



📢 转载信息
原文链接:https://www.kdnuggets.com/we-tried-5-missing-data-imputation-methods-the-simplest-method-won-sort-of
原文作者:Nate Rosidi

Image by Author
# 设置
你正准备训练一个模型,却发现 20% 的值是缺失的。你会删除这些行吗?用平均值填充?还是用更花哨的方法?答案比你想象的更重要。
如果你在网上搜索,你会找到几十种插补方法,从最简单(只用平均值)到最复杂的(迭代机器学习模型)。你可能会认为花哨的方法更好。 K近邻(KNN)会考虑相似的行。 MICE 会构建预测模型。它们肯定比直接使用平均值要好,对吧?
我们也曾这样认为。我们错了。
# 实验
我们从 StrataScratch 项目中获取了 作物推荐数据集——包含 22 种作物、2,200 个土壤样本,以及氮含量、温度、湿度和降雨量等特征。一个随机森林模型在这个数据集上达到了 99.6% 的准确率。这几乎干净得令人怀疑。
本次分析扩展了我们关于 农业数据分析 的项目,该项目通过探索性数据分析(EDA)和统计检验来探索相同的数据集。在这里,我们问:当干净的数据遇到真实世界的问题——缺失值——会发生什么?
非常适合我们的实验。
我们引入了 20% 的缺失值(完全随机,模拟传感器故障),然后测试了五种插补方法:

我们的测试非常彻底;我们使用了 5 个随机种子上的 10 折交叉验证(每种方法总共运行 50 次)。为确保测试集信息不泄露到训练集中,我们的插补模型仅在训练集上进行训练。对于统计检验,我们应用了 Bonferroni 校正。我们还对 KNN 和 MICE 的输入特征进行了标准化,因为如果我们不进行标准化,值范围在 0 到 300 之间(降雨量)的输入,在为这些方法进行距离计算时,将比值范围在 3 到 10 之间(pH值)的输入产生更大的影响。完整的代码和可重现的结果可以在我们的 notebook 中找到。
然后我们运行了它并盯着结果看。
# 惊喜
我们预期的结果是:KNN 或 MICE 会获胜,因为它们更智能。它们会考虑特征间的关系。它们使用真正的机器学习。
我们得到的结果是:
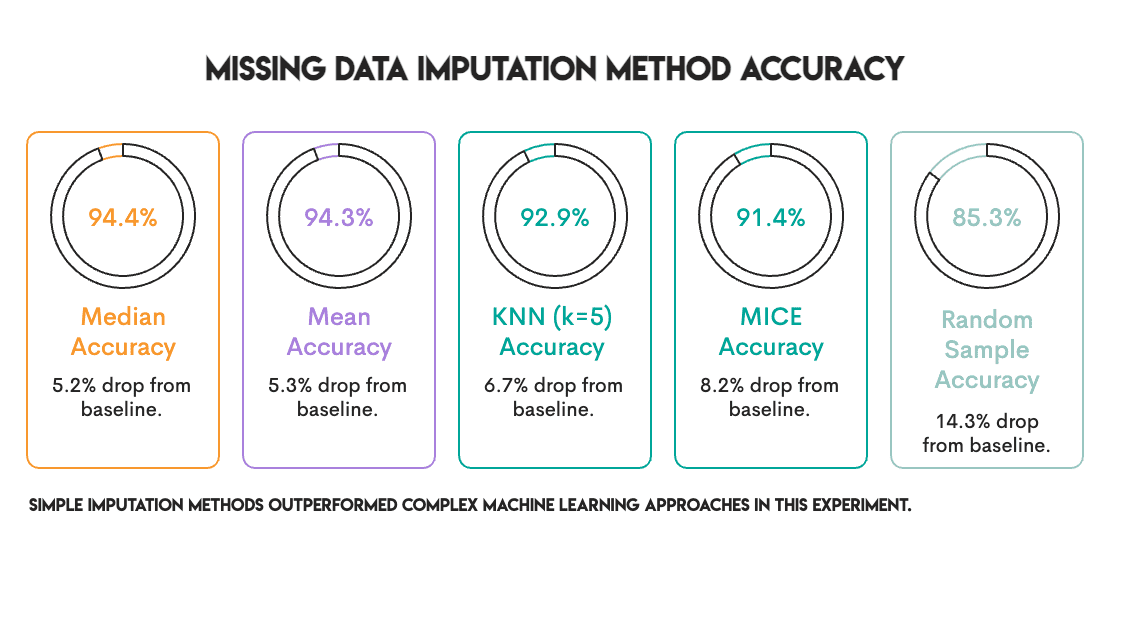
中位数和平均值并列第一。那些复杂的(Sophisticated)方法排在第三和第四位。
我们运行了统计检验。平均值 vs. 中位数:p = 0.7。根本不接近显著性。它们实际上是相同的。
但关键在于:它们都显著优于 KNN 和 MICE(经过 Bonferroni 校正后 p < 0.001)。简单的这些方法不仅匹配了花哨的方法。它们击败了它们。
# 等等,怎么回事?
在你扔掉 MICE 安装程序之前,让我们深入探讨一下为什么会发生这种情况。
任务是预测。我们衡量的是准确率。插补后模型是否仍能正确分类作物?对于这个特定目标,重要的是保留预测信号,而不一定需要保留确切的值。
平均值插补做了一些有趣的事情:它用一个“中性”值替换缺失值,这个值不会将模型推向任何特定的类别。这很无聊,但很安全。随机森林仍然可以找到其决策边界。
KNN 和 MICE 更加努力;它们估计了实际值可能是什么。但在此过程中,它们可能会引入噪声。如果最近邻居并不那么相似,或者如果 MICE 的迭代建模捕获了虚假的模式,那么你可能是在增加错误而不是消除错误。
基线已经很高了。准确率为 99.6%,这是一个相当容易的分类问题。当信号很强时,插补错误就不那么重要了。模型可以承受一些噪声。
随机森林 是稳健的。基于树的模型能很好地处理不完美的数据。线性模型在处理平均值插补导致的方差失真时遇到了更多困难。

