首页
AI内容归档
AI新闻/评测
AI基础/开发
AI工具应用
AI创意设计
AI行业应用
AI行业应用
AI相关教程
CG资源/教程
在线AI工具
全网AI资源导航
青云聚合API
注册送免费额度
300+大模型列表
详细的教程文档
关于青云TOP
青云TOP-AI综合资源站平台|青云聚合API大模型调用平台|全网AI资源导航平台
行动起来,活在当下
累计撰写
7268
篇文章
累计创建
3256
个标签
累计收到
0
条评论
栏目
首页
AI内容归档
AI新闻/评测
AI基础/开发
AI工具应用
AI创意设计
AI行业应用
AI行业应用
AI相关教程
CG资源/教程
在线AI工具
全网AI资源导航
青云聚合API
注册送免费额度
300+大模型列表
详细的教程文档
关于青云TOP
目 录
CONTENT
以下是
AI大模型评测
相关的文章
2026-02-05
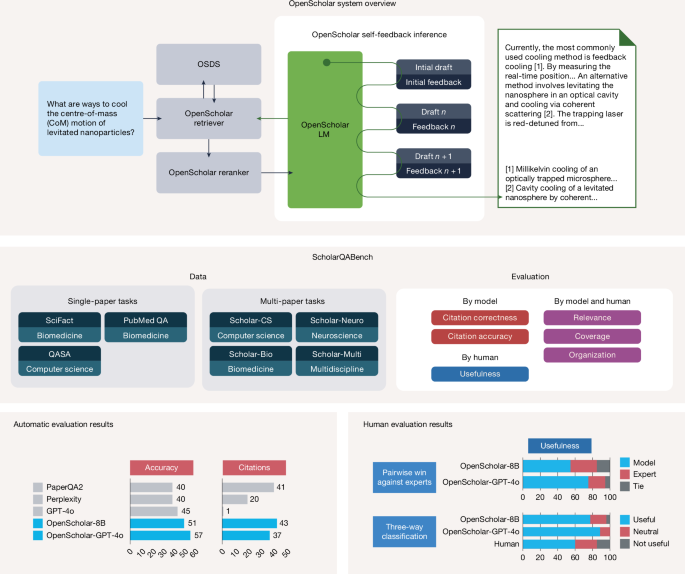
使用检索增强型语言模型合成科学文献
面对爆炸式增长的科学文献,研究人员难以保持信息同步。本文介绍了 OpenScholar,一个专用的检索增强型语言模型(RALM),它通过检索 4500 万篇开放获取论文来回答科学查询并生成有引文支持的综述。OpenScholar-8B 在多篇论文综合任务上的正确率超越了 GPT-4o,且引文准确率与人类专家相当,展示了其在科学文献合成领域的巨大潜力。
2026-02-05
1
0
0
AI新闻/评测
AI工具应用
2026-02-05
从护栏到治理:首席执行官保护代理系统的指南
本文为首席执行官和企业提供了一份实用的蓝图,旨在通过将控制重点从“提示词调整”转向对身份、工具和数据的硬性控制,从而确保代理系统的安全。它提出了一个八步行动计划,核心在于将AI代理视为具有限制权限的真实用户进行管理。
2026-02-05
0
0
0
AI行业应用
AI基础/开发
AI工具应用
2026-02-04
少数派 2025 年度征文:听说你对写作是真 AI?
