



📢 转载信息
原文作者:Antonio Martellotta and Dr. Mikkel Hansen
本文由 Qbtech 的 Dr. Mikkel Hansen 联合撰写。
注意力缺陷多动障碍(ADHD)的评估和诊断传统上依赖于临床观察和行为评估。虽然这些方法很有价值,但过程可能复杂且耗时。Qbtech 公司于 2002 年在瑞典斯德哥尔摩成立,通过将客观测量与临床专业知识相结合,增强了 ADHD 的诊断能力,帮助临床医生做出更明智的诊断决策。其获得 FDA 批准和 CE 标志的产品——QbTest(基于诊所)和 QbCheck(远程)——已在全球 14 个国家完成了超过一百万次测试,已成为广泛采用的客观 ADHD 测试工具。现在,Qbtech 旨在通过 QbMobile 扩展其能力,这是一个智能手机原生评估应用,它使用亚马逊云科技(AWS)将临床级别的 ADHD 测试直接带到患者的设备上。
在本文中,我们将探讨 Qbtech 如何利用 Amazon SageMaker AI(一项用于构建、训练和部署 ML 模型的全托管服务)和 AWS Glue(一项使数据集成更简单、更快、更具成本效益的无服务器服务)来简化其机器学习(ML)工作流程。Qbtech 开发并部署了一个模型,该模型能够高效地处理来自智能手机摄像头、运动传感器和测试结果的数据。这一新解决方案将特征工程时间从数周缩短到数小时,同时保持了医疗服务提供商所需的高临床标准。
挑战:让客观 ADHD 评估触手可及
ADHD 影响着全球数百万人,但传统的诊断往往涉及漫长的等待时间和多次诊所就诊。虽然 Qbtech 现有的解决方案推进了临床和基于网络摄像头的远程测试,但该公司发现了一个通过智能手机技术扩大可及性的机会。Qbtech 需要将来自不同智能手机硬件的原始摄像头源和运动传感器数据,转化为临床验证的 ADHD 评估结果,这些结果应能与其既有的临床工具提供同等的客观诊断价值。这要求处理复杂的多模态数据流,提取有意义的特征,并训练出能够在数千种设备变体中保持准确性的模型——所有这些都必须符合严格的医疗监管要求。
构建人工智能(AI)模型:从原始数据到临床见解
Qbtech 的移动 ADHD 评估方法利用机器学习技术来同时处理和分析多个数据流。该团队选择 Binary LightGBM 作为其 ADHD 评估模型的主要算法。
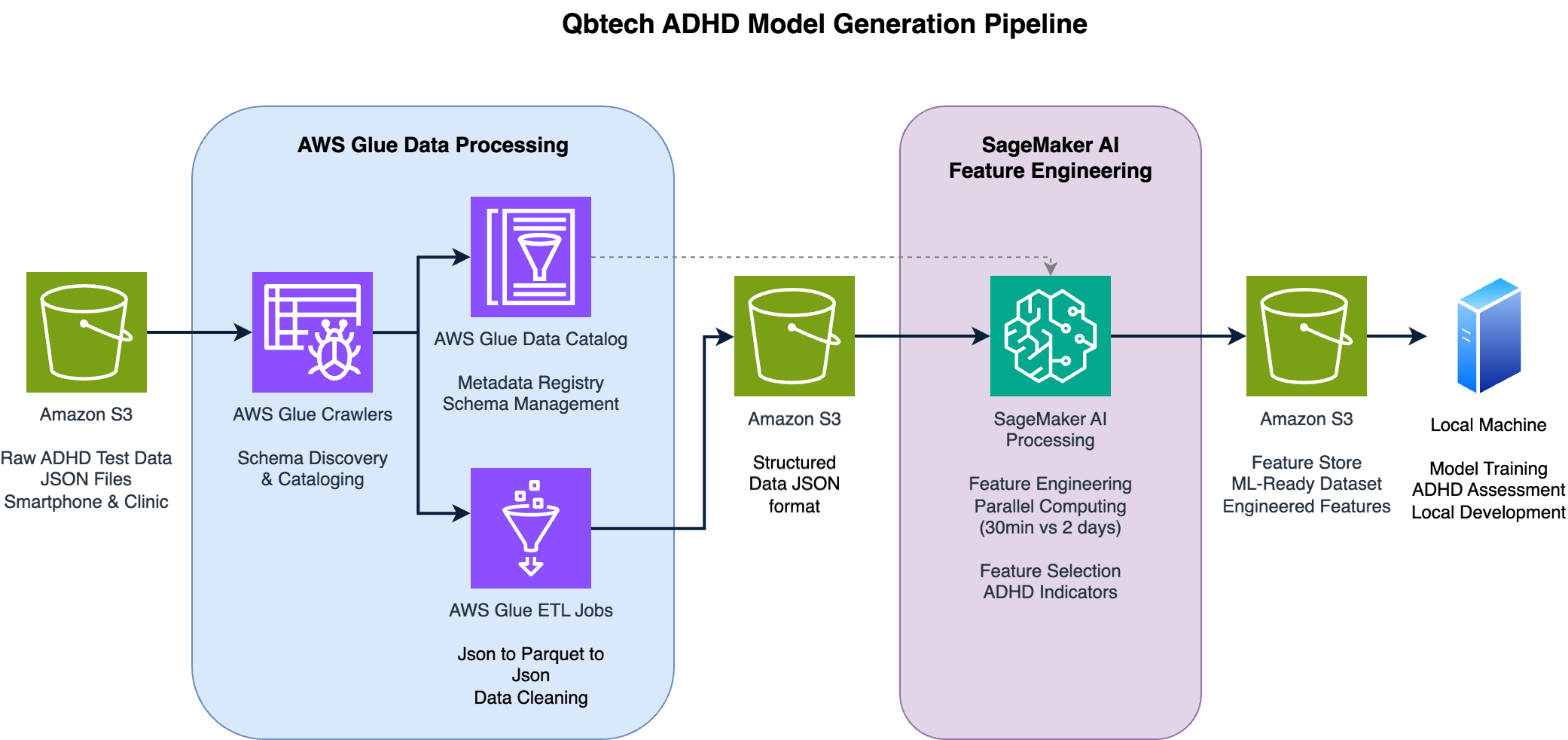
图 1:QbMobile ADHD 评估模型的端到端数据处理和特征工程管道
最终模型使用了 24 个输入特征,这些特征来源于面部追踪、头部运动测量、测试期间的错误模式、用户操作手机的方式以及人口统计信息。为了捕捉 ADHD 在不同患者群体中表现出的注意力、多动性和冲动性的细微模式,这种规模是必要的。该团队使用了三个关键框架:LightGBM 作为主要机器学习算法,Scikit-learn (sklearn) 作为数据处理和模型开发的机器学习工具库,以及 SHAP (SHapley Additive exPlanations) 作为评估特征重要性的方法。选择这些工具是因为它们在处理多模态数据和强大的部署能力方面具有灵活性。