



📢 转载信息
原文作者:Zohreh Norouzi, Aayushi Garg, Melanie Li, Saurabh Trikande, Jayadev Vadakkanmarveettil, and James Zheng
当组织在 Amazon Bedrock 上扩展其生成式 AI 工作负载时,对推理性能和资源消耗的运行可见性变得至关重要。运行延迟敏感型应用程序的团队必须了解模型生成响应的速度。管理高吞吐量工作负载的团队必须了解其请求如何消耗配额,以便避免意外的限流。到目前为止,获得这种可见性需要自定义客户端端检测或在问题发生后进行被动故障排除。
今天,我们为 Amazon Bedrock 发布了两个新的 Amazon CloudWatch 指标:TimeToFirstToken 和 EstimatedTPMQuotaUsage。这些指标为您提供流式传输延迟和配额消耗的服务器端可见性。这些指标会自动为每个成功的推理请求发出,无需额外费用,无需 API 更改或选择加入。它们现已在 AWS/Bedrock CloudWatch 命名空间中提供。
本文将介绍以下内容:
- 为什么了解时间到第一令牌延迟和配额消耗对生产 AI 工作负载至关重要
- 新的 TimeToFirstToken 和 EstimatedTPMQuotaUsage 指标如何工作
- 如何开始使用这些指标来设置警报、建立基线和主动管理容量。
Amazon Bedrock 已提供一组 CloudWatch 指标来帮助您监控推理工作负载。AWS/Bedrock 命名空间包含 Invocations、InvocationLatency、InvocationClientErrors、InvocationThrottles、InputTokenCount 和 OutputTokenCount 等指标。这些指标提供了对请求量、端到端延迟、错误率和令牌使用的可见性。这些指标在 Converse、ConverseStream、InvokeModel 和 InvokeModelWithResponseStream API 中均可用,并且可以按 ModelId 维度进行筛选。虽然这些指标提供了强大的运行基础,但它们留下了两个重要的空白:它们没有捕获流式响应开始的速度(时间到第一令牌),也没有反映请求在考虑令牌燃尽乘数后实际消耗的配额。今天宣布的两个新指标恰好弥补了这些空白。
生产 AI 推理工作负载的可观测性需求
在流式推理应用程序(如聊天机器人、编码助手或实时内容生成)中,模型返回第一个令牌所需的时间直接影响感知响应速度。第一个令牌的延迟直接影响应用程序的感知响应能力,即使整体吞吐量保持在可接受的范围内。然而,测量这个服务器端指标以前需要您在 API 调用周围仪表化您的应用程序代码以捕获时间戳。这增加了复杂性,并可能引入不反映实际服务端行为的测量不准确性。
配额管理提出了一个不同但同样重要但同样重要的挑战。Amazon Bedrock 为某些模型应用 令牌燃尽乘数。这意味着请求实际消耗的配额可能与您在计费指标中看到的原始令牌计数不同。例如,Anthropic Claude 模型,包括 Claude Sonnet 4.6、Claude Opus 4.6、Claude Sonnet 4.5 和 Claude Opus 4.5,对输出令牌应用 5 倍燃尽乘数用于配额目的。这意味着生成 100 个输出令牌的请求实际上会消耗您每分钟令牌 (TPM) 配额的 500 个令牌。您仅根据实际令牌使用量计费。如果没有对此计算的可见性,限流可能会显得不可预测,从而难以设置适当的警报或提前规划容量增加。对于使用 跨区域推理配置文件的客户,这些挑战会加剧,因为您需要每个推理配置文件的可见性来了解跨地理和全局配置的性能和消耗。
了解新引入的指标
下图显示了每个指标在流式推理请求生命周期中的捕获位置。
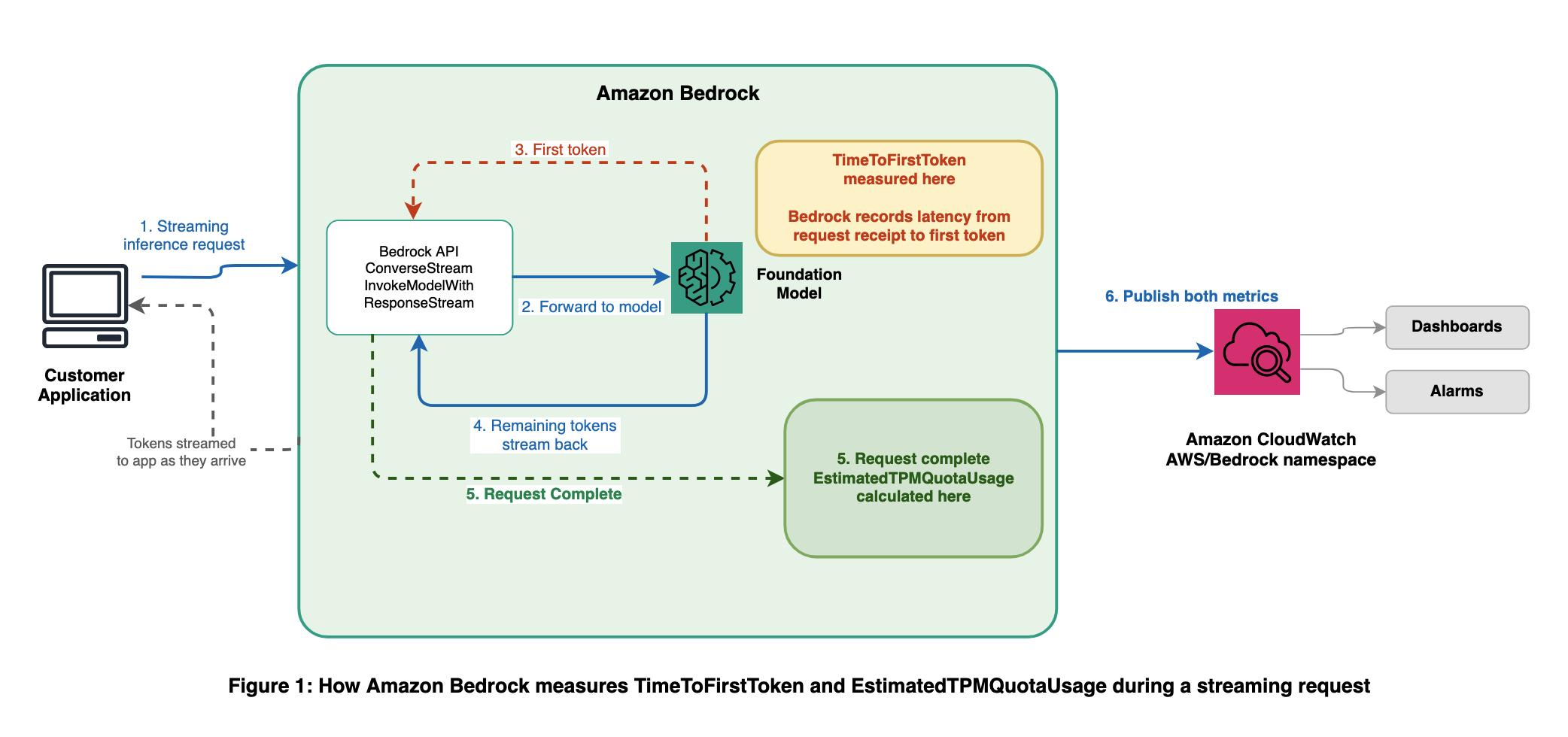
TimeToFirstToken:
TimeToFirstToken 指标衡量从 Amazon Bedrock 收到流式请求到服务生成第一个响应令牌的延迟(以毫秒为单位)。此指标针对流式 API 发出:ConverseStream 和 InvokeModelWithResponseStream。由于此指标是在服务器端测量的,因此它反映了实际的服务端延迟,而没有网络条件或客户端处理的干扰。
