



📢 转载信息
原文链接:https://www.kdnuggets.com/5-excel-ai-lessons-i-learned-the-hard-way
原文作者:Rachel Kuznetsov

Image by Editor
# 引言
对于许多组织,尤其是那些受监管行业或技术基础设施有限的组织来说,Excel及其 XLMiner 插件是进行预测建模和机器学习工作流程的主要平台。
然而,Excel的易用性掩盖了一个关键的差距:运行模型与构建可信赖的分析系统之间的区别。在参与一个贷款审批预测项目时,我发现基于Excel的机器学习失败的原因不在于算法的限制,而在于一些经常被忽视的做法。
本文将这些不愉快的经验转化为五个全面的框架,以提升您的Excel式机器学习工作。
# 经验教训1:异常值检测的多种方法
异常值处理更多是一门艺术而非科学,过早地移除可能会消除携带重要信息的合法极端值。在某个案例中,所有住宅资产价值超过95百分位数的都被使用简单的IQR(四分位距)计算移除,假设它们是错误数据。后来的分析显示,这实际上移除了合法的超高价值房产,而这对于大额贷款审批是一个相关的细分群体。
经验教训: 在移除异常值之前,应使用多种检测方法并进行人工审查。创建一个全面的异常值检测框架。
在主数据旁边的相邻工作表中,创建检测列:
- A列: 原始值 (residential_assets_value)
- B列: IQR方法
=IF(A2 > QUARTILE.INC($A$2:$A$4270,3) + 1.5*(QUARTILE.INC($A$2:$A$4270,3)-QUARTILE.INC($A$2:$A$4270,1)), "Outlier_IQR", "Normal") - C列: 3-西格玛方法
=IF(ABS(A2-AVERAGE($A$2:$A$4270)) > 3*STDEV($A$2:$A$4270), "Outlier_3SD", "Normal") - D列: 百分位数方法
=IF(A2 > PERCENTILE.INC($A$2:$A$4270,0.99), "Outlier_P99", "Normal") - E列: 组合标记
=IF(COUNTIF(B2:D2,"Outlier*")>=2, "INVESTIGATE", "OK") - F列: 人工审查 [备注,在调查后填写]
- G列: 最终决策 [保留/移除/转换]
这种多方法方法揭示了我贷款数据中的一些模式:
- 被所有三种方法(IQR、3-sigma和百分位数)标记的值:很可能是错误数据
- 被IQR标记但未被3-sigma标记的值:在偏斜分布中合法的较高值
- 仅被百分位数标记的值:我差点错失的极端但有效的数据点
“人工审查”列至关重要。对于每个被标记的观测值,记录发现,例如:“合法的豪华房产,经公共记录核实”或“可能是数据录入错误,数值超过市场最大值的10倍。”
# 经验教训2:始终设置随机种子
很少有经历比在准备最终报告时,无法重现之前展示的优秀模型结果更令人沮丧。这种情况发生在一个分类树模型上:某天的验证准确率为97.3%,但第二天的准确率却是96.8%。差异看起来很小,但这会损害分析的可信度。这会让听众质疑哪个数字是真实的,以及分析在多大程度上可以信任。
经验教训: 罪魁祸首是没有固定种子的随机分区。大多数机器学习算法在某个阶段都涉及随机性。
- 数据分区:哪些观测值进入训练集与验证集和测试集
- 神经网络:初始权重随机化
- 某些集成方法:随机特征选择
XLMiner 在数据分区时使用随机过程。每次运行具有相同参数的相同模型都会产生略有不同的结果,因为训练/验证拆分每次都不同。
解决方案很简单,但并不明显。当使用 XLMiner 的分区功能(在大多数模型对话框中都可以找到)时:
- 勾选标记为“设置种子”的复选框(默认未勾选)
- 输入一个特定的整数:12345、42、2024,或任何易于记忆的数字
- 将此种子值记录在模型日志中
现在,每当使用该种子运行模型时:
- 相同的训练/验证/测试拆分
- 相同的模型性能指标
- 对相同观测值的相同预测
- 完全可重现
以下是未设置种子时(对相同的逻辑回归进行三次运行)的贷款审批数据集的示例:
- 第1次运行:验证准确率 = 92.4%,F1分数 = 0.917
- 第2次运行:验证准确率 = 91.8%,F1分数 = 0.923
- 第3次运行:验证准确率 = 92.1%,F1分数 = 0.919
而使用种子=12345时(对相同的逻辑回归进行三次运行):
- 第1次运行:验证准确率 = 92.1%,F1分数 = 0.928
- 第2次运行:验证准确率 = 92.1%,F1分数 = 0.928
- 第3次运行:验证准确率 = 92.1%,F1分数 = 0.928
这种差异对于可信度来说至关重要。当需要重建分析时,可以自信地完成,因为数字是匹配的。
重要提示: 种子控制分区和初始化的随机性,但它不能使分析免受其他变化的影响。如果数据被修改(添加观测值、更改转换)或调整模型参数,结果仍然会不同,这是应该的。
# 经验教训3:正确的数据分区:三向划分
与可重现性相关的是分区策略。XLMiner 的默认设置创建了 60/40 的训练/验证拆分。这看起来很合理,直到出现问题:测试集在哪里?