该团队使用了大约 2000 个样本,每个样本包含约 50MB 的数据。在这个数据集中,存在类别不平衡,少数类别约占样本的 20%。数据被仔细地分割成训练集和测试集,通过基于诊断和人口统计特征的分层抽样(stratification),确保了跨越交叉群组的平等代表性。还特别考虑了分组问题,因为一些受试者完成了多次测试。该团队实施了五折交叉验证策略,采用了相同的分层和分组方法。这个全面的数据集,源自 Qbtech 十多年来的临床测试经验,为训练出能够在不同人群和设备类型之间泛化的模型奠定了基础。
训练性能和评估
虽然实际的模型训练仅需要大约一分钟的计算时间,但资源消耗最大的部分是将原始样本转换为结构化特征。在这个预处理阶段,SageMaker AI 托管处理作业(managed processing jobs)提供了显著的加速,减少了特征提取的处理时间,并支持在整个开发生命周期中进行高效的迭代。为了确保临床有效性,Qbtech 采用了严格的评估指标,包括敏感性(85.7%)、特异性(74.9%)和 PR-AUC(73.2%)。该团队在每次评估折叠中使用了 Optuna 进行超参数调优的嵌套交叉验证,优化的目标是敏感性和特异性之和,而不是 PR-AUC,以实现更平衡的误差。选择这些指标和优化策略是为了与医疗设备的临床诊断标准和监管要求保持一致。该团队指出,在医疗领域,ADHD 的诊断中没有绝对的“真值”——黄金标准是多位医生对诊断达成一致。Qbtech 解决方案的真正价值在于提供了一致的、客观的数据,从而增强了临床医生诊断决策的信心。
利用 Amazon SageMaker AI 扩展特征工程
Qbtech 开发流程中的一个关键改进是实现了云基础架构上的并行处理能力。通过实施异步处理,使每个测试能够并行而非顺序运行,该团队可以在多个进程中并行执行下载、JSON 解析和特征转换。特征工程管道首先将原始数据转换为每个数据源的时间序列,然后从这些时间序列中生成各种特征。例如,面部位置数据被处理以计算 30 秒窗口内最小、最大和平均移动等统计数据。为了将处理时间从 2 天减少到 30 分钟,Qbtech 在 Amazon SageMaker AI 上使用 Python 的 multiprocessing 功能实施了并行处理方法:
from multiprocessing import Pool, cpu_count def uuids_to_dataset(df_uuid): """Process all files into a dataset""" with Pool(cpu_count()) as p: r = list(p.imap(uuid_to_features, df_uuid["uuid"].to_list())) df = pd.concat(r) df = df.sort_values(by="uuid").reset_index(drop=True) return df此函数创建一个工作池,其大小等于计算实例上可用的中央处理器(CPU)核心数——例如,在具有 32 个核心的 ml.m5.8xlarge 实例上,这意味着可以同时处理 32 个文件。每个工作进程调用 uuid_to_features,该函数负责从 Amazon S3 中检索 JSON 测试文件,解析 50MB 的加速度计和面部跟踪数据,并执行实际的特征计算以提取临床指标。然后使用 pandas 的 concat 函数将所有工作进程的结果合并到一个数据集中。
