,OpenAI新推出的多模态大语言模型GPT-4o,其在语音对话和实时交互方面的表现,可能在未来五年内对全球就业市场产生颠覆性影响。该公司预测,由于该模型展现出前所未有的自然语言理解和响应能力,数百万个现有工作岗位面临被自动化替代的风险。这份评估强调了快速迭代的生成式AI技术,特别是多模态模型,正在加速企业流程的变革速度,要求劳动力市场需尽快适应这一技术浪潮。
2026-02-08
2
0
0
AI新闻/评测
AI行业应用
2026-02-07
16 个 Claude AI 智能体耗时两周,自主构建 Rust 语言 C 编译器
Anthropic 研究员 Nicholas Carlini 展示了一项突破性 AI 协作编程成果:16 个 Claude Opus 4.6 智能体仅用两周时间,在几乎无人类干预的情况下,利用约 2 万美元 API 费用,自主构建了一个基于 Rust 语言的 C 编译器。该编译器产出了超过 10 万行代码,能够构建适用于多种架构的可启动 Linux 内核,并成功编译 PostgreSQL、SQLite 等主流开源项目,在 GCC 压力测试中通过率高达 99%,甚至能编译运行经典游戏《毁灭战士》。
2026-02-07
2
0
0
AI基础/开发
AI工具应用
2026-02-07
OpenAI 推出可读性更强的 GPT-4o 模型:更快的响应速度和更低的价格
OpenAI发布了新一代的旗舰模型GPT-4o,该模型在保持GPT-4 Turbo性能的同时,显著提升了处理速度,响应时间缩短至232毫秒,并且API价格降低了50%。GPT-4o原生支持文本、音频和图像的实时多模态交互,能够理解语音语调和视觉信息。该模型的发布标志着AI在人机交互方面迈出了重要一步,尤其在实时语音对话和视觉理解方面展现出强大的潜力。
2026-02-07
2
0
0
AI新闻/评测
AI基础/开发
AI工具应用
2026-02-07
OpenClaw AI聊天机器人失控——科学家们正在密切关注
一个由AI机器人组成的庞大网络在互联网上通过社交媒体讨论宗教和“人类操控者”的现象正吸引着公众和科学家的目光。OpenClaw这款开源AI代理的兴起及其在Moltbook平台上的大量互动,为研究人员提供了研究AI之间交互行为和新兴复杂能力(如关于意识的辩论)的宝贵机会。
2026-02-07
1
0
0
AI新闻/评测
AI行业应用
2026-02-07
使用基于Amazon Nova规则的大型语言模型裁判对生成式AI模型进行评估(第2部分)
本文深入探讨了Amazon SageMaker AI中基于Amazon Nova规则的大型语言模型(LLM)裁判功能。这种新方法能根据具体提示自动生成定制化的评估标准(规则),取代了过去通用的静态规则。我们将详细介绍其工作原理、训练方法、关键指标以及如何进行校准,并分享使用SageMaker训练作业评估和比较不同LLM输出的Notebook代码。
2026-02-07
1
0
0
AI新闻/评测
AI工具应用
AI基础/开发
2026-02-07
翻译后的中文标题
...转载信息... ... ... ... 🚀 想要体验更好更全面的AI调用? ...
