



📢 转载信息
原文链接:https://www.kdnuggets.com/7-tiny-ai-models-for-raspberry-pi
原文作者:Abid Ali Awan
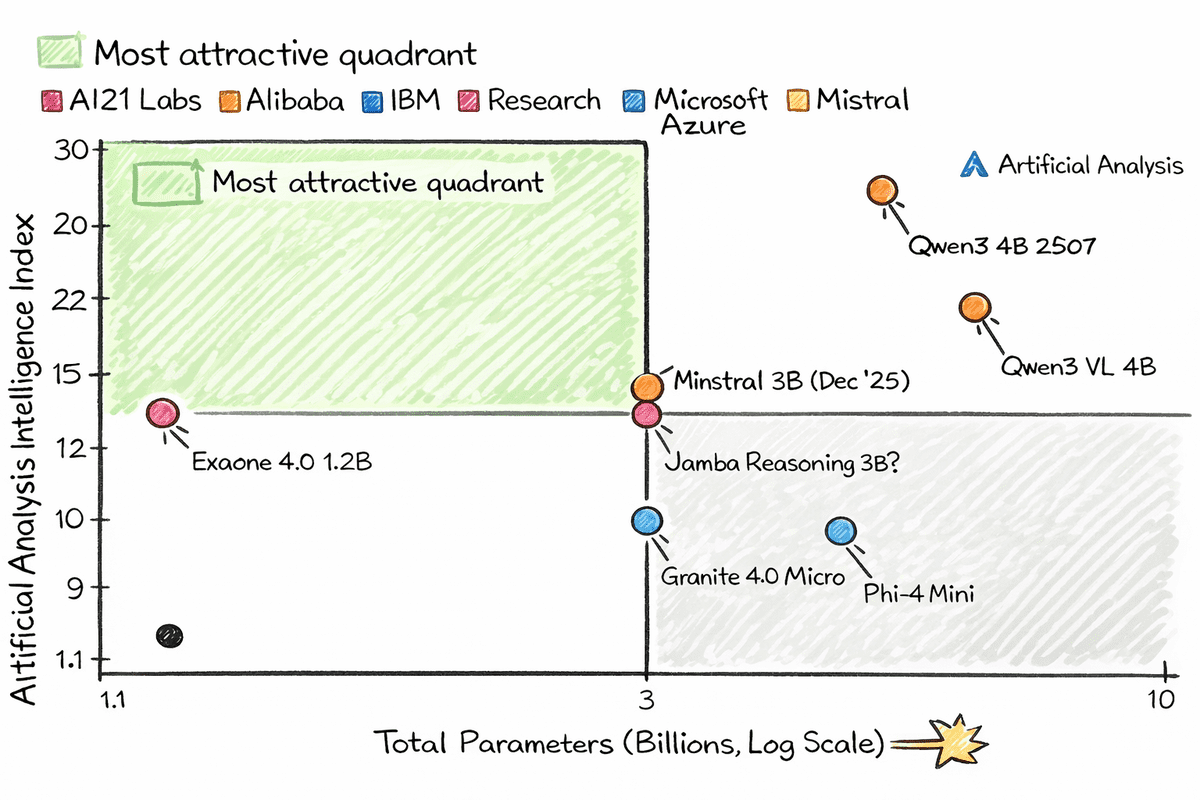
图片基于 Artificial Analysis
# 引言
我们经常谈论小型AI模型。但那些真正能够在CPU能力有限、内存极少的树莓派等微小设备上运行的微型模型呢?
