



📢 转载信息
原文作者:Bharath Suresh, Mary Law 和 Amelia Mantle
本文由 Snowflake 的 Bharath Suresh 和 Mary Law 撰写。
代理式 AI 是一种能够自主运行的 AI 类型,只需最少的监督即可自动化更广泛的任务。它结合了传统 AI 和 生成式 AI 的能力,可以在没有持续人为干预的情况下做出决策、执行任务并适应环境。这些自主系统可以规划、推理并采取行动以实现特定目标。下图摘自《AI 代理实用指南》,展示了这些自主操作的流程。
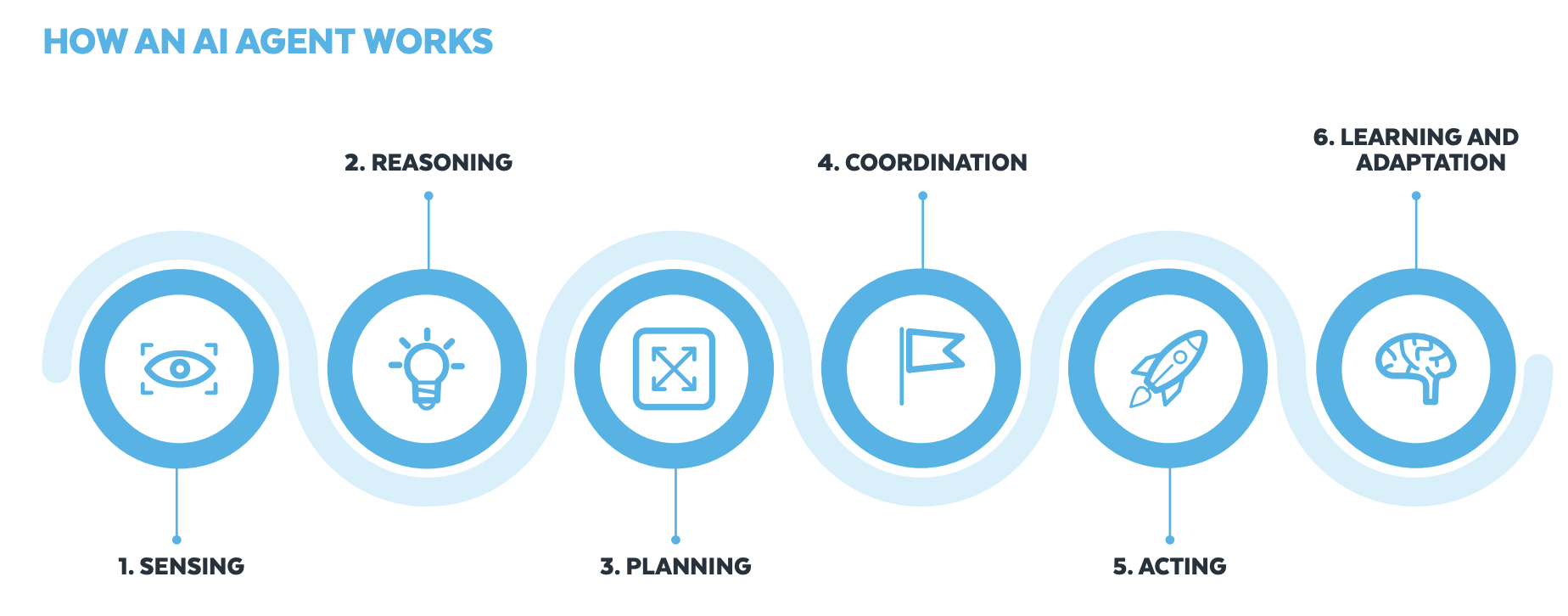
在本文中,我们将介绍如何使用来自 Snowflake AI Data Cloud 和 Amazon Web Services (AWS) 的工具来构建组织可以用来做出数据驱动决策、提高运营效率并最终获得竞争优势的生成式 AI 解决方案。
Snowflake 是一家 AWS Competency Partner,拥有生成式 AI、数据与分析、机器学习和零售独立软件开发商 (ISV) 等多项 AWS 能力。Snowflake 可在 AWS Marketplace 中获取。Snowflake 为各组织构建工具,以调动其数据、统一孤立的数据,并安全地发现和共享数据。Snowflake 将 AI 带入受治理的数据中,使团队能够在非结构化数据上运行分析工作流程、开发代理式应用程序,并使用结构化和非结构化数据进行模型训练,同时将运营开销和端到端治理降至最低。Snowflake 是一个强大的 AWS 合作伙伴,在超过 20 个 AWS 区域中可用,提供广泛的支持和与 AWS 服务的集成。这包括使用 AWS PrivateLink 进行安全连接,使用 Snowpipe 从 Amazon Simple Storage Service (Amazon S3) 自动加载数据,使用 AWS Glue 进行数据编目,以及使用 Amazon SageMaker 进行模型开发。Snowflake 已获得 Amazon SageMaker 就绪产品服务验证。
业务挑战
传统的车辆保险理赔处理涉及多个阶段,从手动验证驾驶执照、理赔表和汽车损坏图像等文件开始。这种手动工作流程通常是孤立的,并且容易出错。在本文中,我们将演示一个自动执行此端到端流程的代理式 AI 工作流程。该示例展示了在提高运营效率和可扩展性、减少人为错误并支持明智决策的同时,可能实现的艺术。示例解决方案涉及以下关键服务:
- Snowflake – AI 数据云。一个统一的平台,可消除数据孤岛,使数据和 AI 变得简单、互联和可信。
