



📢 转载信息
原文链接:https://www.kdnuggets.com/postgres-vs-mysql-vs-sqlite-comparing-sql-performance-across-engines
原文作者:Nate Rosidi, KDnuggets Market Trends & SQL Content Specialist
Postgres vs MySQL vs SQLite:跨引擎的SQL性能对比
检查使用真实世界分析问题的三个流行SQL数据库的实际基准测试。
作者:Nate Rosidi, KDnuggets 市场趋势与SQL内容专家, 发布于 2026年3月10日 in SQL

图片来源:作者
# 引言
在设计应用程序时,选择正确的SQL数据库引擎会对性能产生重大影响。
三个常见的选项是 PostgreSQL、MySQL 和 SQLite。这些引擎各有独特的优势和优化策略,适合不同的场景。
PostgreSQL通常在处理复杂的分析查询方面表现出色,MySQL也能提供强大的通用性能。另一方面,SQLite为嵌入式应用程序提供了一个轻量级的解决方案。
在本文中,我们将使用四个分析性面试问题来对这三个引擎进行基准测试:两个中等难度,两个高难度。
在每一个问题中,目标是考察每个引擎如何处理 连接(joins)、窗口函数、日期算术和复杂聚合。这将突出特定平台的优化策略,并提供有关每个引擎性能和规格的有用见解。
# 理解三个SQL引擎
在深入基准测试之前,让我们先了解这三个数据库系统之间的区别。
PostgreSQL 是一个功能丰富、开源的关系型数据库,以其先进的SQL合规性和复杂的查询优化而闻名。它能有效地处理复杂的分析查询,对窗口函数、公用表表达式(CTEs)和多种索引策略有强大的支持。
MySQL 是使用最广泛的开源数据库,因其在Web应用程序中的速度和准确性而受到青睐。尽管它历史上侧重于事务性工作负载,但现代版本的该引擎包含了全面的分析功能,支持窗口函数并改进了查询优化。
SQLite 是一个轻量级的引擎,直接嵌入到应用程序中。与前两个作为独立服务器进程运行的引擎不同,SQLite作为一个库运行,非常适合移动应用程序、桌面程序和开发环境。
然而,正如你可能预期的那样,这种简洁性也带来了一些限制,例如并发写入操作和某些SQL功能。
本文的基准测试使用了四个测试不同SQL功能能力的面试问题。 对于每个问题,我们将分析所有三个引擎的查询解决方案,突出它们的语法差异、性能考量和优化机会。
我们将测试它们在执行时间方面的性能。Postgres和MySQL在StrataScratch平台(服务器端)上进行了基准测试,而SQLite在内存中本地进行了基准测试。
# 解决中等难度问题
// 回答面试题 #1: 高风险项目
这个面试题要求你根据分摊的员工薪资来识别超出预算的项目。
数据表:提供了三个表:linkedin_projects(包含预算和日期)、linkedin_emp_projects 和 linkedin_employees。
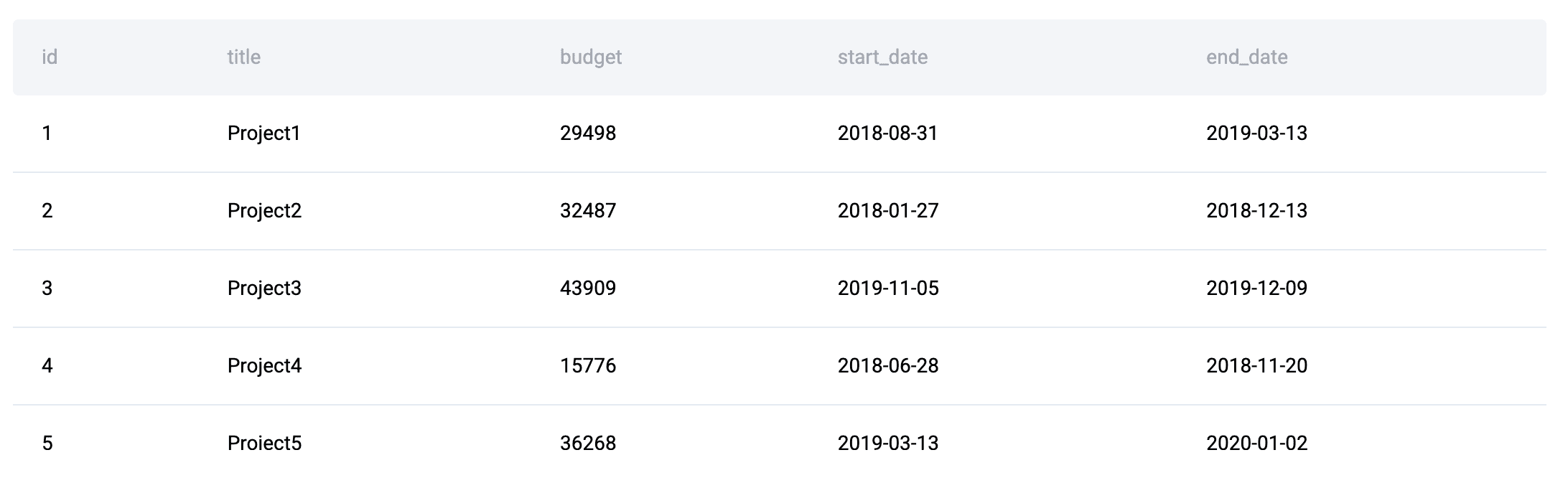

