



📢 转载信息
原文作者:Surya Kari, Joel Carlson, Michael Cai, Morteza Ziyadi, Pradeep Natarajan, and Saurabh Sahu
评估大型语言模型 (LLM) 的性能,不仅仅局限于困惑度或双语评估字交替数 (BLEU) 等统计指标。对于大多数现实世界的生成式AI场景,了解模型是否比基线模型或早期迭代产生了更好的输出至关重要。这在摘要、内容生成或智能体等应用中尤为重要,这些应用中主观判断和细微的正确性起着核心作用。
随着组织在生产中深化部署这些模型,我们发现客户对系统性地评估模型质量的需求日益增长,传统方法无法完全满足这些需求,特别是当任务需要主观判断、上下文理解或与特定业务需求保持一致时。为了弥补这一差距,LLM-as-a-judge已成为一种有前景的方法,它利用LLM的推理能力,以更灵活和可扩展的方式评估其他模型。
今天,我们很高兴地介绍一种通过Amazon Nova LLM-as-a-Judge功能在Amazon SageMaker AI上进行模型评估的综合方法。SageMaker AI是一项完全托管的Amazon Web Services (AWS) 服务,用于大规模构建、训练和部署机器学习 (ML) 模型。Amazon Nova LLM-as-a-Judge旨在跨模型家族提供对生成式AI输出的稳健、无偏见的评估。Nova LLM-as-a-Judge作为SageMaker AI上的优化工作流程提供,使用户可以在几分钟内根据特定用例开始评估模型性能。与许多表现出架构偏见的评估器不同,Nova LLM-as-a-Judge经过严格验证,保持公正性,并在关键的“裁判”基准测试中实现了领先的性能,同时密切反映了人类偏好。凭借其卓越的准确性和最小的偏见,它为可信赖的、生产级的LLM评估设定了新标准。
Nova LLM-as-a-Judge功能提供模型迭代之间的成对比较,因此您可以自信地根据数据做出关于模型改进的决策。
Nova LLM-as-a-Judge 的训练方式
Nova LLM-as-a-Judge是通过一个多阶段训练过程构建的,该过程包括监督训练和强化学习阶段,使用了用人类偏好进行注释的公共数据集。对于专有组件,多名注释员独立评估了数千个示例,方法是比较两个不同LLM对相同提示的响应。为验证一致性和公平性,所有注释都经过了严格的质量检查,最终判断经过校准,以反映广泛的人类共识,而不是个人观点。
