



📢 转载信息
原文链接:https://www.kdnuggets.com/google-stax-testing-models-and-prompts-against-your-own-criteria
原文作者:Shittu Olumide / KDnuggets
Google Stax:根据您自己的标准测试模型和提示词
学习Google Stax如何根据您自己的标准测试AI模型和提示词。将Gemini与GPT进行比较,使用自定义评估器。为初学者提供的分步指南。

引言
如果您正在构建使用大型语言模型(LLM)的应用程序,您可能经历过这样的场景:您更改了一个提示词,运行几次,感觉输出更好。但它真的更好吗?没有客观的指标,您就被困在行业现在称为“凭感觉测试”的状态,这意味着基于直觉而非数据来做决策。
挑战源于AI模型的一个基本特征:不确定性。与传统软件不同,后者对相同的输入总是产生相同的输出,LLM可能对相似的提示词产生不同的响应。这使得传统的单元测试无效,并让开发人员猜测他们的更改是否真正提高了性能。
然后出现了Google Stax,这是Google DeepMind和Google Labs推出的一款新的实验性工具包,旨在为AI评估带来准确性。在本文中,我们将探讨Stax如何使开发人员和数据科学家能够根据自己定制的标准来测试模型和提示词,用可重复的、数据驱动的决策取代主观判断。
理解Google Stax
Stax是一个开发工具,它简化了生成式AI模型和应用程序的评估。将其视为一个专门为处理LLM的独特挑战而构建的测试框架。
其核心是,Stax解决了一个简单但关键的问题:您如何知道一个模型或提示词在您的特定用例中比另一个更好?Stax不依赖于可能不反映您应用程序需求的通用标准,而是让您定义项目中的“好”意味着什么,并根据这些标准进行衡量。
探索关键能力
- 它帮助您定义自己的成功标准,超越流畅性和安全性等通用指标
- 您可以并排测试各种模型上的不同提示词
- 您可以可视化收集的性能指标(包括质量、延迟和token使用量),从而做出数据驱动的决策
- 它可以使用您自己的数据集大规模运行评估
Stax非常灵活,不仅支持Google的Gemini模型,还通过API集成支持OpenAI的GPT、Anthropic的Claude、Mistral等模型。
超越标准基准测试
通用AI基准测试起着重要作用,例如帮助跟踪模型的高级别进展。然而,它们通常未能反映特定领域的需求。一个在开放域推理方面表现出色的模型,在专业任务上可能会表现不佳,例如:
- 以合规为重点的摘要
- 法律文件分析
- 企业特定问答
- 品牌语气的遵循
通用基准测试与实际应用程序之间的差距正是Stax发挥价值的地方。它使您能够根据您的数据和标准来评估AI系统,而不是基于抽象的全球分数。
开始使用Stax
步骤1:添加API密钥
要生成模型输出并运行评估,您需要添加API密钥。Stax建议从Gemini API密钥开始,因为内置的评估器默认使用它,尽管您可以配置它们使用其他模型。您可以在首次使用时添加第一个密钥,或稍后在设置中添加。
为了比较多个提供商,请为要测试的每个模型添加密钥;这使得在不切换工具的情况下进行并行比较。
获取API密钥
步骤2:创建评估项目
项目是Stax中的中心工作区。每个项目对应一个单独的评估实验,例如,测试一个新的系统提示或比较两个模型。
您将在两种项目类型之间进行选择:
| 项目类型 | 最适合 |
|---|---|
| 单模型 | 基准性能或测试模型或系统提示的迭代 |
| 并排比较 | 在同一数据集上直接比较两个不同的模型或提示词 |

图1:一个并排比较流程图,显示两个模型接收相同的输入提示,它们的输出流向一个生成比较指标的评估器。
步骤3:构建数据集
一次可靠的评估始于准确且能反映您真实用例的数据。Stax提供两种主要方法来实现这一点:
选项A:在提示词游乐场中手动添加数据
如果您没有现有的数据集,请从头开始构建:
- 选择您要测试的模型
- 设置系统提示(可选)以定义AI的角色
- 添加代表真实用户输入的提示词
- 提供人工评分(可选)以创建基线质量分数
每个输入、输出和评分都会自动保存为测试用例。
选项B:上传现有数据集
对于拥有生产数据的团队,可以直接上传CSV文件。如果您的数据集不包含模型输出,请点击“生成输出”并选择一个模型来生成它们。
最佳实践:在数据集中包含边缘情况和冲突示例,以确保全面测试。
评估AI输出
进行手动评估
您可以在游乐场中或在项目基准测试中直接对单个输出提供人工评分。虽然人工评估被认为是“黄金标准”,但它速度慢、成本高且难以扩展。
使用自动评估器执行自动评估
为了同时对许多输出进行评分,Stax使用LLM作为评委评估,即一个强大的AI模型根据您的标准评估另一个模型的输出。
Stax包含常用的预加载评估器:
- 流畅性
- 事实一致性
- 安全性
- 指令遵循
- 简洁性

