



📢 转载信息
原文链接:https://blogs.nvidia.com/blog/jetson-generative-ai-edge-oss/
原文作者:Chen Su
在今年早些时候的CES展会上,这款 机器能够回答问题。
在此次演示中,Cat AI Assistant运行在 NVIDIA Jetson Thor 上,这是一个专为工业和机器人系统中的实时推理而构建的边缘AI平台,并使用了 NVIDIA Nemotron 语音模型,以实现快速准确的自然语音交互。Qwen3 4B模型通过vLLM在本地运行,能够以低延迟解析请求并生成响应,无需连接云端。
除了企业创新,开源模型还为开发者提供了自由构建和实验的全新可能性。在NVIDIA Jetson上运行OpenClaw,使开发者能够创建私有的、始终在线的边缘AI助手——无需支付API费用,并能完全保护数据隐私。
所有Jetson开发者套件都支持OpenClaw,允许用户灵活切换2B到30B的开源模型。通过在本地运行一流的AI助手,用户可以实现晨报播报、自动化日常任务、代码审查以及智能家居控制——所有这些都能实时完成。
从云端到边缘
在它们最近的大部分发展历程中,开源模型主要运行在最容易支持它们的地方。
它们运行在数据中心,拥有弹性的计算能力和持久的网络连接。然而,云部署会带来延迟成本和持续的计算开销,这些成本会随着每一次查询而增加。
物理系统则需要优化不同的方面。低延迟对于需要与人及环境交互的机器至关重要。有限的功耗是因为设备本身有严格的限制。而一致的行为是因为任何变数都可能带来风险。
此外,还有供应问题。内存短缺导致整个行业成本上涨。Jetson将计算和内存集成在了一个系统级模块(SoM)中,加速了客户硬件的设计,并且相比离散组件的方案,在采购和验证方面更加容易。
随着模型效率的不断提高,开发者也开始提出不同的问题。不再是哪个模型在孤立运行时表现最好,而是将模型部署在哪里最合适。
越来越多的答案指向了设备端,从Jetson Orin Nano 8GB开始,即可支持入门级的生成式AI模型。
大规模构建自主物理AI系统
对于 物理AI 系统而言,生成式AI模型正在拓展其可能性。
卡特彼勒的(开发中)车载Cat AI Assistant,在本地运行语音和语言模型,并结合可信赖的机器上下文信息,以支持操作员的指导和安全功能。
在CES展会上, Franka Robotics 展示了其在机器人领域的应用。该公司FR3 Duo双臂系统在板载运行NVIDIA GR00T N1.6模型,实现了从感知到运动的全流程,无需任务脚本。策略直接在本地执行。