训练数据在设计上是多样化且具有代表性的。提示涵盖了广泛的类别,包括现实世界知识、创造力、编码、数学、专业领域和毒性,以便模型能够评估许多现实世界场景中的输出。训练数据包括来自90多种语言的数据,主要由英语、俄语、中文、德语、日语和意大利语组成。重要的是,一项内部偏见研究评估了超过10,000个针对75个第三方模型的人类偏好判断,证实Amazon Nova LLM-as-a-Judge相对于人类注释仅显示出 3% 的总体偏差。尽管这在减少系统性偏差方面是一项重大成就,但我们仍然建议偶尔进行抽查,以验证关键比较。
在下图 [图片 1] 中,您可以了解当比较Amazon Nova输出与其他模型的输出时,Nova LLM-as-a-Judge的偏差与人类偏好的比较情况。在此处,偏差衡量的是裁判偏好与人类偏好在数千个示例上的差异。正值表示裁判略微偏爱 Amazon Nova 模型,负值表示相反。为了量化这些估计的可靠性,我们假设独立二项分布,使用比例差异的标准误差计算了 95% 的置信区间。
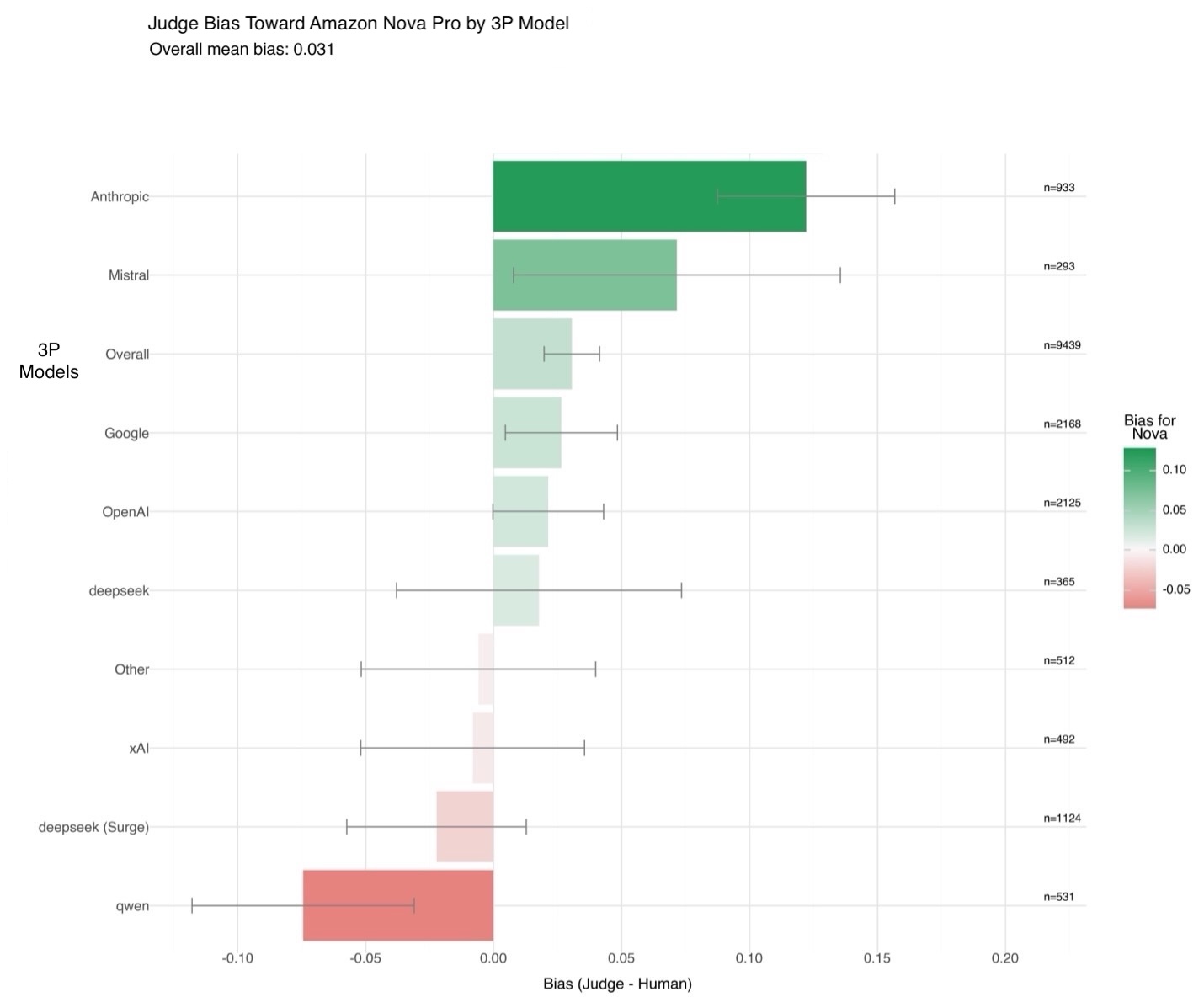
Amazon Nova LLM-as-a-Judge在评估模型中实现了先进的性能,在各种任务上展示了与人类判断的强有力的一致性。例如,它在JudgeBench上获得 45% 的准确率(Meta J1 8B 为 42%),在PPE上获得 68% 的准确率(Meta J1 8B 为 60%)。Meta J1 8B 的数据摘自通过强化学习激励LLM-as-a-Judge中的思考。
这些结果突显了Amazon Nova LLM-as-a-Judge在聊天机器人相关评估中的优势,如PPE基准测试所示。我们的基准测试遵循当前最佳实践,报告了JudgeBench、CodeUltraFeedback、Eval Bias 和 LLMBar 上位置交换响应的协调结果,同时对PPE使用单次通过结果。
| 模型 | Eval Bias | Judge Bench | LLM Bar | PPE | CodeUltraFeedback |
| Nova LLM-as-a-Judge | 0.76 | 0.45 | 0.67 | 0.68 | 0.64 |
| Meta J1 8B | – | 0.42 | – | 0.60 | – |
| Nova Micro | 0.56 | 0.37 | 0.55 | 0.6 | – |
在本文中,我们将介绍一种使用SageMaker AI实现Amazon Nova LLM-as-a-Judge评估的简化方法,解释结果指标,并将此过程应用于改进生成式AI应用程序。
评估工作流程概述
评估过程始于准备一个数据集,其中每个示例都包含一个提示和两个备选的模型输出。JSONL 格式如下所示:
{
"prompt":"Explain photosynthesis.",
"response_A":"Answer A...",
"response_B":"Answer B..."
