



📢 转载信息
原文作者:Damodar Shetyo, Aravindan Veeramani, Matt Padilla, Shobhit Swaroop, Utkarsh Srivastava, and Vinodh Venkatesan
在亚马逊,我们对全球业务及其子公司进行客户和交易筛选,以遵守制裁和其他全球法律法规。未能遵守这些法律可能导致严重的经济处罚和声誉损害。亚马逊合规团队开发了一个由AI驱动的筛选和调查系统,它已将亚马逊的合规流程转变为行业领先的解决方案:亚马逊合规筛选(Amazon Compliance Screening)。该系统每日在全球160多家业务中筛选约20亿笔交易,以防止被禁交易的发生。我们执行来自多个司法管辖区的制裁名单,包括但不限于美国外国资产控制办公室(OFAC)的特别指定国民和被封锁人员名单(SDN名单)以及英国财政部的名单(HMT名单)。制裁执行力度持续加强,仅美国监管机构自2023年以来就已处以20亿美元的罚款。以如此规模管理合规性需要数千名人工专家根据行业标准/最佳实践来审查标记的交易和进行调查。然而,这种高强度依赖人工的方法造成了严重的瓶颈——人工审查周期可能需要数天,直接通过延迟交易、账户冻结和订单履行中断影响客户体验。面对不断增长的规模,亚马逊必须在遵守复杂且不断变化的监管要求的同时,保持高准确性、降低合规成本并加速复杂的调查工作。
解决方案概述:三层智能合规系统
亚马逊合规筛选系统采用了一种复杂的三层方法,平衡了速度、准确性和彻底性:
第1层 – 筛选引擎:作为基础,它使用先进的模糊匹配算法和使用Amazon SageMaker开发和部署的自定义向量嵌入模型,将每条输入的实体数据与制裁名单和其他政府名单上的实体进行比较。该层针对高召回率进行了优化,即使以牺牲误报率为代价,也能捕获所有潜在匹配项。
第2层 – 智能自动化引擎:采用传统的机器学习模型来过滤掉低质量的匹配项,显著减少噪音。此层通过分析匹配质量信号来减少误报,使合规团队能够专注于真正的风险。
第3层 – AI驱动的调查系统:使用部署在Amazon Bedrock AgentCore Runtime上的专业AI智能体,对剩余的高质量匹配项进行全面评估。从高层次来看,这些智能体系统地收集相关信息,遵循亚马逊合规团队制定的调查标准操作程序(SOP)进行整体分析,并生成带有建议的详细案例摘要。只有在智能体因证据不足或情况超出标准调查参数而无法得出结论的罕见情况下,才需要人工介入。
本博文将重点介绍第3层,探讨亚马逊合规团队如何通过基于AWS构建的一系列AI智能体来构建其AI驱动的调查系统。
系统架构