这种并行处理方法实现了 96% 的计算时间缩短,使团队能够在开发模型时快速迭代,同时保持医疗应用所需的可靠性。Qbtech 报告称,在其开发过程中没有出现硬件故障或中断,使他们能够专注于模型改进而非基础设施管理。
数据管道:从智能手机到临床决策
数据管道始于各种格式的原始智能手机传感器数据。原始的 ADHD 测试数据以 JSON 格式提供,包含加速度计读数、面部跟踪数据和测试结果。AWS Glue 作业负责将这些异构数据初始提取和转换为适合分析的标准化格式。这些转换有助于在不同设备类型和操作系统之间保持数据质量和一致性,这是保持评估准确性的关键要求。Glue 作业将格式从原始文件转换为标准格式,将旧格式转换为新格式,并使文件结构更易于分析(例如,从数组计算平均值)。
特征提取和选择
特征工程过程从原始传感器数据中提取有意义的临床指标。Qbtech 从原始数据中提取了大约 200 个特征,其中只有 24 个进入了最终模型。从原始特征到模型输入的减少是通过一个系统的手动选择过程实现的,该过程分析了每个标签的直方图,以检查类别之间的分离情况。该团队实施了一种迭代方法,逐步添加最有希望的特征,同时监测交叉验证性能的改进。SHAP 分析被用来验证特征是否以临床上有意义的方式与诊断相互作用——例如,确认运动特征的更高值与 ADHD 可能性增加相关。该团队还消除了高相关性的特征,作为确保所选特征独立贡献于诊断的另一种技术。这种有条不紊的特征选择过程反映了编码到模型开发中的领域知识。一个关键的挑战是将长时序数据简化为表格特征,同时仍然捕捉到基本信号。该团队开发了从面部跟踪和运动传感器数据中提取临床相关模式的技术,重点关注与 ADHD 症状相关的指标。
端到端延迟
对于临床工具而言,结果必须快速可用。Qbtech 的管道在数据收集到模型推理之间,在不到一分钟的时间内交付结果。这种快速的周转时间支持实时临床决策,并改善了患者体验。
量化影响:开发效率提升
主要改进在于特征工程的“交付时间”,通过并行处理,从两天缩短到仅 30 分钟。这种 96% 的墙上时间(wall time)缩短,使团队能够更高效地完成 20 次开发迭代,显著加速了模型开发周期。
临床影响:比较临床性能
QbMobile 与 Qbtech 现有产品的临床验证显示出令人鼓舞的结果。性能指标表明,基于智能手机的评估保持了 Qbtech 现有解决方案的高临床标准。转向移动评估改变了护理提供模式。对于仅提供远程服务的提供商,QbMobile 实现了 100% 的远程诊断流程。它使那些因后勤挑战而无法进行临床评估的患者能够接受适当的评估。这种转变减少了诊断障碍,并实现了对治疗效果更频繁的监测。
部署和持续改进