}
{
"prompt":"Summarize the article.",
"response_A":"Answer A...",
"response_B":"Answer B..."
}准备好此数据集后,您将使用提供的 SageMaker 评估配方,该配方配置评估策略,指定用作裁判的模型,并定义如 temperature 和 top_p 等推理设置。
评估在 SageMaker 训练作业内部运行,该作业使用预构建的 Amazon Nova 容器。SageMaker AI 预配计算资源,协调评估,并将输出指标和可视化写入 Amazon Simple Storage Service (Amazon S3)。
完成后,您可以下载并分析结果,其中包括偏好分布、胜率和置信区间。
了解 Amazon Nova LLM-as-a-Judge 的工作原理
Amazon Nova LLM-as-a-Judge使用一种称为 二元总体偏好裁判 的评估方法。二元总体偏好裁判 是一种方法,其中语言模型并排比较两个输出,选择更好的一个或宣布平局。对于每个示例,它会产生一个明确的偏好。当您汇总跨多个样本的这些判断时,您会得到胜率和置信区间等指标。这种方法使用模型自身的推理能力,以直接、一致的方式评估相关性和清晰度等质量。
- 此裁判模型旨在在不需要粒度反馈的情况下,在需要低延迟的总体偏好的情况下提供支持。
- 该模型的输出是 [[A>B]] 或 [[B>A]] 之一。
- 该模型的主要用例是需要自动化、低延迟、总体成对偏好的情况,例如在训练管道中进行检查点选择的自动化评分。
了解 Amazon Nova LLM-as-a-Judge 评估指标
当使用 Amazon Nova LLM-as-a-Judge 框架比较两个语言模型的输出来源时,SageMaker AI 会生成一套全面的定量指标。您可以使用这些指标来评估哪个模型表现更好以及评估的可靠性如何。结果分为三大类:核心偏好指标、统计置信指标 和标准误差指标。
核心偏好指标报告了裁判模型偏爱每个模型输出的频率。a_scores 指标计算模型 A 被青睐的示例数,b_scores 计算模型 B 被选为更好的情况数。ties 指标捕获了裁判模型对两个响应评分相同或无法识别明确偏好的实例。inference_error 指标计算了由于数据格式错误或内部错误而导致裁判无法生成有效判断的情况数。
统计置信指标量化了观察到的偏好反映模型质量的真实差异而非随机变化的几率。winrate 报告了在所有有效比较中模型 B 被青睐的比例。lower_rate 和 upper_rate 定义了此胜率的 95% 置信区间的下限和上限。例如,一个胜率为 0.75、置信区间在 0.60 到 0.85 之间的结果表明,即使考虑到不确定性,模型 B 也持续优于模型 A。score 字段通常与模型 B 的获胜次数匹配,但也可以针对更复杂的评估策略进行定制。
标准误差指标提供了每个计数统计不确定性的估计。这些包括 a_scores_stderr、b_scores_stderr、ties_stderr、inference_error_stderr 和 score_stderr。较小的标准误差值表示结果更可靠。较大的值可能表明需要额外的评估数据或更一致的提示工程。
解释这些指标需要同时关注观察到的偏好和置信区间:
- 如果
winrate远高于 0.5 且置信区间不包括 0.5,则统计上偏爱模型 B 优于模型 A。 - 相反,如果
winrate低于 0.5 且置信区间完全低于 0.5,则偏爱模型 A。 - 当置信区间与 0.5 重叠时,结果不确定,建议进行进一步评估。
inference_error值较高或标准误差较大表明评估过程中可能存在问题,例如提示格式不一致或样本量不足。
以下是评估运行的示例指标输出:
{
"a_scores": 16.0,
"a_scores_stderr": 0.03,
"b_scores": 10.0,
"b_scores_stderr": 0.09,
"ties": 0.0,
"ties_stderr": 0.0,
"inference_error": 0.0,
"inference_error_stderr": 0.0,
"score": 10.0,
"score_stderr": 0.09,
"winrate": 0.38,
"lower_rate": 0.23,
"upper_rate": 0.56
}在此示例中,模型 A 被青睐 16 次,模型 B 被青睐 10 次,没有平局或推理错误。winrate 为 0.38 表示模型 B 在 38% 的情况下被青睐,95% 的置信区间范围从 23% 到 56%。由于该区间包含 0.5,此结果表明评估不确定,可能需要额外数据来明确哪个模型整体表现更好。
这些指标作为评估过程的一部分自动生成,为比较模型和根据数据做出部署哪个模型的决策提供了严格的统计基础。
解决方案概述
此解决方案演示了如何使用 Nova LLM-as-a-Judge 功能在 Amazon SageMaker AI 上评估生成式AI模型。提供的 Python 代码指导您完成整个工作流程。
