



📢 转载信息
原文链接:https://machinelearningmastery.com/the-complete-ai-agent-decision-framework/
原文作者:Vinod Chugani
在本文中,您将学习一种实用、可重复的方法,为您的特定问题、团队和生产需求选择正确的人工智能智能体框架和编排模式。
我们将涵盖的主题包括:
- 一个三问决策框架,用于快速缩小选择范围。
- 流行智能体框架的并排比较。
- 将问题映射到模式和技术栈的端到端用例。
话不多说,让我们开始吧。
完整的AI智能体决策框架
图片作者:Vinod Chugani
您已经了解了 LangGraph、CrewAI 和 AutoGen。您理解 ReAct、规划与执行(Plan-and-Execute) 和 反思(Reflection) 模式。但是,当您坐下来构建时,会遇到一个真正的问题:“对于我的特定问题,我应该使用哪个框架?哪种模式?我如何确定我做出了正确的选择?”
本指南为您提供了一个系统的框架来做出这些决策。无需猜测。
三问决策框架
在编写任何代码之前,请回答这三个问题。它们会将您的选择从数十种可能性缩小到一个明确推荐的路径。
问题 1:您的任务复杂度如何?
简单任务涉及带有清晰输入和输出的直观工具调用。例如,检查订单状态的聊天机器人就属于此类。复杂任务则需要跨多个步骤进行协调,例如从头开始生成研究报告。注重质量的任务需要精炼循环,其中准确性比速度更重要。
问题 2:您的团队能力如何?
如果您的团队缺乏编码经验,像 Flowise 这样的可视化构建器或 n8n 是合理的选择。熟悉 Python 的团队可以使用 CrewAI 进行快速开发,或使用 LangGraph 进行精细控制。勇于探索前沿的研发团队可能会选择 AutoGen 来构建实验性的多智能体系统。
问题 3:您的生产需求是什么?
原型阶段优先考虑速度而非完善度。CrewAI 可以快速实现目标。生产系统需要可观测性、测试和可靠性。LangGraph 可以提供这些,包括通过 LangSmith 提供的可观测性。企业级部署要求安全性和集成性。Semantic Kernel 则适合微软生态系统。
以下是这三个问题如何引导您找到正确的框架和模式的可视化表示:
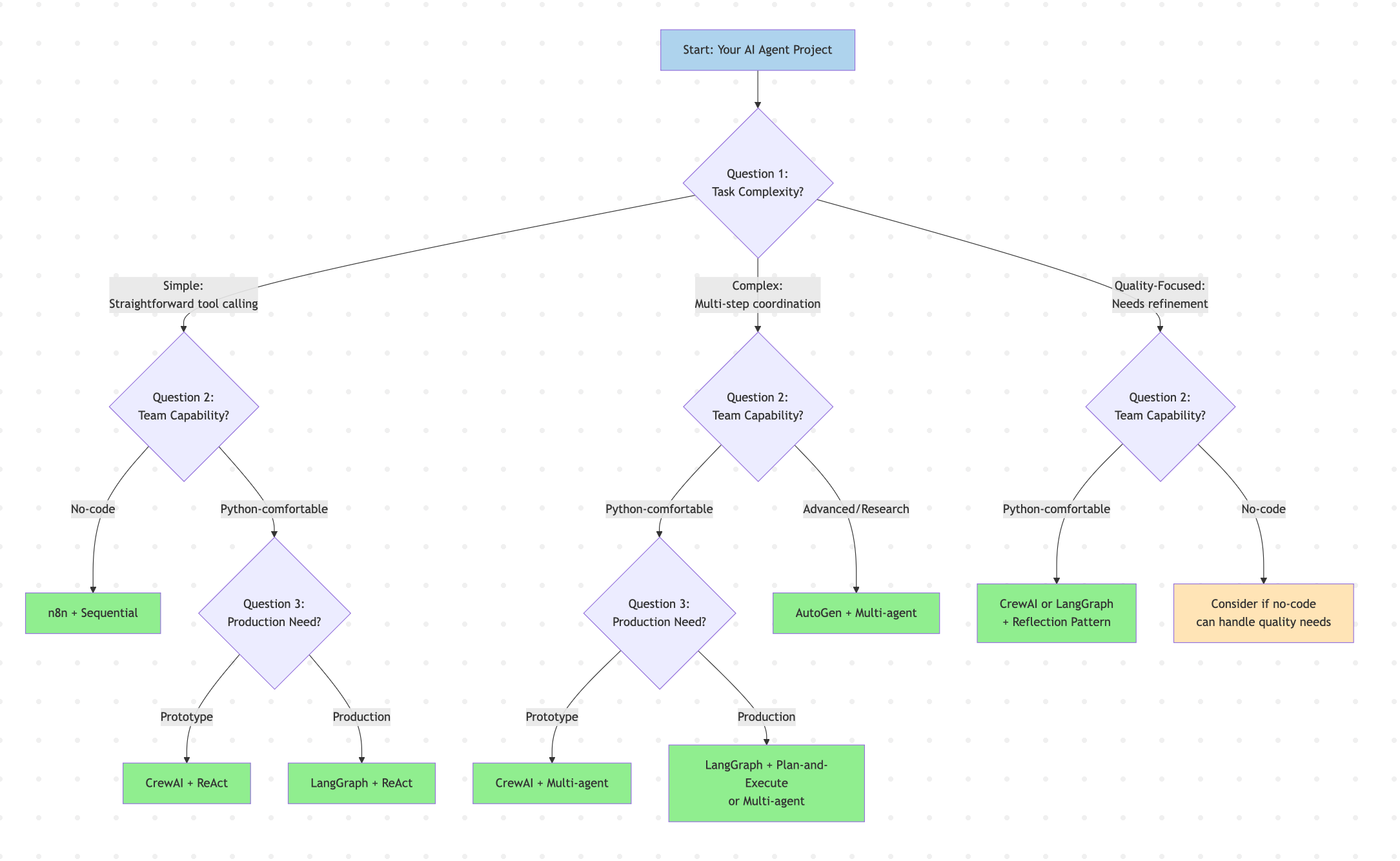
匹配您对这些问题的回答,您就已经排除了 80% 的选项。现在让我们快速比较一下这些框架。
框架概览比较
| 框架 | 易用性 | 生产就绪性 | 灵活性 | 最适用场景 |
|---|---|---|---|---|
