



📢 转载信息
原文作者:Zainab Afolabi, Laksh Puri, Margherita Rosnati, Hammad Mian, Joonas Kukkonen
本文由 Bark.com 的 Hammad Mian 和 Joonas Kukkonen 联合撰写。
在扩展视频内容创作时,许多公司都面临着在缩短制作时间的同时保持质量的挑战。本文演示了 Bark.com 和 AWS 如何合作解决这个问题,并提供了一个可复制的方法来实现 AI 驱动的内容生成。Bark.com 利用 Amazon SageMaker 和 Amazon Bedrock 将其营销内容管道的生产时间从数周缩短到数小时。
Bark 每周将成千上万的人与专业服务联系起来,从景观美化到家庭护理,涵盖多个类别。当 Bark 的营销团队发现有机会扩展到中漏斗社交媒体广告时,他们面临着一个扩展性问题:有效的社交活动需要大量的个性化创意内容来进行快速 A/B 测试,但他们手动制作的生产流程每个活动需要数周时间,并且无法支持多种客户细分的变化。
如果您也面临类似的营销内容扩展挑战,此架构模式可以为您提供有用的起点。通过与 AWS 生成式 AI 创新中心合作,Bark 开发了一个 AI 驱动的内容生成解决方案,该方案在实验性测试中显著缩短了生产时间,同时提高了内容质量得分。此次合作旨在实现四个目标:
- 生产时间 – 从数周缩短到数小时
- 个性化规模 – 为每个活动支持多个客户微细分
- 品牌一致性 – 在生成的内容中保持声音和视觉标识
- 质量标准 – 达到专业制作的广告水平
在本文中,我们将详细介绍我们构建的技术架构、促成成功的关键设计决策以及实现的显著成果,为您提供实施类似解决方案的蓝图。
解决方案概述
Bark 与 AWS 生成式 AI 创新中心合作,开发了一个能够应对这些营销内容扩展挑战的解决方案。该团队设计了一个使用 AWS 服务和定制 AI 模型相结合的系统。下图展示了该解决方案的架构。
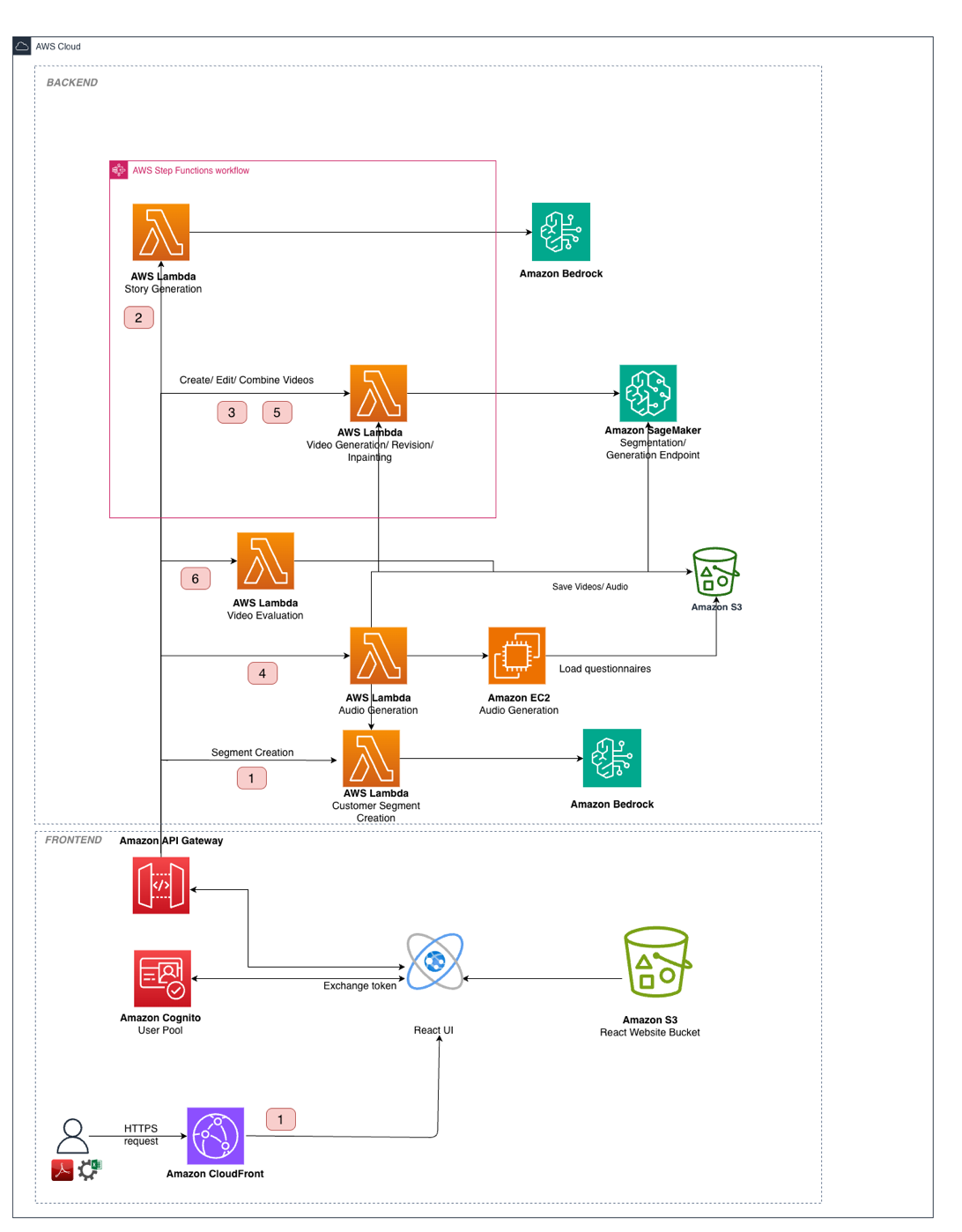
解决方案架构包含以下集成层:
- 数据和存储层 – Amazon Simple Storage Service (Amazon S3) 存储资产,包括训练数据、生成的视频片段、参考图像和最终输出。模型构件和自定义推理容器存储在 Amazon Elastic Container Registry (Amazon ECR) 中。
- 处理层 – AWS Lambda 协调多阶段管道,AWS Step Functions 管理七步生成过程中的工作流状态。Amazon Bedrock 结合 Anthropic 的 Claude Sonnet 3.7 处理文本生成任务,包括客户细分、故事生成和质量评估。
