



📢 转载信息
原文链接:https://www.kdnuggets.com/the-complete-hugging-face-primer-for-2026
原文作者:Shittu Olumide

Image by Author
Hugging Face(再)简介
在本教程结束时,您将了解并理解Hugging Face在现代机器学习中的重要性,探索其生态系统,并设置本地开发环境,开始您的机器学习实践之旅。您还将了解到Hugging Face对每个人都是免费的,并发现它为初学者和专家提供的工具。但首先,让我们了解一下Hugging Face的宗旨。
Hugging Face是一个AI在线社区,它已成为任何从事人工智能和机器学习工作的人的基石,使研究人员、开发人员和组织能够以以前无法实现的方式利用机器学习。
将Hugging Face视为一个装满了来自世界各地最佳作者所著书籍的图书馆。您无需编写自己的书籍,而是可以借阅一本,理解它,并用它来解决问题——无论是摘要文章、翻译文本还是对电子邮件进行分类。
以类似的方式,Hugging Face充满了来自世界各地研究人员和开发人员编写的机器学习和AI模型,您可以下载并在本地机器上运行它们。您也可以直接使用Hugging Face API来使用这些模型,而无需昂贵的硬件。
如今,Hugging Face Hub托管着数百万个预训练模型、数十万个数据集以及大型演示应用合集,所有这些都由全球社区贡献。
追溯Hugging Face的起源
Hugging Face由法国企业家Clement Delangue、Julien Chaumond和Thomas Wolf创立。他们最初的设想是构建一个由AI驱动的聊天机器人,但他们发现开发人员和研究人员在访问预训练模型和实现尖端算法方面存在困难。随后,Hugging Face转向创建机器学习工作流程工具和开源机器学习平台。
Image by Author
参与Hugging Face开源AI社区
Hugging Face处于工具和资源的核心地位,提供了机器学习工作流程所需的一切。Hugging Face为AI提供了所有这些工具和资源。Hugging Face不仅仅是一家公司,更是推动AI时代发展的全球社区。
Hugging Face提供了一套工具,例如:
- Transformers 库: 用于跨任务(如文本分类和摘要等)访问预训练模型。