首先,它通过从 SQuAD 采样问题并从 Qwen2.5 和 Anthropic 的 Claude 3.7 生成候选响应来准备数据集。这些输出以 JSONL 文件格式保存,其中包含提示和两个响应。
我们使用 bedrock-runtime 客户端通过 Amazon Bedrock 访问了 Anthropic 的 Claude 3.7 Sonnet。我们使用 SageMaker 托管的 Hugging Face 端点 访问了 Qwen2.5 1.5B。
接下来,一个 PyTorch Estimator 启动一个评估作业,使用 Amazon Nova LLM-as-a-Judge 配方。该作业在 ml.g5.12xlarge 等 GPU 实例上运行,并生成评估指标,包括胜率、置信区间和偏好计数。结果保存到 Amazon S3 以供分析。
最后,一个可视化函数渲染图表和表格,总结了哪个模型更受青睐、偏好程度如何以及估计的可靠性。通过这种端到端的方法,您可以评估改进、跟踪回归,并根据数据做出部署生成模型的决策——所有这些都无需手动注释。
先决条件
在运行 Notebook 之前,您需要完成以下先决条件:
- 对 SageMaker AI 提出以下配额增加请求。对于此用例,您需要请求至少 1 个 g5.12xlarge 实例。在 Service Quotas 控制台中,请求以下 SageMaker AI 配额:1 个 G5 实例 (g5.12xlarge) 用于训练作业使用。
- (可选)您可以创建一个 Amazon SageMaker Studio 域(参考 使用快速设置创建 Amazon SageMaker AI)以访问具有上述角色的 Jupyter 笔记本。(您也可以在本地设置中使用 JupyterLab。)
- 创建一个 AWS Identity and Access Management (IAM) 角色,具有托管策略
AmazonSageMakerFullAccess、AmazonS3FullAccess和AmazonBedrockFullAccess,以授予 SageMaker AI 和 Amazon Bedrock 运行示例所需的访问权限。 - 向您的 IAM 角色分配以下策略作为 信任关系:
- 创建一个 AWS Identity and Access Management (IAM) 角色,具有托管策略
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Principal": {
"Service": [
"bedrock.amazonaws.com",
"sagemaker.amazonaws.com"
]
},
"Action": "sts:AssumeRole"
}
]
}
- 克隆包含此部署资产的 GitHub 仓库。此仓库由一个引用训练资产的 Notebook 组成:
git clone https://github.com/aws-samples/amazon-nova-samples.git
cd customization/SageMakerTrainingJobs/Amazon-Nova-LLM-As-A-Judge/接下来,运行 Notebook Nova Amazon-Nova-LLM-as-a-Judge-Sagemaker-AI.ipynb 以开始在 Amazon SageMaker AI 上使用 Amazon Nova LLM-as-a-Judge 实现。
模型设置
要进行 Amazon Nova LLM-as-a-Judge 评估,您需要生成要比较的候选模型的输出来源。在此项目中,我们使用了两种不同的方法:在 Amazon SageMaker 上部署 Qwen2.5 1.5B 模型,以及在 Amazon Bedrock 中调用 Anthropic 的 Claude 3.7 Sonnet 模型。首先,我们在专用的 SageMaker 端点上部署了 Qwen2.5 1.5B,这是一个开放权重多语言语言模型。这是通过使用 HuggingFaceModel 部署接口实现的。要部署 Qwen2.5 1.5B 模型,我们提供了一个便捷的脚本供您调用:python3 deploy_sm_model.py
部署后,可以使用包装 SageMaker 预测器 API 的帮助函数执行推理:
# Initialize the predictor once
predictor = HuggingFacePredictor(endpoint_name="qwen25-<endpoint_name_here>")
def generate_with_qwen25(prompt: str, max_tokens: int = 500, temperature: float = 0.9) -> str:
""" Sends a prompt to the deployed Qwen2.5 model on SageMaker and returns the generated response. Args:
prompt (str): The input prompt/question to send to the model.