得益于现代架构和积极的量化技术,参数量在10亿到20亿左右的模型现在可以运行在极其小巧的设备上。当这些模型被量化后,它们几乎可以在任何地方运行,甚至可以在您的智能冰箱上运行。您所需要的只是llama.cpp、一个来自Hugging Face Hub的量化模型以及一个简单的命令即可开始。
这些微型模型的激动人心之处在于,它们并非弱小或过时。在实际的文本生成任务中,许多模型的性能超越了许多早期的更大型模型。有些模型还支持工具调用、视觉理解和结构化输出。它们不是又小又笨的模型。它们小巧、快速,而且出奇地智能,完全有能力在可以握在手中的设备上运行。
在本文中,我们将探讨7款可以在树莓派和其他低功耗机器上使用llama.cpp良好运行的微型AI模型。如果您想在没有GPU、没有云成本或繁重基础设施的情况下实验本地AI,那么这个列表是一个绝佳的起点。
# 1. Qwen3 4B 2507
Qwen3-4B-Instruct-2507是一款紧凑但功能强大的非思考型语言模型,在其尺寸级别上实现了性能的巨大飞跃。它仅有40亿参数,在指令遵循、逻辑推理、数学、科学、编码和工具使用方面表现出强劲的提升,同时扩展了对多种语言的长尾知识覆盖。
