



📢 转载信息
原文作者:Vijay Velpula and Ram Vittal
在规模化构建和管理机器学习 (ML) 特征是现代数据科学工作流中最关键和最复杂的挑战之一。组织常常在碎片化的特征管道、不一致的数据定义以及跨团队的重复工程工作等方面遇到困难。如果没有一个用于存储和重用特征的集中式系统,模型就有可能在过时或不匹配的数据上进行训练,导致泛化能力差、模型准确性降低以及治理问题。此外,当每个团队维护自己的独立数据集和转换时,促进数据工程、数据科学和 ML 运维团队之间的协作变得困难。
Amazon SageMaker 通过 SageMaker Unified Studio 和 SageMaker Catalog 来应对这些挑战,组织可以使用它们来安全地跨项目和账户构建、管理和共享资产。该生态系统中的一项关键功能是实现离线特征存储——一个专为管理用于模型训练和验证的历史特征数据而设计的结构化存储库。离线特征存储旨在实现可扩展性、可追溯性和可重现性,以便数据科学家能够使用准确、时间对齐的数据集来训练模型,从而防止数据泄露并保持实验之间的一致性。
这篇博文提供了使用 SageMaker Catalog 在 SageMaker Unified Studio 域中实现离线特征存储的分步指南。通过采用发布-订阅模式,数据生产者可以使用此解决方案来发布经过精心整理、版本化的特征表——而数据消费者则可以安全地发现、订阅和重用它们进行模型开发。该方法将 Amazon S3 Tables 与 Apache Iceberg 集成以实现事务一致性,使用 AWS Lake Formation 进行细粒度访问控制,并利用 Amazon SageMaker Studio 进行可视化和基于代码的数据工程。
通过这一统一的解决方案,团队可以实现一致的特征治理,加速 ML 实验,并减少运营开销。在本文中,我们将展示如何设计一个协作、受治理且面向生产的离线特征存储,以实现企业范围内可信 ML 特征的重用。
解决方案概述
该解决方案演示了如何使用与 SageMaker Catalog 集成的 SageMaker Unified Studio 域来实现离线特征存储,从而为 ML 团队实现可扩展、受治理且协作式的特征管理。该架构建立了一个统一的环境(如下图所示),该环境简化了管理员、数据工程师和数据科学家创建、发布和使用高质量、可重用特征表的方式。
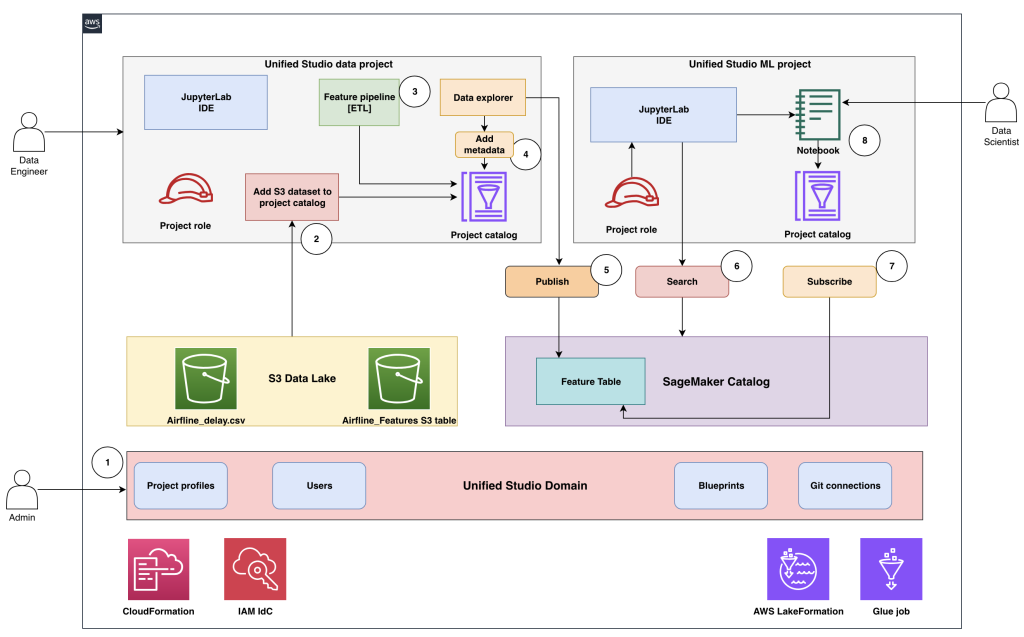
其核心是,该解决方案使用 SageMaker Unified Studio 域作为治理和协作层,用于在集中控制下管理项目、用户和数据资产。S3 Tables 以 Apache Iceberg 格式为存储和版本化特征数据奠定了基础。SageMaker Catalog 允许统一管理数据集,充当发布、发现和订阅特征表的中央注册中心。
以下描述了不同角色在端到端工作流中的交互方式:
- 管理员使用 AWS CloudFormation 模板和 AWS 管理控制台来设置和配置环境,包括预配 SageMaker Unified Studio 域以及引入用户和组。
- 管理员创建 SageMaker Unified Studio 数据项目,并将 Amazon Simple Storage Service (Amazon S3) 数据集(例如