通过此指标,您可以:
- 设置延迟警报 – 创建 CloudWatch 警报,在 time-to-first-token 超过可接受阈值时通知您,以便您在性能下降影响用户之前检测到它。
- 建立 SLA 基线 – 分析跨模型的历史 TimeToFirstToken 数据,为您的应用程序设置知情的性能基线。
- 诊断性能问题 – 将 TimeToFirstToken 与其他 Amazon Bedrock 指标(如 InvocationLatency (Time to Last Token))相关联,以隔离延迟问题是源于初始模型响应时间还是整体请求处理。
该指标使用 ModelId 维度发布,可选维度包括 ServiceTier 和 ResolvedServiceTier。对于跨区域推理配置文件,ModelId 对应于您的推理配置文件标识符(例如,us.anthropic.claude-sonnet-4-5-v1),因此您可以单独监控每个配置文件的 TimeToFirstToken。此指标仅针对成功完成的流式请求发出。
EstimatedTPMQuotaUsage:
EstimatedTPMQuotaUsage 指标跟踪请求估计消耗的每分钟令牌 (TPM) 配额。与原始令牌计数不同,此指标考虑了 Amazon Bedrock 在评估配额消耗时使用的因素,包括缓存写入令牌和 输出令牌燃尽乘数。指标名称包含“Estimated”(估计),以反映它为监控和容量规划提供了配额消耗的近似值。Amazon Bedrock 的内部限流决策基于实时计算,可能与此指标略有不同,但 EstimatedTPMQuotaUsage 旨在为您提供可靠、可操作的信号。它应该足够准确,可以自信地设置警报、跟踪消耗趋势和规划配额增加。此指标在所有推理 API 中发出,包括 Converse, InvokeModel, ConverseStream, 和 InvokeModelWithResponseStream。
了解配额消耗公式:
估计配额消耗的计算公式取决于您的吞吐量类型:
按需推理:
EstimatedTPMQuotaUsage = InputTokenCount + CacheWriteInputTokens + (OutputTokenCount × burndown_rate)
燃尽率因模型而异——有关模型及其适用费率的完整列表,请参阅 用于配额管理的令牌燃尽乘数。对于按需推理,缓存读取令牌不计入配额。
例如,Claude Sonnet 4.5 的输出令牌有 5 倍燃尽率。一个具有 1,000 个输入令牌、200 个缓存写入令牌和 100 个输出令牌的按需请求消耗 1,000 + 200 + (100 × 5) = 1,700 个配额令牌。这比您仅从原始令牌计数中估计的要多 400 个。
预置吞吐量(保留层):
EstimatedTPMQuotaUsage = InputTokenCount + (CacheWriteInputTokens × 1.25) + (CacheReadInputTokens × 0.1) + OutputTokenCount
对于预置吞吐量,输出令牌的燃尽乘数不适用。但是,缓存读取令牌按 0.1 的费率计费,缓存写入令牌按 1.25 的权重计费。
请注意,计费与配额使用不同——您根据实际令牌使用量计费,而不是根据燃尽调整或加权金额。有关更多详细信息,请参阅 用于配额管理的令牌燃尽乘数。
有了这个指标,您可以:
- 设置主动配额警报 – 创建 CloudWatch 警报,当您的估计配额使用量接近 TPM 限制时触发,这样您就可以在请求被限流之前采取行动。
- 跨模型跟踪消耗 – 比较不同模型之间的配额使用情况,以了解哪些工作负载消耗的容量最多并进行相应优化。
- 规划配额增加 – 使用历史消耗趋势在您的使用增长导致限流之前,通过 AWS 服务配额请求配额增加。
指标维度和筛选
这两个指标都具有以下特征:
指标包括 ModelId 等维度,允许您按模型筛选和聚合数据。当您使用跨区域推理配置文件时(无论是地理区域的(例如,us.anthropic.claude-sonnet-4-5-v1)还是全局的(例如,global.anthropic.claude-sonnet-4-5-v1)),ModelId 维度对应于您的推理配置文件标识符。这意味着您可以查看每个跨区域推理配置文件和模型组合的独立指标。这使您可以精细地了解跨推理配置的性能和消耗。