max_tokens (int): Maximum number of tokens to generate.
temperature (float): Sampling temperature for generation.
Returns:
str: The model-generated text.
"""
response = predictor.predict({
"inputs": prompt,
"parameters": {
"max_new_tokens": max_tokens,
"temperature": temperature
}
})
return response[0]["generated_text"]
answer = generate_with_qwen25("What is the Grotto at Notre Dame?")
print(answer)同时,我们将 Anthropic 的 Claude 3.7 Sonnet 模型集成到 Amazon Bedrock 中。Amazon Bedrock 提供了一个托管的 API 层,用于访问专有基础模型 (FM),而无需管理基础设施。Claude 生成函数使用 bedrock-runtime AWS SDK for Python (Boto3) 客户端,它接受用户提示并返回模型的文本补全:
# Initialize Bedrock client once
bedrock = boto3.client("bedrock-runtime", region_name="us-east-1")
# (Claude 3.7 Sonnet) model ID via Bedrock
MODEL_ID = "us.anthropic.claude-3-7-sonnet-20250219-v1:0"
def generate_with_claude4(prompt: str, max_tokens: int = 512, temperature: float = 0.7, top_p: float = 0.9) -> str:
""" Sends a prompt to the Claude 4-tier model via Amazon Bedrock and returns the generated response. Args:
prompt (str): The user message or input prompt.
max_tokens (int): Maximum number of tokens to generate.
temperature (float): Sampling temperature for generation.
top_p (float): Top-p nucleus sampling.
Returns:
str: The text content generated by Claude.
"""
payload = {
"anthropic_version": "bedrock-2023-05-31",
"messages": [{"role": "user", "content": prompt}],
"max_tokens": max_tokens,
"temperature": temperature,
"top_p": top_p
}
response = bedrock.invoke_model(
modelId=MODEL_ID,
body=json.dumps(payload),
contentType="application/json",
accept="application/json"
)
response_body = json.loads(response['body'].read())
return response_body["content"][0]["text"]
answer = generate_with_claude4("What is the Grotto at Notre Dame?")