- Datasets 库: 提供对精选自然语言处理 (NLP)、视觉和音频数据集的轻松访问。这可以为您节省时间,避免从头开始。
- Model Hub (模型中心): 这是研究人员和开发人员分享并为您提供测试和下载适用于您正在构建的任何项目预训练模型的地方。
- Spaces (空间): 您可以使用Gradio和Streamlit在此构建和托管您的演示。
真正将Hugging Face与其他AI和机器学习平台区分开来的是其开源方法,它允许来自世界各地的研究人员和开发人员为AI社区做出贡献、开发和改进。
解决关键的机器学习挑战
机器学习具有变革性,但多年来它也面临着一些挑战。这包括从头开始训练大规模模型,需要巨大的计算资源,这些资源昂贵且大多数个人无法获得。准备数据集、调整模型架构以及将模型部署到生产环境中都极其复杂。
Hugging Face通过以下方式应对这些挑战:
- 通过预训练模型降低计算成本。
- 通过直观的API简化机器学习。
- 通过中央存储库促进协作。
Hugging Face通过多种方式减轻了这些挑战。通过提供预训练模型,开发人员可以跳过昂贵的训练阶段,即时开始使用最先进的模型。
Transformers 库提供了易于使用的 API,允许您仅用几行代码实现复杂的机器学习任务。此外,Hugging Face充当中央存储库,促进模型和数据集的无缝共享、协作和发现。
最终,我们实现了AI的民主化,无论种族或资源如何,任何人都可以构建和部署机器学习解决方案。这就是为什么Hugging Face在包括微软、谷歌、Meta等在内的各个行业中被接受,并将该技术集成到其工作流程中。
探索Hugging Face生态系统
Hugging Face的生态系统很广泛,包含了许多集成组件,可支持AI工作流的完整生命周期:
导航Hugging Face Hub
- AI工件的中央存储库:模型、数据集和应用程序(Spaces)。
- 支持公共和私有托管,提供版本控制、元数据和文档。
- 用户可以上传、下载、搜索和对AI资源进行基准测试。
要开始使用,请在浏览器中访问Hugging Face网站。主页界面简洁,提供探索模型、数据集和Spaces的选项。
Image by Author
处理模型