airline_delay.csv和airline_features(一个 S3 表))引入项目目录,然后将数据工程师指定为项目所有者。 - 数据工程师打开数据项目,使用可视化提取、转换、加载 (ETL) 工具或数据处理作业来构建特征管道,并在项目目录中的
airline_features表中创建特征。 - 数据工程师使用数据浏览器工具来丰富
airline_features表,并添加元数据以提高可发现性和治理性。 - 在验证和批准后,数据工程师将
airline_features表发布到 SageMaker Catalog,以供全公司访问。 - 数据科学家打开 ML 项目,使用 AI 驱动的搜索在目录中查找
airlines_features表,并识别发布的特征表是否适合他们的模型开发。 - 数据科学家提交订阅请求以使用发布的特征表。如果未配置自动批准,发布者必须审查并批准访问请求。
- 批准后,数据科学家可以通过项目目录访问特征表,既可以通过数据浏览器访问,也可以直接从 Jupyter Notebook 访问,用于模型训练和实验。
这个结构化的工作流提供了持续的数据治理,促进了协作,并通过实现企业范围内可信、版本化的 ML 特征的重用,消除了重复的特征工程工作。
核心组件
离线特征存储解决方案架构由多个集成组件组成。每个组件在实现安全数据治理、可扩展特征工程以及跨 ML 角色的无缝协作方面都发挥着独特的作用。关键组件包括:
SageMaker Unified Studio 域:SageMaker Unified Studio 域作为管理 ML 项目、用户和数据资产的中央控制平面。它为数据工程师、数据科学家和管理员之间的协作提供了一个统一的界面。该域支持强制执行细粒度访问控制,与 AWS IAM Identity Center 集成以实现单点登录,并支持批准工作流,以确保跨团队和账户的安全 ML 资产共享。
带 Apache Iceberg 格式的 S3 Tables:S3 Tables 使用 Apache Iceberg 表格式为特征数据提供可扩展的无服务器存储。Apache Iceberg Open Table Format (OTF) 支持 ACID 事务、模式演进和时间旅行功能,团队可以利用这些功能以完全可重现的方式查询特征数据的历史版本。S3 Tables 与 Spark、Glue 和 SageMaker 无缝集成,可在分析和 ML 工作负载之间实现一致的数据访问。
特征工程管道:特征工程管道将原始数据集自动转换为经过精心整理的高质量特征。该管道基于 Apache Spark 构建,可在规模化提供分布式数据处理,实现延迟率计算、类别编码和特征聚合等复杂转换。管道直接将输出写入 S3 表,有助于确保原始/处理数据与工程特征之间的可追溯性和一致性。
SageMaker Catalog:SageMaker Catalog 作为组织范围内的存储库,用于注册、发布和发现 ML 资产,如数据集、特征表和模型。它与 Lake Formation 集成以进行细粒度访问控制,并与 IAM Identity Center 集成以进行用户管理。该目录支持元数据丰富、版本控制和审批工作流,使团队能够跨项目安全地共享和重用受信任的资产。
这些组件共同创建了一个紧密结合的生态系统,可简化 ML 特征的生命周期管理(从创建、发布到发现和使用),同时维护企业级治理和数据沿袭跟踪。
管理员工作流