| n8n / Flowise | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ | 无代码团队,简单工作流 |
| CrewAI | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | 快速原型制作,多智能体系统 |
| LangGraph | ⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 生产系统,精细控制 |
| AutoGen | ⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐⭐ | 研究,实验性多智能体 |
| Semantic Kernel | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | 微软/企业环境 |
使用此表来排除不符合您团队能力或生产要求的基础设施。“最适用场景”一栏应与您的用例紧密对齐。
真实的用例与完整的决策分析
用例 1:客户支持聊天机器人
问题: 构建一个智能体,可以回答客户问题、查询您的数据库以检查订单状态,并在需要时创建支持工单。
决策分析: 您的任务复杂度中等。您需要根据用户问题动态选择工具,但每个工具调用都是直截了当的。您的 Python 团队可以处理代码。您需要生产可靠性,因为客户依赖它。
推荐技术栈:
为什么选择此组合? LangGraph 提供了您需要的生产特性:通过 LangSmith 提供的可观测性、稳健的错误处理和状态管理。ReAct 模式能很好地处理不可预测的用户查询,允许智能体根据上下文推断应调用哪个工具。
为什么不选择替代方案? CrewAI 也可以工作,但提供的生产工具较少。AutoGen 对于直截了当的工具调用来说过于复杂了。如果用户提出各种问题,Plan-and-Execute 模式会过于僵化。以下是此架构在实践中的外观:
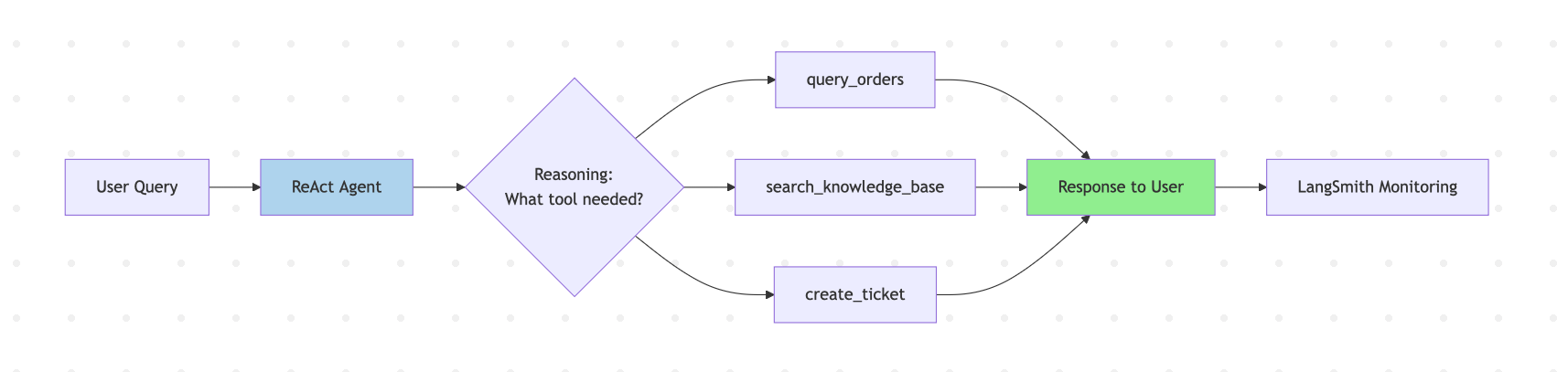
实施方法: 构建一个带有三个工具(query_orders()、search_knowledge_base() 和 create_ticket())的单一 ReAct 智能体。使用 LangSmith 监控智能体的决策。为超出置信度阈值的边缘情况添加人工升级。
关键点: 从一个简单的智能体开始。只有在遇到明显的限制时才增加复杂性。
用例 2:研究报告生成
问题: 您的智能体需要跨多个来源研究一个主题,分析发现,综合见解,并生成带有适当引用的、完善的报告。