- Snowflake Document AI – 一项 AI 功能,使用 Arctic-TILT(一种专有的大型语言模型 (LLM))从文档中提取数据。Document AI 最适合将文档中的非结构化数据转换为表中的结构化数据。请参阅Document AI 可用性。
- Snowflake 中的 Streamlit – 一个开源 Python 库,可无缝创建和共享用于机器学习 (ML) 和数据科学的自定义 Web 应用程序。通过使用 Streamlit,您可以快速构建和部署强大的数据应用程序。有关构建仪表板、数据工具和人工智能和机器学习 (AI/ML) 的其他用例,请参阅Streamlit in Snowflake 演示。
- Amazon Bedrock – 一项完全托管的服务,用于构建生成式 AI 应用程序,提供来自领先 AI 公司的各种高性能基础模型 (FM) 的选择。Amazon Nova Lite 是一种低成本的多模态模型,用于处理图像、视频和文本输入,速度极快。
- LangGraph – 一个有状态的编排框架,为代理工作流程带来额外的控制权。
该解决方案的演示如下视频所示。

解决方案概述
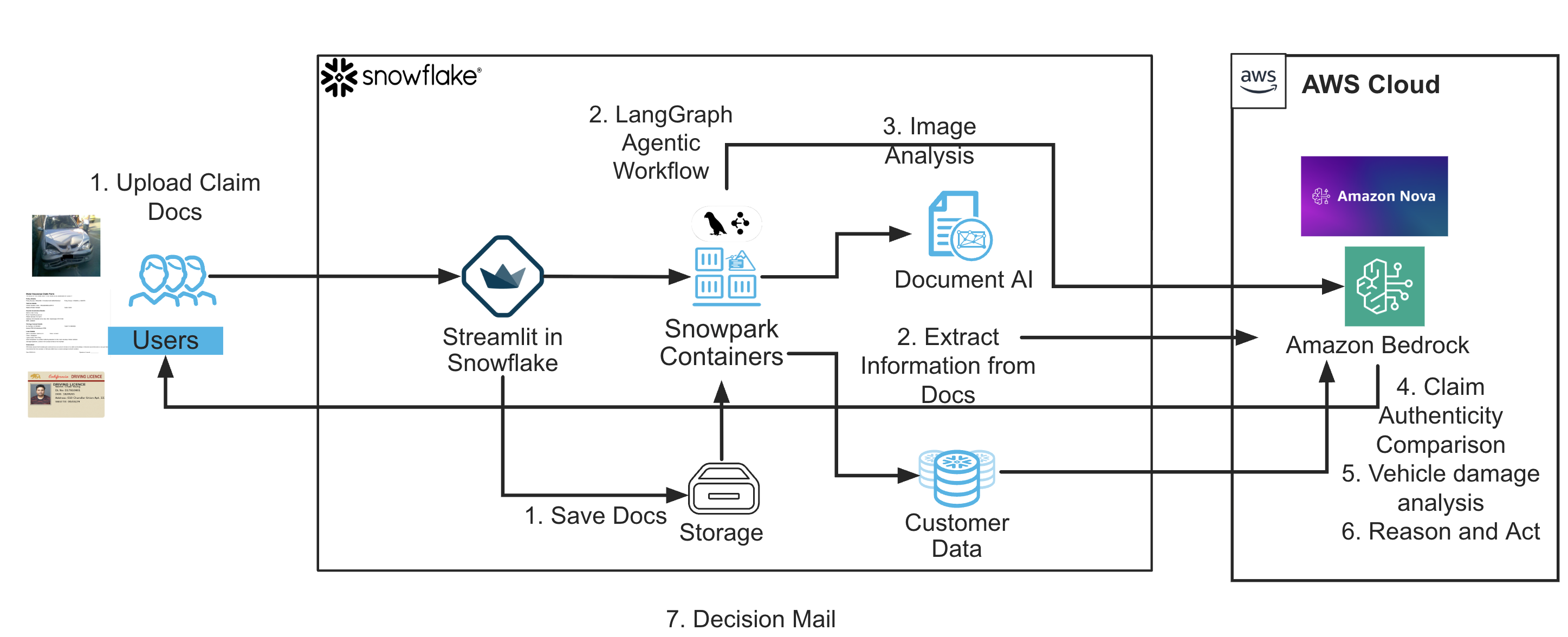
此解决方案使用代理式 AI 架构,为车辆保险理赔处理实施了一个完全自主、可解释的工作流程。其核心是将结构化文档提取、多模态图像分析、保单验证和自然语言生成相结合,通过有状态的 LangGraph 工作流程串联起来,并通过交互式 Streamlit UI 呈现。以下是端到端流程的大致工作原理:
- 用户上传三个基本工件:
- 扫描的驾驶执照 (DL)
- 填写好的理赔表(PDF 或图像)
- 汽车损坏照片
- 上传的执照和理赔文档使用 Snowflake 的 Cortex Document AI 模型(
LICENSE_DATA和CLAIMS_DATA)进行处理。这些模型提取结构化字段,如姓名、驾照号码、车辆详细信息和事故日期,所有这些都通过零样本或微调推理实现。 - 汽车损坏照片由 Amazon Bedrock 中的 Amazon Nova Lite 分析。将图像和文本提示传递给模型,该模型会返回有关可见损坏、汽车类型、品牌和颜色的专业摘要。这为推理过程增加了非结构化的图像洞察。
- 从执照、理赔和图像中提取的值会相互交叉检查以确保一致性(例如,姓名匹配、驾照号码、车辆颜色),并与 Snowflake 保单记录进行验证(例如,客户资料、VIN、保单到期日)。这确认了理赔的真实性和资格。
- 将理赔中的事故日期与从 Snowflake 检索到的保单到期日进行比较。保单窗口外的理赔会自动标记。