一个常见的错误是构建一个神经网络,根据验证性能进行调整,然后将这些验证指标作为最终结果报告。
经验教训: 如果没有单独的测试集,优化会直接在报告的数据上进行,从而夸大性能估计。正确的划分策略使用三个集合。
1. 训练集(数据量的50%)
- 模型学习模式的地方
- 用于拟合参数、系数或权重
- 对于贷款数据集:约 2,135 个观测值
2. 验证集(数据量的30%)
- 用于模型选择和超参数调优
- 用于比较不同的模型或配置
- 有助于选择最佳的剪枝树、理想的截止值或理想的神经网络架构
- 对于贷款数据集:约 1,280 个观测值
3. 测试集(数据量的20%)
- “期末考试”——只评分一次
- 仅在所有建模决策完成后使用
- 提供对现实世界性能的无偏估计
- 对于贷款数据集:约 854 个观测值
关键规则: 绝不要根据测试集的性能进行迭代。一旦模型因“在测试集上表现更好”而被选中,该测试集就变成了第二个验证集,性能估计也会随之产生偏差。
这是我现在的流程:
- 将种子设置为 12345
- 划分 50/30/20(训练/验证/测试)
- 构建多个模型变体,仅在验证集上评估每个模型
- 根据验证性能和业务需求选择最佳模型
- 仅使用选定的模型对测试集进行一次评分
- 将测试集的性能作为预期的实际结果进行报告
以下是贷款审批项目的示例:
| 模型版本 | 训练准确率 | 验证准确率 | 测试准确率 | 已选定? |
|---|---|---|---|---|
| 逻辑回归(所有变量) | 90.6% | 89.2% | 尚未评分 | 否 |
| 逻辑回归(逐步法) | 91.2% | 92.1% | 尚未评分 | 否 |
| 分类树(深度=7) | 98.5% | 97.3% | 尚未评分 | 是 |
| 分类树(深度=5) | 96.8% | 96.9% | 尚未评分 | 否 |
| 神经网络(7个节点) | 92.3% | 90.1% | 尚未评分 | 否 |
在根据验证性能选择 分类树(深度=7) 后,测试集仅被评分一次:准确率为 97.4%。这个测试准确率代表了预期的生产性能。
# 经验教训4:训练/验证差距:在过拟合造成损害前发现它
问题:初步查看项目报告中的分类树结果似乎很有希望。
训练数据性能:
- 准确率:98.45%
- 精确率:99%
- 召回率:96%
- F1 分数:98.7%
模型到目前为止看起来很成功,直到焦点转向验证结果。
验证数据性能:
- 准确率:97.27%
- 精确率:98%
- 召回率:94%
- F1 分数:97.3%
差异看起来很小,准确率仅相差 1.18%。但确定这种差距是否构成问题需要一个系统的框架。
经验教训: 了解模型何时记忆而不是学习至关重要。
实践解决方案: 创建一个过拟合监控器。建立一个简单但系统的比较表,使过拟合显而易见。
步骤1:创建比较框架
以下是“Overfitting_Monitor”工作表中的模型性能比较:
| 指标 | 训练集 | 验证集 | 差距 | 差距 % | 状态 |
