



📢 转载信息
原文作者:Kimo El Mehri and Johana Hernandez Herrera
各行各业的企业都面临一个共同的挑战:如何高效地从海量非结构化数据中提取有价值的信息。传统方法通常涉及资源密集型流程和僵化的模型。本文将介绍一种颠覆性的解决方案:Amazon Bedrock中的Claude工具使用功能,它利用大型语言模型(LLMs)的强大能力,无需进行广泛的设置或训练,即可实现动态、自适应的实体识别。
在本文中,我们将探讨:
- 什么是Claude工具使用(函数调用)及其工作原理
- 如何使用Claude工具使用通过自然语言提示提取结构化数据
- 使用Amazon Bedrock、AWS Lambda和Amazon Simple Storage Service (S3)设置无服务器管道
- 实现多种文档类型的动态实体提取
- 遵循AWS最佳实践部署生产级解决方案
什么是Claude工具使用(函数调用)?
Claude工具使用,也称为函数调用,是一项强大的功能,允许我们通过建立和调用外部函数或工具来增强Claude的能力。该功能使我们能够为Claude提供一组预先建立的工具,供其按需访问和使用,从而扩展其功能。
Claude工具使用如何在Amazon Bedrock中工作
Amazon Bedrock是一项全托管的生成式人工智能(AI)服务,提供行业领先者(如Anthropic)提供的多种高性能基础模型(FMs)。Amazon Bedrock使得实现Claude的工具使用变得非常简单:
- 用户定义一组工具,包括它们的名称、输入模式和描述。
- 提供一个可能需要使用一个或多个工具的用户提示。
- Claude评估提示,并确定是否有任何工具可以帮助解决用户的问题或任务。
- 如果适用,Claude会选择要使用哪些工具以及使用什么输入。
解决方案概述
在本文中,我们将演示如何使用Amazon Bedrock中的Claude工具使用功能从驾驶执照中提取自定义字段。此无服务器解决方案可实时处理文档,提取姓名、日期和地址等信息,而无需进行传统的模型训练。
架构
我们的自定义实体识别解决方案采用无服务器架构,利用Amazon Bedrock的Claude模型高效处理文档并提取相关信息。这种方法最大限度地减少了对复杂基础设施管理的需求,同时提供了可扩展的、按需的 처리能力。
该解决方案架构使用了多个AWS服务来创建一个无缝的管道。处理流程如下:
- 用户将文档上传到Amazon S3进行处理
- S3 PUT事件通知触发一个AWS Lambda函数
- Lambda处理文档并将其发送到Amazon Bedrock
- Amazon Bedrock调用Anthropic Claude进行实体提取
- 结果记录在Amazon CloudWatch中以供监控
下图展示了这些服务如何协同工作:
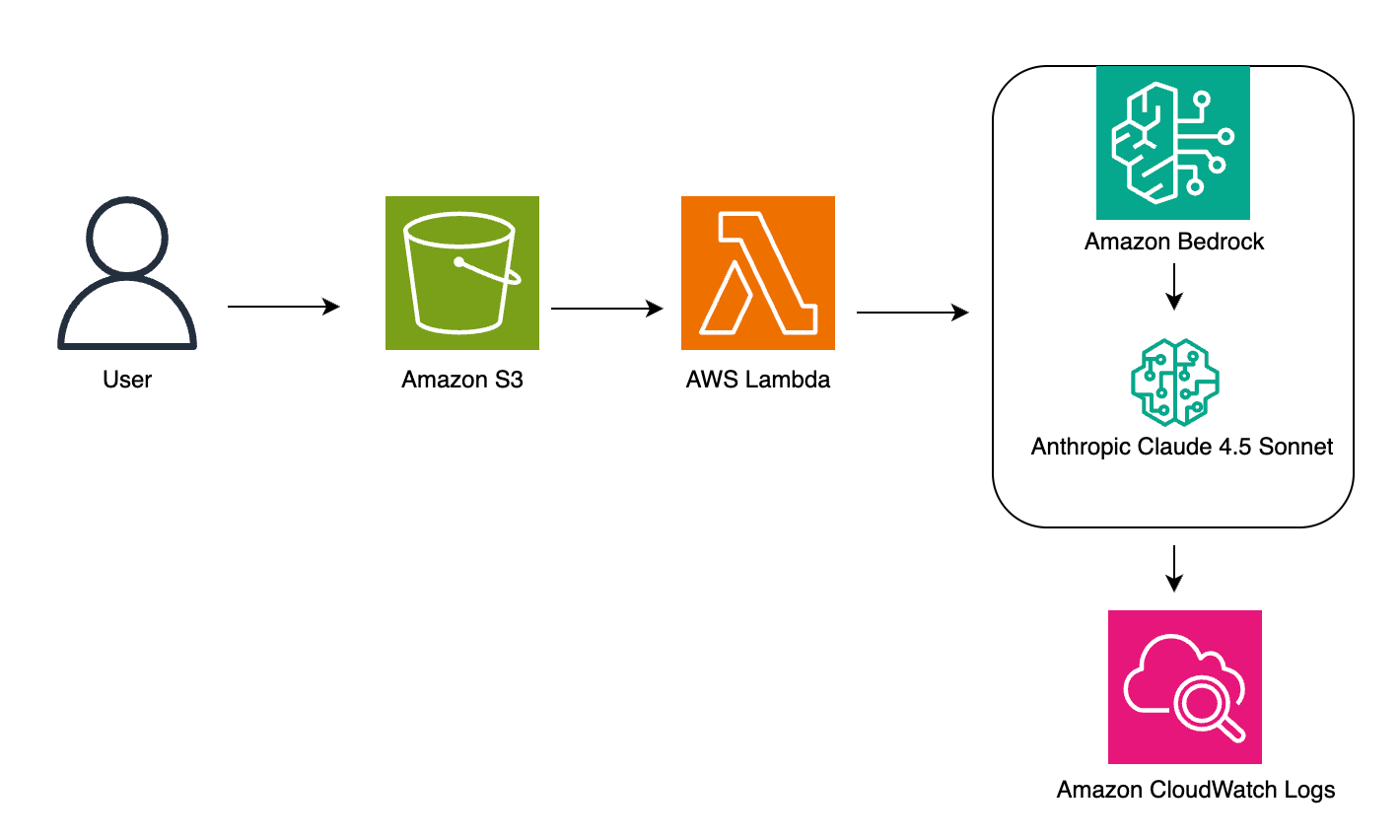