模型部分是Hugging Face Hub的中心。它提供跨越多种机器学习任务的数千个预训练模型,使您无需从头开始构建所有内容,就可以利用预训练模型来完成文本分类、摘要和图像识别等任务。
Image by Author
利用Transformers库
Transformers 库是旗舰级的开源SDK,它标准化了Transformer模型在跨任务(包括NLP、计算机视觉、音频和多模态学习)中的推理和训练使用方式。它具有以下特点:
- 支持超过数千种模型架构(例如 BERT、GPT、T5、ViT)。
- 为常见任务提供管道(pipelines),包括文本生成、分类、问答和视觉任务。
- 与PyTorch、TensorFlow和JAX集成,实现灵活的训练和推理。
访问Datasets库
Datasets库提供了以下工具:
- 从Hub发现、加载和预处理数据集。
- 通过流式传输、过滤和转换功能处理大型数据集。
- 高效管理训练、评估和测试拆分。
该库使得跨语言和任务使用真实世界数据进行实验变得更加容易,无需复杂的数据工程。
Image by Author
Hugging Face还维护着几个补充模型训练和部署的辅助库:
- Diffusers:用于使用扩散技术的生成图像/视频模型。
- Tokenizers:用Rust实现的超快速分词实现。
- PEFT:参数高效微调方法(LoRA, QLoRA)。
- Accelerate:简化分布式和高性能训练。
- Transformers.js:支持直接在浏览器或Node.js中进行模型推理。
- TRL (Transformers Reinforcement Learning):用于使用强化学习方法训练语言模型的工具。
使用Spaces构建
Spaces是轻量级的交互式应用程序,用于展示通常使用Gradio或Streamlit等框架构建的模型和演示。它们允许开发人员:
- 以最少的基础设施部署机器学习演示。
- 共享用于文本生成、图像编辑、语义搜索等的交互式可视化工具。
- 在不编写后端服务的情况下进行视觉实验。
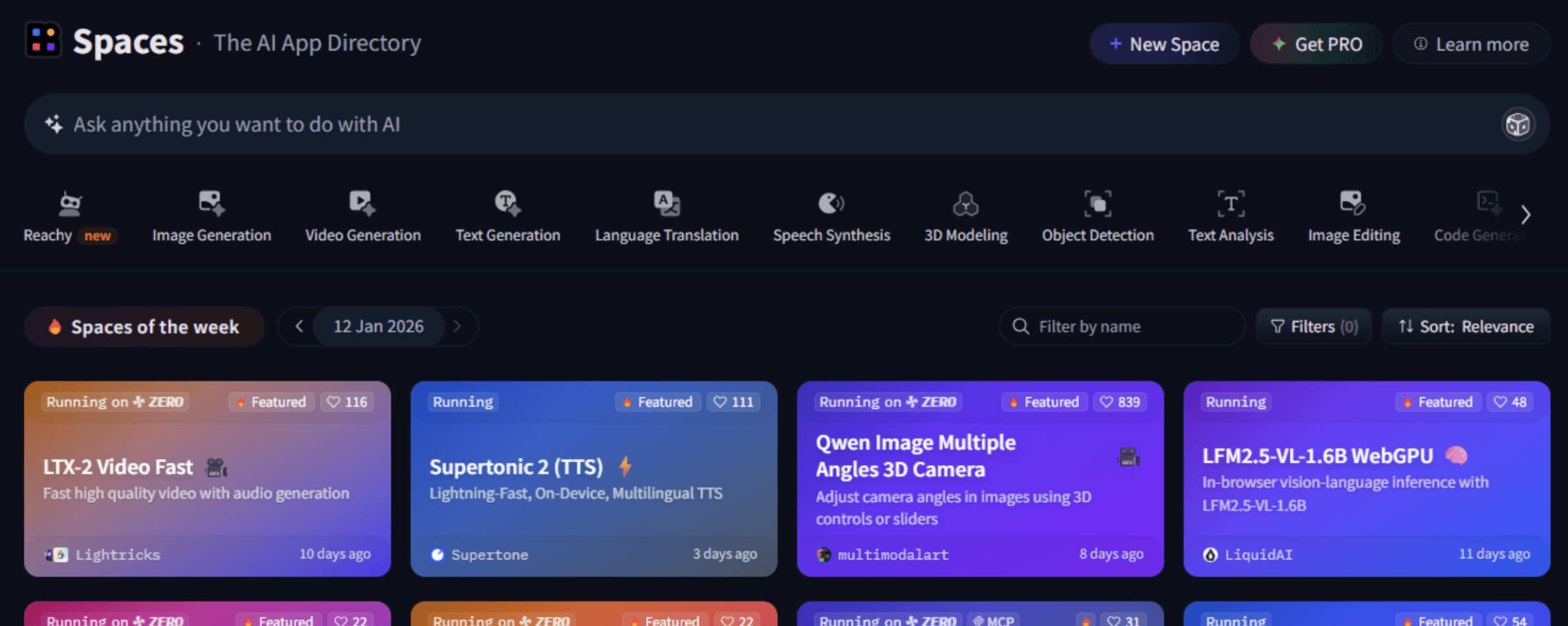
Image by Author
利用部署和生产工具
除了开源库之外,Hugging Face还提供生产级服务,例如:
- Inference API (推理API):这些 API 通过 REST API 实现托管模型推理,无需配置服务器,并且还支持扩展模型(包括大型语言模型)以支持实时应用。