这与现有的 Amazon Bedrock CloudWatch 指标(如 Invocations、InvocationLatency 和令牌计数指标)一致。
| 属性 | TimeToFirstToken | EstimatedTPMQuotaUsage |
| CloudWatch 命名空间 | AWS/Bedrock | AWS/Bedrock |
| 单位 | 毫秒 | 计数 |
| 支持的 API | ConverseStream, InvokeModelWithResponseStream | Converse, InvokeModel, ConverseStream, InvokeModelWithResponseStream |
| 更新频率 | 1 分钟聚合 | 1 分钟聚合 |
| 范围 | 成功完成的请求 | 成功完成的请求 |
| 主要维度 | ModelId |
ModelId |
| 可选维度 | ServiceTier, ResolvedServiceTier |
ServiceTier, ResolvedServiceTier, ContextWindow(对于超过 200K 令牌的输入上下文) |
| 支持的推理类型 | 跨区域推理(地理和全局)、区域内推理 | 跨区域推理(地理和全局)、区域内推理 |
开始使用
这些指标已经在您的 CloudWatch 控制台中可用。当您的应用程序调用 Amazon Bedrock 推理 API 时,服务会处理请求、调用模型,并将所有适用的指标(包括 TimeToFirstToken 和 EstimatedTPMQuotaUsage)发布到您 CloudWatch 账户的 AWS/Bedrock 命名空间。然后,您可以使用 CloudWatch 控制台、警报和指标数学来监控、警报和分析这些指标。请完成以下步骤开始使用它们:
- 打开 Amazon CloudWatch 控制台并导航到 Metrics > All metrics。
- 选择 AWS/Bedrock 命名空间。
- 查找 TimeToFirstToken 或 EstimatedTPMQuotaUsage 指标,并按
ModelId进行筛选以查看特定模型的数据。 - 创建警报以接收有关延迟下降或配额使用接近限制的通知。
发起推理请求并观察新指标
要生成指标数据点,请向 Amazon Bedrock 发起推理请求。以下示例使用 AWS SDK for Python (Boto3) 来演示非流式请求(它会发出 EstimatedTPMQuotaUsage)和流式请求(它会同时发出 EstimatedTPMQuotaUsage 和 TimeToFirstToken)。
在这些示例中,我们使用 us-east-1 作为 AWS 区域,使用 us.anthropic.claude-sonnet-4-6-v1 作为跨区域推理配置文件。请将其替换为您自己的区域和模型或推理配置文件 ID。
Converse(非流式)
以下示例使用 Converse API。此非流式调用在 CloudWatch 中的 AWS/Bedrock 命名空间下发出 EstimatedTPMQuotaUsage 指标。
import boto3
bedrock = boto3.client('bedrock-runtime', region_name='us-east-1')
response = bedrock.converse(
modelId='us.anthropic.claude-sonnet-4-6-v1',
messages=[
{
'role': 'user',
'content': [
{
'text': 'What is the capital of France?'
}
]
}
]
)
print(response['output']['message']['content'][0]['text'])
print(f"Input tokens: {response['usage']['inputTokens']}")