print(answer)当您生成并测试了这两个函数后,就可以着手为 Nova LLM-as-a-Judge 创建评估数据了。
准备数据集
为了创建用于比较 Qwen 和 Claude 模型的真实评估数据集,我们使用了斯坦福问答数据集 (SQuAD),这是一个在自然语言理解中被广泛采用的基准,根据 CC BY-SA 4.0 许可分发。SQuAD 包含数千个众包的问答对,涵盖了各种维基百科文章。通过对该数据集进行采样,我们确保评估提示反映了高质量、事实性的问答任务,这些任务代表了现实世界的应用。
我们首先加载了一小部分示例,以保持工作流程快速且可重现。具体来说,我们使用 Hugging Face datasets 库从 SQuAD 训练集中下载并加载了前 20 个示例:
from datasets import load_dataset
squad = load_dataset("squad", split="train[:20]")此命令检索了完整数据集的一个切片,其中包含 20 个条目,具有结构化字段,包括上下文、问题和答案。为验证内容并检查示例,我们打印了一个示例问题及其基本事实答案:
print(squad[3]["question"])
print(squad[3]["answers"]["text"][0])对于评估集,我们从该子集中选择了前六个问题:
questions = [squad[i]["question"] for i in range(6)]
生成 Amazon Nova LLM-as-a-Judge 评估数据集
准备好 SQuAD 中的评估问题集后,我们生成了两个模型的输出,并将它们组合成一个结构化数据集,供 Amazon Nova LLM-as-a-Judge 工作流程使用。该数据集是 SageMaker AI 评估配方的核心输入。为此,我们遍历每个问题提示并调用前面定义的两个生成函数:
generate_with_qwen25()用于来自 SageMaker 上部署的 Qwen2.5 模型的补全。generate_with_claude()用于来自 Amazon Bedrock 中 Anthropic Claude 3.7 Sonnet 的补全。
对于每个提示,工作流程会尝试从每个模型生成响应。如果生成调用因 API 错误、超时或其他问题而失败,系统会捕获异常并存储一条明确的错误消息以指示失败。这确保了即使存在瞬时错误,评估过程也能顺利进行:
import json
output_path = "llm_judge.jsonl"
with open(output_path, "w") as f:
for q in questions:
try:
response_a = generate_with_qwen25(q)
except Exception as e:
response_a = f"[Qwen2.5 generation failed: {e}]"
try:
response_b = generate_with_claude4(q)
except Exception as e:
response_b = f"[Claude 3.7 generation failed: {e}]"
row = {
"prompt": q,
"response_A": response_a,
"response_B": response_b
}
f.write(json.dumps(row) + "\n")