- 根据匹配准确性和保单状态做出决定。系统会编译比较摘要,并使用 Amazon Nova Lite 中的自然语言生成功能生成面向客户的决定电子邮件。
- 所有阶段都作为节点链接到 LangGraph 状态机中,每个节点处理共享的工作流程状态并将其向前传递。这种结构提供了模块化、可审计性和确定性控制。
- 最终输出——包括工作流程步骤、决定状态、匹配值和电子邮件——通过 Streamlit UI 实时显示给用户。一个调试展开器会显示每个提取阶段的完整原始 JSON 数据。
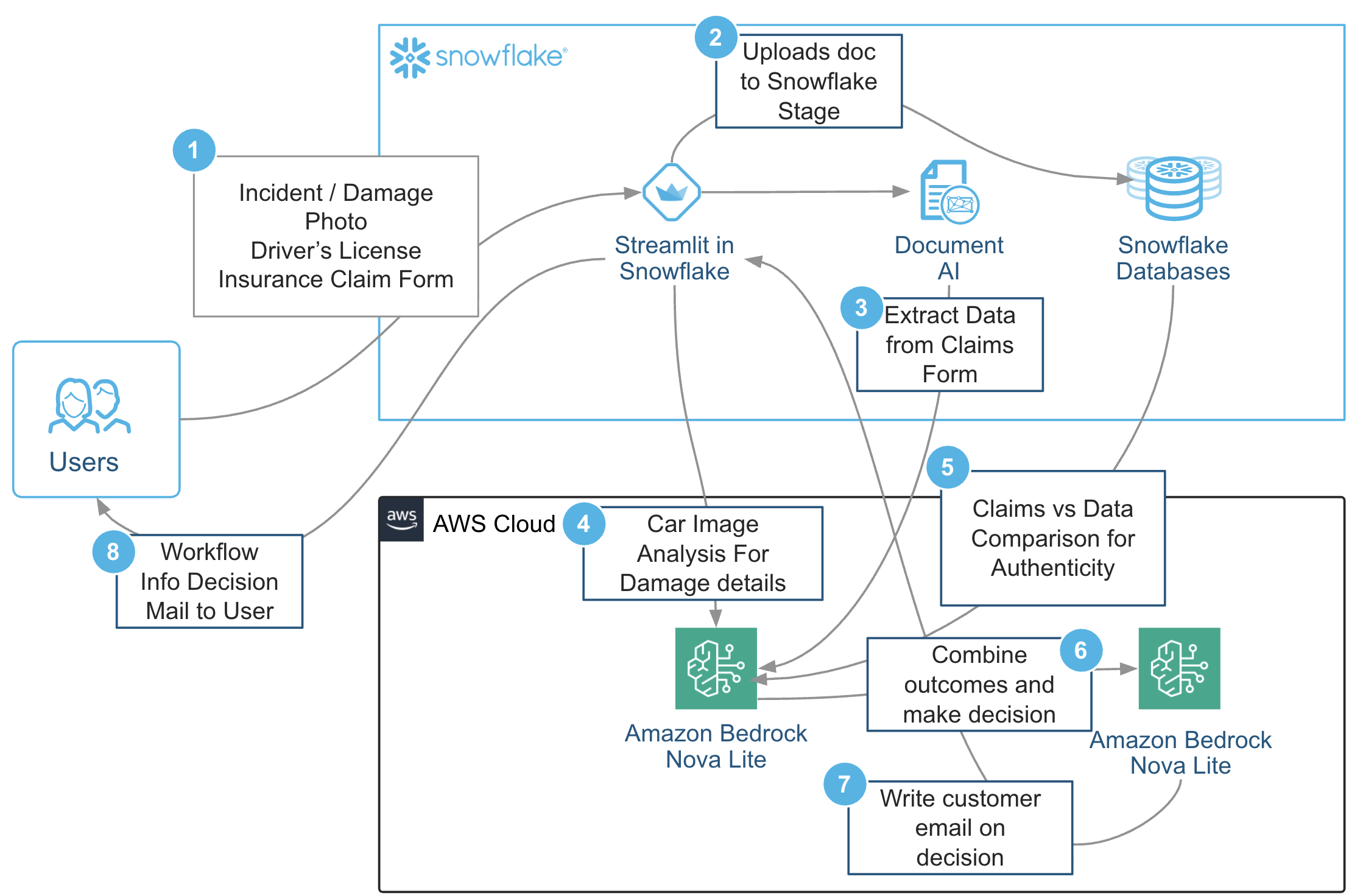
此解决方案展示了如何将多个 AI 组件——文档理解、多模态推理和自定义模型生成——紧密集成到单个管道中,该管道可以自主感知、推理和行动。解决方案工作流程遵循以下步骤:
- 用户将所有文档提交给 Streamlit 应用程序。
- 用户将事故照片、驾驶执照和保险理赔表等文档上传到 Snowflake Stage。
- 使用 Snowflake Document AI 从保险理赔表中提取数据。
- 使用 Amazon Bedrock 中的 Amazon Nova Lite 来比较提取的理赔数据是否真实。
- 使用 Amazon Bedrock 中的 Amazon Nova Lite 分析汽车图像以识别损坏细节。
- 系统结合前几步的结果来决定理赔。
- 起草一封电子邮件给客户,告知他们决定结果。
- 工作流程信息和决定通过电子邮件发送给用户。
这些步骤如下所示。
先决条件
要实现本文提供的解决方案,您需要具备以下条件:
- Snowflake 帐户 – 具有权限的活动帐户、熟悉 Snowflake SQL 或 Snowsight,并启用了 Cortex Document AI。
- AWS 帐户 – 具有 Amazon Bedrock 访问权限的活动帐户,包括对 Amazon Nova Lite 的访问权限,以及已配置的 AWS 凭证。
- Python 环境 – 安装了 Python 3.x 和所需的包。
- GitHub 访问权限 – 克隆提供的 GitHub 存储库。该存储库提供了对每个组件如何通过 LangGraph 驱动的状态机无缝集成和运行的全面理解,从文档上传和提取到验证。
- 文档准备 – 样本驾驶执照图像、理赔表 PDF 和具有相关数据的汽车损坏图像。
- Snowflake 数据设置 – 包含保单持有人数据(
customer ID、VIN和POLICY_END)和样本数据的`customer_policy_view`表或视图。 - Snowflake Document AI 模型构建 – 在 Snowsight 中为执照和理赔构建的两个模型,已训练并发布以用于预测。