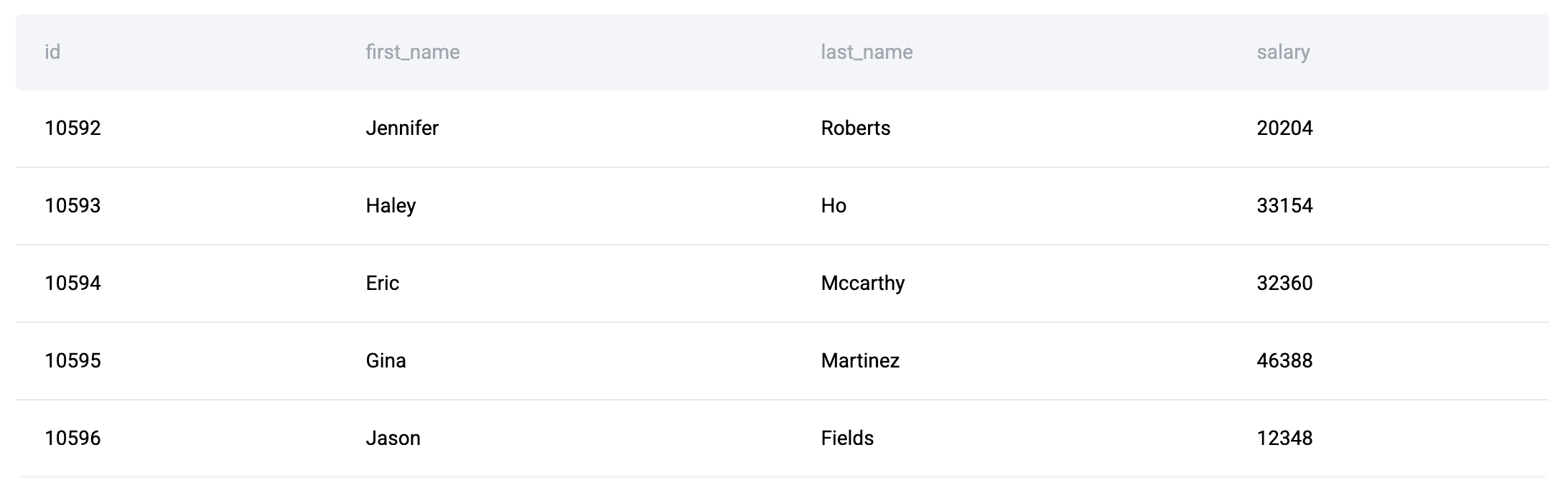
目标是计算每位员工年薪分摊到每个项目的比例,并确定哪些项目超出了预算。
在PostgreSQL中,解决方案如下:
SELECT a.title, a.budget, CEILING((a.end_date - a.start_date) * SUM(c.salary) / 365) AS prorated_employee_expense FROM linkedin_projects a INNER JOIN linkedin_emp_projects b ON a.id = b.project_id INNER JOIN linkedin_employees c ON b.emp_id = c.id GROUP BY a.title, a.budget, a.end_date, a.start_date HAVING CEILING((a.end_date - a.start_date) * SUM(c.salary) / 365) > a.budget ORDER BY a.title ASC;PostgreSQL优雅地处理日期算术,直接进行减法(end_date - start_date),返回日期之间的天数。
由于该引擎原生的日期处理能力,计算简单易读。
在MySQL中,解决方案是:
SELECT a.title, a.budget, CEILING(DATEDIFF(a.end_date, a.start_date) * SUM(c.salary) / 365) AS prorated_employee_expense FROM linkedin_projects a INNER JOIN linkedin_emp_projects b ON a.id = b.project_id INNER JOIN linkedin_employees c ON b.emp_id = c.id GROUP BY a.title, a.budget, a.end_date, a.start_date HAVING CEILING(DATEDIFF(a.end_date, a.start_date) * SUM(c.salary) / 365) > a.budget ORDER BY a.title ASC;在MySQL中,需要使用DATEDIFF()函数进行日期算术,该函数明确计算两个日期之间的天数。
虽然这增加了一个函数调用,但MySQL的查询优化器可以高效地处理它。
最后,我们来看看SQLite的解决方案:
SELECT a.title, a.budget, CAST( (julianday(a.end_date) - julianday(a.start_date)) * (SUM(c.salary) / 365) + 0.99 AS INTEGER) AS prorated_employee_expense FROM linkedin_projects a INNER JOIN linkedin_emp_projects b ON a.id = b.project_id INNER JOIN linkedin_employees c ON b.emp_id = c.id GROUP BY a.title, a.budget, a.end_date, a.start_date HAVING CAST( (julianday(a.end_date) - julianday(a.start_date)) * (SUM(c.salary) / 365) + 0.99 AS INTEGER) > a.budget ORDER BY a.title ASC;SQLite使用julianday()函数将日期转换为数值进行算术运算。
由于SQLite没有CEILING()函数,我们可以通过添加0.99并转换为整数来模拟它,这样可以准确地向上取整。
// 优化查询
对于这三种引擎,可以在连接列(project_id、emp_id、id)上使用索引来显著提高性能。PostgreSQL的优势在于对GROUP BY子句使用(title, budget, end_date, start_date)的复合索引。
正确使用主键至关重要,因为MySQL的InnoDB引擎会自动按主键对数据进行聚簇。
// 回答面试题 #2: 查找用户购买记录
这个面试题的目标是输出那些在第一次购买后1到7天内(不包括当天重复购买)进行了第二次购买的重复客户的ID。
数据表:唯一的表是amazon_transactions。它包含交易记录,有id、user_id、item、created_at和revenue。