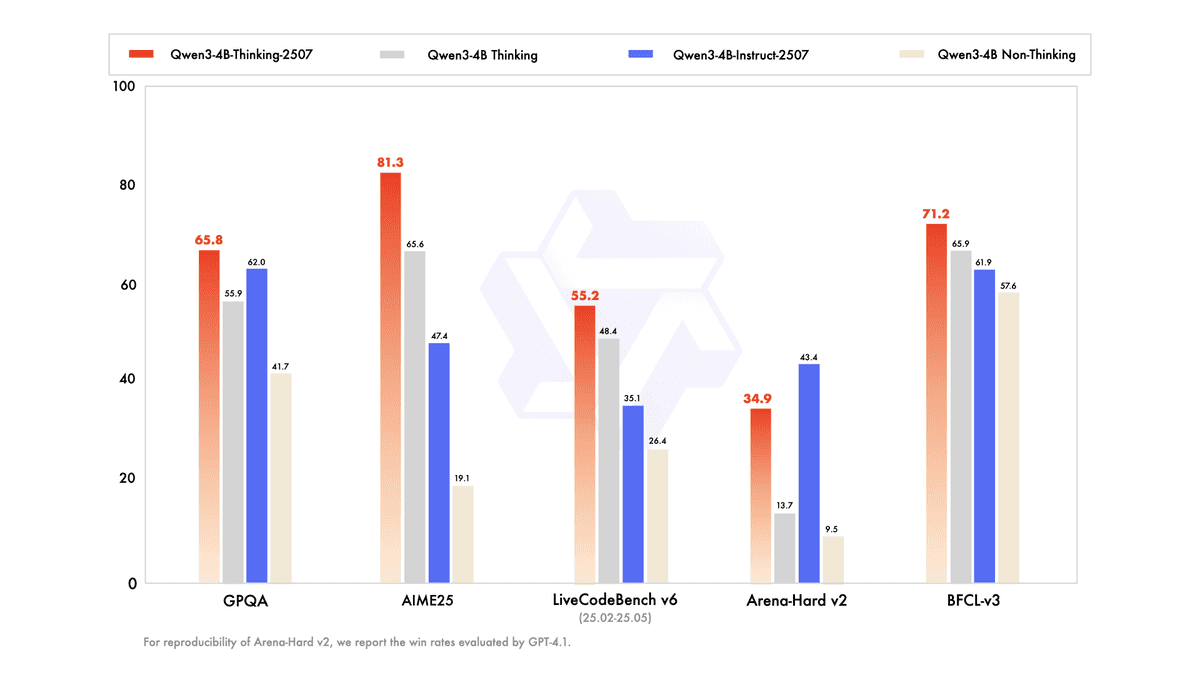
该模型在主观和开放式任务中表现出对用户偏好的显著改进的对齐性,从而生成更清晰、更有帮助和更高质量的文本。它支持令人印象深刻的256K原生上下文长度,使其能够高效处理极长的文档和对话,成为对深度和速度有要求但又不想承受大型模型开销的实际应用的选择。
# 2. Qwen3 VL 4B
Qwen3‑VL‑4B‑Instruct是Qwen家族迄今为止最先进的视觉-语言模型,它将最先进的多模态智能封装在一个高效的4B参数的外形尺寸中。它提供了卓越的文本理解和生成能力,并结合了更深层次的视觉感知、推理和空间意识,使其在图像、视频和长文档处理方面表现出色。
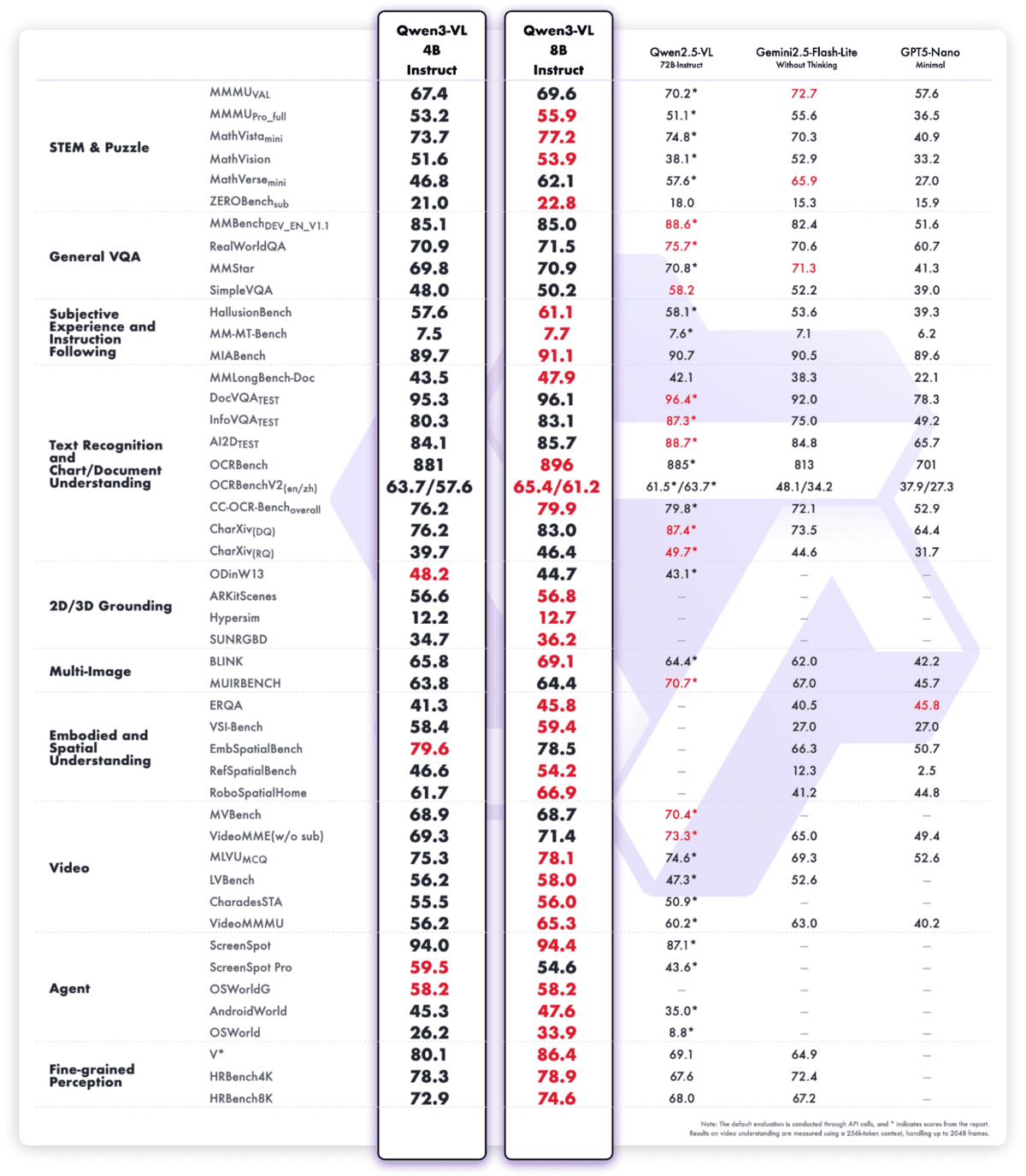
该模型支持原生的256K上下文(可扩展至1M),使其能够处理整本书或数小时的视频,并具有准确的召回率和精细的时间戳索引。像交错式MRoPE、深度堆栈视觉融合和精确文本-时间戳对齐这样的架构升级,显著提高了长程视频推理、精细细节识别和图像-文本对齐能力。
除了感知能力,Qwen3‑VL‑4B‑Instruct还充当视觉代理,能够操作PC和移动设备的GUI、调用工具、生成视觉代码(HTML/CSS/JS, Draw.io),并处理以文本和视觉为基础的复杂多模态工作流。