少数派发布2025年度征文,设立“AI 助力赛道”与“手工匠人赛道”,鼓励创作者探索 AI 写作的边界与价值。文章详细介绍了两大赛道的投稿要求、创作环节中对 AI 使用的界限,以及丰厚的奖励机制,邀请读者共同探讨人类写作与 AI 辅助写作的优劣。
2026-02-04
1
0
0
AI新闻/评测
AI工具应用
AI创意设计
2026-02-03
人工智能是否已经具备人类水平的智能?证据是明确的
在图灵于1950年提出“模仿游戏”后,机器是否能展现出人类思维的通用认知能力这一问题,如今似乎有了肯定的答案。随着大型语言模型(LLM)在图灵测试中超越人类,并在数学、科学等领域取得卓越成就,我们必须正视AI已达到通用智能的现实,并为接下来的发展做好准备。
2026-02-03
2
0
0
AI新闻/评测
AI行业应用
2026-02-03
我们对人工智能“真相危机”的误解
美国国土安全部使用AI生成内容引发热议,但读者的反应揭示了我们对AI真相危机的准备存在根本性缺陷。本文指出,即使内容被揭穿是伪造的,它仍能影响人们的信念。我们原以为验证工具可以解决危机,但现实是,单纯的事实核查已不足以重建社会信任,真相的捍卫者们正远远落后。
2026-02-03
1
0
0
AI新闻/评测
AI行业应用
2026-02-02
人工智能大模型应敢于持续“摸高”(“咖”说科技)
本文深入探讨了当前人工智能大模型的发展趋势和未来方向。作者指出,中国企业在提升模型效率方面已取得初步优势,并强调未来模型研发必须敢于挑战前沿技术难题(持续“摸高”),同时紧密结合生产力变革趋势,以实现更广泛的社会和商业价值。文章对中国AI生态的未来充满信心。
2026-02-02
2
0
0
AI新闻/评测
AI基础/开发
AI行业应用
2026-02-02
人脑理解语言的方式或与人工智能出乎意料地相似
一项新研究表明,人脑理解口语的方式与先进的人工智能语言模型(如GPT)非常相似。研究人员通过追踪听众收听播客时的大脑活动,发现意义的理解是逐步展开的,这与AI模型的层级化处理过程相吻合。这一发现挑战了传统的基于规则的语言理解理论,揭示了人脑在构建意义方面与尖端AI模型的惊人共性。
2026-02-02
0
0
0
AI新闻/评测
AI基础/开发
2026-02-01
通过背景故事集为语言模型定制虚拟角色:Anthology 方法介绍
本文介绍了Anthology方法,它通过生成和利用包含丰富个体价值观和经验的自然主义背景故事,来指导大型语言模型(LLMs)形成具有代表性、一致性和多样性的虚拟角色。Anthology能使LLMs更精准地模拟个体人类样本,有望革新用户研究和社会科学领域的调查方式。
