



📢 转载信息
原文作者:Vijit Vashishtha and Koshal Agrawal
组织通常依赖 A/B 测试来优化用户体验、消息传递和转化流程。然而,传统的 A/B 测试是随机分配用户,并需要数周的流量才能达到统计显著性。虽然有效,但这个过程可能很慢,并且可能无法充分利用用户行为中的早期信号。
本文将介绍如何使用 Amazon Bedrock、Amazon Elastic Container Service (Amazon ECS)、Amazon DynamoDB 和 Model Context Protocol (MCP) 构建一个 AI 驱动的 A/B 测试引擎。该系统通过在实验期间分析用户上下文来做出更明智的变体分配决策,从而改进了传统的 A/B 测试。这有助于您减少噪音、及早识别行为模式,并更快地获得自信的获胜者。
通过阅读本文,您将获得一个能够使用服务器less AWS 服务提供可扩展、自适应和个性化实验的架构和参考实现。
传统 A/B 测试的挑战
传统的 A/B 测试遵循熟悉的模式:随机将用户分配到变体,收集数据,然后选择获胜者。
这种方法存在局限性:
- 仅随机分配 – 即使早期信号表明存在显著差异
- 收敛缓慢 – 您需要等待数周才能收集足够的数据
- 高噪音 – 系统可能会将某些用户分配给明显不符合其需求的变体
- 手动优化 – 您通常需要事后对数据进行分段
真实场景:为什么随机分配会拖慢您的速度
考虑一家零售商在其产品页面上测试两个号召性用语 (CTA) 按钮:
- 变体 A:“立即购买”
- 变体 B:“立即购买 – 免费送货”
最初几天,变体 B 的表现似乎不错,您可能会考虑推广它。然而,更深入的会话分析揭示了一些有趣之处:
- 高端忠诚度会员,他们已经享受免费送货,看到“免费送货”消息时会犹豫。有些人甚至会导航到他们的账户页面来验证他们的福利。
- 来自优惠券和折扣网站的、偏爱优惠的访问者,更倾向于变体 B。
- 移动用户更喜欢变体 A,因为较短的 CTA 在较小的屏幕上显示效果更好。
虽然变体 B 似乎早期获胜,但不同的用户行为集群影响了这一表现,而不是普遍的偏好。
分配是随机的,因此实验需要一个长周期来平均化这些影响——并且您需要手动分析多个细分才能理解它。这就是 AI 辅助分配可以帮助改进实验的地方。
解决方案概述:AI 辅助变体分配
AI 辅助 A/B 测试引擎通过使用实时用户上下文和早期行为模式来做出更明智的变体分配决策,从而升级了经典的实验。
该解决方案引入了一个使用 Amazon Bedrock 构建的自适应 A/B 测试引擎。该引擎不将每个用户分配到相同的变体,而是实时评估用户上下文,检索过去的行为数据,并为该个体选择最佳变体。
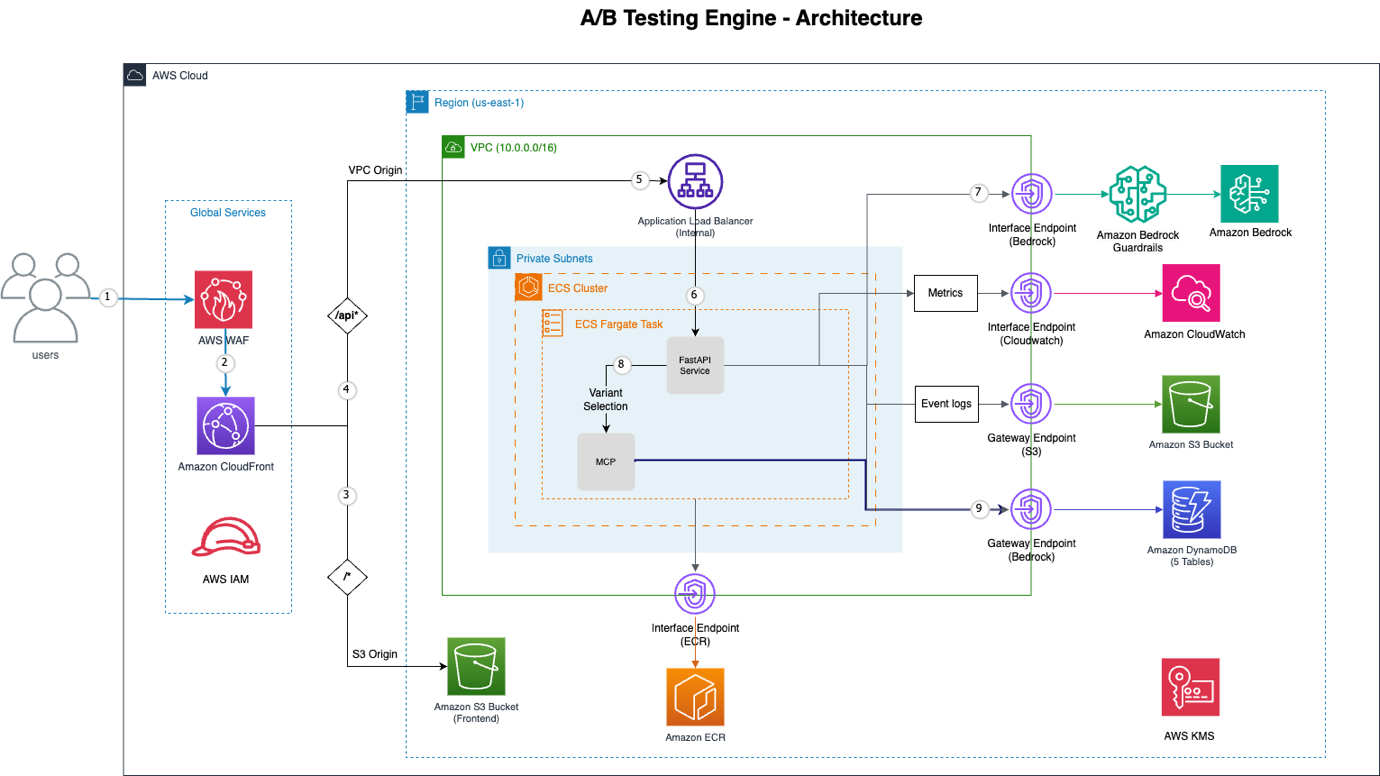
图 1:A/B 测试引擎架构
该架构包含以下 AWS 组件:
- Amazon CloudFront + AWS WAF – 全球内容分发网络 (CDN),提供分布式拒绝服务 (DDoS) 保护、SQL 注入防御和速率限制。
- VPC Origin – 从 Amazon CloudFront 到内部应用程序负载均衡器的私有连接(无公共互联网暴露)。
- Amazon ECS 搭配 AWS Fargate:运行 FastAPI 应用程序的无服务器容器编排。
- Amazon Bedrock – 使用 Claude Sonnet 和原生工具使用的 AI 决策引擎。
- Model Context Protocol (MCP) – 提供对行为和实验数据的结构化访问。
- VPC Endpoints – 到 Amazon Bedrock、Amazon DynamoDB、Amazon S3、Amazon Elastic Container Registry (Amazon ECR) 和 Amazon CloudWatch 的私有连接。
- Amazon DynamoDB – 用于实验、事件、分配、配置文件和批处理作业的五个表。
- Amazon Simple Storage Service (Amazon S3) – 静态前端托管和事件日志存储。
Amazon Bedrock 如何改进变体决策
核心创新在于结合用户上下文、行为历史、类似用户模式和实时性能数据来选择最佳变体。本节将揭示 AI 决策过程的工作原理。
AI 决策提示:Amazon Bedrock 所见
当用户触发变体请求时,系统会构建一个全面的提示,为 Amazon Bedrock 提供做出明智决策所需的完整内容。以下是实际提示的结构:
# System Prompt (defines Amazon Bedrock's role and behavior) system_prompt = """
You are an expert A/B testing optimization specialist with access to tools for gathering user behavior data. CRITICAL INSTRUCTIONS: 1. ALWAYS call get_user_assignment FIRST to check for existing assignments 2. Only call other tools if you need specific information to make a better decision 3. Call tools based on what information would be valuable for this specific decision 4. If user has existing assignment, keep it unless there's strong evidence (30%+ improvement) to change 5. CRITICAL: Your final response MUST be ONLY valid JSON with no additional text, explanations, or commentary before or after the JSON object Available tools: - get_user_assignment: Check existing variant assignment (CALL THIS FIRST) - get_user_profile: Get user behavioral profile and preferences - get_similar_users: Find users with similar behavior patterns - get_experiment_context: Get experiment configuration and performance - get_session_context: Analyze current session behavior - get_user_journey: Get user's interaction history - get_variant_performance: Get variant performance metrics - analyze_user_behavior: Deep behavioral analysis from event history - update_user_profile: Update user profile with AI-derived insights - get_profile_learning_status: Check profile data quality and confidence - batch_update_profiles: Batch update multiple user profiles Make intelligent, data-driven decisions. Use the tools you need to gather sufficient context for optimal variant selection. RESPONSE FORMAT: Return ONLY the JSON object. Do not include any text before or after it.""" # User Prompt (provides specific decision context) prompt = f"""Select the optimal variant for this user in experiment {experiment_id}. USER CONTEXT: - User ID: {user_context.user_id} - Session ID: {user_context.session_id} - Device: {user_context.device_type} (Mobile: {bool(user_context.is_mobile)}) - Current Page: {user_context.current_session.current_page} - Referrer: {user_context.current_session.referrer_type or 'direct'} - Previous Variants: {user_context.current_session.previous_variants or 'None'} CONTEXT INSIGHTS: {analyze_user_context()} PERSONALIZATION CONTEXT: - Engagement Score: {profile.engagement_score:.2f} - Conversion Likelihood: {profile.conversion_likelihood:.2f} - Interaction Style: {profile.interaction_style} - Previously Successful Variants: {profile.successful_variants} AVAILABLE VARIANTS: {format_variants_for_prompt(variants)} HISTORICAL PERFORMANCE: {get_variant_performance_summary(variants)} INSTRUCTIONS: 