- Inference Endpoints (推理端点):用于管理 GPU/TPU 端点,使团队能够以监控和日志记录支持的规模提供模型服务。
- Cloud Integrations (云集成):Hugging Face与AWS、Azure和Google Cloud等主流云提供商集成,使企业团队能够在其现有云基础设施内部署模型。
遵循简化的技术工作流程
以下是Hugging Face上的典型开发人员工作流程:
- 在Hub上搜索并选择一个预训练模型。
- 使用
Transformers在本地或云笔记本中加载和微调模型。 - 将微调后的模型和数据集上传回Hub并进行版本控制。
- 使用Inference API或Inference Endpoints进行部署。
- 通过Spaces共享演示。
此工作流程极大地加速了原型设计、实验和生产开发。
使用Gradio创建交互式演示
import gradio as gr
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
def predict(text):
result = classifier(text)[0] # extract first item
return {result["label"]: result["score"]}
demo = gr.Interface(
fn=predict,
inputs=gr.Textbox(label="Enter text"),
outputs=gr.Label(label="Sentiment"),
title="Sentiment Analysis Demo"
)
demo.launch()
您可以通过运行python后跟文件名来运行此代码。在我的情况下,是python demo.py以便下载,然后您将看到如下所示的内容。
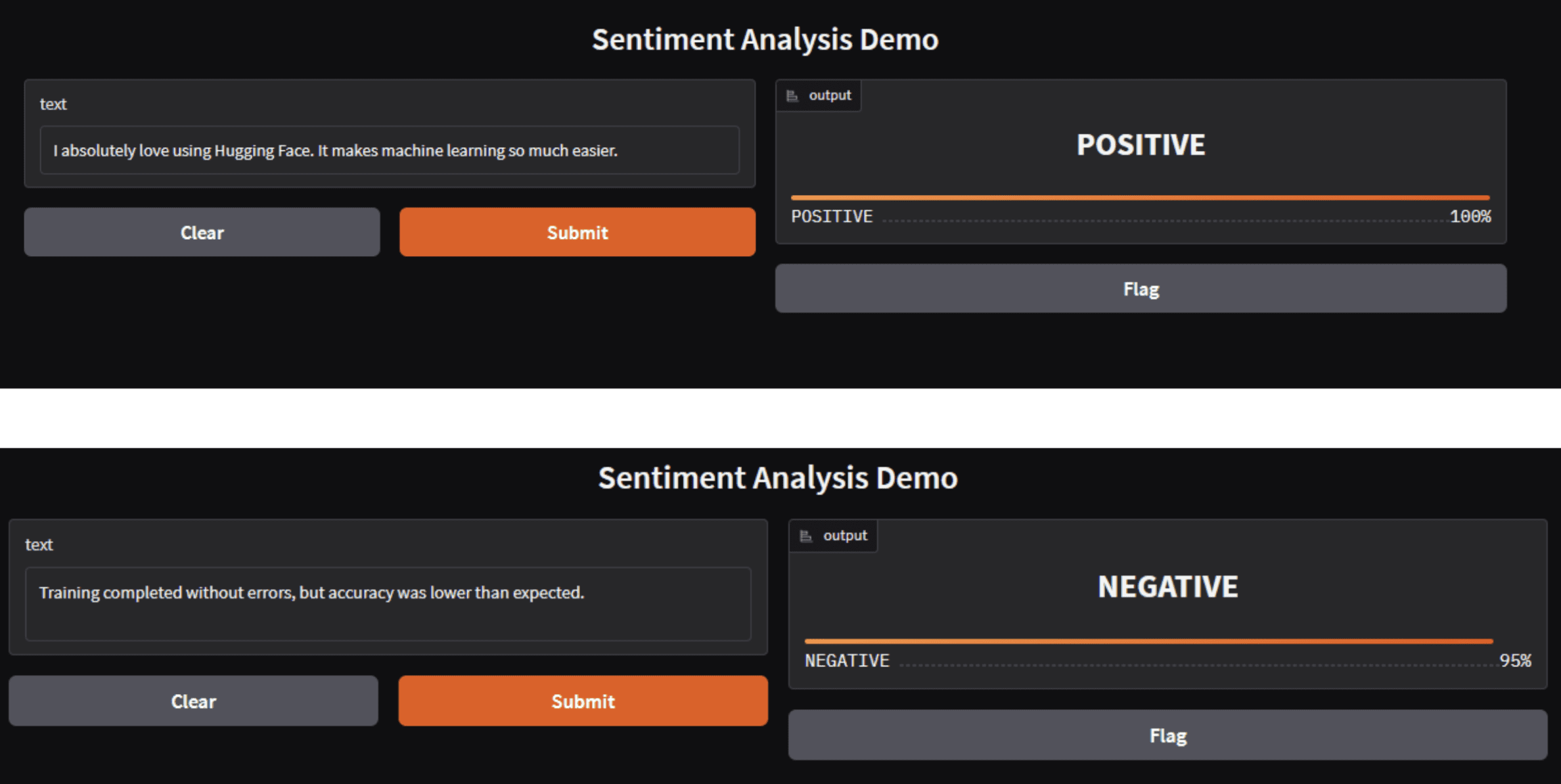
Image by Author
同一个应用可以直接作为Hugging Face Space进行部署。
请注意,Hugging Face
pipelines返回的预测结果是列表,即使是单次输入也是如此。当与Gradio的Label组件集成时,您必须提取第一个结果并返回一个映射标签到置信度分数的字符串标签或字典。不执行此操作会导致ValueError,因为输出类型不匹配。