- Amazon Bedrock 配置 – 已设置 AWS 凭证,以便 Python 可以访问 Amazon Bedrock 模型中的 FM。
使用的文档
为了模拟此代理式 AI 工作流程中真实的保险理赔场景,我们准备了三份代表性的输入文档,这些文档与真实用户提交理赔的方式相符。数据集包括:
- 显示姓名、驾照号码、出生日期、地址和执照有效期的新版驾驶执照 (DL),如下图所示

- 填写完整的理赔表 (PDF),记录客户 ID、车辆详细信息、事故描述和事故日期,如下所示

- 显示车辆损坏的照片,如下所示


本文中使用的汽车损坏图像来自汽车损坏数据集。
文档处理
此示例解决方案使用 Snowflake Document AI(由专有的 Arctic-TILT LLM 提供支持),以令人印象深刻的灵活性从上传的文档中提取信息。有关开始使用 Document AI 的信息,请访问设置 Document AI。
我们使用 Snowflake 的 DOCUMENT_INTELLIGENCE 类(由 Arctic-TILT LLM 提供支持),在 Snowsight 中创建了两个 Document AI 模型构建:LICENSE_DATA 和 CLAIMS_DATA,分别用于提取特定字段。在具有适当角色的 Snowsight 中登录后,我们上传样本文档,使用自然语言提示定义提取字段(例如,“许可证号码是多少?”),审查置信度评分的结果,并使用 MODEL_NAME!PREDICT(GET_PRESIGNED_URL(...)) SQL 语法发布模型。这使得管道中的零样本提取成为可能,而无需为每个新文件重新训练。下图显示了文档处理的工作流程。

上传的文档会经过专门的 AI 驱动处理。使用 LICENSE_DATA!PREDICT 解析执照以获取姓名和驾照号码等字段。使用 CLAIMS_DATA!PREDICT 解析理赔以获取车辆和事故详细信息(包括推断的车辆颜色)。
汽车图像由 Amazon Bedrock 上的 Amazon Nova Lite 模型分析,以提取结构化的损坏细节。这种多模态提取层将原始输入转换为结构化洞察,供下游决策使用。
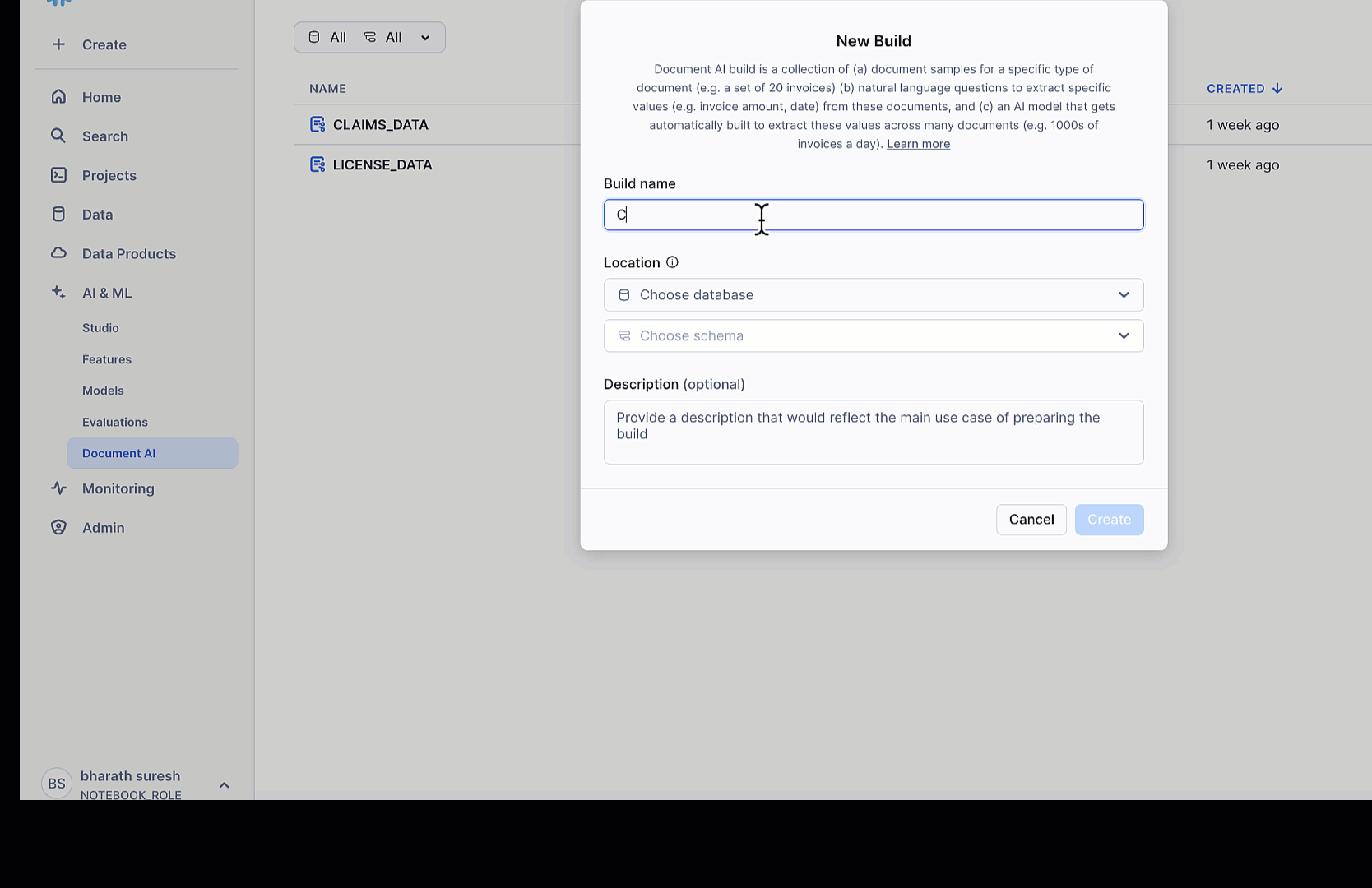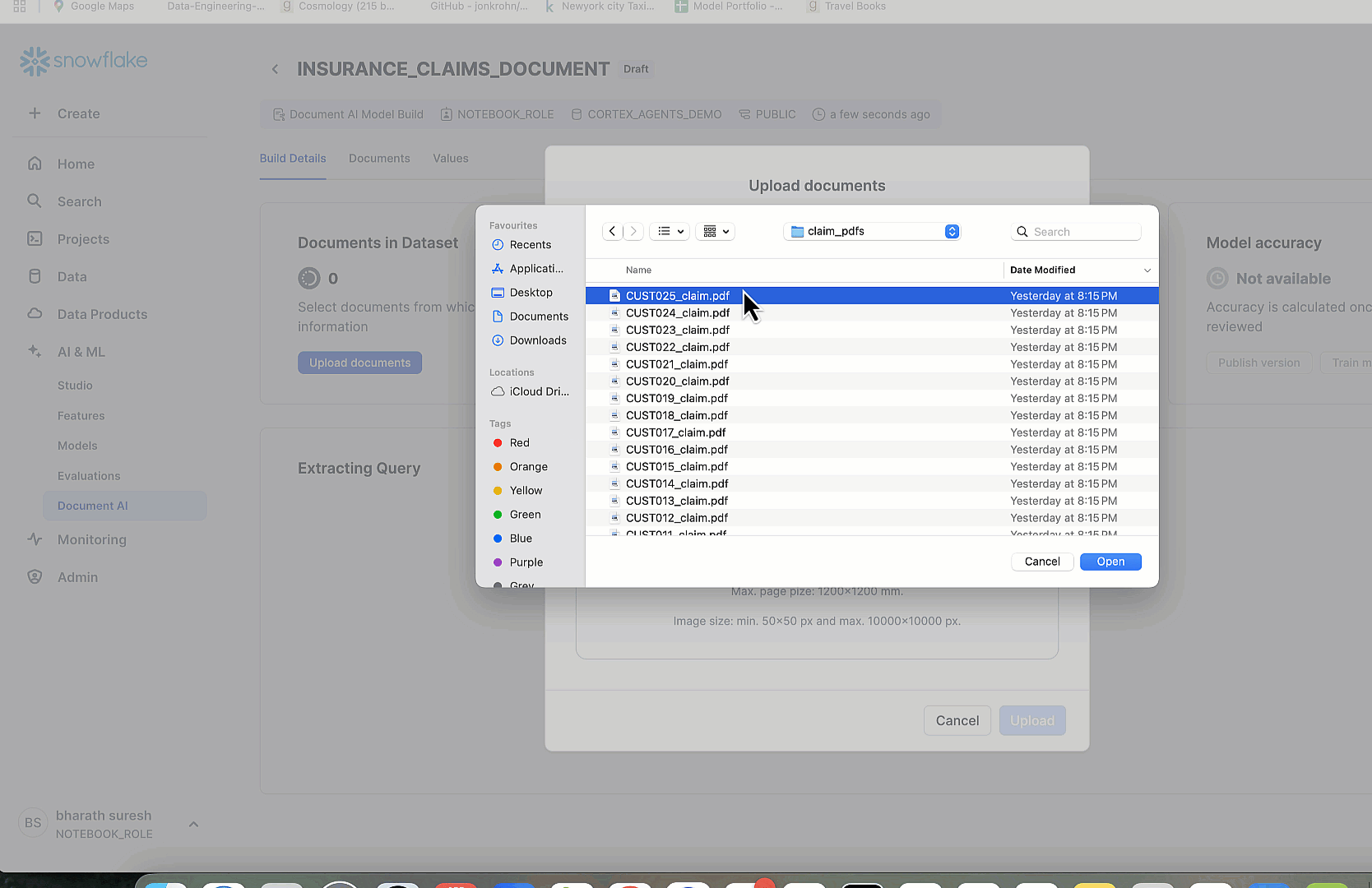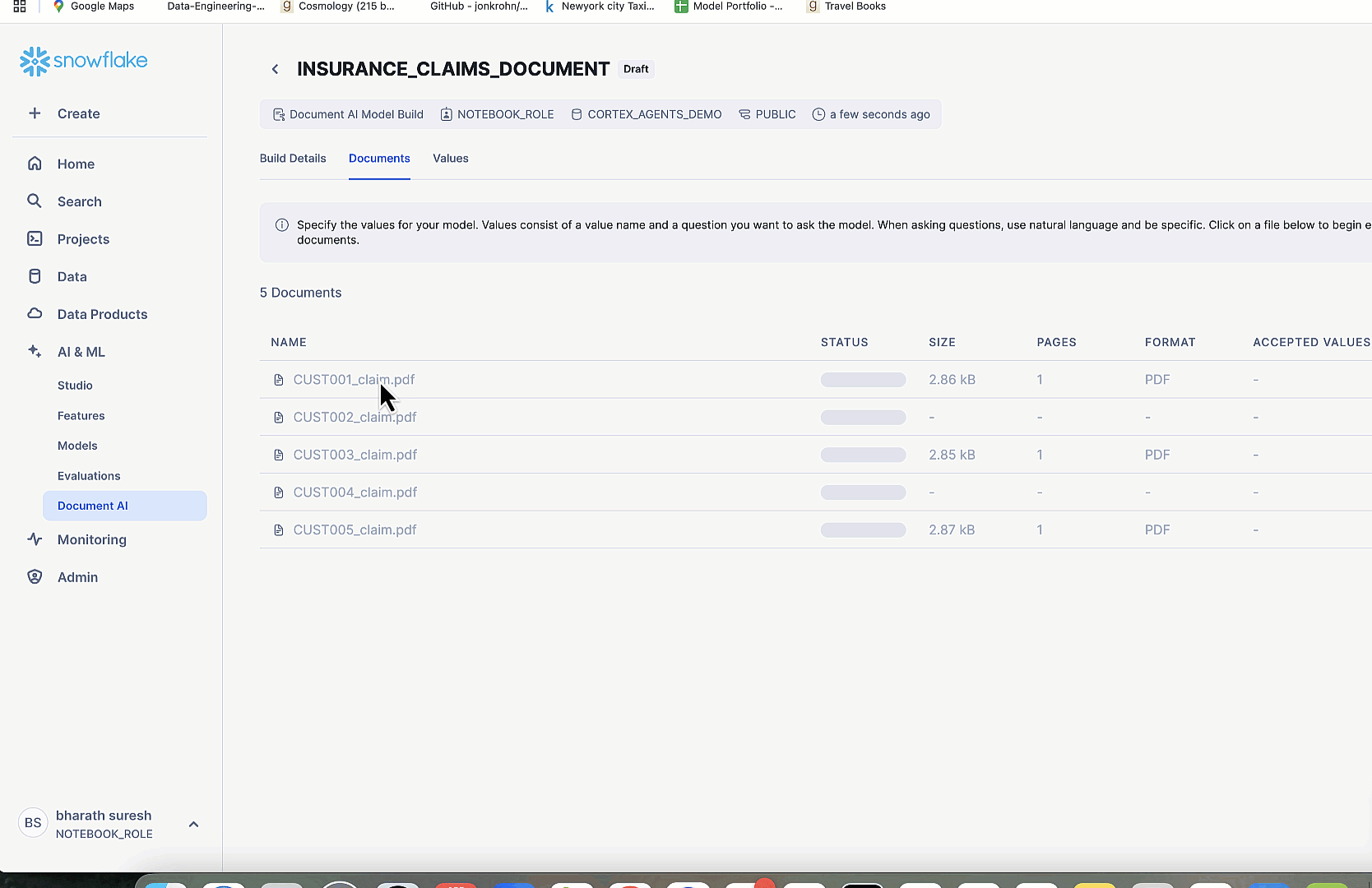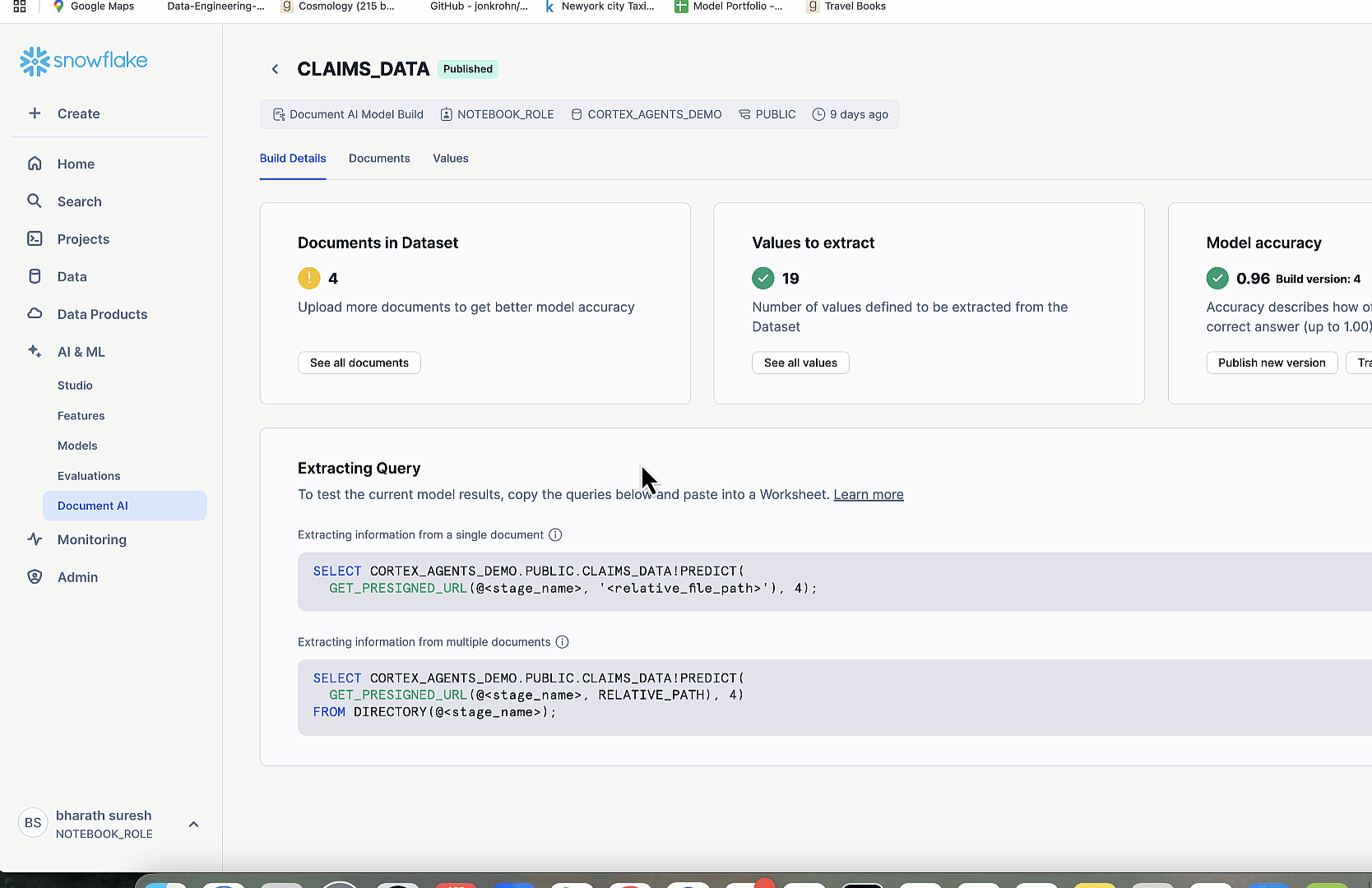