架构组件
- Amazon S3: 存储输入文档
- AWS Lambda: 在文件上传时触发,将提示和数据发送给Claude,存储结果
- Amazon Bedrock (Claude): 处理输入并提取实体
- Amazon CloudWatch: 监控和记录工作流程性能
先决条件
- 拥有Amazon Bedrock访问权限的AWS账户
- 访问Amazon Bedrock、AWS Lambda和Amazon S3的Identity and Access Management (IAM)权限
- 对Python和JSON的基本了解
- 能够访问Amazon Bedrock中的Claude模型
- 设置Claude模型的跨区域推理配置文件
分步实现指南:
本实施指南演示了如何使用Amazon Bedrock及相关AWS服务构建一个无服务器文档处理解决方案。通过遵循这些步骤,您可以创建一个系统,自动从驾驶执照等文档中提取信息,避免手动数据输入并缩短处理时间。无论您是处理少量文档还是成千上万个文档,该解决方案都可以自动扩展以满足您的需求,同时保持数据提取的一致准确性。
- 设置您的环境(10分钟)
- 创建源S3存储桶用于输入(例如,driver-license-input)。
- 配置IAM角色和权限:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "bedrock:InvokeModel",
"Resource": "arn:aws:bedrock:*::foundation-model/*", "arn:aws:bedrock:*:111122223333:inference-profile/*"
},
{
"Effect": "Allow",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::amzn-s3-demo-bucket/*"
}
]
}- 创建Lambda函数(30分钟)
此Lambda函数在新图像上传到S3存储桶时自动触发。它读取图像,将其编码为base64,并通过Amazon Bedrock使用工具使用API将其发送到Claude 4.5 Sonnet。为了演示目的,该函数定义了一个名为extract_license_fields的工具。但是,您可以根据用例定义工具名称和模式 — 例如,提取保险卡数据、ID卡或业务表单。Claude会根据提示的相关性和输入结构动态选择是否调用您的工具。
我们使用“tool_choice”: “auto”让Claude决定何时调用函数。在生产用例中,您可能希望硬编码“tool_choice”: { “type”: “tool”, “name”: “your_tool_name” }以实现确定性行为。- 转到AWS Lambda控制台
- 选择创建函数。
- 选择从头开始编写。
- 将运行时设置为Python 3.12.