1. FIRST: Call get_user_assignment to check if user has existing assignment 2. If existing assignment exists, only change if you have strong evidence (30%+ improvement expected) 3. Call additional tools as needed to gather sufficient context for an optimal decision 4. Consider: device type, user behavior, session context, variant performance 5. Make data-driven decision based on tool results CRITICAL: Respond with ONLY valid JSON, no additional text before or after: { "variant_id": "A|B|C", "confidence": 0.85, "reasoning": "Detailed explanation including which tools you used and why" } """提示结构的关键要素:
两层提示结构结合了系统提示和用户提示。
系统提示将 Amazon Bedrock 定义为“具有访问行为数据工具的专家 A/B 测试优化专家”,并提供了 11 种 MCP 工具(分配检查、配置文件分析、协同过滤、性能指标、会话分析)和关键规则(首先检查现有分配、更改的 30% 阈值、仅 JSON 响应)。
用户提示提供了完整的决策上下文,包括用户属性(设备、页面、推荐者、先前变体)、个性化数据(参与度分数、转化可能性、互动风格)、动态格式化的变体配置、实时性能指标和 5 步决策框架。
两者共同帮助 Amazon Bedrock 智能地协调工具调用,并做出具有完全透明度的、数据驱动的变体选择。
为什么选择 Amazon Bedrock 而非传统机器学习
传统机器学习 (ML) 模型(例如,决策树、逻辑回归、神经网络)多年来一直是用户细分的驱动力。那么,为什么使用 Amazon Bedrock 进行变体分配呢?答案在于四项关键功能:
智能工具编排
传统的 ML 需要硬编码的特征工程。您必须预先决定要获取哪些数据以及如何组合它们。Amazon Bedrock 通过 Model Context Protocol,根据情况智能地决定调用哪些工具。
Amazon Bedrock 的工具调用模式(来自实际日志):
User 1 (New Mobile User): 1. get_user_assignment() → No existing assignment 2. get_similar_users(user_id) → Found 47 similar mobile users 3. get_variant_performance(variant_id="B") → 23% higher mobile conversion Decision: Variant B (confidence: 0.65)
User 2 (Returning Premium Customer): 1. get_user_assignment() → Existing: Variant A 2. get_user_profile(user_id) → High engagement, premium buyer 3. get_variant_performance(variant_id="B") → Only 5% improvement Decision: Keep Variant A (confidence: 0.82, "Insufficient evidence to change")Amazon Bedrock 会根据每个用户的独特情况调整其数据收集。新用户触发相似性分析,而返回用户触发配置文件分析。一个边缘情况可能会触发所有工具。您不必编程此逻辑——Amazon Bedrock 会自行推理。
多因素推理综合
传统 ML 模型会产生预测,但没有解释。Amazon Bedrock 提供了一个综合多种因素的推理。
{
"variant_id": "B",
"confidence": 0.86,
"reasoning": "User's mobile device (small screen) strongly favors Variant B's shorter CTA. Similar mobile users show 23% higher conversion with B. User's high engagement score (0.83) suggests receptiveness to incentive messaging. Device constraints and behavioral alignment create strong signal for Variant B despite A's historical lead on desktop."