别高兴得太早。
# 情节反转
我们衡量了另一项指标:相关性保留。
真实数据的关键在于:特征不是孤立存在的。它们会一起变动。在我们的数据集中,当土壤含磷量很高时,它通常也含有很高的钾含量(相关性为 0.74)。这不是随机的;农民通常一起添加这些营养素,并且某些土壤类型对两者的保持程度相似。
当你对缺失值进行插补时,你可能会不小心破坏这些关系。平均值插补用一个“平均钾含量”来填充缺失值,而不管该行中磷含量如何。多次这样做,P 和 K 之间的联系就会开始减弱。你的插补数据可能逐列看起来不错,但列之间的关系却在悄悄地瓦解。
为什么这很重要?如果你的下一步是 聚类、PCA,或任何以特征关系为重点的分析,那么你正在处理受损的数据,而且你甚至不知道。
我们检查了:插补后,有多少 P↔K 相关性得以保留?
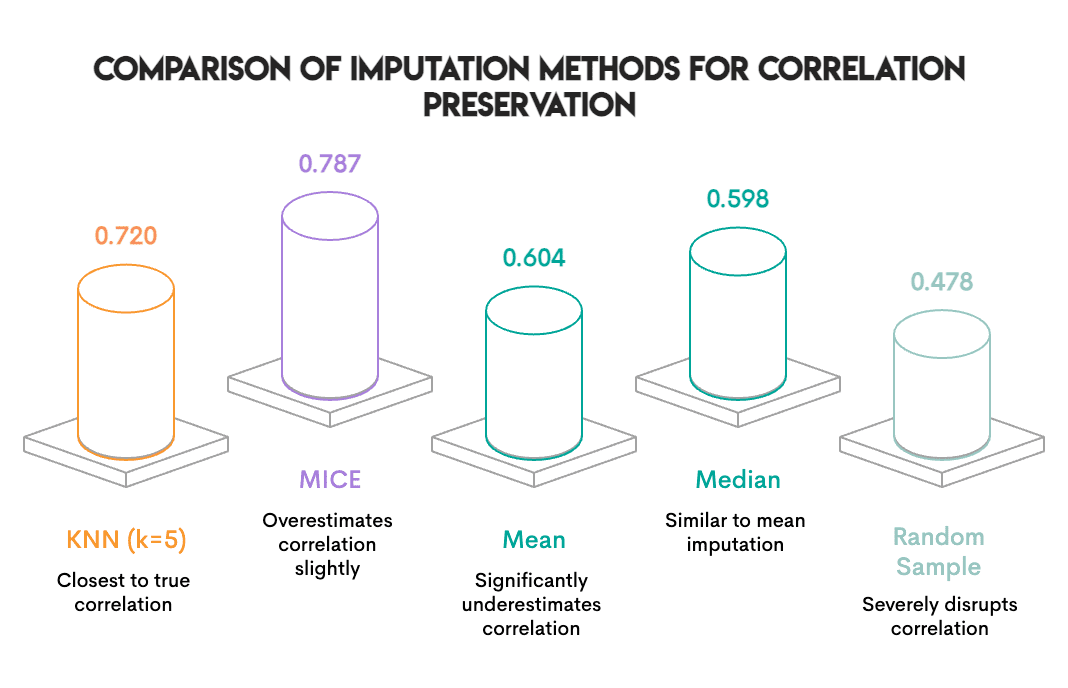
Image by Author
排名完全颠倒了。
KNN 几乎完美地保留了相关性。平均值和中位数破坏了其中约四分之一。而随机抽样(对每列独立抽样值)消除了这种关系。
这是有道理的。平均值插补用相同的数字替换缺失值,而不管其他特征是什么样子。如果一行具有高氮含量,平均值插补也不关心;它仍然会用平均钾含量进行插补。KNN 查看相似的行,因此如果高氮行倾向于高钾,它就会插补一个高钾值。
# 权衡
真正的发现是:没有单一的最佳插补方法。相反,应根据你的具体目标和环境选择最合适的方法。
准确率排名和相关性排名几乎是相反的:
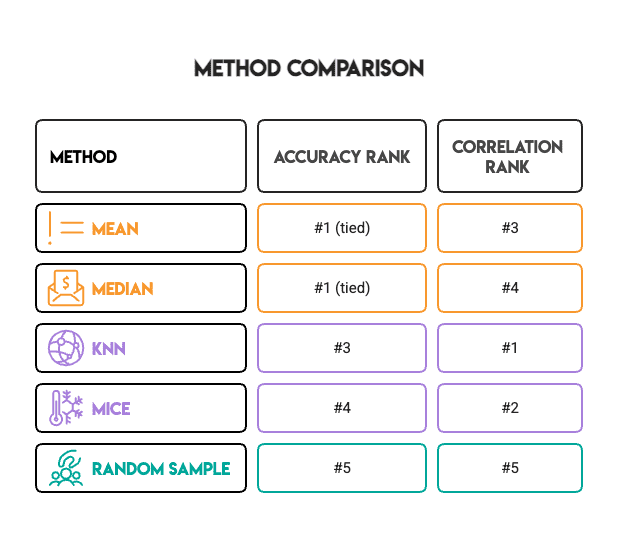
Image by Author
(至少随机抽样是一致的——它在所有方面都很糟糕。)
这种权衡并非我们的数据集所独有。它根植于这些方法的运行方式。平均值/中位数是单变量的,它们一次只看一列。KNN/MICE 是多变量的,它们会考虑关系。单变量方法保留边际分布但破坏相关性。多变量方法保留结构,但可能会产生某种形式的预测误差/噪声。
# 那么,你实际上应该怎么做?
在运行此实验并深入研究文献后,我们得出了以下实用指南:
当满足以下条件时,使用平均值或中位数:
- 你的目标是预测(分类、回归)
- 你使用的是稳健的模型(随机森林、XGBoost、神经网络)
- 缺失率低于 30%
- 你需要快速的方法
当满足以下条件时,使用 KNN:
- 你需要保留特征关系
- 下游任务是聚类、PCA 或可视化
- 你希望相关性能在探索性分析中得以保留
当满足以下条件时,使用 MICE:
- 你需要有效的标准误差(用于统计推断)
- 你正在报告置信区间或 p 值
- 缺失数据机制可能是 MAR(在随机缺失)
避免随机抽样:
- 它看起来很诱人,因为它“保留了分布”
- 但它会破坏所有多变量结构
- 我们找不到一个好的用例
# 诚实的注意事项
我们测试了一个数据集、一个缺失率(20%)、一个机制(MCAR,完全随机缺失)和一种下游模型(随机森林)。你的设置可能会有所不同。文献表明,在其他数据集上,MissForest 和 MICE 通常表现更好。我们关于简单方法可以竞争的发现是真实的,但并非普遍适用。
# 底线
我们进行这项实验的初衷是想证实复杂的插补方法物有所值。相反,我们发现对于预测准确性,谦逊的平均值方法表现出色,但在保留特征之间的关系方面却完全失败了。
教训不是“总是使用平均值插补”。而是“了解你正在优化什么”。

Image by Author
如果你只需要预测,请从简单的方法开始。测试一下 KNN 或 MICE 在你的数据上是否真的有帮助。不要想当然。
如果你需要相关结构用于下游分析,平均值会在给你完全合理的准确率数字的同时,悄悄地破坏它。这是一个陷阱。
无论你做什么,在使用 KNN 之前请缩放你的特征。相信我们这一点。
Nate Rosidi 是一位数据科学家和产品策略师。他还是教授分析课程的兼职教授,也是 StrataScratch 的创始人,该平台通过来自顶级公司的真实面试问题帮助数据科学家准备面试。Nate 撰写关于职业市场最新趋势、提供面试建议、分享数据科学项目,并涵盖 SQL 的所有内容。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区