Stax评估界面显示一列模型输出,旁边是来自各种评估器的评分列,以及一个“运行评估”按钮
利用自定义评估器
虽然预加载的评估器提供了良好的起点,但构建自定义评估器是衡量您特定用例中重要内容的最佳方法。
自定义评估器允许您定义特定标准,例如:
- “回应是否有帮助但不过于随意?”
- “输出是否包含任何个人身份信息(PII)?”
- “生成的代码是否遵循我们内部的风格指南?”
- “品牌语气的连贯性是否符合我们的指导方针?”
构建自定义评估器:定义清晰的标准,为评判模型编写包含评分核对表的提示词,并针对少量手动评分的输y于输出进行测试,以确保一致性。
探索实际用例
用例1:客户支持聊天机器人
假设您正在构建一个客户支持聊天机器人。您的要求可能包括:
- 专业语气
- 基于您的知识库的准确答案
- 无幻觉
- 在三次交流内解决常见问题
使用Stax,您将:
- 上传真实客户查询的数据集
- 从不同模型(或不同提示词版本)生成响应
- 创建一个自定义评估器,对专业性和准确性进行评分
- 并排比较结果以选择最佳性能者
用例2:内容摘要工具
对于新闻摘要应用程序,您关心的是:
- 简洁性(摘要在100字以内)
- 与原文的一致性
- 关键信息的保留
使用Stax预先构建的摘要质量评估器可以立即获得指标,而自定义评估器可以强制执行特定的长度限制或品牌语气要求。
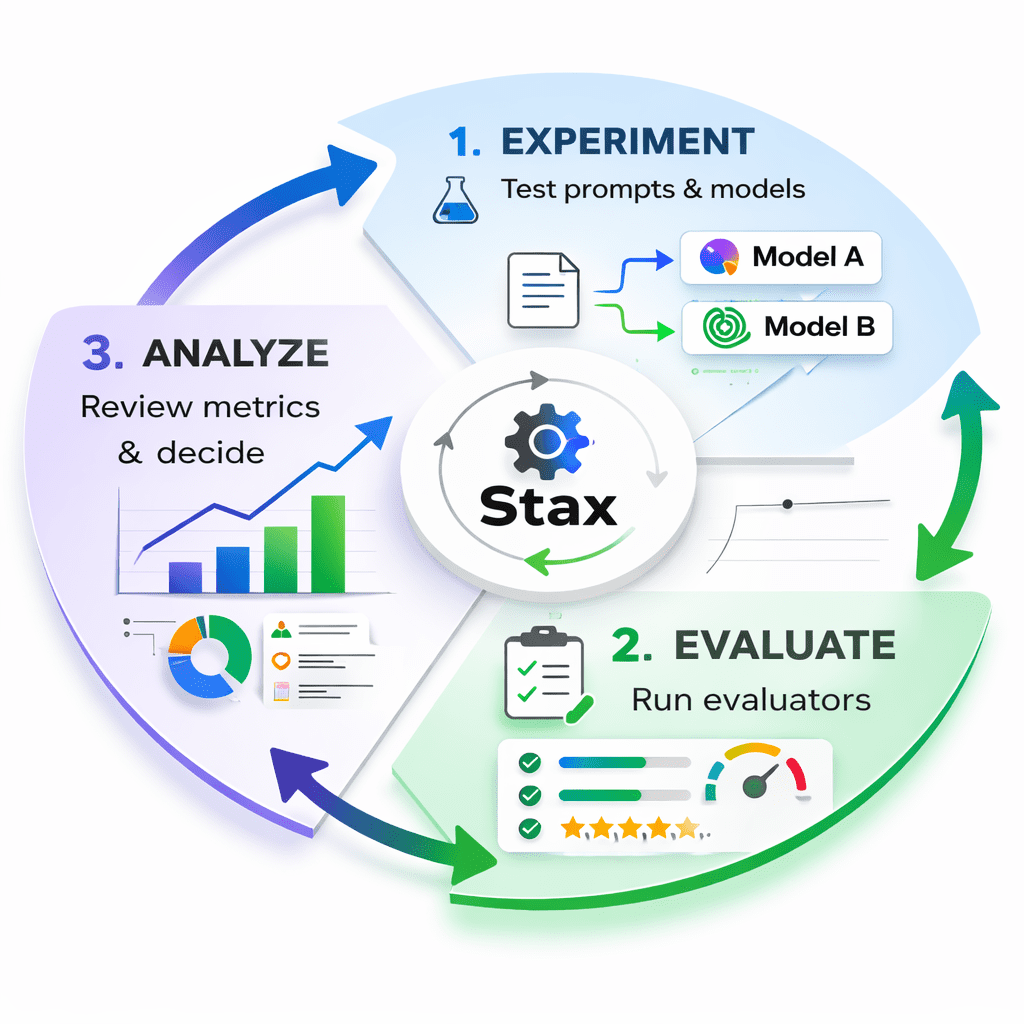
图2:Stax飞轮的视觉效果,显示三个阶段:实验(测试提示词/模型)、评估(运行评估器)和分析(审查指标并决策)。
解读结果
评估完成后,Stax会将新列添加到您的数据集中,显示每个输出的评分和理由。项目指标部分提供了以下内容的汇总视图:
- 人工评分
- 平均评估器得分
- 推理延迟
- Token计数
使用这些量化数据来:
- 比较迭代:提示词A是否持续优于提示词B?
- 在模型之间选择:更快的模型是否值得牺牲一点质量?
- 跟踪进展:您的优化是否真的提高了性能?
- 识别失败:哪些输入持续产生糟糕的输出?