print(f"JSONL file created at: {output_path}")此工作流程生成了一个名为 llm_judge.jsonl 的 JSON Lines 文件。每行包含一个结构如下的单个评估记录:
{
"prompt": "What is the capital of France?",
"response_A": "The capital of France is Paris.",
"response_B": "Paris is the capital city of France."
}然后,将此 llm_judge.jsonl 上传到您预先定义的 S3 存储桶中:
upload_to_s3("llm_judge.jsonl", "s3://<YOUR_BUCKET_NAME>/datasets/byo-datasets-dev/custom-llm-judge/llm_judge.jsonl")启动 Nova LLM-as-a-Judge 评估作业
准备好数据集并创建评估配方后,最后一步是启动 SageMaker 训练作业,该作业执行 Amazon Nova LLM-as-a-Judge 评估。在此工作流程中,训练作业充当一个完全托管的、自包含的过程,它加载模型、处理数据集并在您指定的 Amazon S3 位置生成评估指标。
我们使用 SageMaker Python SDK 中的 PyTorch 估计器类来封装评估运行的配置。估计器定义了计算资源、容器映像、评估配方以及结果存储的输出路径:
estimator = PyTorch(
output_path=output_s3_uri,
base_job_name=job_name,
role=role,
instance_type=instance_type,
training_recipe=recipe_path,
sagemaker_session=sagemaker_session,
image_uri=image_uri,
disable_profiler=True,
debugger_hook_config=False,
)
配置好估计器后,使用 fit() 方法启动评估作业。此调用将作业提交到 SageMaker 控制平面,预配计算集群,并开始处理评估数据集:
estimator.fit(inputs={"train": evalInput})
Amazon Nova LLM-as-a-Judge 评估作业的结果
下图说明了 Amazon Nova LLM-as-a-Judge 评估作业的结果。
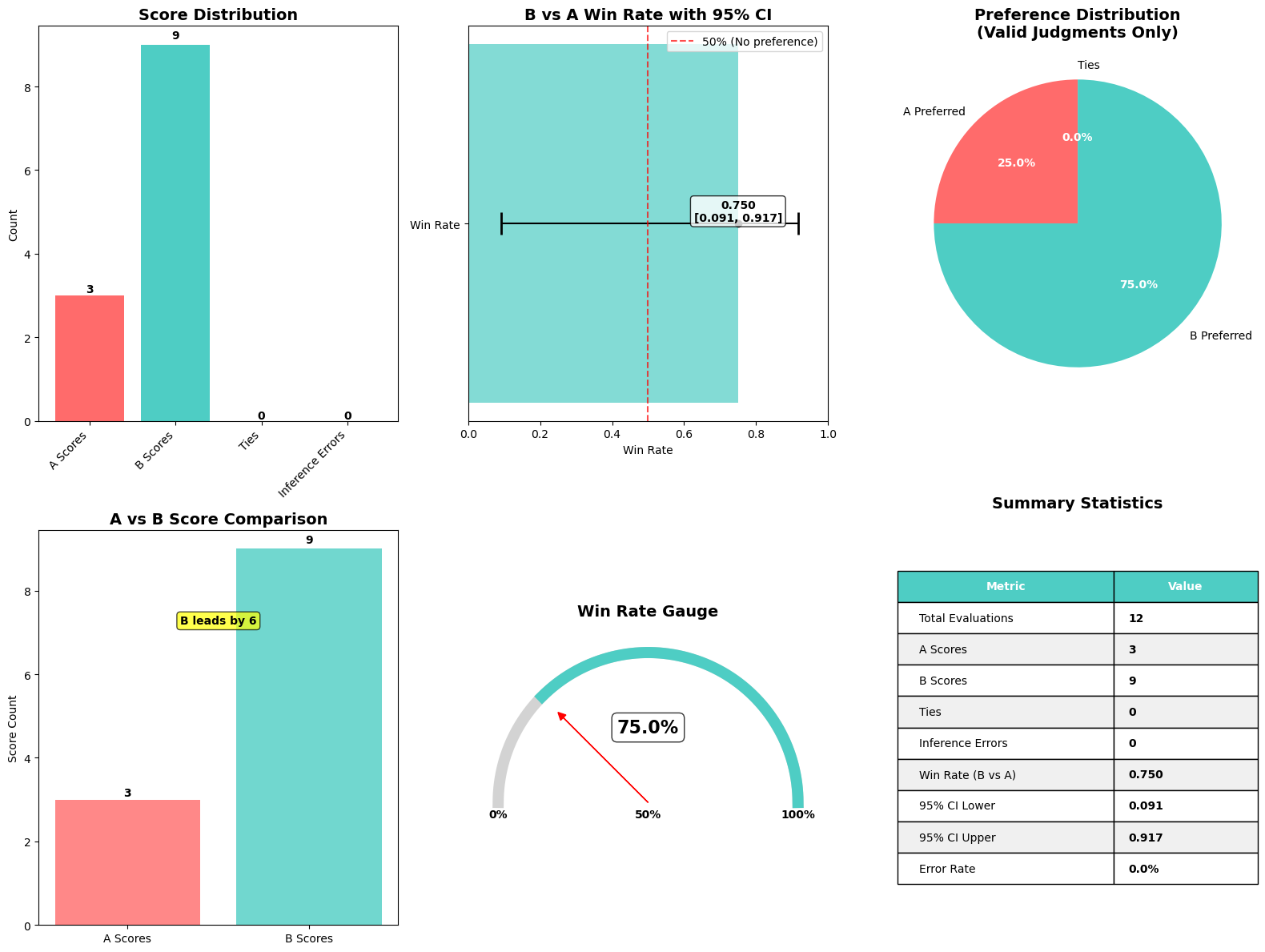
为了帮助实践者快速解释 Nova LLM-as-a-Judge 评估的结果,我们创建了一个 便捷函数,它生成一个单一的、全面的可视化,总结了关键指标。此函数 plot_nova_judge_results 使用 Matplotlib 和 Seaborn 渲染一个包含六个面板的图像,每个面板都突出了评估结果的不同方面。
此函数接收评估作业完成后生成的评估指标字典,并生成以下视觉组件:
- 得分分布条形图 – 显示模型 A 被青睐的次数、模型 B 被青睐的次数、平局的次数以及裁判未能产生决定的次数(推理错误)。这提供了对评估的决定性程度以及任一模型是否占主导地位的即时印象。
- 带 95% 置信区间的胜率 – 绘制模型 B 相对于模型 A 的总体胜率,包括一个误差... [内容被截断]
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区