在机器人研究领域,来自NVIDIA GEAR Lab的 SONIC项目 利用超过1亿帧的运动捕捉数据训练了一个人形控制器,然后将生成的策略部署在一个物理机器人上,其中运动规划器运行在 Jetson Orin 上,每秒处理大约12毫秒。策略循环以50Hz运行,所有计算都在板载完成。
这种模式也延伸到了开发者社区。来自UIUC的SIGRobotics俱乐部团队使用Jetson Thor构建了一个双臂抹茶制作机器人,并运行GR00T N1.5模型。该项目在NVIDIA的具身AI黑客松中获得了第一名。
这种研究势头在纽约大学机器人与具身智能中心得以延续。该团队近期在Jetson Thor上运行了其 YOR机器人,并利用NVIDIA Blackwell计算能力处理AI驱动运动所需的重度计算。早期结果表明,YOR在处理复杂抓取任务时,对新物体和场景变化的泛化能力更强,鲁棒性更高,加速了其在烹饪和洗衣等各种家庭任务中的准备工作。
独立研究人员也发现了同样的趋势。Hugging Face的跨模态研究主管Andrés Marafioti在Jetson AGX Orin上构建了一个代理AI系统,该系统能够跨模型路由任务并自行安排工作。一天深夜,该代理向他发送了一条消息:去睡觉吧,一切都会在早上准备好。
来自Collabnix社区的开发者Ajeet Singh Raina展示了如何在NVIDIA Jetson Thor上运行 OpenClaw,以实现一个可以24/7运行的个人AI助手。该设置允许用户在本地进行个人大语言模型推理,处理用户自己的数据,同时系统通过本地网关管理电子邮件和日历。
Jetson成为新标准
NVIDIA Jetson已成为在边缘端运行开源模型的通用平台。
它支持广泛的开源模型和AI框架,为开发者在边缘端的几乎任何生成式AI工作负载提供了灵活性。
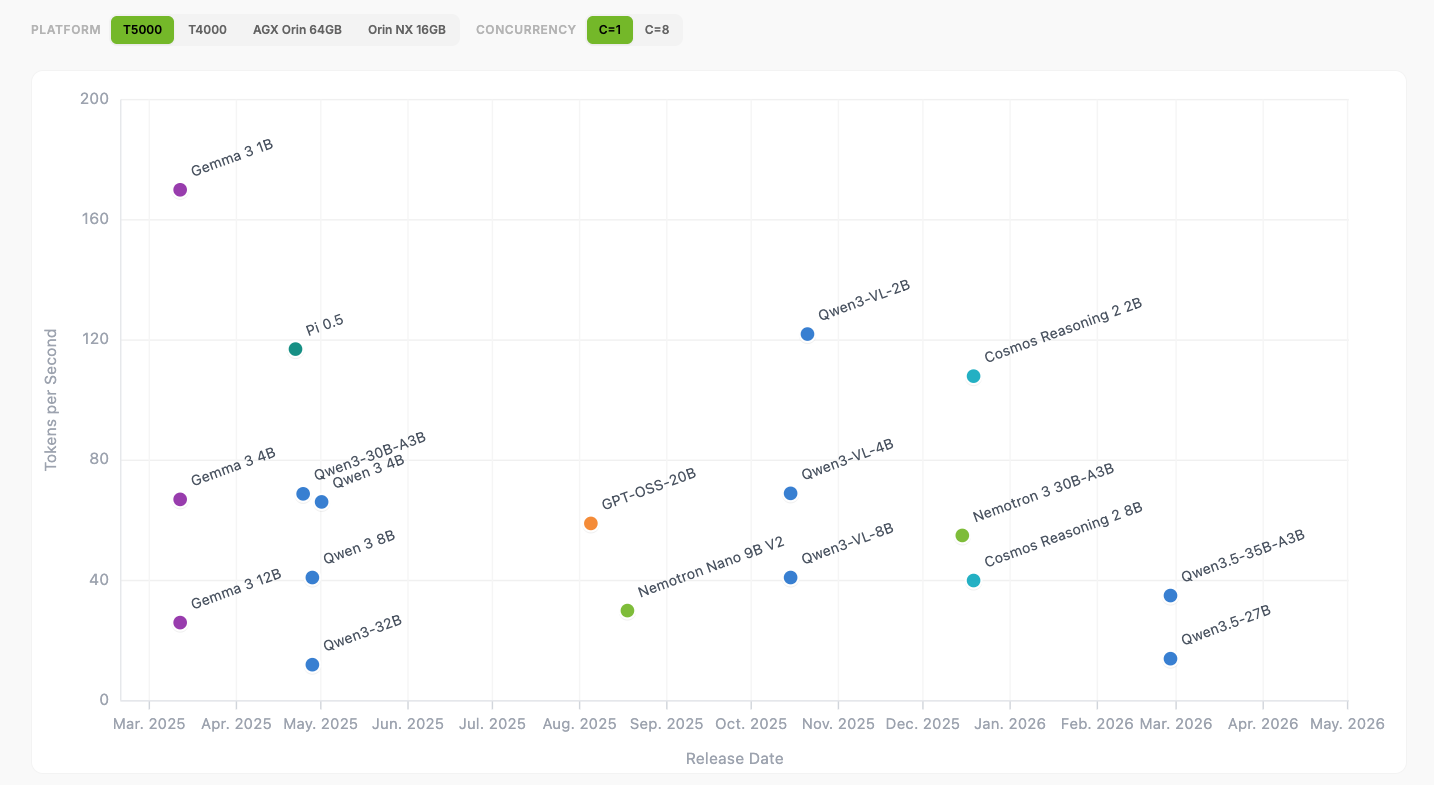
模型基准测试可在 Jetson AI Lab 上找到,同时也有来自开源社区的教程。Jetson Thor在所有主流生成式AI模型上都提供了领先的推理性能。
Gemma: 该模型基于Google的Gemini研究构建,是Jetson的多功能主力。它开箱即支持多模态,这意味着它可以理解视觉信息并以超过140种语言进行交流。在Jetson Thor上,它能够处理高达128K的上下文窗口,非常适合需要记住长串复杂或多步指令的机器人。
gpt-oss-20B: 这个来自OpenAI的模型,通过在Jetson Thor和Orin上本地运行,实现了接近最先进的推理性能,从而降低了部署先进AI的门槛,实现了成本效益高的推理。
Mistral AI: 新的Mistral 3开源模型系列为开发者和企业提供了行业领先的准确性、效率和定制化能力。该系列包含了3B到14B的小型、密集模型,速度快且与其尺寸相比非常智能。Jetson开发者可以使用NVIDIA Jetson Thor上的vLLM容器,在单个并发下达到每秒52个token,在并发为8时可扩展至每秒273个token。