在 Snowsight 中准备 Document AI 模型
为了从驾驶执照和保险理赔表等非结构化文档中提取信息,我们使用 Snowflake 的 Document AI。我们创建了两个模型构建——LICENSE_DATA 和 CLAIMS_DATA——每个模型都旨在通过自然语言提示提取特定字段。在以适当角色登录 Snowsight 后,我们在左侧导航窗格中选择 AI & ML 和 Document AI 。然后我们创建一个新的构建并上传样本文档。
每个文件都经过光学字符识别 (OCR) 处理,之后我们通过将值名称与提取问题配对来定义字段。然后,我们会收到有置信度评分的答案,我们会进行审查和确认。当准确性令人满意时,我们会发布模型,使其可以使用 MODEL_NAME!PREDICT(GET_PRESIGNED_URL(...)) 语法从 SQL 中调用。为了提高精度,我们可以选择使用已审查的文档来微调模型。此设置支持从真实世界表格中进行稳健的零样本字段提取——无需自定义 ML 管道。
在 Snowsight 中创建和训练 Document AI 模型(例如,`LICENSE_DATA` 和 `CLAIMS_DATA`)并确保它们已发布并准备好使用 `MODEL_NAME!PREDICT(GET_PRESIGNED_URL(...))` 进行预测后,我们就过渡到使用 Python 代码来处理工作流程的其余部分。Python 代码将处理编排、数据检索、LLM 交互和决策制定的步骤,这些步骤是完成保险理赔处理管道所必需的。
下面的视频展示了此过程。
使用 Amazon Nova Lite 进行汽车损坏分析
为了评估事故图像中的车辆损坏情况,我们在 AWS Bedrock 中使用 Amazon Nova Lite,这是一个高性能、低延迟的多模态 FM。Nova Lite 使我们的代理式工作流程能够仅使用一个自然语言提示来解释非结构化的图像数据(例如汽车照片),而无需专门的计算机视觉模型。
图像通过 Streamlit 界面上传后,会被编码为 base64 并包装在多模态提示中。我们通过将图像和文本指令发送给模型来模拟专业的损坏检查场景。以下是我们后端中使用的实际逻辑:
with open(path, "rb") as image_file:
binary_data = image_file.read()
base64_string = base64.b64encode(binary_data).decode("utf-8")
client = boto3.client("bedrock-runtime", region_name="us-east-1")