}
此推理结合了:
- 设备限制(技术因素)
- 类似用户模式(协同过滤)
- 个人参与度指标(行为因素)
- 历史表现(统计因素)
传统的 ML 模型可能会预测“Variant B:78% 概率”,但无法解释设备限制如何与类似用户模式相互作用来指导该预测。
处理边缘情况和冲突信号
当信号冲突时,Amazon Bedrock 会推理权衡:
Conflicting Signals Example: - Variant A: Higher aggregate conversion rate (4.2% vs 3.8%) - User: Premium customer (typically prefers professional styling) - Similar Users: Show 34% higher conversion with Variant B's social proof - Device: Desktop (both variants work well) Amazon Bedrock's Reasoning: "Despite Variant A's higher aggregate conversion rate, this premium customer's profile matches the 'social proof responsive' cluster (0.91 similarity). Similar premium users show 34% lift with social proof emphasis. The desktop device allows Variant B's richer testimonial display without performance penalty. Expected individual conversion probability: 0.78 vs 0.61 for Variant A." Decision: Variant B (confidence: 0.84)
零训练,即时适应
传统的 ML 需要:
- 历史训练数据收集(数周/数月)
- 特征工程和模型训练
- 随着模式变化进行定期再训练
- 对 ML 模型本身进行 A/B 测试
Amazon Bedrock 可立即生效:
- 第一天:利用现有数据的类似用户模式
- 第二天:从昨天的结果中学习
- 第三十天:基于累积的见解进行复杂个性化
- 您不需要再训练管道
实现深度解析
以下几部分将描述 AI 辅助引擎在后台的工作方式。
混合分配策略
新用户 → 基于哈希(成本效益高)
返回用户 → AI 驱动(高价值)
新用户:基于哈希的分配(快速,无 AI 成本)
if is_new_user:
user_hash = int(hashlib.sha256(user_id.encode()).hexdigest(), 16)
return variants[index]
对于返回用户,后端调用 Amazon Bedrock:
decision = bedrock_client.converse(
modelId="anthropic.claude-3-5-sonnet",
messages=[
{"role": "user", "content": [{"text": prompt}]}
],
toolConfig={"tools": mcp_registry.tools}
)
这种混合方法至关重要。新用户没有行为数据,因此 AI 分析提供的价值很小。基于哈希的分配赋予他们一致的体验,同时我们收集数据。在收集到行为信号后,AI 选择可以带来显著提升。
MCP 工具框架和执行
Model Context Protocol (MCP) 通过智能工具编排系统为 Amazon Bedrock 提供对您行为数据的结构化访问。Amazon Bedrock 不是将所有数据转储到提示中(成本高昂且速度慢),而是选择性地调用工具来收集所需的确切信息。这会创建一个多轮对话,在其中它请求数据、分析数据并做出决策。
工具执行的工作原理
每次 Amazon Bedrock 的响应可能包含一个工具调用。FastAPI 后端执行该工具,返回结果,然后继续对话:
if response.stopReason == "tool_use":
tool_name = tool_call["name"]
payload = tool_call["input"]
result = await mcp.execute(tool_name, payload)
messages.append({
"role": "user",
"content": [{"toolResult": result}]
})
此循环将继续,直到模型生成最终的决策 JSON。这种多轮对话允许 Amazon Bedrock 收集它所需的确切上下文,对其进行分析并做出决策。
关键 MCP 工具
工具 1:get_similar_users() – 协同过滤
使用基于集群的匹配查找行为模式相似的用户:
Algorithm: (1) Check user's similarity cluster, (2) Query DynamoDB for cluster members, (3) Calculate similarity scores, (4) Return top N similar users Similarity Score (0.0-1.0) calculated from: - Engagement score similarity (30%): Similar engagement levels - Interaction style match (20%): Same pattern (focused/explorer/decisive/casual) - Content preferences overlap (20%): Shared interests and content types - Conversion likelihood similarity (15%): Similar purchase probability - Visual preference match (15%): Same design preference (complex/balanced/minimal) Threshold: > 0.5 to be considered similar
工具 2:get_user_profile() – 行为指纹
从 DynamoDB PersonalizationProfile 表检索全面的行为配置文件:
Behavioral Signals: engagement_score, conversion_likelihood, cta_responsiveness, reading_depth, social_proof_sensitivity, urgency_sensitivity (all 0.0-1.0) Preferences: interaction_style (focused|explorer|decisive|casual), attention_span (long|medium|short), visual_preference (complex|balanced|minimal), content_preferences, preferred_content_length Performance Data: successful_variants, variant_performance mapping, confidence_score Device Context: device_type, visit_frequency Similarity Data: similarity_cluster, similar_user_ids