管理员工作流定义了建立安全协作环境以实现离线特征存储所需的初始设置。管理员负责预配 SageMaker Unified Studio 域,启用 IAM Identity Center 进行用户身份验证,并使用 Lake Formation 配置 S3 表以进行受控数据访问。他们还创建专门的生产者和消费者项目,通过环境蓝图(基于 CloudFormation)部署必要的基础设施,并分配具有适当权限的用户和组。此设置有助于确保数据工程师和数据科学家可以在 SageMaker Unified Studio 中无缝构建、发布和使用 ML 特征的一致、受良好治理的基础。
先决条件
必须完成以下先决条件,以确保正确设置所需 AWS 服务和权限,从而实现无缝集成和治理。
- 启用 IAM Identity Center
- 在控制台中导航到 IAM Identity Center。
- 如果尚未激活,请选择启用。
- 选择使用 AWS Organizations 启用或独立启用,并完成设置向导。
- 启用 S3 Tables
- 在控制台中转到 Amazon S3。
- 选择S3 Tables 部分,然后选择启用 S3 Tables 集成。
- Lake Formation 管理员
- 验证控制台角色是否已添加到 Lake Formation 管理员,以便进行适当的资源创建和权限管理。
设置环境
完成先决条件后,下一步是通过创建和配置 SageMaker Unified Studio 域来设置环境,该域是管理离线特征存储架构中用户、项目和数据资产的中心工作区。
设置 SageMaker Unified Studio 域:
- 导航到 SageMaker Unified Studio 控制台,然后在导航窗格中选择域。选择创建域,然后选择快速设置。
- 选择创建新的 VPC 或选择现有的 VPC 来配置域网络。
- 展开快速设置,然后输入域名称(例如,
Corporate)。 - 对于域执行角色和域服务角色,选择创建并使用新服务角色。
- 选择一个 VPC(标记为
SageMaker Unified Studio的 VPC 应正确配置),并选择至少三个私有子网,每个子网位于不同的可用区。 - 选择继续以继续进行域创建。
- 通过提供电子邮件地址、名字和姓氏来创建IAM Identity Center 用户帐户(您将在创建后收到一封激活 IAM Identity Center 帐户的电子邮件)。
- 选择创建域以开始域创建过程。域创建通常需要 2-5 分钟才能完成。
创建 SageMaker Unified Studio 项目:
- 转到 SageMaker Unified Studio 域 URL,并使用域设置期间创建的 IAM Identity Center 凭据登录,如果收到邀请电子邮件,请接受它。
- 创建项目:
- 从域主页选择创建项目,以创建生产者项目并命名为
airlines_core_features。添加描述,配置设置,并分配用户和权限。 - 对于项目配置文件,选择所有功能。
- 重复前面的两个步骤,创建一个名为
airlines_ml_models的消费者项目。
注意:项目创建通常需要 5-10 分钟才能完成。
- 从域主页选择创建项目,以创建生产者项目并命名为
- 复制项目角色 ARN
- 导航到
airlines_core_features项目详细信息。 - 导航到项目并复制项目角色 Amazon 资源名称 (ARN)(
arn:aws:iam::ACCOUNT:role/datazone_usr_role_*) - 为
airlines_ml_models重复前面的两个步骤
- 导航到
基础设施部署