- GPU 计算层 – 为了可靠地服务 Wan 2.1 Text2Video-14B,我们运行一个多 GPU 推理容器,该容器使用张量并行化将模型分片到单个 p4de.24xlarge SageMaker 实例的八个 GPU 上。TorchServe 作为端点处理请求,torchrun 启动每个 GPU 的一个工作进程。我们使用 Fully Sharded Data Parallel (FSDP) 分片——一种将模型组件分布到 GPU 上的技术——用于文本编码器和扩散转换器,以在不将权重卸载到 CPU 的情况下保持在 GPU 内存限制内。由于视频扩散是耗时操作,因此端点通过扩展的推理超时和更长的容器启动健康检查窗口进行调优,以适应模型加载时间并帮助避免过早重启。 Amazon Elastic Container Service (Amazon ECS) 上的 GPU 驱动的 g5.2xlarge 实例容器负责为叙述者配音生成语音合成,在空闲时可缩减至零。
- 用户界面层 – 带有 Amazon Cognito 身份验证的 React 前端提供了一个视频工作室界面,营销团队可以通过自然语言命令在该界面上审查、编辑和批准生成的营销内容。
创意构思管道
现在您已经了解了整体架构,让我们来探讨一下如何在您自己的环境中实现创意构思管道。该管道将客户问卷数据转化为生产就绪的故事情节,过程分为三个阶段。
阶段 1: 客户细分生成
管道首先使用带有 Anthropic Claude Sonnet 3.7 的 Amazon Bedrock 分析 Bark 的客户问卷数据。大型语言模型 (LLM) 处理调查响应,以识别具有结构化属性(包括人口统计信息、动机、痛点和决策因素)的独特客户画像。例如,在家庭护理类别中,系统识别出以下细分:
- 压力巨大的家庭照顾者 – 40-50 岁的成年人,在工作责任和照顾年迈父母之间取得平衡,优先考虑可靠性和信任。
- 注重独立的年长者 – 接受需要偶尔帮助的必要性,但仍寻求维持自主性的老年人。
每个细分画像都通过人工干预 (human-in-the-loop) 流程在 UI 中进行审查,并作为后续创意构思的输入,从而创建与已识别的受众特征产生共鸣的广告。
阶段 2: 创意简报生成
鉴于业务类别和目标细分,系统会生成 4-6 个不同抽象程度的创意概念——鼓励字面和隐喻方法。我们将模型配置为高温度采样(0.8-1),以鼓励发散性思维。模型采用思维链推理,在生成简报之前明确评估概念的相关性、参与潜力和娱乐价值。这会针对相同的商业目标产生多种叙事方法,例如直接的推荐格式或情感共鸣的隐喻故事。
阶段 3: 故事情节细化
