目 录CONTENT

以下是
AI大模型评测
相关的文章
-

-
-
-
-
-
-
-
-
-
-
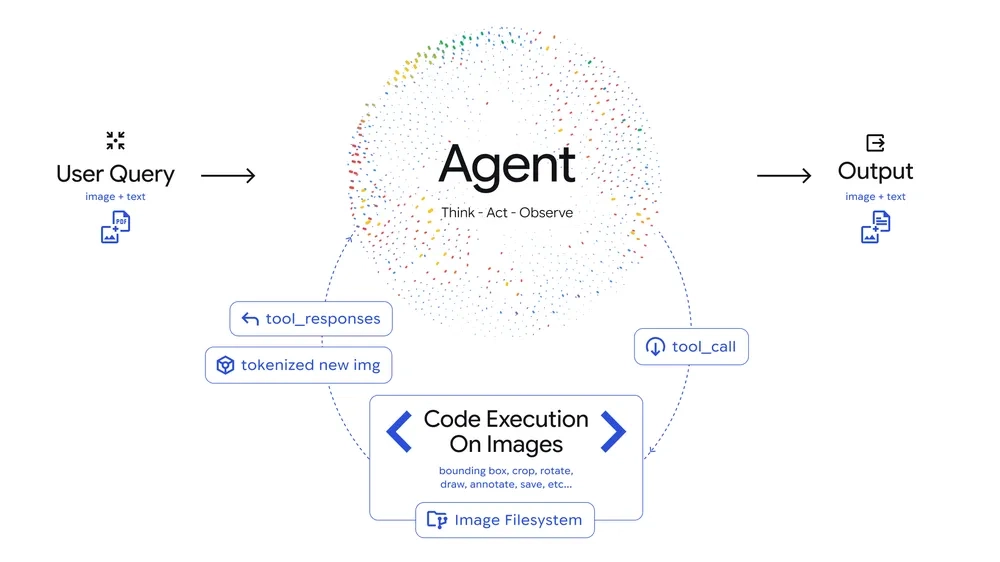
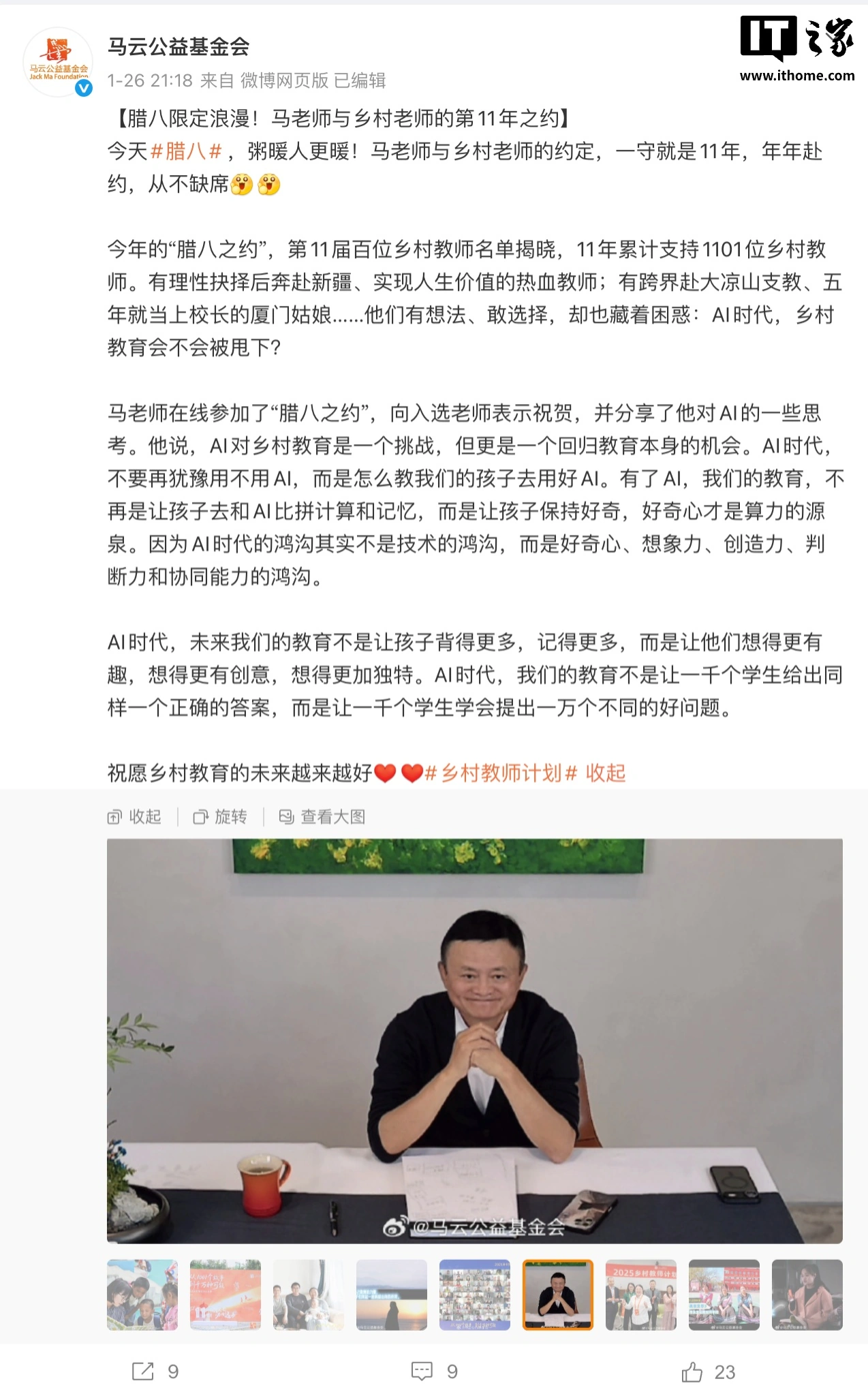
阿里发布旗舰推理模型Qwen3-Max-Thinking:性能媲美GPT-5.2、Claude Opus 4.5 阿里巴巴正式发布了其旗舰推理模型Qwen3-Max-Thinking,该模型参数量超万亿(1T),预训练数据量高达36T Tokens。目前,AI助手千问已在PC端和网页端接入此“AI大脑”,用户可通过一键切换体验更强的推理能力。性能方面,Qwen3-Max-Thinking在多项权威基准测试中表现出色,整体性能已可媲美GPT-5.2-Thinking-xhigh、Claude Opus 4.5和Gemini 3 Pro。该模型带来了更强的世界知识记忆、专家级的复杂推理能力以及更契合人类价...
-
-
-
-
-
-
-
-
-