model_id = "us.amazon.nova-lite-v1:0"
system_list = [{ "text": "You are an expert car inspector. When provided with a car accident photo, return a technical summary describing the vehicle and any visible damage."
}]
message_list = [{ "role": "user", "content": [ { "image": { "format": ext, "source": {"bytes": base64_string} } }, { "text": "Please inspect this damaged car image and return a summary of the damage and car type in professional language." } ],
}]
native_request = { "schemaVersion": "messages-v1", "messages": message_list, "system": system_list, "inferenceConfig": {"maxTokens": 500, "topP": 0.1, "topK": 20, "temperature": 0.3}
}
The invoke_model() method then sends this payload to Bedrock:
response = client.invoke_model( modelId=model_id, body=json.dumps(native_request), accept="application/json", contentType="application/json"
)该模型返回一个自然语言响应,例如:
The vehicle appears to be a hatchback with moderate rear-end collision damage. There are visible dents around the rear bumper. The car is likely a dark purple Ford Focus.我们将此摘要存储在共享工作流程状态的 car 对象中:
model_response = json.loads(response["body"].read())
content_text = model_response["output"]["message"]["content"][0]["text"]
car_data = { "visible_damage": content_text
}通过使用 Amazon Nova Lite 中的多模态功能,我们显著减少了图像处理的复杂性,并避免了训练和维护单独的图像识别模型的需要。此步骤为代理式管道增加了视觉智能——从而能够对保险理赔进行更完整和与人类对齐的评估。
使用 Amazon Nova 进行跨文档比较和保单验证
从驾驶执照、理赔表和汽车图像中提取数据后,代理式 AI 工作流程会验证信息的*一致性*和*真实性*。这是通过跨文档比较和针对 Snowflake 记录的保单验证检查来完成的。
首先,我们使用从理赔表中提取的姓名来识别客户。我们查询 Snowflake 视图 (customer_policy_view) 以检索关联的客户 ID。然后,我们将此视图与 DRIVER_LICENSES 表联接,以获取参考字段,例如颜色、品牌和型号、出生日期、驾照号码和保单到期日。
以下是工作流程中使用的实际 SQL 逻辑:
df_id = session.sql(f""" SELECT CUSTOMER_ID FROM customer_policy_view WHERE LOWER(NAME) = '{extracted_name.lower()}'
""").to_pandas()
df = session.sql(f""" SELECT cpv.NAME, cpv.COLOR, cpv.MAKE_MODEL, cpv.POLICY_END, dl.LICENSE_NO, dl.DOB FROM customer_policy_view cpv JOIN DRIVER_LICENSES dl ON LOWER(cpv.NAME) = LOWER(dl.NAME) WHERE cpv.CUSTOMER_ID = '{customer_id}'
""").to_pandas()
接下来,我们将文档中提取的每个值与其在数据库中的对应值进行比较。比较的字段包括:
full_namedl_nodobvehicle_colormake_model
每次比较都会返回一个匹配状态(true 或 false)以及提取值和参考值,以便我们可以清楚地跟踪不匹配项。比较字典结构如下:
comparison = { "full_name": { "match": extracted_name.lower() == db_name.lower(), "claim_value": extracted_name, "db_value": db_name }, ...