|---|---|---|---|---|---|
| 准确率 | 98.45% | 97.27% | 1.18% | 1.20% | ✓ 良好 |
| 精确率 | 99.00% | 98.00% | 1.00% | 1.01% | ✓ 良好 |
| 召回率 | 96.27% | 94.40% | 1.87% | 1.94% | ✓ 良好 |
| F1 分数 | 98.76% | 97.27% | 1.49% | 1.51% | ✓ 良好 |
| 特异性 | 96.56% | 92.74% | 3.82% | 4.06% | ? 观察 |
以下是解释规则:
- 差距 < 3%:✅ 良好 - 模型泛化良好
- 差距 3-5%:❓ 观察 - 可接受,但要密切监控
- 差距 5-10%:⚠️ 令人担忧 - 可能过拟合,考虑简化
- 差距 > 10%:❌ 问题 - 明确过拟合,必须解决
详细分析如下:
- 总体评估:良好
- 原因:所有主要指标的差距均在 2% 以内。特异性差距略高,但仍可接受。模型似乎泛化良好。
- 建议:继续进行测试集评估。
步骤2:添加计算公式
单元格:差距 (针对准确率)
=[@Training] - [@Validation]
单元格:差距 % (针对准确率)
=([@Training] - [@Validation]) / [@Training]
单元格:状态 (针对准确率)
=IF([@[Gap %]]<0.03, "✓ Good", IF([@[Gap %]]<0.05, "? Watch", IF([@[Gap %]]<0.10, "⚠ Concerning", "✗ Problem")))
步骤3:创建可视化过拟合图表
构建一个并排的条形图,比较每个指标的训练与验证结果。这可以使模式一目了然:

当条形图接近时,模型泛化良好。当训练条明显长于验证条时,存在过拟合。
跨不同模型的比较
真正的价值在于比较不同模型的过拟合模式。在“Model_Overfitting_Comparison”工作表中,这是比较情况:
| 模型 | 训练准确率 | 验证准确率 | 差距 | 过拟合风险 |
|---|---|---|---|---|
| 逻辑回归 | 91.2% | 92.1% | -0.9% | 低(负差距) |
| 分类树 | 98.5% | 97.3% | 1.2% | 低 |
| 神经网络(5个节点) | 90.7% | 89.8% | 0.9% | 低 |
| 神经网络(10个节点) | 95.1% | 88.2% | 6.9% | 高 – 拒绝此模型 |
| 神经网络(14个节点) | 99.3% | 85.4% | 13.9% | 非常高 – 拒绝此模型 |
解释: 具有 10 多个节点的神经网络明显过拟合。尽管训练准确率很高(99.3%),但验证准确率下降到 85.4%。该模型记忆了训练数据中无法泛化的模式。
最佳选择: 分类树
- 高性能(97.3% 验证准确率)
- 最小的过拟合(1.2% 差距)