仅在完成前面的步骤(包括域创建、项目创建、IAM Identity Center 设置和 S3 Tables 启用)后,才部署 CloudFormation 堆栈。堆栈需要以下输入参数:
- IAM Identity Center ID:导航到 IAM Identity 控制台以检索 AWS 访问门户 URL 的第一部分。它将显示为
https://d-1234da5678.awsapps.com/start - SMUSProducerProjectRoleName:导航到 Unified Studio 项目门户,打开您的生产者项目,然后检索项目角色名称。例如,
arn:aws:iam::<account-id>:role/datazone_usr_role_xxxx_yyyy - SMUSConsumerProjectRoleName:重复上一步以检索消费者项目角色名称。

堆栈成功部署后,将创建以下 AWS 资源:
- S3 存储桶:用于原始和已处理数据存储,例如
amzn-s3-demo-blog-smus-featurestore-{account-id} - S3 表存储桶:用于 Iceberg 表存储,例如
amzn-s3-demo-airlines-s3tables-bucket - S3 表命名空间:组织化的特征表命名空间,例如
airlines - S3 表:用于特征存储,例如
fg_airline_features - Glue 数据库:用于源数据目录,例如
airline_raw_db - IAM Identity Center 组:生产者和消费者组,例如
FeatureStore-Producers, FeatureStore-Consumers - Lake Formation 权限:细粒度访问控制,例如
数据库和表权限 - IAM 角色和策略:用于服务集成,例如 SageMaker 执行角色。
将 SSO 组添加到 SageMaker 域
为 SageMaker 域分配用于单点登录 (SSO) 的 IAM Identity Center 组,以启用用户在项目之间的访问和协作。
- 导航到 SageMaker Unified Studio 控制台,然后在导航窗格中选择域。
- 转到用户管理。
- 选择添加用户和组以管理域访问。
- 选择SSO 组。
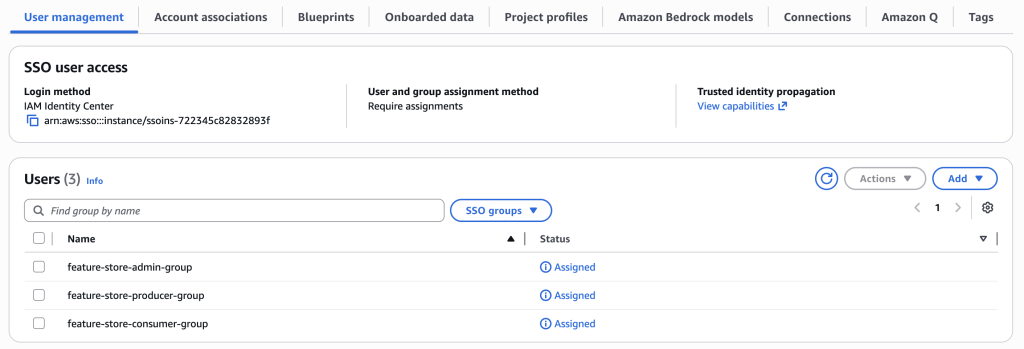
- 选择在基础设施部署期间创建的 SSO 组:
feature-store-admin-group(用于管理员)feature-store-producer-group(用于数据工程团队)feature-store-consumer-group(用于数据科学团队)
- 选择添加以完成分配并启用组访问
- 用户管理部分将显示 SSO 组为已分配。
创建 IAM Identity Center 用户
为数据生产者、消费者和管理员创建单独的用户以访问 SageMaker 域。
创建数据生产者用户:
- 导航到 IAM Identity Center 控制台,然后在导航窗格中选择用户。
- 选择添加用户,输入用户详细信息:
- 用户名:输入
dataproducer。 - 电子邮件:输入有效地址,例如
dataproducer@example.com. - 名字:输入
Data。 - 姓氏:输入
Producer。 - 将用户分配给
feature-store-producer-group.