最后阶段将通用创意简报转化为细分特定的故事情节。随机特征采样机制——它随机确定要强调的属性——会识别要强调的客户细分属性,在满足特定动机和痛点的同时保持多样性。系统通过引导推理进行明确的简报到细分匹配,然后使用完整的视听规格(包括场景描述、镜头方向、旁白文本和计时)生成最终的故事情节。此阶段的人工审查在生产开始前确认品牌一致性。
跨场景维持视觉一致性
30 秒的广告包含 4-6 个不同的场景,最好单独生成。如果没有仔细协调,AI 模型会表现出语义漂移——角色外观改变,背景意外移动,品牌元素不一致。我们的解决方案实施了一个双层一致性框架。
语义一致性
您可以通过一个三阶段过程将创意简报转化为视频提示:
- 元素提取 – LLM 分析故事情节以识别原子装饰元素——演员、道具、对象和位置——并标记需要在场景之间保持一致的元素。
- 蓝图生成 – 对于每个重复出现的元素,系统会生成详细的规格蓝图,建立规范的视觉表示。
- 提示转换 – 高层场景描述被转化为详细的视频生成提示,整合了原始创意简报(用于叙事一致性)和规范的装饰规格(用于视觉一致性)。
视觉一致性
尽管通过详细提示实现的语义一致性在很大程度上减少了漂移,但即使在相同的提示规格下,视频生成模型仍然表现出一定的解释自由度。为了解决此限制,我们实施了一个参考图像提取和传播管道,如下图所示。
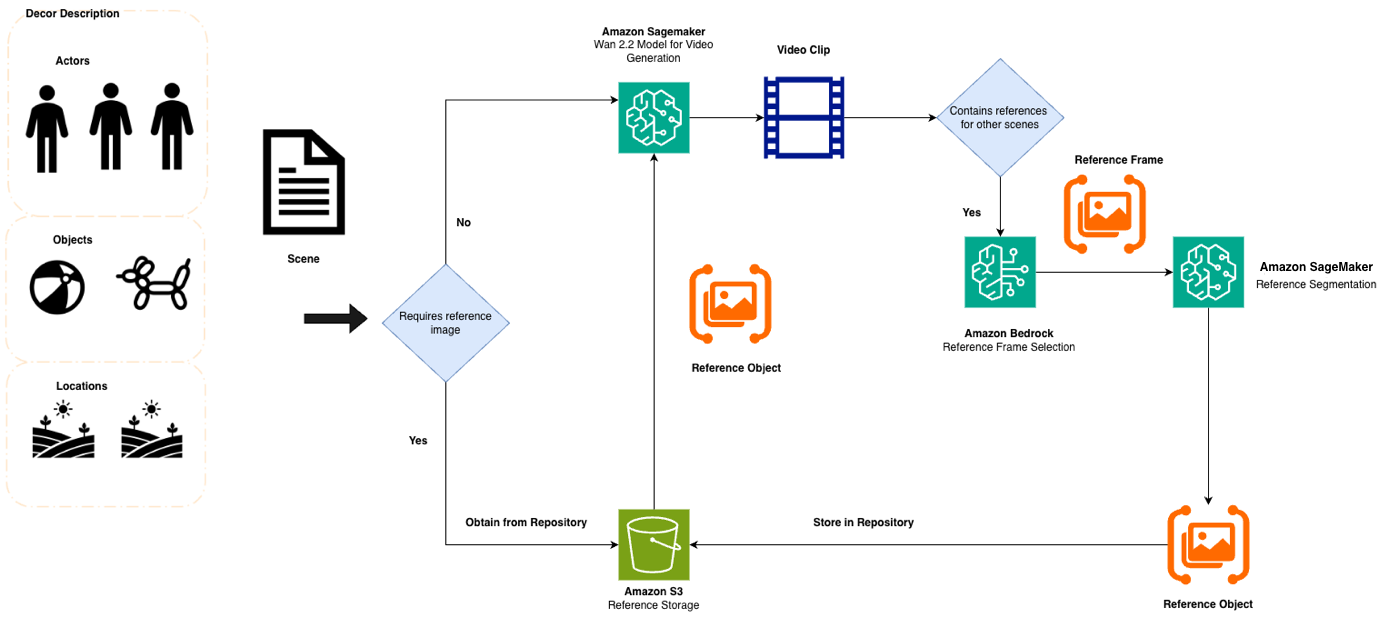
该管道包含以下阶段:
- 最佳帧识别 – Amazon Nova Premier 分析生成的场景,以识别目标元素出现最清晰的帧。
- 元素分割 – 在 Amazon ECS 上部署的开源 Segment Anything Model 将目标元素与背景分离。
- 参考传播 – 提取的参考图像通过 Wan 2.2 的参考到视频功能输入到后续的视频生成调用中。
这种双重约束方法——将语义规范与详细提示相结合,并将视觉规范与参考图像相结合——创建了一个强大的一致性框架,我们通过系统性消融研究进行了验证。
视频生成管道
该管道根据场景要求,通过战略性模型选择来协调五种模态——文本、图像、视频、音频和叠加图形:
- 参考到视频合成 – 需要视觉连续性的场景使用带有提取参考图像的 Wan 2.1 VACE- 14B。
- 文本到视频生成 – 引入新元素的场景使用 Wan 2.1 Text2Video-14B。
Step Functions 工作流将生成过程排序,以在依赖场景开始之前验证参考图像是否可用。
语音合成和图形