# 3. Exaone 4.0 1.2B
EXAONE 4.0 1.2B是一款紧凑的、对设备友好的语言模型,旨在将代理式AI和混合推理引入资源效率极高的部署中。它集成了非推理模式以实现快速、实用的响应,以及可选的推理模式以解决复杂问题,允许开发者在单个模型内动态地权衡速度和深度。
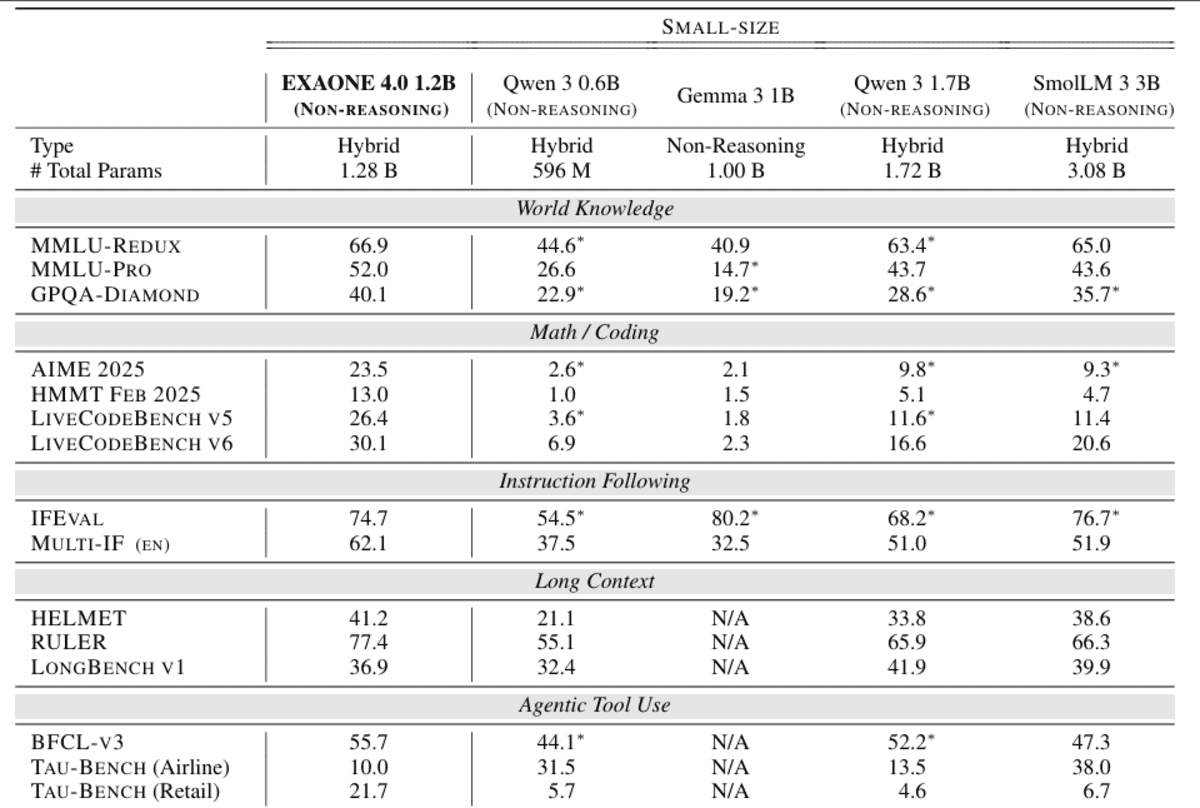
尽管体积很小,1.2B变体仍支持代理式工具使用,使其能够进行函数调用和自主任务执行,并提供英语、韩语和西班牙语的多语言能力,将其用途扩展到单语边缘应用之外。
在架构上,它继承了EXAONE 4.0的先进特性,如混合注意力机制和改进的规范化方案,同时支持64K的令牌上下文长度,这使其在如此小的规模下,对于长上下文理解能力异常强大。
它专门针对对内存占用和延迟与模型质量同等重要的设备端和低成本推理场景进行了优化。
# 4. Ministral 3B
Ministral-3-3B-Instruct-2512是Ministral 3系列中最小的成员,是一款高度高效的微型多模态语言模型,专为边缘和低资源部署而设计。它是一个FP8指令微调模型,专门针对聊天和指令遵循工作负载进行了优化,同时保持了对系统提示和结构化输出的强有力遵循。