- 用户名:输入
- 发送邀请电子邮件以激活帐户。
创建数据消费者和管理员用户:
使用相同的步骤创建数据消费者和管理员用户,但第 2 步略有不同:
- 创建数据消费者用户:
- 用户名:输入
dataconsumer。 - 电子邮件:输入有效地址,例如
dataconsumer@example.com. - 名字:输入
Data。 - 姓氏:输入
Consumer。 - 将用户分配给 f
eature-store-consumer-group。
- 用户名:输入
- 创建管理员用户:
- 用户名:输入
dataadmin。 - 电子邮件:输入有效地址,例如
dataadmin@example.com。 - 名字:输入
Data。 - 姓氏:输入
Admin。 - 将用户分配给
feature-store-admin-group。
- 用户名:输入
将用户组添加到项目
以管理员身份登录 SageMaker Unified Studio 企业域(使用 UI 控制台),并将用户组分配给他们相应的项目以实现正确的访问控制。
将用户分配给生产者项目:
- 导航到
airlines_core_features项目设置。 - 转到成员部分。
- 添加
feature-store-producer-group并授予适当的项目权限。
将用户分配给消费者项目:
- 导航到 airlines_ml_models 项目设置。
- 转到成员部分
- 添加
feature-store-consumer-group并授予适当的项目权限。
将数据集上传到 S3 存储桶
在 CloudFormation 模板创建的 S3 存储桶 amzn-s3-demo-blog-smus-featurestore-<account-id> 中创建 S3 前缀 /raw/AirlineDelayCause/。使用 Amazon S3 控制台将示例 航空延误数据集 上传到 S3 存储桶前缀 s3://amzn-s3-demo-blog-smus-featurestore-<account-id>/raw/AirlineDelayCause/