工具 3:get_variant_performance() – 实时指标
从 Experiment 表的 VariantPerformance 嵌套对象检索性能数据:
current_performance: impressions, clicks, conversions, conversion_rate (conversions/impressions), confidence (0.0-1.0), last_updated timestamp historical_data: Time-series performance aggregated from Events table metadata: experiment_id, variant_id, time_period_days, has_performance_data flag Note: The system stores metrics in the Experiment table and updates them as events occur
将 AI 见解存储回配置文件
每次变体选择后,系统都会记录结果以改进未来的决策:
profile.update({
"last_selected_variant": decision.variant_id,
"confidence_score": decision.confidence,
"behavior_tags": extracted_signals
})
dynamodb.put_item(
TableName="user_profile",
Item=profile.to_item()
)
随着时间的推移,系统记录了更多的结果,用户配置文件会变得越来越准确地反映个体偏好,从而使 Amazon Bedrock 能够做出更明智的变体选择。
理解置信度分数
每次 AI 决策都包含一个置信度分数 (0.0-1.0),这是 Amazon Bedrock 在其推理过程中生成的。该分数反映了系统根据可用数据对变体选择的确定性评估。
Amazon Bedrock 如何确定置信度:
Amazon Bedrock 在分配置信度时会评估多个因素:-
- 数据可用性 – 更多行为数据和历史性能 → 更高的置信度
- 信号一致性 – 用户配置文件、类似用户和性能数据之间的信号一致 → 更高的置信度
- 类似用户证据 – 具有一致偏好的较大类似用户集群 → 更高的置信度
- 统计显著性 – 满足显著性阈值的性能数据 → 更高的置信度
- 配置文件成熟度 – 具有丰富历史的成熟用户配置文件 → 更高的置信度
置信度分数是一个整体评估,而不是一个计算指标,因此它可以根据上下文灵活地权衡因素。
解释置信度分数:-
- 0.9–1.0:极其可靠 – 所有因素的有力证据
- 0.7–0.89:高置信度 – 良好的数据质量和一致的信号
- 0.5–0.69:中等 – 合理的数据但存在不确定性
- 0.3–0.49:低 – 数据有限或信号冲突
- < 0.3:非常低 – 数据不足,无法做出自信的预测
上下文丰富中间件
中间件会自动为每个请求添加设备和会话上下文:
user_agent = request.headers["user-agent"]
device = detect_device(user_agent)
referrer = classify_referrer(request.headers.get("referrer", ""))
user_context.device_type = device.type
user_context.referrer_type = referrer
这有助于验证 Amazon Bedrock 是否拥有丰富的上下文,而无需前端显式发送它。
基于零售场景的实际示例
让我们重新审视零售商的 CTA 测试——这次展示 Amazon Bedrock 的完整决策过程,包括实际的工具调用。
用户 1:移动端的忠诚度会员
初始上下文
- 设备:iPhone
- 忠诚度:高级忠诚度会员
- 浏览模式:快速,目标明确
- 推荐者:直接导航
- 过往购买:频繁
决策过程
Tool Call 1: get_user_assignment(user_id="user_001", experiment_id="cta_test_2024")
Response: No existing assignment exists
Tool Call 2: get_user_profile(user_id="user_001")
Response: { "engagement_score": 0.89, "conversion_likelihood": 0.24, "interaction_style": "focused", "attention_span": "short", "successful_variants": ["A", "simple_design"], "confidence_score": 0.87
}
Tool Call 3: get_similar_users(user_id="user_001", limit=5)
Response: { "count": 52, "avg_conversion_rate": 0.21, "preferred_variants": ["A"], "shared_characteristics": ["mobile", "loyalty_member", "focused_buyer"]
}
Tool Call 4: get_variant_performance(experiment_id="cta_test_2024", variant_id="A")
Response: { "current_performance": { "impressions": 3900, "clicks": 312, "conversions": 125, "conversion_rate": 0.032, "confidence": 0.89 }, "has_performance_data": true
}
Amazon Bedrock 评估数据并返回:
{
“variant_id”: “A”,
“confidence”: 0.86,
“reasoning”: “Strong alignment across multiple signals: (1) User profile shows 'focused' interaction style with short attention span, preferring streamlined experiences. (2) High profile confidence (0.87) from historical data. (3) 52 similar loyalty members on mobile strongly prefer Variant A (simple 'Buy Now'). (4) Variant A shows solid performance with 3.2% conversion rate and 125 conversions from 3,900 impressions. (5) Loyalty status means free shipping message is redundant. All signals point to concise CTA without incentive framing.”