当潜在匹配项通过第1层和第2层筛选后,就会创建一个案例并路由到我们的AI驱动调查系统。智能体随后收集和分析信息,并生成带有风险评估和最终决定的综合调查摘要。我们的调查员AI智能体基于Strands智能体框架构建,由托管在Amazon Bedrock上的大型语言模型提供支持,并部署在Amazon Bedrock AgentCore Runtime上。该系统采用多个AI智能体协同工作,每个智能体都使用专门的工具来与外部系统交互、访问数据并执行其指定的职能。
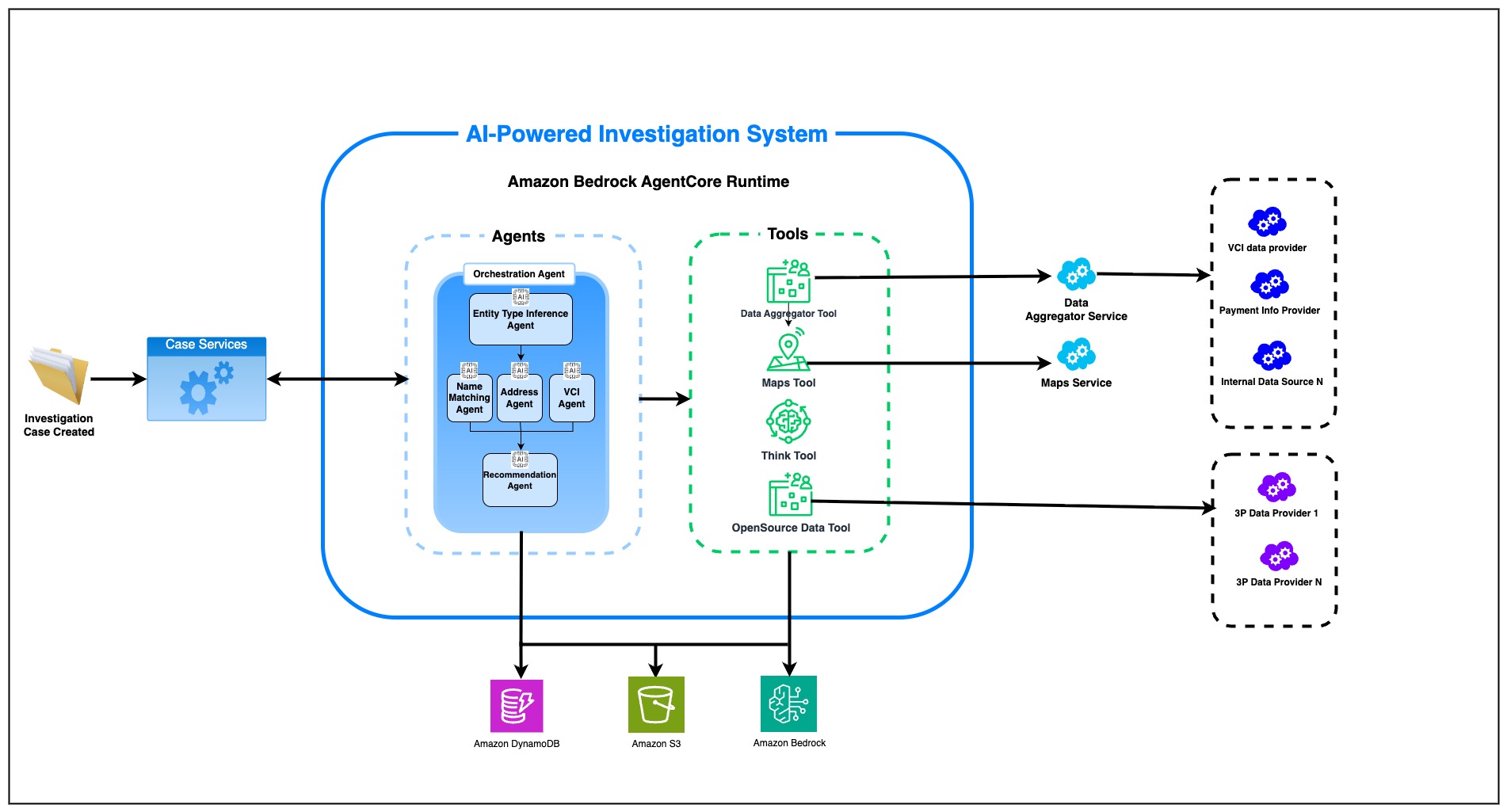
智能体架构
我们的系统由多个AI智能体组成,每个智能体都旨在处理调查过程的特定方面。
- 名称匹配智能体 (Name matching agent):分析跨多种语言和脚本的名称变体、音译和文化命名惯例。该智能体识别到“Abel Hernandez, Jr.”和“Hernandez Abel”可能指同一个人,并处理涉及昵称、娘家姓和别名的复杂场景。它处理非拉丁脚本,包括阿拉伯文、中文、日文和西里尔文,同时理解文化命名惯例,例如不同文化中名字和姓氏的顺序。例如,在调查“李明”和“Ming Li”之间的匹配时,该智能体能识别出音译变化和中西方格式中不同的名字顺序。
- 地址匹配智能体 (Address matching agent):专注于地理数据,理解地址的变体、缩写和国际格式差异。它能识别出“123 Main St., New York, NY”和“123 Main Street, New York City, New York”是否指向同一个地点。该智能体处理国际地址格式和本地缩写,根据地理空间数据验证地址,并检测潜在的地址混淆技术。例如,该智能体可以确定“Flat No. 502, Sai Kripa Apartments, Plot No. 23, Linking Road, Bandra West, Mumbai – 400050, Maharashtra, India”和“Sai Kripa Apts., 5th Floor, Flat 502, 23 Linking Rd., Bandra (W), Mumbai, MH 400050”指的是同一个地址,尽管格式有所不同。
- 实体类型推断智能体 (Entity type inference agent):通过首先使用数据聚合工具检查亚马逊内部系统的数据来确定输入实体的类型(个人或组织)。当在亚马逊内部系统中找不到证据时,它会使用多种语言中的命名模式和公司指示符(LLC、Inc.、Ministry)来确定该条目的适当实体类型(例如,个人或组织)。
- 经验证客户信息(VCI)智能体 (Verified customer information (VCI) agent):审查客户(或其他当事方)提供的识别文件、商业注册和账户验证记录等信息。