验证数据访问
上传数据集后,导航到 airlines_core_features 项目并使用 AWS Data Catalog 查询数据:
SELECT * FROM "awsdatacatalog"."curated_db"."airline_delay_cause" LIMIT 10;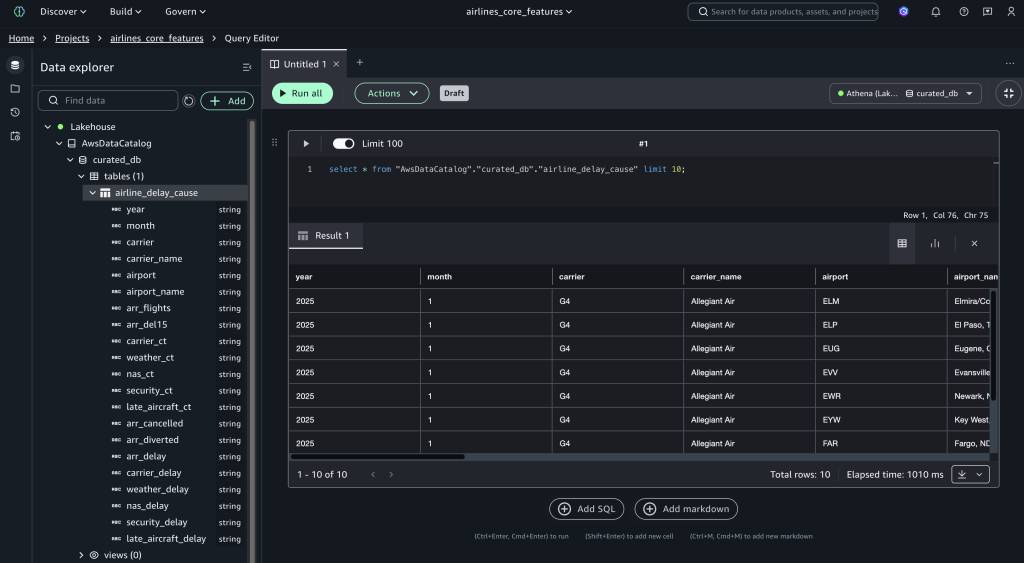
验证特征存储表
查询特征存储表以验证其是否可访问。它将返回零记录,但不应出现错误。
SELECT * FROM "s3tablescatalog/airline"."airline"."fg_airline_features" LIMIT 10;
数据工程师工作流
此工作流演示了数据工程师如何使用 SageMaker Unified Studio 和 S3 Tables 创建和共享特征。
以数据生产者用户身份登录
导航到 SageMaker Unified Studio 域,并使用 dataproducer 用户(feature-store-producer-group 的成员)的 IAM Identity Center 凭据登录,然后访问 airlines_core_features 项目。
创建特征工程作业
- 将 airlines-delay-cause-feature-engineering-pipeline 脚本下载到您的本地系统。
- 导航到构建工具,然后选择数据处理作业。
- 选择 airlines_core_features 项目,然后选择继续。
- 转到基于代码的作业部分,然后选择从文件创建作业。