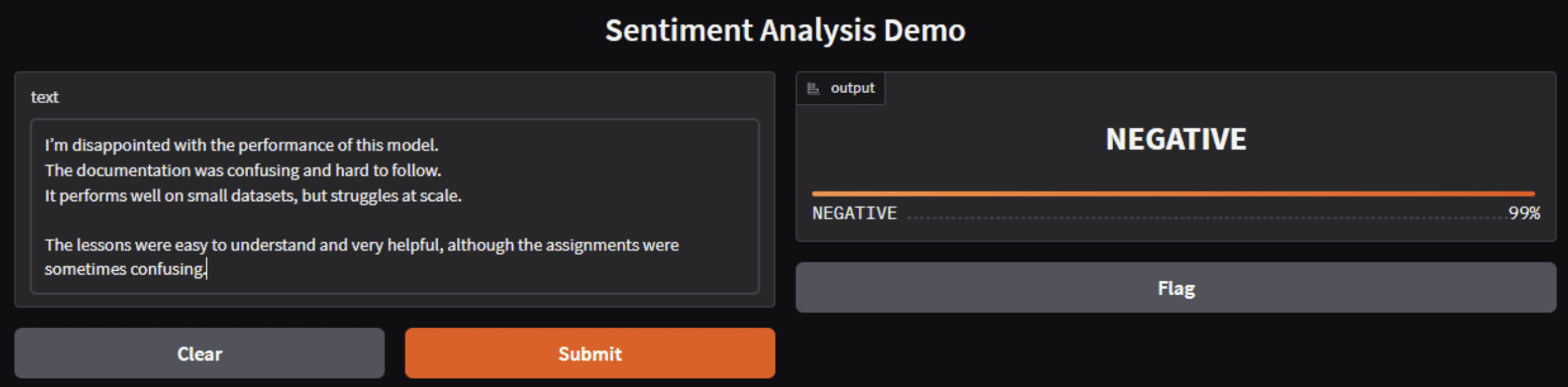
Image by Author
Hugging Face的情感模型对整体情绪进行分类,而不是单独的意见。当负面信号强于或多于正面信号时,即使存在一些正面反馈,模型也会自信地预测负面情绪。
您可能想知道为什么开发人员和组织使用Hugging Face;原因如下:
- 标准化:Hugging Face提供了一致的 API 和接口,规范了模型在不同语言和任务中的共享和使用方式。
- 社区协作:该平台的开放治理鼓励研究人员、教育工作者和行业开发人员的贡献,加速创新并实现社区驱动的模型和数据集改进。
- 民主化:通过提供易于使用的工具和现成的模型,AI开发对没有大量计算资源的学习者和组织来说变得更加容易。
- 企业级解决方案:Hugging Face提供企业功能,例如私有模型中心、基于角色的访问控制以及受监管行业所需的平台支持。
考虑挑战和局限性
虽然Hugging Face简化了机器学习生命周期的许多部分,但开发人员应注意以下几点:
- 文档复杂性:随着工具的发展,文档的深度各不相同;某些高级功能可能需要深入探索才能正确理解。(社区反馈指出生态系统部分文档质量不一)。
- 模型发现:Hub上有数百万个模型,找到正确的模型通常需要仔细的过滤和语义搜索方法。
- 道德和许可:开放存储库可能会引发内容使用和许可方面的挑战,特别是对于可能包含专有或受版权保护内容的由用户上传的数据集。有效治理和谨慎标记许可及预期用例至关重要。
结论
在2026年,Hugging Face已成为开放AI开发的中坚力量,提供涵盖研究和生产的丰富生态系统。其社区贡献、开源工具、托管服务和协作工作流程的结合,重塑了开发人员和组织处理机器学习的方式。无论您是训练尖端模型、部署 AI 应用,还是参与全球研究工作,Hugging Face都提供了加速创新的基础设施和社区支持。
Shittu Olumide 是一位软件工程师和技术作家,热衷于利用尖端技术来构建引人入胜的叙事,对细节有敏锐的洞察力,并擅长简化复杂概念。您也可以在Twitter上找到Shittu。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区