决策分析: 复杂度高。您有多个不同的阶段,需要不同的能力。您的强大 Python 团队可以处理复杂的架构。质量比速度更重要,因为这些报告会影响业务决策。
推荐技术栈:
- 框架:CrewAI
- 模式:多智能体 + 反思 + 顺序工作流
为什么选择此组合? CrewAI 的角色设计自然映射到研究团队结构。您可以定义专业化的智能体:应用 ReAct 动态探索来源的研究智能体、处理发现的分析智能体、起草报告的撰写智能体,以及使用反思确保质量的编辑智能体。
这模仿了人类研究团队的工作方式。研究智能体收集信息,分析智能体综合信息,撰写智能体构建叙述,编辑智能体在发布前完善所有内容。以下是此多智能体系统从研究到最终输出的流程:

应避免的常见错误: 不要使用单一的 ReAct 智能体。虽然它更简单,但它难以处理此任务所需的协调和质量一致性。对于复杂的य研究任务,多智能体方法配合反思可以产生更好的输出。
替代考虑: 如果您的团队希望对工作流进行最大程度的控制,LangGraph 可以用更明确的编排来实现相同的多智能体架构。选择 CrewAI 以实现更快的开发,选择 LangGraph 以实现精细控制。
用例 3:数据管道监控
问题: 监控机器学习管道的性能漂移,在发生问题时诊断问题,并遵循标准操作程序执行修复。
决策分析: 复杂度中等。您有多个步骤,但它们遵循预定的程序。您的 MLOps 团队技术能力强。可靠性至关重要,因为这是在生产环境中自主运行的。
推荐技术栈:
为什么选择此组合? 您的 SOP 定义了明确的诊断和修复步骤。规划与执行模式在此表现出色。智能体会根据问题类型创建计划,然后系统地执行每一步。这种确定性方法可防止智能体进入意外的领域。
为什么不选择 ReAct? 当您的路径已知时,ReAct 会增加不必要的决策点。对于遵循既定程序的工作流程,Plan-and-Execute 提供了更好的可靠性和更简单的调试。以下是管道监控的规划与执行工作流外观:

框架选择: 如果您的团队偏爱基于代码的工作流并需要强大的可观测性,请选择 LangGraph。如果他们更喜欢使用预构建的监控工具集成来实现可视化工作流设计,则选择 n8n。
用例 4:代码审查助手
问题: 自动审查拉取请求(PR),识别问题,提出改进建议,并验证修复是否符合您的质量标准。
决策分析: 复杂度介于中等到高之间,需要探索和质量保证。您的开发团队熟悉 Python。它在生产环境中运行,但质量比原始速度更重要。
推荐技术栈:
- 框架:LangGraph
- 模式:ReAct + 反思(混合)