生产部署利用 AWS 服务来实现可靠性和规模化。Qbtech 将训练好的模型与 Python 代码一起打包到 Docker 镜像中。然后,通过触发 GitHub Action 的 GitHub 发布,将 Docker 镜像部署到 AWS ECR。最后,Terraform 连同其后端基础设施的其余部分一起部署 SageMaker AI 端点。为了在不同设备上保持一致的性能,Qbtech 在开发过程中会进行定期的验证检查,检查设备型号是否以任何意外方式影响评估性能。
医疗合规所需的安全性和监控
Qbtech 在 AWS 上的部署包含了医疗保健应用所需全面的安全和监控措施。所有数据在静态时都经过加密,系统通过保持数据匿名来维护患者隐私——存储在 Qbtech 的数据无法识别出任何个人。系统强制执行多重身份验证,并持续监控服务可用性、性能指标和潜在的安全威胁。所有系统访问都经过记录和监控,并自动标记可疑活动。这种方法有助于满足医疗保健安全要求,同时保持临床工作流程所需的可靠性。
展望未来:为全球影响扩大规模
Qbtech 的基础设施策略预期 QbMobile 将在全球范围内被更广泛地采用。该团队计划利用 SageMaker AI 的弹性扩展功能,以应对随着使用量增加而出现的任何性能瓶颈。在模型增强方面,Qbtech 正在实施年度更新周期,这超越了简单的再训练。随着数据集的扩展,他们将整合捕捉额外行为模式的新特征,持续提高诊断准确性和稳健性。
未来研究方向
在当前工作的基础上,Qbtech 正在探索额外的数据流和传感器输入,以进一步提高评估准确性和扩大诊断能力。他们还与监管机构就如何实施模型性能的持续改进计划进行对话,这可能包括使用神经网络等不同模型。来自超过 100 万次完成测试的见解,为特征校准和阈值定义提供了独特的 [Foundation]。这种数据驱动的方法使得移动评估能够受益于公司丰富的临床经验。
在 ADHD 之外,该平台在更广泛的应用中显示出潜力。Qbtech 认为,QbMobile 使研究人员能够获取他们以前没有或难以获取的数据类型。通过研究合作,他们旨在探索 QbMobile、机器学习和附加功能在影响 ADHD 以及未来可能影响其他疾病方面的全部潜力。
结论
Qbtech 在 AWS 上实施 QbMobile,展示了在实现可访问、客观的 ADHD 评估方面取得的实质性进展。通过利用 Amazon SageMaker AI 的并行处理能力和 AWS Glue 的数据转换能力,他们将特征工程时间减少了 96%,同时构建了一个可在全球智能手机上运行的、经过临床验证的 AI 模型。
其影响超越了技术指标:患者现在可以从他们的设备上获取临床级别的 ADHD 评估,从而减少等待时间并改善了医疗服务的可及性。对于医疗服务提供者而言,标准化、客观的数据使得诊断更加自信,并且能够更好地监测治疗效果。
随着全球心理健康挑战的持续增长,Qbtech 利用基于云的 AI 的方法展示了现代基础设施如何在规模上扩大对专业医疗服务的可及性。他们的方法为希望利用 AI 和云计算来改善患者成果的其他医疗保健组织提供了见解。
要了解更多关于在 AWS 上构建医疗保健 AI 解决方案的信息,请查阅 Amazon SageMaker AI 和 AWS Glue 文档,或联系 AWS 医疗保健专家讨论您的具体用例。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区