- 推荐智能体 (Recommendation agent):综合所有AI智能体的发现结果,应用加权风险分析,并根据收集到的证据生成最终建议及详细理由。它从所有调查智能体那里汇总证据,根据多个因素应用风险评分,并为建议生成详细的理由。该智能体以置信度水平将案例分类为误报或真阳性,生成包含所有收集到的证据、每个智能体的分析、风险评估以及带有支持性理由的明确建议的综合案例摘要。
- 编排智能体 (Orchestration agent):协调所有智能体之间的工作流程。它位于这些智能体之上,管理智能体之间的依赖关系,根据案例复杂性优化调查顺序,在适当的情况下处理并行执行,并在处理异常情况时监控智能体进度。编排智能体是使用Strands图多智能体模式(Graph Multi-Agent Pattern)实现的,该模式允许基于图结构进行确定性的执行顺序。
工具
工具是扩展智能体能力的主要机制,使智能体能够与外部系统交互、访问数据和操作其环境。我们的智能体利用各种工具——有些内置于Strands中(例如ThinkTool),有些则是根据特定需求开发的。亚马逊合规筛选系统使用以下定制工具:
- 数据聚合器工具 (Data aggregator tool):数据聚合器工具充当数据聚合器,是我们AI智能体与亚马逊广泛数据生态系统之间的关键桥梁。该数据聚合器微服务从多个内部来源检索和整合信息,包括了解您的客户(KYC)系统、交易历史系统、账户验证记录、当事方信息和历史合规数据。
- 地图工具 (Maps tool):地图工具提供地理空间智能和地址验证功能。它执行地址验证和标准化、地理编码和反向地理编码、管辖区分析以及位置之间的距离计算。该工具集成了多个地理API,以帮助智能体验证基于位置的信息、检测地址差异。此功能对于地址匹配智能体验证基于位置的信息、检测可疑地址模式和理解实体之间的地理关系至关重要。
- 开源数据工具 (Open source data tool):开源数据工具从多个第三方数据提供商处聚合公开可用信息,从而在调查期间进行全面的开源情报收集。该工具连接到各种专业数据源,包括公司注册数据库。
合规优先设计
所有智能体都遵循亚马逊合规团队制定的严格指导方针和调查标准操作程序(SOP)。我们遵循这些准则,以确保AI推理符合监管要求和公司政策。每项决策和推理步骤都会被记录和可追溯,使我们能够审计完整的调查路径并确切了解AI如何得出其结论。我们实施了严格的检查,以验证智能体严格遵守其指定的SOP,无论案例数量或复杂性如何,都在所有调查中保持一致性。例如,推荐智能体在收到所有AI智能体(名称匹配、地址匹配、实体类型推断智能体和VCI智能体)的结果之前无法执行;当智能体置信度分数低于我们定义的阈值时,案例会自动升级给人工调查员,并附带一个“人在回路中”(human-in-the-loop)的任务。
为什么选择Strands和Amazon Bedrock AgentCore Runtime?