在架构上,它将一个3.4B参数的语言模型与一个0.4B的视觉编码器相结合,实现了文本推理与原生图像理解的集成。
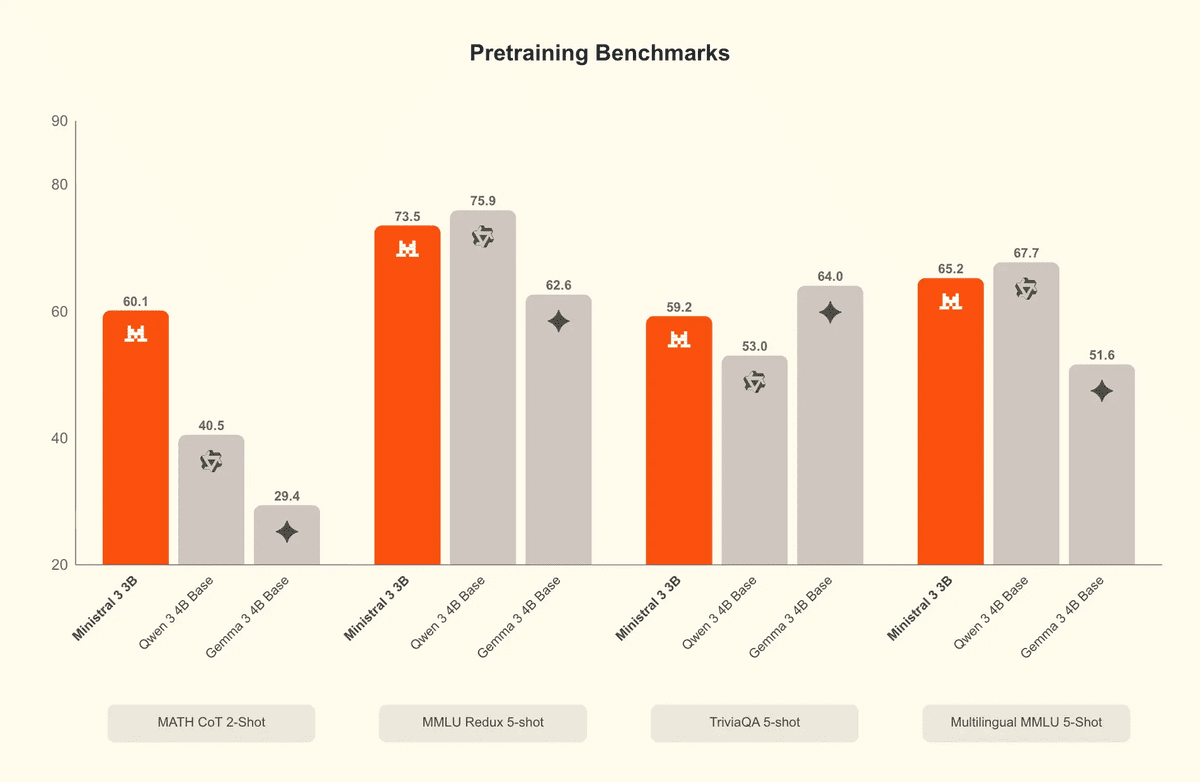
尽管体积紧凑,该模型支持256K的上下文窗口、强大的多语言覆盖(数十种语言)以及原生的代理能力(如函数调用和JSON输出),使其非常适合需要效率而又不牺牲能力的实时、嵌入式和分布式AI系统。
该模型旨在以FP8格式容纳在8GB VRAM以内(量化后更少),Ministral 3 3B Instruct在每瓦性能和每美元性能方面表现出色,适用于那些要求效率但又需要能力的生产用例。
# 5. Jamba Reasoning 3B
Jamba-Reasoning-3B是一款紧凑但能力超群的30亿参数推理模型,旨在以小巧的体积提供强大的智能、长上下文处理能力和高效率。
其明确的创新是混合Transformer–Mamba架构,其中少量的注意力层负责捕获复杂依赖关系,而大部分层则使用Mamba状态空间模型来实现高效的序列处理。