2026-02-01
1
0
0
AI新闻/评测
AI基础/开发
2026-02-01
雄安发布国内首个结构化数据通用大模型
雄安新区成功举办“人工智能+”创新生态系列活动,发布了由清华大学与稳准智能联合研发的“极数”数据大模型(LimiX)。该模型是国内首个专注于结构化数据的通用大模型,标志着AI范式正从“语言智能”向“数据智能”转变,为工业、能源等实体经济智能化转型提供强大支持。
2026-02-01
1
0
0
AI新闻/评测
AI基础/开发
AI行业应用
2026-01-31
AI“幻觉”如何威胁信息可信度:事实核查工具的局限性
人工智能模型,特别是大型语言模型(LLM),正日益被集成到新闻和信息领域,但它们“幻觉”的倾向对信息可信度构成了严重挑战。研究表明,AI会自信地生成看似真实却完全虚构的答案,这使得依赖这些系统进行内容创作或事实核查变得极其危险。现有的事实核查工具和技术在应对AI的复杂虚构信息时存在显著局限,凸显了人类监督在验证AI生成内容真实性方面不可替代的作用。业界正亟需开发更鲁棒的机制来区分事实与虚构,以维护信息生态的健康。
2026-01-31
2
0
0
AI新闻/评测
AI基础/开发
2026-01-31
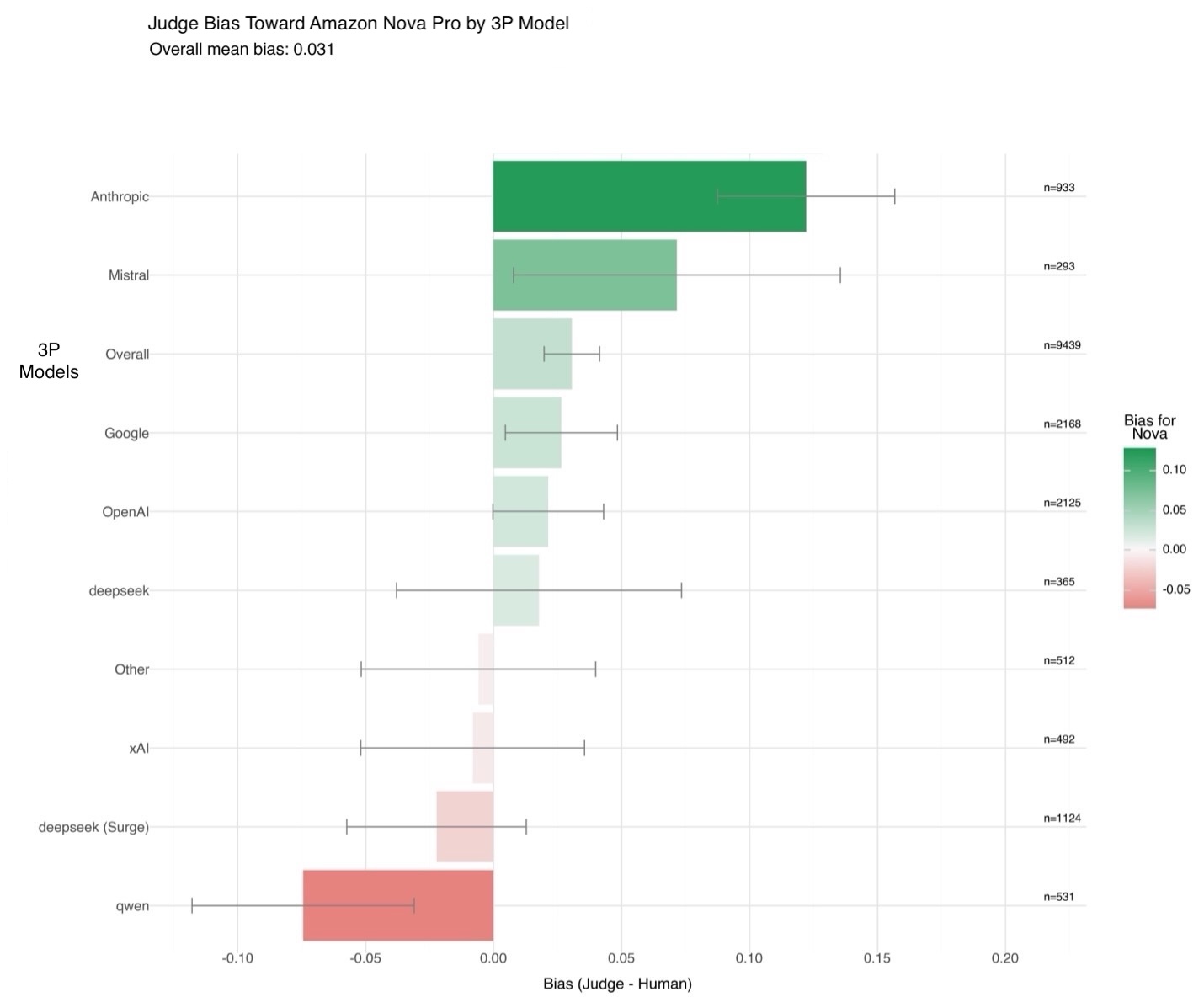
使用 Amazon SageMaker AI 上的 Amazon Nova LLM-as-a-Judge 评估生成式 AI 模型
评估大型语言模型(LLM)的性能超越了传统的统计指标。本文介绍了如何在 Amazon SageMaker AI 上使用 Amazon Nova LLM-as-a-Judge 功能,这是一个强大的、经过严格验证的 LLM 评估方法。Nova LLM-as-a-Judge 能够提供公正的、与人类偏好高度一致的成对比较,帮助用户在几分钟内部署工作流程,并做出数据驱动的模型改进决策。
2026-01-31
1
0
0
AI新闻/评测
AI工具应用
AI基础/开发
2026-01-31
使用 Amazon Nova LLM-as-a-Judge 在 Amazon SageMaker AI 上评估生成式 AI 模型