}
用户 2:来自优惠券网站的首次访问者
初始上下文
- 设备:Android
- 无忠诚度状态
- 浏览模式:缓慢,侧重于比较
- 推荐者:优惠聚合网站
决策过程
Tool Call 1: get_user_assignment(user_id="user_002", experiment_id="cta_test_2024")
Response: No existing assignment found
Tool Call 2: get_user_profile(user_id="user_002")
Response: { "engagement_score": 0.15, "conversion_likelihood": 0.05, "confidence_score": 0.12 // Very low - new user }
Tool Call 3: get_similar_users(user_id="user_002", limit=10)
Response: { "count": 39, "avg_conversion_rate": 0.18, "preferred_variants": ["B"], "shared_characteristics": ["first_visit", "coupon_site_referrer", "deal_seeking"], "note": "Similar new users from deal sites show 2.3x higher conversion with incentive messaging"
}
Tool Call 4: get_variant_performance(experiment_id="cta_test_2024", variant_id="B")
Response: { "current_performance": { "impressions": 3850, "clicks": 385, "conversions": 158, "conversion_rate": 0.041, "confidence": 0.95 }, "has_performance_data": true
}
Amazon Bedrock 选择:
{
“variant_id”: “B”,
“confidence”: 0.91,
“reasoning”: “Despite low user profile confidence (0.12 - new user), strong contextual signals create high decision confidence: (1) Referrer source (RetailMeNot) indicates deal-seeking behavior. (2) 39 similar first-time visitors from coupon sites show strong preference for Variant B (incentive messaging). (3) Variant B shows strong performance with 4.1% conversion rate and 158 conversions from 3,850 impressions. (4) New user status means no prior variant preference to contradict. Context-driven decision leveraging similar user patterns compensates for lack of individual behavioral history.”
}
关键区别
用户 1(成熟的配置文件)
- 严重依赖个人行为历史(0.87 置信度)
- 类似用户得到确认,但未驱动决策
- 设备 + 忠诚度状态被视为关键因素
用户 2(新用户)
- 个人数据有限(0.12 置信度)
- 严重依赖类似用户模式(39 个类似用户)
- 推荐者上下文是决定性信号
- 通过强烈的上下文信号仍获得 0.91 的决策置信度
这展示了系统如何根据可用信息调整其数据收集策略——在有个人历史时使用,没有时则使用类似用户模式。
未来增强
该系统为高级个性化奠定了基础:
- 动态变体生成 – 不再是选择预定义的变体,而是使用 Amazon Bedrock 为每个用户生成自定义内容。想象一下,CTA 的消息、颜色和紧迫感会根据个体行为进行调整。
- 多臂老虎机 – 将 AI 个性化与老虎机算法结合,实现自动流量分配。在探索新选项的同时,将流量转移到获胜变体。
- 跨实验学习 – 在实验之间共享见解。如果用户在一个测试中对紧迫性消息反应良好,则自动将其应用于其他测试。
- 实时优化 – 使用 Amazon Kinesis 的流数据实时更新配置文件。在几秒钟而不是几分钟内响应用户行为。
- 高级细分 – 让 AI 通过聚类自动发现用户细分。不再需要手动创建细分——系统会自动找到您 ... [内容被截断]
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区