- 选择文件,然后选择上传本地文件。选择文件,然后选择下一步。
- 将
airlines-delay-cause-feature-engineering-pipeline作为作业名称输入,然后选择提交。 - 选择创建的作业,然后选择运行作业以运行管道。
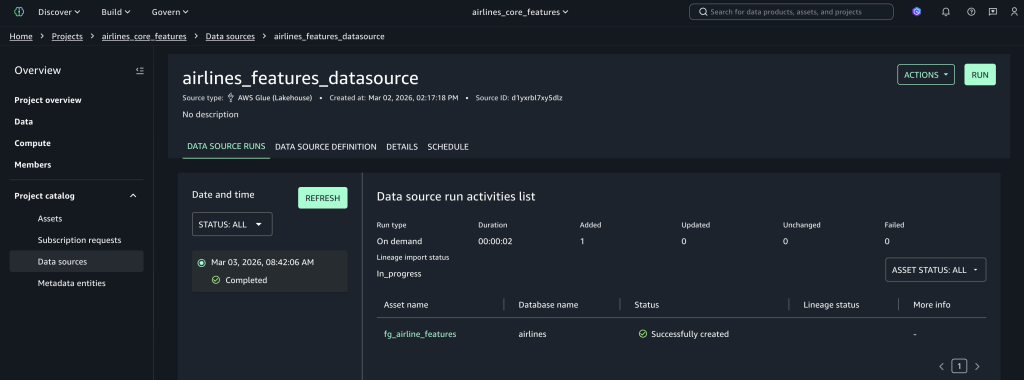
创建数据源连接
- 导航到数据源。
- 选择创建数据源。
- 对于数据源名称,输入
airlines_features_datasource。 - 对于数据源类型,选择AWS Glue Data Catalog。
- 转到数据选择,并将目录名称输入为
s3tablescatalog/airlines。 - 对于数据库名称,从下拉列表中选择 airlines。
- 将表选择条件设置为
*,然后选择下一步。 - 在将资产发布到目录中,选择否,然后选择下一步。
- 将运行首选项设置为按需,然后选择下一步。
- 选择创建以创建数据源并发现表。
发布特征资产
- 转到资产,然后选择由数据源作业创建的
fg_airline_features资产。 - 选择发布资产,添加元数据和描述,并完成发布以使其在各项目中可发现。
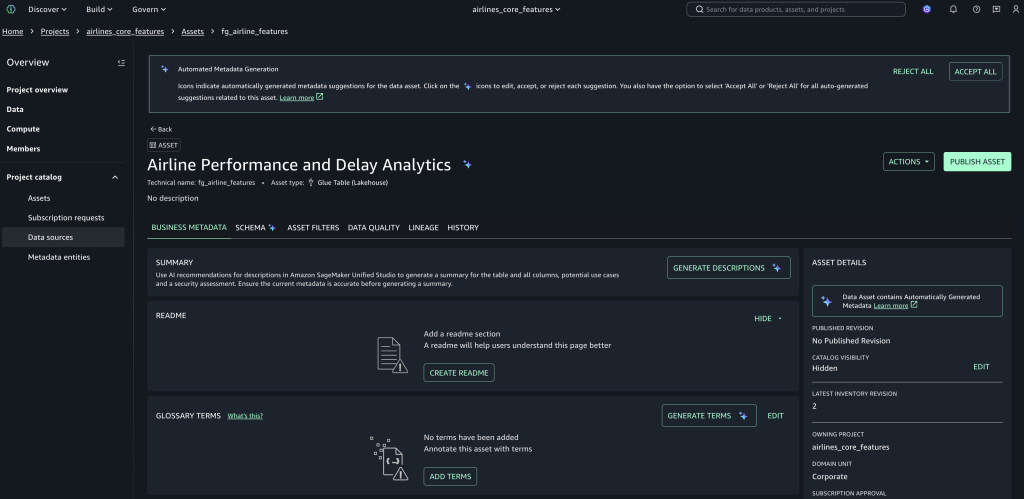
验证特征存储
查询创建的由数据处理作业加载的特征存储。
- 从构建工具下拉菜单打开查询编辑器。
- 将连接设置为 s3tables 目录,然后运行以下查询:
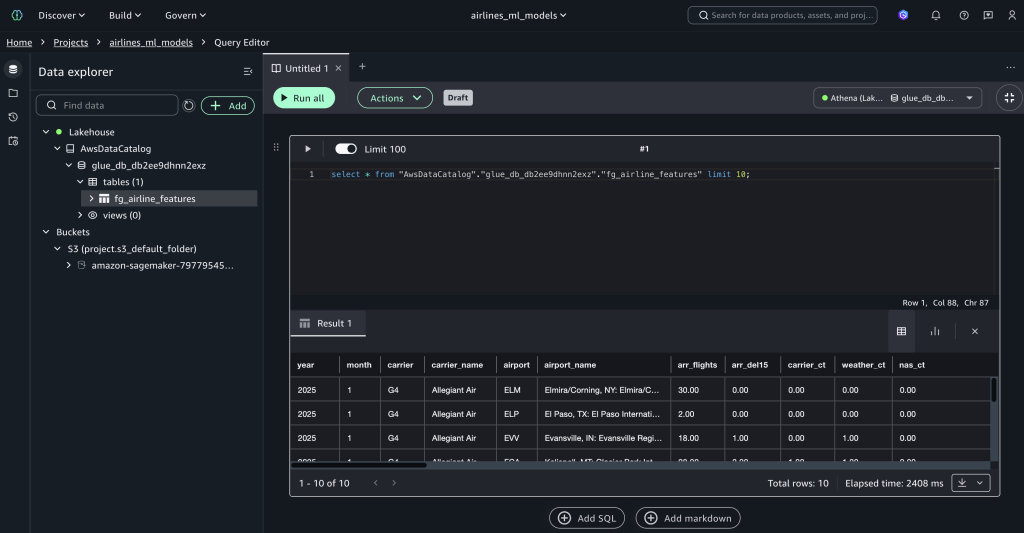
SELECT * FROM "s3tablescatalog/airlines"."airlines"."fg_airline_features" LIMIT 10;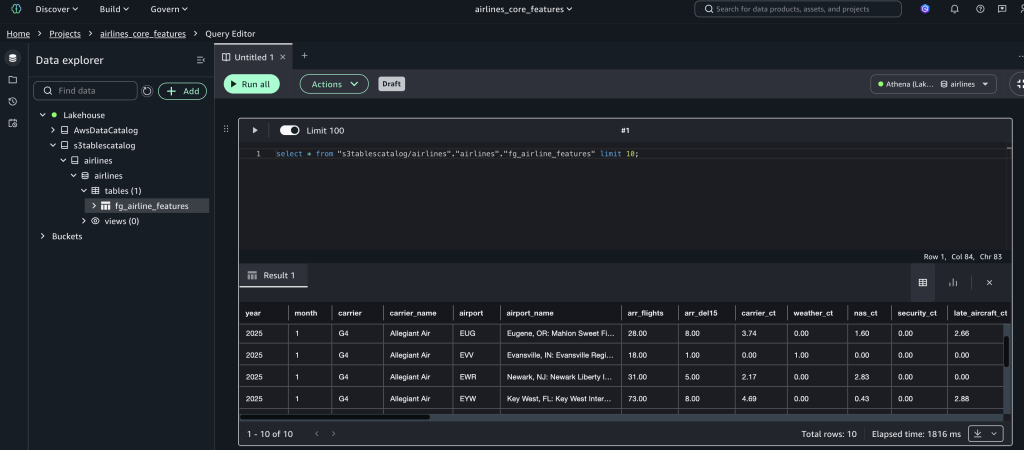