}然后,我们通过将理赔中的事故日期与 Snowflake 中的保单到期日期进行比较来验证保单的有效状态:
incident_date = datetime.strptime(claim.get("date_of_incident", [{}])[0].get("value"), "%Y-%m-%d").date()
valid = incident_date and db_policy_end_date_obj and incident_date <= db_policy_end_date_obj
decision = "✅ Claim Accepted" if valid else "❌ Claim Rejected due to expired policy"
这种双层验证有助于使理赔在事实上准确且在法律上有效。关键的不匹配(例如无效的驾照号码或过期的保单)会导致自动拒绝,而经验证的匹配和在保单内的事故则会导致接受。
通过在 Python 中完全执行此推理步骤并使用结构化比较逻辑,我们保持了完全的透明度、灵活性和可审计性——这对于企业保险系统至关重要。
使用 Amazon Nova 进行自主推理和理赔决策
在提取和验证了所有相关数据——包括驾驶执照、理赔表、汽车照片和保单数据库中的数据——之后,工作流程的最后一步是推理*全部*上下文并生成清晰、专业的理赔决定。这时 Amazon Nova Lite 再次登场,这次作为逻辑处理器和自然语言生成器。
我们构建了一个结构化提示,向 Amazon Nova Lite 提供迄今收集到的所有证据,包括逐字段的比较结果、保单到期日、事故发生日期以及计算出的决定标志(接受或拒绝)。以下是在 Python 中计算的决定逻辑:decision = "✅ Claim Accepted" if valid else "❌ Claim Rejected due to expired policy"
然后我们准备一个人类可读的推理提示,总结情况:
email_prompt = f"""Write a short professional email to a customer summarizing their insurance claim review.
Comparison:
{json.dumps(comparison, indent=2)}
Incident Date: {incident_date}
Policy End: {db_policy_end_date_obj}
Decision: {decision}
"""此提示使用 Amazon Bedrock Runtime API 传递给 Amazon Nova Lite。Nova Lite 会解释全部上下文并生成一条量身定制的清晰信息给客户:
body = { "schemaVersion": "messages-v1", "messages": [{"role": "user", "content": [{"text": email_prompt}]}], "inferenceConfig": {"maxTokens": 1000}
}
email_response = bedrock.invoke_model( body=json.dumps(body), modelId="us.amazon.nova-lite-v1:0", accept="application/json", contentType="application/json"
)响应可能如下所示:
Dear Steven, we have completed the review of your insurance claim submitted on February 14, 2025. Based on our evaluation, your documents have been successfully verified and the incident falls within your active policy period. We’re pleased to inform you that your claim has been accepted.此输出与结构化决定和比较结果一起存储在工作流程状态中。对于所有结果,在我们代理式应用程序的最后一步中,系统将自动生成一个客户就绪的消息,无需人工干预。
通过使用 Amazon Nova Lite 处理多模态输入和自主决策通信,我们完成了智能、自我推理工作流程的闭环,该工作流程模仿了人类保险理算师的判断和同理心,并且可以大规模执行此操作。
最终输出示例
在处理上传的文档、分析汽车图像、验证提取的字段并确认保单资格后,代理式 AI 工作流程会产生一个结构化且可解释的输出,其中包括跨文档和 Snowflake 记录的比较结果、理赔决定(接受或拒绝)以及由 Amazon Nova Lite 生成的面向客户的电子邮件。以下是成功理赔的完整输出示例:
{ "decision": "✅ Claim Accepted", "comparison": { "full_name": { "match": true, "claim_value": "Steven Smith", "db_value": "Steven Smith" }, "dl_no": { "match": true, "claim_value": "DL-2605979475", "db_value": "DL-2605979475" }, "dob": { "match": true, "claim_value": "1991-08-15", "db_value": "1991-08-15" }, "vehicle_color": { "match": true, "claim_value": "Purple", "db_value": "Dark Purple" }, "make_model": { "match": true, "claim_value": "Ford Focus", "db_value": "Ford Focus Titanium" } }, "email": "Dear Steven, we have completed the review of your insurance claim submitted on February 14, 2025. Based on our evaluation, your documents have been successfully verified and the incident falls within your active policy period. We’re pleased to inform you that your claim has been accepted. You will receive a follow-up with next steps shortly. Thank you for choosing our services."
}此输出展示了管道的全部强大功能,其中包含来自 Snowflake 的真实数据、Document AI 的智能提取、使用 Amazon Nova Lite 的多模态推理以及自然语言的决策解释。
结构化格式使得审计、日志记录或与下游系统(如客户关系管理 (CRM) 系统、电子邮件工作流程或保险管理平台)集成变得非常简单。更重要的是,它在生产中实现了可信赖、可解释 AI 的闭环。
代理式 AI 工作流程如何实现自动化
整个车辆保险理赔处理管道被实现为一个代理式 AI 工作流程,其中每个阶段都会观察输入、应用推理、使用 LLM 做出决策,并将上下文转发给下一个阶段。这由 LangGraph 进行编排,LangGraph 是一个有状态的工作流程引擎,它将每个任务视为一个模块化节点,并在整个图中传递一个共享状态。
在...
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区