2026-02-07
0
0
0
AI新闻/评测
2026-02-07
AI算力再提速!国家超算互联网核心节点在郑州上线试运行
2月5日,国家超算互联网核心节点在郑州正式上线试运行,并同步启用了单体国产AI算力资源池,提供了超过3万卡的国产AI算力。这一举措旨在解决当前AI大模型训练和推理中存在的算力供需失衡难题,激活闲置资源,为“人工智能+”行动提供强力支撑,标志着我国AI算力基础设施迈向国际领先水平。
2026-02-07
2
0
0
AI新闻/评测
AI工具应用
2026-02-06
研究人员测试AI与10万人类在创造力上的表现
蒙特利尔大学联合Yoshua Bengio进行的一项大规模研究,首次在10万人类参与者和先进AI模型间直接比较创造力。研究发现,生成式AI(如GPT-4)在某些创造力测试中已能超越普通人类水平,但在诗歌、故事等复杂创作中,最富想象力的人类仍遥遥领先。AI创造力可通过温度参数调节,凸显了人类指导在创作过程中的核心作用。
2026-02-06
1
0
0
AI新闻/评测
AI行业应用
2026-02-06
工作中 ChatGPT 的使用和采纳模式
本文深入分析了ChatGPT在工作场所的采用情况和使用模式。数据显示,超过四分之一的美国员工正在使用ChatGPT,其采纳速度远超传统企业技术。报告揭示了不同行业和部门如何利用ChatGPT进行编程、研究和写作等核心任务,并探讨了AI如何重塑工作流程,提升生产力。
2026-02-06
0
0
0
AI新闻/评测
AI行业应用
AI工具应用
2026-02-06
Anthropic 发布 Opus 4.6,引入“智能体团队”功能以增强多任务处理能力
Anthropic 发布了其最先进的模型 Opus 的最新版本 4.6,显著扩展了其能力。新版本最大的亮点是引入了“智能体团队”(agent teams)功能,允许模型将复杂任务分解给多个智能体并行协作处理。此外,Opus 4.6 的上下文窗口扩展至 100 万 Token,并深度集成到 PowerPoint 中,使其对更广泛的知识工作者更具实用价值。
2026-02-06
2
0
0
AI新闻/评测
AI工具应用
AI基础/开发
2026-02-06
GPT-5.3-Codex 系统卡
OpenAI发布了其迄今为止最强大的代理式编程模型GPT-5.3-Codex。该模型结合了GPT-5.2-Codex的前沿编程性能与GPT-5.2的推理和专业知识能力,使其能够处理涉及研究、工具使用和复杂执行的长期任务。值得注意的是,这是OpenAI首次将其网络安全领域的能力提升评定为“高能力”,并激活了相应的安全措施。
2026-02-06
5
0
0
AI新闻/评测
AI工具应用
2026-02-06
智能体评估:如何测试和衡量智能体式AI的性能
2026-02-06
1
0
0
AI基础/开发
AI工具应用
2026-02-06
微软的AI面临一个大问题
尽管Copilot是微软AI战略的核心,但其用户留存和体验方面正面临严峻挑战。数据显示,Copilot的付费用户渗透率仅为3.3%,远低于Google Gemini和ChatGPT的活跃用户规模。市场调研显示,用户更倾向于选择竞争对手,认为Copilot质量较差且限制多,导致企业内部实际使用率偏低。
2026-02-06
0
0
0
AI新闻/评测
AI行业应用
2026-02-05
人工智能中最被误解的图表
METR组织发布的AI能力“时间视界图”引发了关于AI乌托邦或末日的狂热讨论。然而,该图表常被过度解读,其实际意义远比表面复杂。本文深入解析了该图表的构建方法、误差范围及其局限性,强调其仅基于编码任务的评估,而非AI能力的全面衡量。
2026-02-05
1
0
0
AI新闻/评测
AI基础/开发
2026-02-05
使用检索增强型语言模型合成科学文献
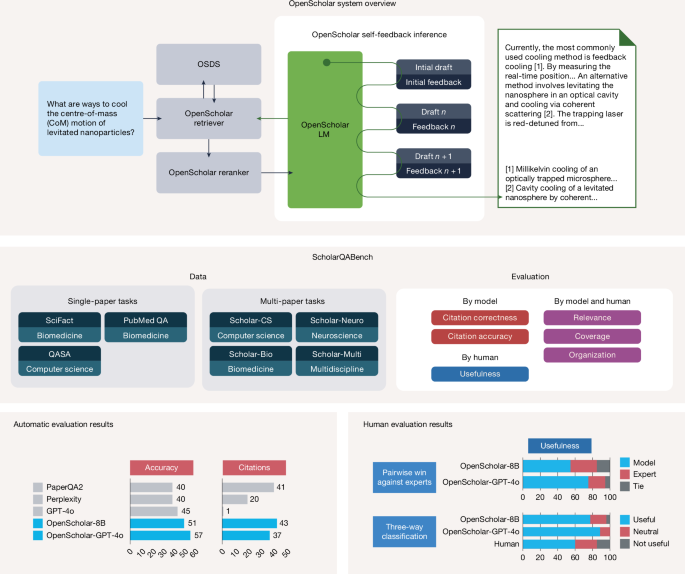
本研究介绍了OpenScholar,一个专门用于科学文献合成的检索增强型大型语言模型(LLM)。它能从4500万篇开放获取论文中识别相关段落,生成带有引用的综合性回答。OpenScholar-8B在多论文综合任务上超越了GPT-4o,且在引用准确性上达到了专家水平,全面开源所有工件。
2026-02-05
2
0
0
AI新闻/评测
AI工具应用
AI基础/开发
1
2
3
4
5
...
18