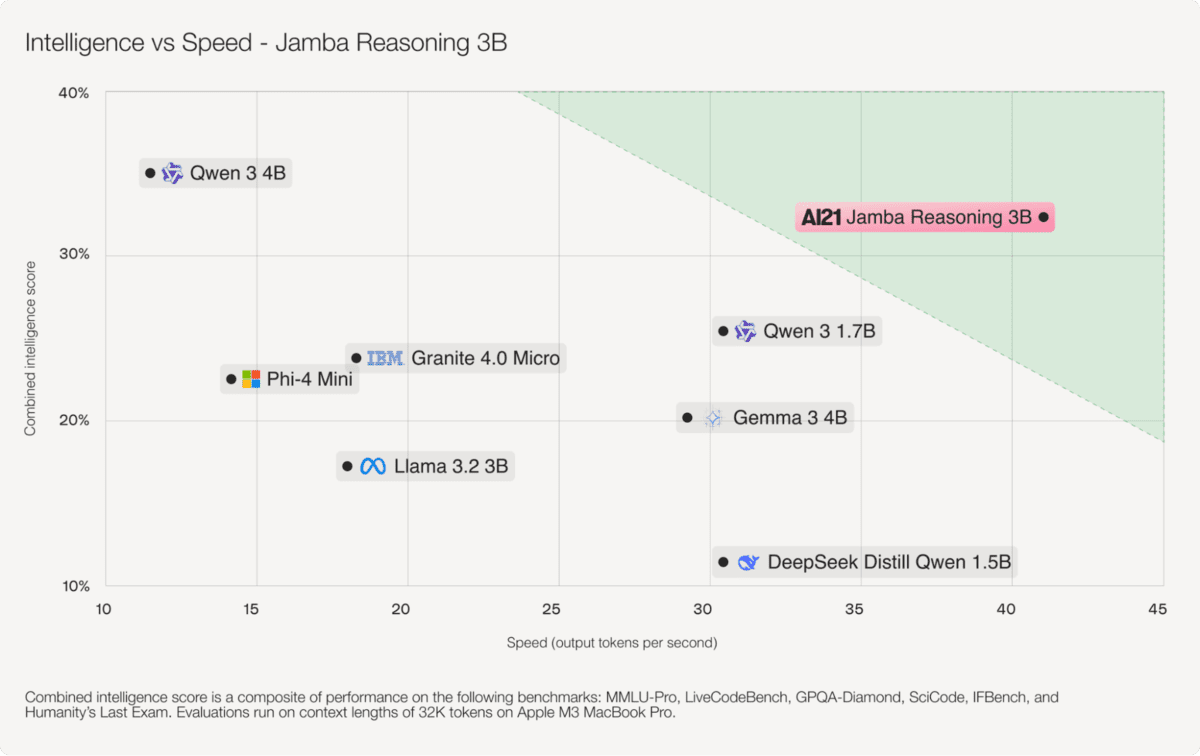
这种设计显著减少了内存开销并提高了吞吐量,使得模型能够在笔记本电脑、GPU,甚至移动级设备上流畅运行,而不会牺牲质量。
尽管体积小,Jamba Reasoning 3B支持256K令牌上下文,可以扩展到非常长的文档,而无需依赖庞大的注意力缓存,这使得长上下文推理变得实用且具有成本效益。
在智能基准测试中,它在跨多个评估的综合分数上超越了可比较的小模型,如Gemma 3 4B和Llama 3.2 3B,展示了其同级别模型中非同寻常的强大推理能力。
# 6. Granite 4.0 Micro
Granite-4.0-micro是由IBM的Granite团队开发的一款3B参数长上下文指令模型,专门为企业级助手和代理工作流而设计。
它使用许可开放的数据集和高质量的合成数据进行微调,强调可靠的指令遵循、专业的语调和安全的响应,这一点在2025年10月的更新中通过添加的默认系统提示得到了加强。
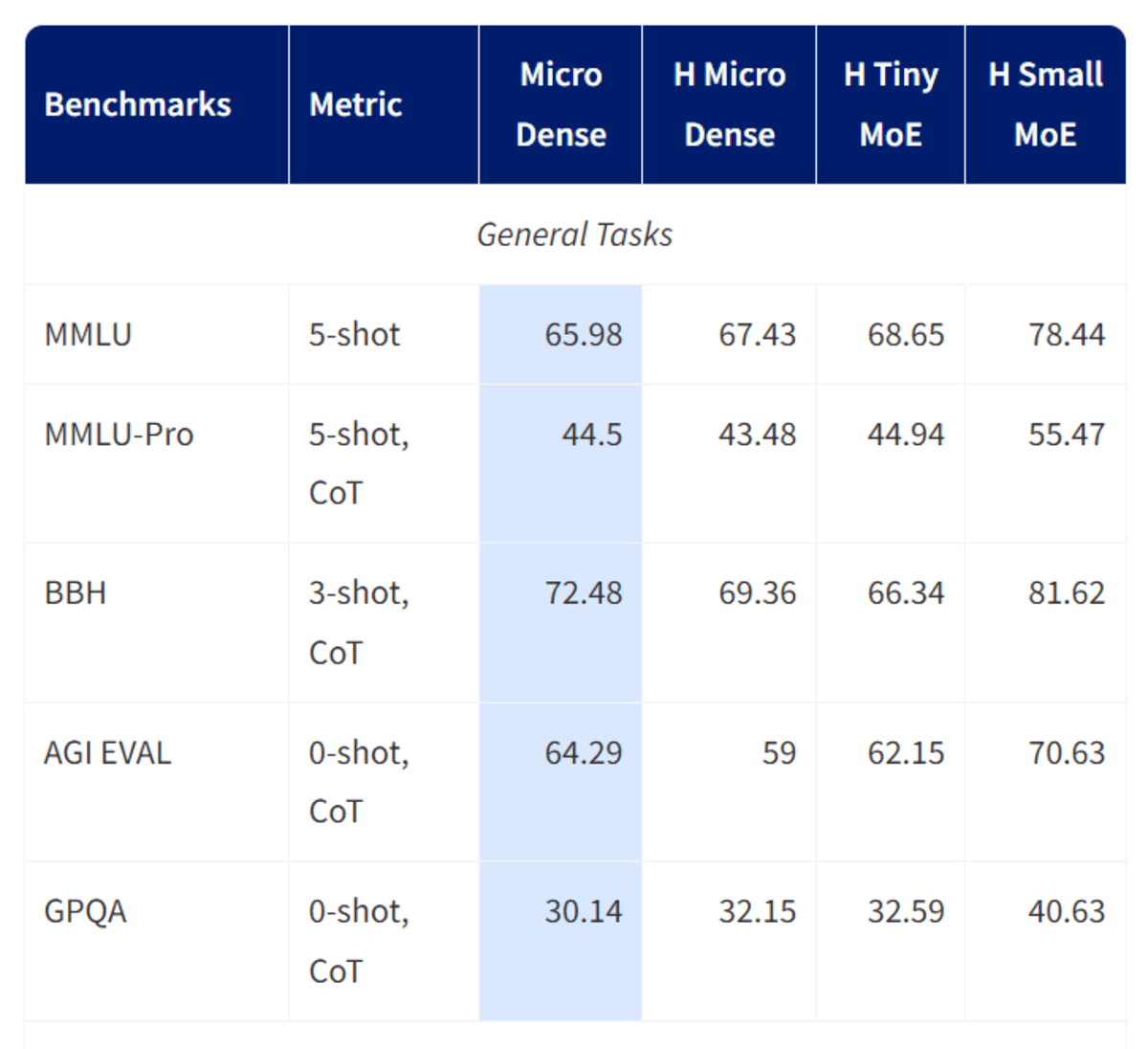
该模型支持非常大的128K上下文窗口、强大的工具调用和函数执行能力,以及广泛的多语言支持,涵盖主要的欧洲、中东和东亚语言。