- 复杂性和泛化能力的良好平衡
以下是一些在发现过拟合时减少它的简单方法:
- 对于分类树:减少最大深度或增加每个节点的最小样本数
- 对于神经网络:减少节点或层的数量
- 对于逻辑回归:移除变量或使用逐步选择
- 对于所有模型:如果可能,增加更多训练数据
# 经验教训5:为分类变量实施数据验证
数据输入错误是机器学习项目的无形杀手。一个小的拼写错误,例如使用“gradute”而不是“graduate”,会创建一个本应是二元变量的第三个类别。模型现在有了一个在训练期间从未见过的意外特征值,这可能在部署期间导致错误,或者更糟的是,在不知不觉中产生不正确的预测。
预防措施:Excel 的数据验证功能。以下是分类变量的实施协议:
在一个隐藏的工作表中(命名为“Validation_Lists”),创建有效值列表:
- 对于教育水平:创建一个包含“Graduate”和“Not Graduate”条目的列
- 对于自雇:创建一个包含“Yes”和“No”条目的列
- 对于贷款状态:创建一个包含“Approved”和“Rejected”条目的列
在数据输入工作表中:
- 选择分类变量的整个列(例如,包含教育数据的列)
- 数据 → 数据验证 → 设置选项卡
- 允许:列表
- 来源:导航到隐藏的验证工作表并选择适当的列表
- 错误提醒选项卡:样式 = 停止,并附带明确的消息:“只允许输入‘Graduate’或‘Not Graduate’”
现在不可能输入无效值。用户会看到一个包含有效选项的下拉列表,从而完全消除了打字错误。
对于具有已知范围的数值变量,应用类似的数据验证以防止不可能的值:
- 信用分数:必须在 300 到 900 之间
- 贷款期限:必须在 1 到 30 年之间
- 年收入:必须大于 0
选择该列,应用数据验证,设置:
- 允许:整数(或小数)
- 数据:介于两者之间
- 最小值:300(针对信用分数)
- 最大值:900
# 最后的想法
以下是文章中概述的经验教训的总结。
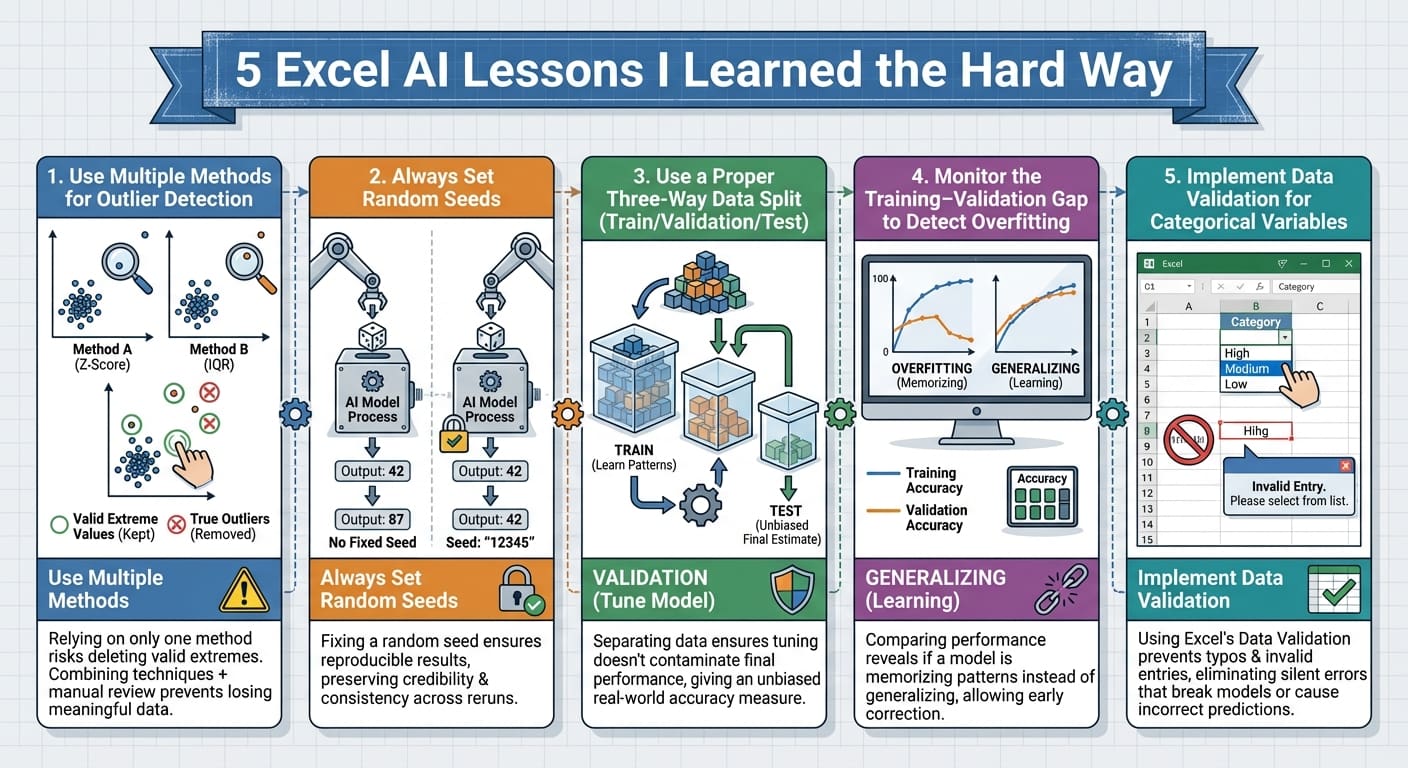
5 Excel AI Lessons I Learned the Hard Way (点击放大)
本文介绍的五项实践——多方法异常值检测、设置随机种子、三向数据分区、监控训练-验证差距以及实施数据验证——有一个共同点:它们都很容易实施,但遗漏起来却会带来灾难性的后果。
这些实践都不需要高级统计知识或复杂的编程。它们不需要额外的软件或昂贵的工具。Excel XLMiner 是一个用于可访问的机器学习的强大工具。
Rachel Kuznetsov 拥有商业分析硕士学位,热衷于解决复杂的数据难题并寻找新的挑战。她致力于让复杂的科学概念更容易理解,并正在探索人工智能影响我们生活的各种方式。在她持续学习和成长的征途中,她记录自己的旅程,以便其他人可以与她一起学习。您可以在 LinkedIn 上找到她。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区