语音合成使用 GPU 驱动的 ECS 实例(g5.2xlarge)上的 Sesame AI Lab 的 Conversational Speech Model。声音克隆需要 Bark 品牌叙述者的 10 秒参考样本;模型会提取说话人嵌入,可用于条件化后续生成。Amazon ECS 在空闲时会缩减至零,从而在活跃生成窗口之外节省成本。此外,文本叠加和行动号召图形使用模板系统,该系统支持与 Bark 品牌指南的排版一致性。这些元素在最终组装期间进行组合。
质量评估循环
Lambda 中的 LLM 作为裁判评估循环会从三个维度评估每个场景:
- 叙事一致性 – 对故事情节描述的准确性。
- 视觉质量 – 没有瑕疵和不一致。
- 品牌合规性 – 与品牌指南的一致性。
低于可配置质量阈值的场景将触发自动重新生成,同时保留视觉参考元素。这种迭代改进将持续进行,直到场景满足质量标准或请求人工审查为止。
消息一致的登录页面
使用生成的视频和客户细分作为基础,我们创建了一个代理系统来生成个性化登录页面。我们使用 Strands 代理执行以下操作:
- 生成页面的 TypeScript 代码。
- 从视频中截取最佳截图包含在页面中(以便用户了解它与他们观看的视频广告直接相关)。
- 修改措辞和设计以与客户细分保持一致。
结果
我们对 AI 生成的内容与 Bark 现有的广告库进行了评估。下表总结了结果。
| 评估维度 | AI 生成广告 | 现有广告库 |
| 故事情节结构连贯性 | 6.9 ± 0.49 | 6.4 ± 0.74 |
| 原创性与参与度 | 6.5 ± 1.23 | 5.2 ± 1.22 |
| 视觉与空间一致性 | 6.9 ± 0.74 | 6.6 ± 0.75 |
得分按 10 分制计算,置信区间为 95%
结果表明,AI 生成的内容在叙事连贯性方面得分更高,验证了分层场景规划方法。原创性得分的 25% 提高表明创意构思管道成功平衡了新颖性与商业可行性。参考图像传播系统在角色和环境一致性方面比手动制作产生了更高的可衡量结果。
端到端来看,该管道在 ml.p4d.24xlarge SageMaker 实例上生成 15-30 秒的广告大约需要 12-15 分钟;这包括编排(参考提取/分割)、自动质量检查和重新生成循环——而不仅仅是单个模型调用。通过将 14B 模型完全放入 GPU 内存并加速繁重的注意力/去噪计算,多 GPU 分片(8 路张量并行)可将每场景生成时间保持在几秒到几分钟之间。将其置于 SageMaker 实时端点之后,可以在请求之间保持模型处于预热状态,并帮助避免重复加载模型造成的延迟,而长推理超时和启动健康检查可减少长时间运行的扩散调用中的故障和重试。
消融研究
为了验证每个架构决策,我们进行了系统的消融研究。下表总结了结果。
| 配置 | 故事情节连贯性 | 参与度 | 视觉一致性 |
| 完整系统 | 6.9 | 6.5 | 6.9 |