- 选择创建函数。
- 配置Lambda超时
- 在Lambda函数配置中,点击常规配置选项卡。
- 在常规配置下,点击编辑
- 对于超时,将默认的3秒增加到至少30秒。建议为较大的图像设置为1-2分钟。
- 选择保存。
注意: 此调整至关重要,因为通过Claude处理图像可能比Lambda的默认超时时间更长,特别是对于高分辨率图像或处理多个字段时。请在CloudWatch日志中监控函数的执行时间,以针对您的特定用例调整此设置。
- 将此代码粘贴到lambda_function.py代码文件中:
import boto3, json import base64 def lambda_handler(event, context): bedrock = boto3.client("bedrock-runtime") s3 = boto3.client("s3") bucket = event["Records"][0]["s3"]["bucket"]["name"] key = event["Records"][0]["s3"]["object"]["key"] file = s3.get_object(Bucket=bucket, Key=key) # Convert image to base64 image_data = file["Body"].read() base64_image = base64.b64encode(image_data).decode('utf-8') # Define tool schema tools = [ { "name": "extract_license_fields", "input_schema": { "type": "object", "properties": { "first_name": {"type": "string"}, "last_name": {"type": "string"}, "issue_date": {"type": "string"}, "license_number": {"type": "string"}, "address": { "type": "object", "properties": { "street": {"type": "string"}, "city": {"type": "string"}, "state": {"type": "string"}, "zip": {"type": "string"} } } }, "required": ["first_name", "last_name", "issue_date", "license_number", "address"] } } ] payload = { "anthropic_version": "bedrock-2023-05-31", "max_tokens": 2048, "messages": [ { "role": "user", "content": [ { "type": "image", "source": { "type": "base64", "media_type": "image/jpeg", "data": base64_image } }, { "type": "text", "text": "Extract the driver's license fields from this image." } ] } ], "tools": tools } try: response = bedrock.invoke_model( modelId="global.anthropic.claude-sonnet-4-5-20250929-v1:0", body=json.dumps(payload) ) result = json.loads(response["body"].read()) # Print every step for debugging print("1. Raw Response:", json.dumps(result, indent=2)) if "content" in result: print("2. Content found in response") for content in result["content"]: print("3. Content item:", json.dumps(content, indent=2)) if isinstance(content, dict): print("4. Content type:", content.get("type")) if content.get("type") == "text": print("5. Text