评估生成式AI模型的性能不能仅依赖统计指标。本文介绍了Amazon Nova LLM-as-a-Judge的综合方法,该功能在Amazon SageMaker AI上运行,能利用LLM的推理能力对其他模型进行灵活、大规模的评估。Nova LLM-as-a-Judge经过严格验证,在关键指标上表现出色,并能紧密反映人类偏好,是实现可靠、生产级LLM评估的新标准。
2026-01-31
1
0
0
AI新闻/评测
AI工具应用
AI基础/开发
2026-01-30
ChatGPT 中将停用 GPT-4o、GPT-4.1、GPT-4.1 mini 和 OpenAI o4-mini
OpenAI 宣布将于 2026 年 2 月 13 日在 ChatGPT 中停用 GPT-4o 等多个旧模型,API 不受影响。此举旨在聚焦于更先进的 GPT-5 系列模型,并回应用户对个性和创造力的反馈,这些反馈已融入 GPT-5.1 和 GPT-5.2,提供了更丰富的定制选项。
2026-01-30
0
0
0
AI新闻/评测
2026-01-30
AI炒作指数:Grok变成色情工具,Claude Code能完美胜任你的工作
AI领域正处于两极分化的恐慌中:一方面Grok被用于生成色情内容,另一方面Claude Code等工具展现出惊人的工作能力,能构建网站甚至解读MRI。本文深入探讨了当前AI技术的矛盾发展及其对就业市场带来的冲击,以及科技巨头间的激烈角力。
2026-01-30
0
0
0
AI新闻/评测
AI工具应用
2026-01-30
新研究揭示开源 AI 模型安全风险:若脱离限制运行或将被黑客轻易劫持
一项最新研究揭示,若开源大语言模型(LLM)在外部计算机上脱离主流平台的安全护栏与限制运行,将面临被黑客轻易劫持的严重安全风险。攻击者可直接针对运行LLM的主机发起攻击,从而操控模型生成垃圾信息、钓鱼内容或虚假宣传,绕过现有安全机制。研究发现,数千个开源模型部署中存在大量非法用途风险,甚至涉及生成儿童性虐待材料等严重问题。安全专家强调,行业对这种“剩余能力”的讨论严重不足,开源生态系统需要在模型安全发布后承担更多的注意义务,预判并提供缓解工具。
2026-01-30
4
0
0
AI新闻/评测
AI基础/开发
AI行业应用
2026-01-29
谷歌DeepMind新模型Gemini 1.5 Pro的重大突破:上下文窗口达100万Token
谷歌DeepMind新推出的Gemini 1.5 Pro大型语言模型实现了突破性的进展,其上下文处理窗口达到了惊人的100万个Token,是现有主流模型能力的数十倍。这一巨大飞跃意味着模型能够一次性处理数小时的视频内容或数十万行的代码库,极大地提升了信息检索和复杂任务处理的能力。新模型在保持高性能的同时,效率也得到了显著优化,预示着AI在处理长篇幅、多模态数据方面将迈入新的时代。