NVIDIA Cosmos 这是一个领先的、开放的、推理型的视觉语言模型,使机器人和AI代理能够像人类一样在物理世界中观察、理解和行动。8B和2B模型都在Jetson上运行,提供先进的时空感知和推理能力。
NVIDIA Isaac GR00T N1.6 是一个通用的机器人技能的开放视觉语言动作(VLA)模型。开发者可以利用它来构建能够在各种任务、环境和载体中感知环境、理解指令并执行动作的机器人。在Jetson Thor上,完整的GR00T N1.6流水线在板载执行,提供实时的感知、空间感知和响应式动作。
NVIDIA Nemotron: 一个由开放模型、数据集和技术组成的家族,使用户能够构建高效、准确和专业的代理AI系统。它专为高级推理、编码、视觉理解、代理任务、安全、语音和信息处理而设计。Nemotron 3 Nano 9B模型使用llama.cpp在Jetson Orin Nano Super上有效运行,性能为每秒9个token。
PI 0.5: 来自Physical Intelligence的VLA模型,使机器人能够理解指令并自主执行复杂的现实世界任务,具有强大的泛化能力和实时适应性,而NVIDIA Jetson Thor提供每秒120个动作token,以支持响应式、低延迟的物理AI部署。
Qwen 3.5: 阿里巴巴的这一模型家族,包括最新的Qwen 3.5版本,提供了密集模型和专家混合(MoE)模型的组合,在推理、编码、多模态理解和长上下文性能方面表现出色。Jetson Thor在Qwen模型上实现了优化性能,例如 Qwen 3.5-35B-A3B 模型,推理速度为每秒35个token,使得实时交互成为可能。
任何开发者都可以微调这些模型,以创建专门的物理AI代理,并将它们无缝部署到物理AI系统中。NVIDIA Jetson平台支持NVIDIA TRT、Llama.cpp、Ollama、vLLM、SGLang等流行AI框架。

在Jetson上使用开源模型
开发者可以深入研究Hugging Face上的教程——包括 在Jetson上部署开源视觉语言模型——并观看最新的 直播。通过此教程学习如何在NVIDIA Jetson上运行OpenClaw。
加入下个月的 GTC 2026,亲眼见证这一切。NVIDIA将展示开源模型如何从数据中心走向物理世界的机器,包括在关于“工业自主的未来”的小组讨论中。
观看NVIDIA创始人兼CEO黄仁勋的 GTC主题演讲,并探索 物理AI、机器人和视觉AI相关会议。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区