| 无参考图像传播 | 7.5 | 4.8 | 6.7 |
| 无叙事元素提取 | 7.6 | 4.5 | 6.4 |
| 无分层场景规划 | 7.0 | 4.5 | 6.5 |
结果表明,移除参考图像传播显著影响了参与度得分(从 6.5 降至 4.8),这表明一致的角色表示支持更复杂的叙事发展。禁用叙事元素提取导致参与度下降最为严重,但结构得分略有提高——这表明结构化叙事分析支持创意风险承担,同时保持连贯的故事情节。
这对您的实施意味着什么
根据我们的经验,以下是您自己视频生成项目的可操作指南:
- 人工干预至关重要 – 尽管系统自动化了大部分生产时间,但在创意简报批准和最终审查阶段的人工干预可以确保品牌一致性。
- 参考图像质量比数量更重要 – 我们的自适应参考提取系统通过多标准评估(视觉清晰度、光照、元素突出度)动态识别最佳帧。糟糕的参考图像会在整个视频序列中传播错误。
- LLM 作为裁判支持快速迭代 – 传统的视频评估成本高昂且缓慢。使用 Anthropic 的 Claude 根据结构化标准评估生成的营销内容,支持了对不同生成方法的快速实验。
- 为复合一致性挑战而设计 – 单一角色一致性已被深入研究;更难的问题是保持复合元素(如装饰完整的房间,其中多个视觉属性必须共存)的一致性。围绕这些复杂情况规划架构。
清理工作
如果您在自己的环境中复制此解决方案,请记住在完成实验后删除资源,以避免持续的成本:
- 删除 SageMaker 端点。
- 移除包含生成资产的 S3 存储桶。
- 终止 Amazon ECS 服务和任务定义。
- 删除 Lambda 函数和 Step Functions 状态机。
结论
此次合作建立了一个使用 AWS 服务进行 AI 辅助创意生产的可复制模式。核心架构洞察——通过分层提示规划结合语义一致性,以及通过参考图像传播实现视觉一致性——解决了多场景视频生成中的基本挑战,这些挑战超出了广告范围,延伸到需要连贯、扩展叙事的各种领域。对于 Bark 而言,该解决方案在业务评估中,有潜力支持个性化社交媒体活动的快速实验,从而支持其扩展到中漏斗营销渠道。
要开始构建类似的解决方案,请考虑以下后续步骤:
- 探索 Amazon Bedrock,用于构建生成式 AI 应用程序。
- 了解 Amazon SageMaker AI,用于托管自定义模型。
- 联系 AWS 生成式 AI 创新中心,讨论您的内容生成挑战。
致谢
特别感谢 Giuseppe Mascellero 和 Nikolas Zavitsanos 的贡献。
关于作者
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区