print(f"Output tokens: {response['usage']['outputTokens']}")ConverseStream(流式)
以下示例使用 ConverseStream API。此流式调用在 CloudWatch 中发出 EstimatedTPMQuotaUsage(值为 double)用于配额消耗,以及 TimeToFirstToken(值为毫秒),衡量从请求到第一个流式令牌的延迟。
import Boto3
bedrock = boto3.client('bedrock-runtime', region_name='us-east-1')
response = bedrock.converse_stream(
modelId='us.anthropic.claude-sonnet-4-6-v1',
messages=[
{
'role': 'user',
'content': [
{
'text': 'What is the capital of France?'
}
]
}
]
)
for event in response['stream']:
if 'contentBlockDelta' in event:
print(event['contentBlockDelta']['delta']['text'], end='')
print()
相同的指标也针对 InvokeModel(非流式)和 InvokeModelWithResponseStream(流式)API 发出。下表总结了每个 API 发出的指标:
| API | 发出的指标 |
| Converse | EstimatedTPMQuotaUsage |
| ConverseStream | EstimatedTPMQuotaUsage, TimeToFirstToken |
| InvokeModel | EstimatedTPMQuotaUsage |
| InvokeModelWithResponseStream | EstimatedTPMQuotaUsage, TimeToFirstToken |
发起这些请求后,请等待大约 1-2 分钟让指标显示出来,然后导航到 CloudWatch 控制台的 Metrics > All metrics > AWS/Bedrock,以验证您模型的可用数据点。
使用 AWS CLI 查询指标
您可以使用 AWS CLI 来验证新指标是否可用并检索它们的值。首先,确认指标正在为您的模型发布:
# List available TimeToFirstToken metrics
aws cloudwatch list-metrics --namespace AWS/Bedrock --metric-name TimeToFirstToken
# List available EstimatedTPMQuotaUsage metrics
aws cloudwatch list-metrics --namespace AWS/Bedrock --metric-name EstimatedTPMQuotaUsage结论
借助新的 TimeToFirstToken 和 EstimatedTPMQuotaUsage CloudWatch 指标,Amazon Bedrock 为您提供了运行生产生成式 AI 工作负载所需的信心和可观测性。关键要点:
- 在服务器端测量流式延迟 – TimeToFirstToken 提供准确的服务器端流式 API 延迟测量,无需任何客户端检测。
- 了解真实的配额消耗 – EstimatedTPMQuotaUsage 反映了您请求的估计配额影响,包括燃尽乘数,因此您可以预测和防止限流。
- 无需采取行动即可开始 – 这两个指标均免费自动发出。打开您的 CloudWatch 控制台即可开始使用。
- 设置主动警报 – 使用这些指标创建警报,以便在性能问题和配额压力影响您的应用程序之前捕获它们。
立即打开您的 Amazon CloudWatch 控制台,探索这些新指标,并为您工作负载的需求设置量身定制的警报。
有关更多信息,请参阅以下资源:
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区