为什么选择混合方法? 审查过程有两个不同的阶段。第一阶段应用 ReAct 进行探索。智能体分析代码结构,根据检测到的编程语言运行相关 Linter,执行测试,并检查常见反模式。这需要动态决策。
第二阶段使用反思。智能体会对其反馈进行批判,以确定其语气、清晰度和实用性。此自我审查步骤在最终反馈到达开发人员之前,会捕获过于苛刻的批评、不明确的建议或缺失的上下文。以下是代码审查中混合 ReAct + 反思模式的工作原理:
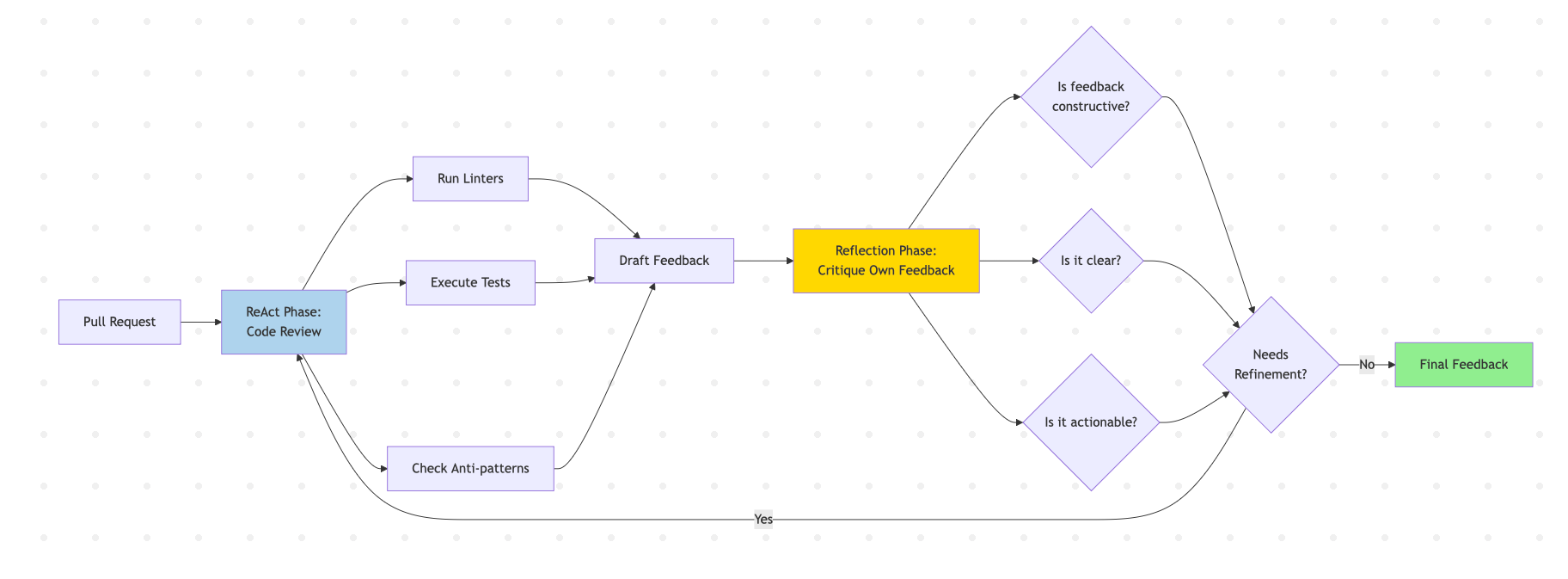
实施方法: 使用用于静态分析、测试执行和文档检查的工具构建 ReAct 智能体。生成初始反馈后,通过一个反思循环进行路由,该循环会问:“此反馈是否有建设性?它清晰吗?开发人员可以据此采取行动吗?” 在最终输出之前,根据自我批评进行完善。
这种混合模式平衡了探索与质量保证,从而产生既彻底又有帮助的审查。
快速参考:决策矩阵
当您需要快速决策时,请使用此矩阵:
| 用例类型 | 推荐框架 | 推荐模式 | 选择此组合的原因 |
|---|---|---|---|
| 支持聊天机器人 | LangGraph | ReAct | 带有可观测性的生产级工具调用 |
| 内容创建(质量至关重要) | CrewAI | 多智能体 + 反思 | 基于角色的设计,带有质量循环 |
| 遵循既定程序 | LangGraph 或 n8n | 规划与执行 | 已知工作流的确定性步骤 |
| 研究或探索任务 | AutoGen 或 CrewAI | ReAct 或多智能体 | 灵活的探索能力 |
| 无代码团队 | n8n 或 Flowise | 顺序工作流 | 可视化设计和预构建集成 |
| 快速原型制作 | CrewAI | ReAct | 通往工作智能体的最快路径 |
| 企业微软环境 | Semantic Kernel | 模式各异 | 原生生态系统集成 |
常见的决策错误以及如何避免
这是一个常见错误及其解决方案的快速参考:
| 错误 | 表现形式 | 错误原因 | 修复方法 |
|---|---|---|---|
| 过早选择多智能体 | “我的任务有三个步骤,所以需要三个智能体” | 增加了协调复杂性、延迟和成本。调试呈指数级难度 | 从单个智能体开始。只有在达到明确的能力限制时才拆分 |
| 对结构化任务使用 ReAct | 智能体在工作流程清晰的情况下做出错误的工具选择或混乱的执行 | ReAct 的灵活性成为负担。在已知序列上浪费 Token | 如果你可以在纸上预先写出步骤,请使用规划与执行 |