图3:一个仪表板视图,显示条形图,比较两个模型在多个指标(质量得分、延迟、成本)上的表现。
实施有效评估的最佳实践
- 从小处着手,再规模化:您不需要数百个测试用例就能获得价值。一个只有十个高质量提示词的评估集,其价值远远超过仅凭感觉测试。从一个集中的集合开始,并随着您的学习而扩展。
- 创建回归测试:您的评估应包括保护现有质量的测试。例如,“始终输出有效的JSON”或“从不包含竞争对手的名称”。这些可以防止新的更改破坏已有效的功能。
- 构建挑战集:创建针对您希望AI改进的领域的数据集。如果您的模型在复杂推理方面遇到困难,请专门为此能力构建一个挑战集。
- 不要放弃人工审查:虽然自动评估可以很好地扩展,但让您的团队使用您的AI产品对于建立直觉仍然至关重要。使用Stax捕获人工测试中的有力示例,并将其合并到您的正式评估数据集中。
回答常见问题
- 什么是Google STAX? Stax是Google的一款开发工具,用于评估LLM驱动的应用程序。它帮助您根据自己的标准测试模型和提示词,而不是依赖于通用基准测试。
- Stax AI如何工作? Stax使用“LLM作为评委”的方法,您定义评估标准,AI模型根据这些标准对输出进行评分。您可以使用预构建的评估器或创建自定义评估器。
- Google的哪个工具允许个人创建他们的机器学习模型? 虽然Stax侧重于评估而非模型创建,但它与其他Google AI工具协同工作。要构建和训练模型,您通常会使用TensorFlow或Vertex AI。然后,Stax帮助您评估这些模型的性能。
- Google的ChatGPT等效产品是什么? Google的主要对话式AI是Gemini(以前称为Bard)。Stax可以帮助您测试和优化Gemini的提示词,并将其性能与其他模型进行比较。
- 我可以用自己的数据训练AI吗? Stax不训练模型;它进行评估。但是,您可以使用自己的数据作为测试用例来评估预训练模型。要使用自己的数据训练自定义模型,您需要使用Vertex AI等工具。
结论
凭感觉测试的时代正在结束。随着AI从实验演示转向生产系统,详细的评估变得越来越重要。Google Stax提供了框架来定义“好”对您独特的用例意味着什么,以及系统地衡量它的工具。
通过用可重复的、数据驱动的评估取代主观判断,Stax可以帮助您:
- 自信地发布AI功能
- 在模型选择方面做出明智的决策
- 更快地迭代提示词和系统指令
- 构建可靠满足用户需求的AI产品
无论您是初学者数据科学家还是经验丰富的ML工程师,采用结构化的评估实践都将改变您构建AI的方式。从小处着手,定义对您的应用程序至关重要的内容,并让数据指导您的决策。
准备好摆脱凭感觉测试了吗?访问stax.withgoogle.com探索该工具,并加入构建更好AI应用程序的开发者社区。
参考文献
Shittu Olumide是一位软件工程师和技术作家,热衷于利用尖端技术来创作引人入胜的叙事,他注重细节,并擅长简化复杂的概念。您也可以在Twitter上找到Shittu。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区