我们的AI智能体是使用Strands构建并在Amazon Bedrock AgentCore Runtime上部署的。Strands和AgentCore Runtime提供了智能体式开发、会话管理、安全隔离和基础设施管理的强大组合,使我们的构建者能够专注于解决核心问题和多智能体编排,同时抽象化复杂的实施细节。Strands通过标准化的模型通信协议(MCP)和智能体间(A2A)结构,与AWS服务和外部工具无缝集成,并且我们可以随时使用整个Bedrock模型库。
AgentCore Runtime的无服务器架构对我们不可预测的工作负载至关重要——当制裁名单每日更新时,案例量会急剧增加。AgentCore Runtime在高峰期自动扩展,在正常运行时缩减规模,无需人工干预即可实现高效的计算资源使用。
结果与性能
我们AI驱动的智能体式调查系统通过显著的改进改变了调查流程。AI智能体同时分析数百个数据点,遵循复杂的程序。它们实现了96%的总体准确性,历史决策的96%精确率和100%召回率,超过了人工水平,并自动化了超过60%的业务量决策。
可采纳的经验教训
基于我们构建亚马逊合规筛选系统的经验,我们建议如下:
从明确的SOP开始:我们AI智能体的成功在很大程度上取决于拥有明确定义的调查标准操作程序。我们在实施AI智能体之前,投入了大量时间与合规团队合作,记录和正式化调查程序。这种前期投入至关重要,因为智能体的效率仅取决于它们遵循的程序。
迭代式智能体开发:我们没有同时部署所有智能体。我们从名称匹配智能体开始,验证其性能,然后逐步增加复杂性并添加其他智能体。这种迭代方法使我们能够在早期识别和解决问题,与利益相关者建立信心,并在扩展更复杂的多个智能体场景之前吸取有关智能体设计的宝贵经验。
平衡自主性与控制:找到自主性和控制之间的正确平衡至关重要。过度的自主性会导致不可预测的行为——在早期迭代中,智能体会跳过地址验证,理由是名称相似度较低,认为没有必要。过度的控制则会限制有效性。我们根据职能和风险采用不同的方法。对于编排智能体,我们实施了Strands图多智能体模式来强制执行确定性的执行顺序(实体类型推断先于名称匹配),保证了对SOP合规性和审计跟踪的调查。对于像名称匹配智能体这样的AI智能体,模型驱动的方法提供了推理自主权,以处理复杂的场景——阿拉伯语到英语的音译、西里尔文变体或中文罗马化——需要通过动态推理语言模式来实现,而这些是刚性规则无法实现的。
工具设计至关重要:工具的质量和可靠性直接影响智能体性能。我们了解到需要设计具有清晰接口、全面错误处理和详细文档的工具,以便智能体能够有效地使用它们。一个设计良好的工具决定了一个智能体是能持续产生有价值的见解,还是在处理基本任务时会遇到困难。
从第一天开始就关注可观测性:从一开始就构建全面的日志记录、监控和调试功能是必不可少的。了解智能体做出特定决策的原因对于合规性和持续改进至关重要。我们可以追溯每个智能体的操作、每次工具调用和每一步推理,这对于故障排除、审计和优化智能体行为被证明是极其宝贵的。
结论
亚马逊的AI驱动的合规筛选系统通过能够精确分析、推理并解决案例的自主智能体,应对复杂的合规挑战。只有在智能体因证据不足或情况超出标准调查参数而无法得出结论时,才需要人工介入。这种自动化优先的方法在保持准确性和可审计性的同时最大化了效率,将人工调查专门保留给需要细致判断的边缘案例。随着监管环境的发展,我们的智能体方法提供了必要的可扩展性,以在持续扩展自主案例解决能力的同时,维持高合规标准。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区