| 框架过度设计 | 为简单的双工具工作流使用 LangGraph 的完整架构 | 扼杀开发速度,增加调试难度和维护负担 | 将框架复杂性与任务复杂性相匹配 |
| 对高风险输出跳过反思 | 面向客户的内容质量不一致,存在明显错误 | 单次生成遗漏了本可捕获的错误。缺乏质量门禁 | 添加反思作为最终质量门禁,以批判输出前交付 |
您的演进路径
不要被您的第一个选择所束缚。成功的智能体系统会不断演进。以下是自然的演进过程:
如果您需要可视化工作流和快速迭代,请从 n8n 开始。当您遇到可视化工具的限制(需要自定义逻辑或复杂的逻辑管理)时,可以升级到 CrewAI。其 Python 基础提供了灵活性,同时保持了易用性。
当您需要生产级的控制(全面的可观测性、复杂的测试、复杂的逻辑管理)时,可以升级到 LangGraph。这使您能够完全控制智能体行为的每个方面。
何时保持不变: 如果 n8n 满足您的需求,不要仅仅因为您可以编写代码就进行迁移。如果 CrewAI 满足要求,不要过度设计而转向 LangGraph。仅在遇到实际限制时才进行迁移,而不是基于理论上的担忧。
您的决策清单
在开始构建之前,请验证您的决定:
- 您能用 2-3 句话清晰描述您的用例吗?如果不能,则尚未准备好选择技术栈。
- 您是否诚实地评估了任务复杂度?不要高估。大多数任务比它们最初看起来要简单。
- 您是否考虑了团队当前的能力,而不是期望的能力?选择他们今天可以使用的工具,而不是他们希望能够使用的工具。
- 这个框架是否具有您现在或六个月内需要的生产特性?不要仅根据您可能需要的功能进行选择。
- 您能在一周内构建一个最小版本吗?如果不能,则说明您选择的东西太复杂了。
底线
正确的 AI 智能体技术栈并非在于使用最先进的框架或最酷的模式。而在于将您的实际需求与经过验证的解决方案相匹配。
您的框架选择主要取决于团队能力和生产需求。您的模式选择主要取决于任务结构和质量要求。两者结合构成了您的技术栈。
从可以工作的最简单的解决方案开始。构建一个最小版本。根据您的成功指标衡量实际性能。只有那时,才应根据实际限制而非理论上的担忧来增加复杂性。
您在这里学到的决策框架(三个问题、用例分析、常见错误和演进路径)为您提供了一种系统化的方法来自信地做出这些选择。将其应用于您的下一个智能体项目,并让现实世界的结果指导您的演进。
准备好开始构建了吗?选择以上与您问题最接近的用例,遵循推荐的技术栈,并从最小实现开始。您在一周的构建中学到的东西,将比另一个月的理论研究学到的更多。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区