Granite‑4.0‑Micro基于具有GQA、RoPE、SwiGLU MLP和RMSNorm等现代组件的密集解码器Transformer架构构建,在稳健性和效率之间取得了平衡,非常适合作为需要与外部系统干净集成的商业应用、RAG管道、编码任务和LLM代理的基础模型,并且采用Apache 2.0开源许可。
# 7. Phi-4 Mini
Phi-4-mini-instruct是微软推出的一款轻量级、开放的3.8B参数语言模型,旨在在严格的内存和计算限制下提供强大的推理和指令遵循性能。
它基于密集的解码器Transformer架构构建,主要在高质量的合成“教科书式”数据和经过精心过滤的公共来源上进行训练,特意强调推理密集型内容而非原始事实记忆。
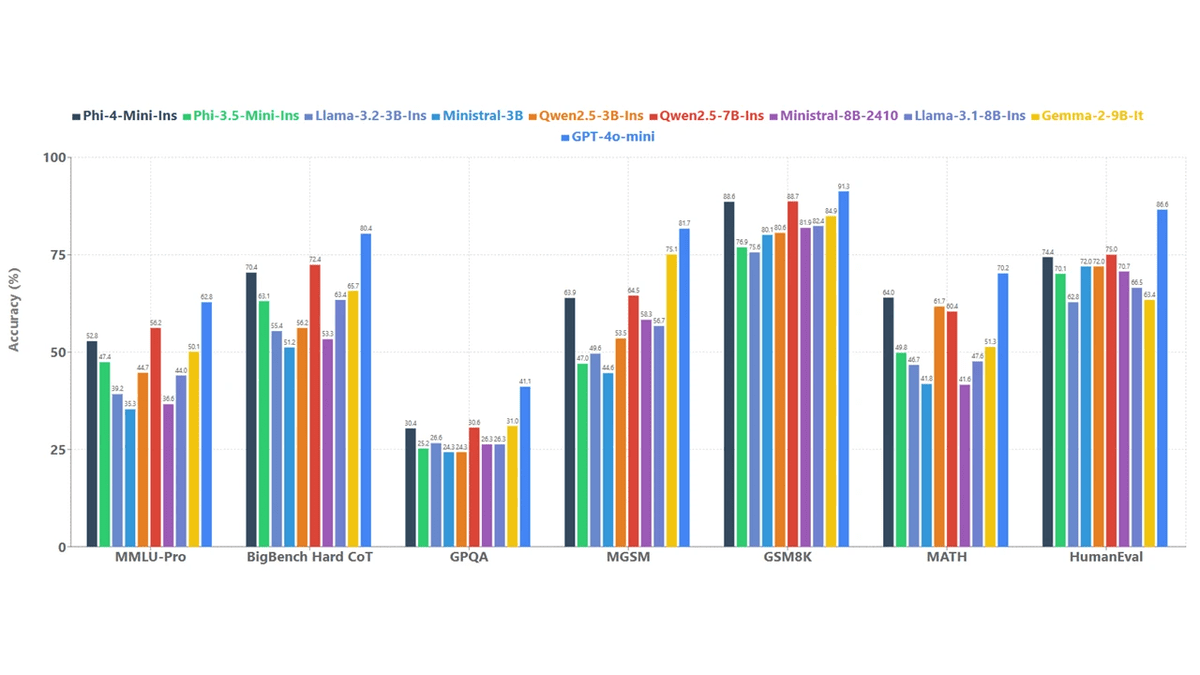
该模型支持128K令牌上下文窗口,在如此小的规模下实现了长文档理解和扩展对话,这很不常见。
后训练结合了监督微调和直接偏好优化,从而实现了精确的指令遵循、稳健的安全行为和有效的函数调用。凭借庞大的200K令牌词汇量和广泛的多语言覆盖,Phi‑4‑mini‑instruct被定位为研究和生产系统的实用构建块,这些系统必须在延迟、成本和推理质量之间取得平衡,尤其是在内存或计算受限的环境中。
# 最终思考
微型模型已经发展到现在,尺寸不再是能力上的限制。在本次列表中,Qwen 3系列脱颖而出,它提供的性能可与规模大得多的语言模型相媲美,甚至能挑战一些专有系统。如果您正在为树莓派或其他低功耗设备构建应用程序,Qwen 3是一个极好的起点,非常值得集成到您的设置中。
除了Qwen之外,EXAONE 4.0 1.2B模型在推理和非平凡问题解决方面尤其强大,同时比大多数替代品小得多。Ministral 3B也因其系列中的最新版本和坚实的通用性能而值得关注。
总的来说,许多这些模型都令人印象深刻,但如果您的优先事项是速度、准确性和工具调用,那么Qwen 3的LLM和VLM变体是难以匹敌的。它们清楚地展示了微型、设备端AI的发展程度,以及为什么在小型硬件上进行本地推理不再是一种妥协。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为与心理健康斗争的学生构建一个AI产品。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区