2026-01-29
1
0
0
AI基础/开发
AI新闻/评测
2026-01-29
语言模型对不同英语方言的偏见:ChatGPT的潜在歧视分析
尽管ChatGPT在全球被广泛使用,但其默认偏向标准美式英语(SAE),对非标准英语方言(如印度英语、尼日利亚英语等)存在系统性偏见。本研究发现,ChatGPT对非标准方言的回复存在更多的刻板印象、贬低内容和理解障碍,且新模型GPT-4的表现并未完全改善这一问题,反而可能加剧歧视。
2026-01-29
0
0
0
AI新闻/评测
AI行业应用
2026-01-29
大型多模态模型中基于下一个词元预测的多模态学习
本文介绍了Emu3,一个仅通过下一个词元预测进行训练的多模态模型家族。Emu3在感知和生成任务上与现有的特定任务模型(如使用扩散或组合架构的模型)性能相当,甚至匹配旗舰系统。它通过统一的词元预测,为大规模多模态建模奠定了坚实基础,并展示了高保真视频生成和多模态-动作建模能力,有望实现统一的多模态智能。
2026-01-29
1
0
0
AI新闻/评测
AI基础/开发
AI工具应用
2026-01-29
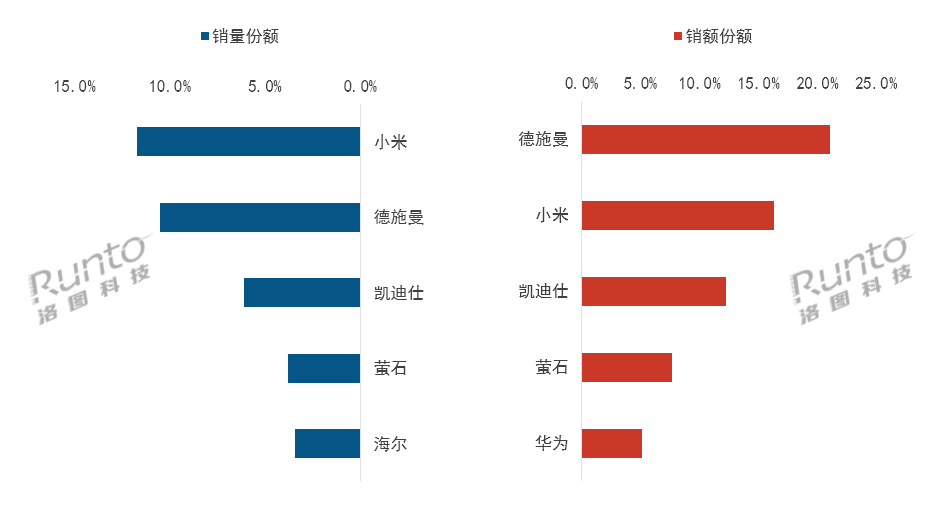
2025年中国智能门锁排行:小米全渠道销量第一!
根据洛图科技(RUNTO)的最新数据显示,2025年中国智能门锁全渠道销量达到1781万套,同比增长2.0%。在国补政策刺激下,市场格局进一步固化,小米、德施曼和凯迪仕稳居销量前三甲,合计市场份额提升至28.3%。其中,小米凭借全价位段覆盖和米家生态优势,在整体全渠道销量中拔得头筹。德施曼则在销售额方面领先,尤其在2000元以上高端市场表现突出,并积极融合AI大模型技术以巩固技术优势。
2026-01-29
1
0
0
AI行业应用
AI工具应用
2026-01-29
语言模型的语言偏见:ChatGPT如何对待不同英语方言
尽管ChatGPT普及,但它主要默认使用标准美式英语(SAE)。本研究深入调查了ChatGPT(GPT-3.5和GPT-4)对包括印度英语、爱尔兰英语和非裔美国人英语在内的非“标准”英语方言的响应偏见。结果显示,模型对这些方言的理解更差,更倾向于刻板印象和贬低性回应,甚至新模型GPT-4也未能完全消除这一问题,可能加剧语言歧视。
2026-01-29
0
0
0
AI新闻/评测
AI工具应用
1
2
3
4
5
...
18