现在,其他项目将可以发现此特征存储表。
数据科学家工作流
本节演示了数据科学家使用 S3 Tables 和 SageMaker Unified Studio 构建的离线特征存储的端到端机器学习工作流,从 dataconsumer 用户登录开始。
以数据消费者用户身份登录
导航到 SageMaker Unified Studio 域 URL,使用数据消费者凭据登录,并选择消费者项目 airlines_ml_models。
搜索特征
使用搜索栏输入 fg_airlines_features 作为特征存储名称来查找已发布的资产,然后选择 fg_airlines_features 目录资产。您还可以使用 AI 驱动的目录搜索,通过特征的名称和描述的片段来查找特征。
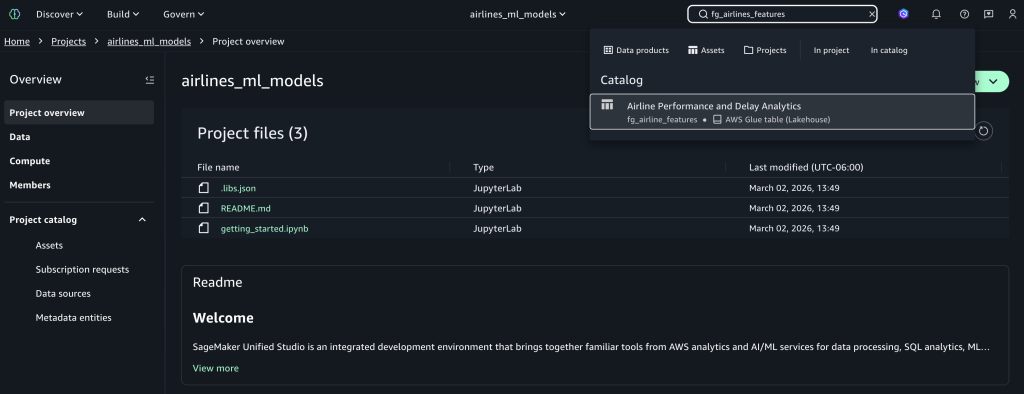
订阅资产
选择已选定的航空特征资产,输入用于 ML 模型开发的业务理由,然后提交访问请求以供批准。
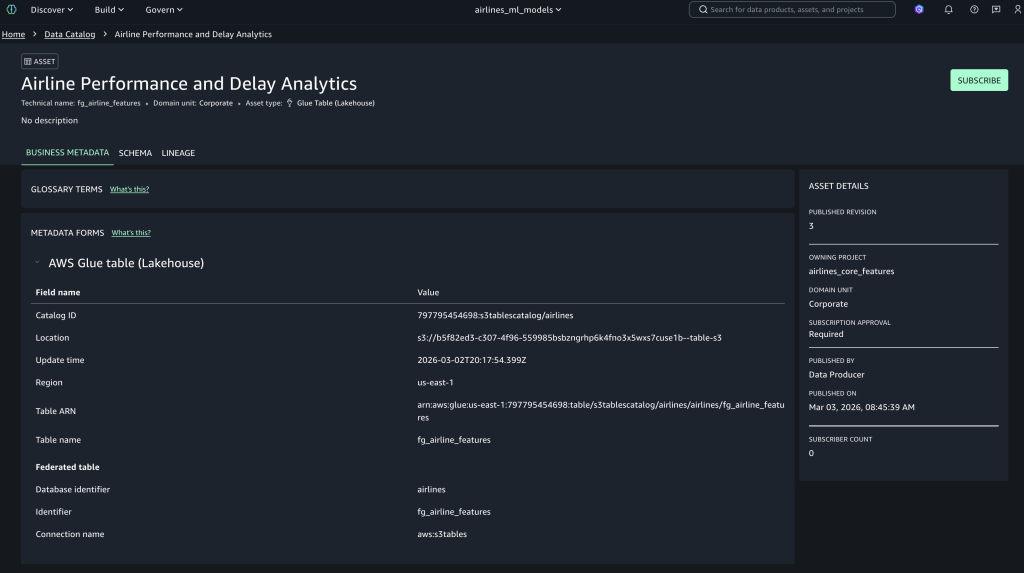
访问已批准的资产
数据生产者用户可以在其工作流中查看待处理的订阅请求。当订阅获得数据生产者的批准时,fg_airline_featurestore 表将在项目目录数据库中可见,并可供查询,如下图所示。
数据沿袭跟踪
SageMaker Catalog 中的数据沿袭是一项符合 OpenLineage 标准的功能,您可以使用它来捕获和可视化沿袭事件(来自支持 OpenLineage 的系统或通过 API),以跟踪数据来源、转换过程以及查看跨组织的数据使用情况。要查看数据沿袭,请选择沿袭选项卡以显示已订阅资产的完整沿袭,如下图所示。

🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区