content:", content.get("text")) if content.get("type") == "tool_calls": print("6. Tool calls found") extracted = json.loads(content["tool_calls"][0]["function"]["arguments"]) print("7. Extracted data:", json.dumps(extracted, indent=2)) return { "statusCode": 200, "body": json.dumps({ "message": "Process completed", "raw_response": result }, indent=2) } except Exception as e: print(f"Error occurred: {str(e)}") return { "statusCode": 500, "body": json.dumps({ "error": str(e), "type": str(type(e)) }) } - 部署Lambda函数: 粘贴代码后,选择代码编辑器左侧的部署按钮,等待部署确认消息。
重要: 更改代码后,请务必部署。这可确保保存了您最新的代码,并在触发Lambda函数时执行。
- 转到AWS Lambda控制台
- 使用Claude工具使用模式
- Amazon Bedrock结合Claude 4.5 Sonnet,支持使用工具使用进行函数调用,您可以在其中使用清晰的JSON模式定义可调用的工具。有效的工具条目必须包括:
- name: 工具的标识符(例如,
extract_license_fields) - input_schema: 定义必需字段、类型和结构的JSON模式
- name: 工具的标识符(例如,
- 示例工具使用定义:
[ { "name": "extract_license_fields", "input_schema": { "type": "object", "properties": { "first_name": {"type": "string"}, "last_name": {"type": "string"}, "issue_date": {"type": "string"}, "license_number": {"type": "string"}, "address": { "type": "object", "properties": { "street": {"type": "string"}, "city": {"type": "string"}, "state": {"type": "string"}, "zip": {"type": "string"} } } }, "required": ["first_name", "last_name", "issue_date", "license_number", "address"] } } ] - 您可以在tools数组中定义多个工具。Claude根据tool_choice值以及提示与给定模式的匹配程度来选择一个(或不选择)。
- 使用“tool_choice”: “auto”让Claude决定。
- 使用显式工具名称强制调用。
"tool_choice": { "type": "tool", "name": "extract_license_fields" }注意: tool_choice字段是可选的。如果省略,Claude默认为“auto”。
- Amazon Bedrock结合Claude 4.5 Sonnet,支持使用工具使用进行函数调用,您可以在其中使用清晰的JSON模式定义可调用的工具。有效的工具条目必须包括:
- 配置S3事件通知(5分钟)
- 打开Amazon S3控制台。
- 选择您的S3存储桶。
- 点击属性选项卡。
- 向下滚动到事件通知。
- 点击创建事件通知。
- 为通知输入一个名称(例如,“LambdaTrigger”)。
- 在事件类型下,选择PUT。
- 在目标下,选择Lambda函数。
- 从下拉列表中选择您的Lambda函数。
- 点击保存更改。
- 打开Amazon S3控制台。
- 测试和验证(15分钟)
- 支持的格式:Claude 4.5支持JPEG、PNG、WebP和单帧GIF格式的图像输入。注意: 虽然此实现目前仅支持.jpeg图像,但您可以修改Lambda函数中的media_type字段以匹配上传文件的MIME类型,从而扩展对其他格式的支持。
- 大小和分辨率限制:
- 最大图像尺寸:20 MB
- 推荐分辨率:300 DPI或更高
- 最大尺寸:4096 x 4096像素
- 大于此尺寸的图像可能会处理失败或产生不准确的结果。
- 提高准确性的预处理技巧:
- 将图像裁剪到紧凑,去除噪点和无关区域。
- 调整对比度和亮度,确保文本清晰可读。
- 校正扫描件的倾斜,确保文本水平对齐。
- 避免低分辨率截图或有大量压缩伪影的图像。
- 首选白色背景和黑色文本,以获得最大的OCR清晰度。
- 上传测试图像:

- 打开您的S3存储桶
- 上传驾驶执照图像(支持的格式:.jpeg, .jpg)。
- 注意:为获得最佳效果,请确保图像清晰可读。
- 监控CloudWatch日志
- 转到Amazon CloudWatch控制台。
- 在左侧导航栏中点击日志组。
- 搜索您的Lambda函数名称
invoke_drivers_license。 - 点击最新的日志流(按时间戳排序)。
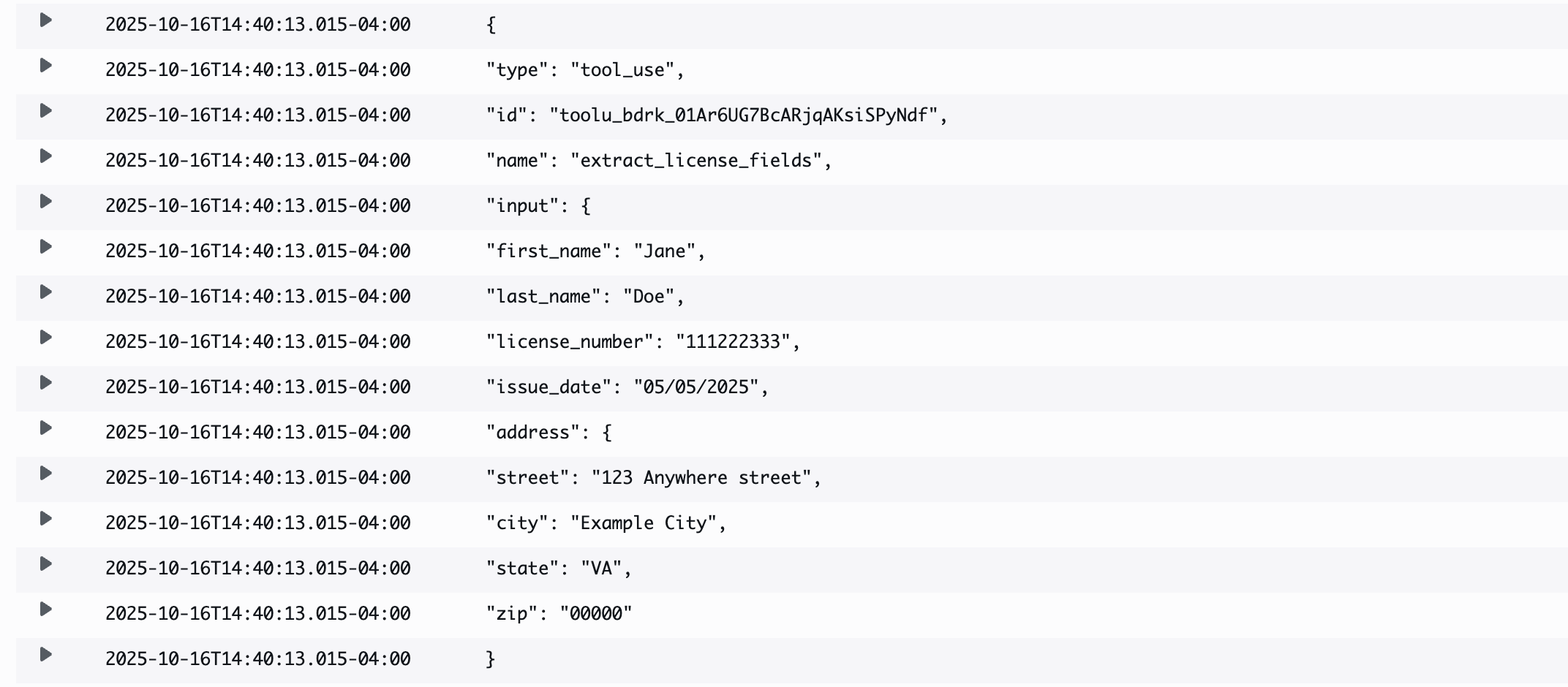
- 查看执行结果,其中显示了此示例输出:
{
"type": "tool_use",
"id": "toolu_bdrk_01Ar6UG7BcARjqAKsiSPyNdf",
"name": "extract_license_fields",
"input": {
"first_name": "JANE",
"last_name": "DOE",
"issue_date": "05/05/2025",
"license_number": "111222333",
"address": {
"street": "123 ANYWHERE STREET",
"city": "EXAMPLE CITY",
"state": "VA",
"zip": "00000"
}
}
}
性能优化
- 配置Lambda内存和超时设置
- 为多个文档实现批量处理
- 使用S3事件通知进行自动处理
- 添加CloudWatch指标进行监控
安全最佳实践
- 为S3存储桶实现静态加密
- 使用AWS Key Management Service (KMS)密钥保护敏感数据
- 应用最小权限IAM策略
- 启用虚拟私有云(VPC)端点以实现私有网络访问
错误处理和监控
- Claude的输出结构化为内容块列表,可能包括文本响应、tool_calls或其他数据类型。调试方法:
- 始终记录Claude的原始响应。
- 检查响应中是否存在
tool_calls。 - 在函数调用周围使用try-except块来捕获错误,如格式错误的有效负载或模型超时。
- 这是一个最小化的错误处理模式:
try:
result = json.loads(response["body"].read())
if "tool_calls" in result.get("content", [{}])[0]:
args = result["content"][0]["tool_calls"][0]["function"]["arguments"]
print("Extracted Fields:", json.dumps(json.loads(args), indent=2))
except Exception as e:
print("Error occurred:", str(e))
清理
- 删除S3存储桶及其内容。
- 移除Lambda函数。
- 删除IAM角色和策略。
- 在不再需要时禁用Bedrock访问。
结论
Amazon Bedrock中的Claude工具使用功能为自定义实体提取提供了一个强大的解决方案,最大限度地减少了对复杂机器学习(ML)模型的需求。这种无服务器架构能够以最小的设置和维护成本,对文档进行可扩展、经济高效的处理。通过利用Amazon Bedrock提供的大型语言模型的力量,组织可以在处理非结构化数据方面实现更高的效率、洞察力和创新水平。
后续步骤
我们鼓励您通过在您的环境中实现示例代码并针对您的具体用例进行定制,来进一步探索此解决方案。欢迎加入AWS re:Post社区关于实体提取解决方案的讨论,您可以在那里分享您的经验并向其他开发人员学习。
为了获得更深入的技术见解,请查阅我们关于Amazon Bedrock、AWS Lambda和Amazon S3的综合文档。考虑通过与Amazon Textract集成以获得额外的文档处理功能,或与Amazon Comprehend集成以进行高级文本分析,从而增强您的实施。要随时了解类似解决方案的最新信息,请订阅我们的AWS机器学习博客,并在AWS Samples GitHub仓库中探索更多示例。如果您是AWS机器学习服务的新用户,请查看我们的AWS机器学习大学或探索我们的AWS解决方案库。有关企业解决方案和支持,请联系您的AWS客户团队。
关于作者
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区