PostgreSQL解决方案:
WITH daily AS ( SELECT DISTINCT user_id, created_at::date AS purchase_date FROM amazon_transactions ), ranked AS ( SELECT user_id, purchase_date, ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY purchase_date) AS rn FROM daily ), first_two AS ( SELECT user_id, MAX(CASE WHEN rn = 1 THEN purchase_date END) AS first_date, MAX(CASE WHEN rn = 2 THEN purchase_date END) AS second_date FROM ranked WHERE rn <= 2 GROUP BY user_id ) SELECT user_id FROM first_two WHERE second_date IS NOT NULL AND (second_date - first_date) BETWEEN 1 AND 7 ORDER BY user_id;在PostgreSQL中,解决方案是使用CTEs(公用表表达式)将问题分解为逻辑清晰、易于阅读的步骤。
日期强制转换函数将时间戳转换为日期,而带有ROW_NUMBER()的窗口函数按时间顺序对购买记录进行排名。PostgreSQL固有的日期减法功能使最终的过滤条件简洁有效。
MySQL解决方案:
WITH daily AS ( SELECT DISTINCT user_id, DATE(created_at) AS purchase_date FROM amazon_transactions ), ranked AS ( SELECT user_id, purchase_date, ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY purchase_date) AS rn FROM daily ), first_two AS ( SELECT user_id, MAX(CASE WHEN rn = 1 THEN purchase_date END) AS first_date, MAX(CASE WHEN rn = 2 THEN purchase_date END) AS second_date FROM ranked WHERE rn <= 2 GROUP BY user_id ) SELECT user_id FROM first_two WHERE second_date IS NOT NULL AND DATEDIFF(second_date, first_date) BETWEEN 1 AND 7 ORDER BY user_id;MySQL的解决方案与之前的PostgreSQL结构类似,使用CTEs和窗口函数。
主要区别在于使用DATE()和DATEDIFF()函数进行日期提取和比较。MySQL 8.0+支持CTEs,而早期版本需要子查询。
SQLite解决方案:
WITH daily AS ( SELECT DISTINCT user_id, DATE(created_at) AS purchase_date FROM amazon_transactions ), ranked AS ( SELECT user_id, purchase_date, ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY purchase_date) AS rn FROM daily ), first_two AS ( SELECT user_id, MAX(CASE WHEN rn = 1 THEN purchase_date END) AS first_date, MAX(CASE WHEN rn = 2 THEN purchase_date END) AS second_date FROM ranked WHERE rn <= 2 GROUP BY user_id ) SELECT user_id FROM first_two WHERE second_date IS NOT NULL AND (julianday(second_date) - julianday(first_date)) BETWEEN 1 AND 7 ORDER BY user_id;SQLite(版本3.25+)也支持CTEs和窗口函数,使其结构与前两个相同。在这种情况下,唯一的区别是日期算术,它使用julianday()而不是原生的减法或DATEDIFF()。
// 优化查询
在这种情况下,也可以为窗口函数中的有效分区(特别是user_id)使用索引。PostgreSQL可以从活动用户的部分索引中受益。 如果处理大量数据集,也可以考虑在PostgreSQL中物化daily CTE。为了获得MySQL的最佳CTE性能,请确保您使用的是8.0+版本。
# 解决高难度问题
// 回答面试题 #3: 随时间推移的收入
这个问题面试题要求你计算购买收入的3个月滚动平均值。
目标是按时间顺序输出年月值及其相应的滚动平均值。排除(负购买金额)的交易。
数据表: amazon_purchases:包含交易记录,有user_id、created_at和purchase_amt。

首先,让我们检查PostgreSQL的解决方案:
SELECT t.month, AVG(t.monthly_revenue) OVER( ORDER BY t.month ROWS BETWEEN 2 PRECEDING AND CURRENT ROW ) AS avg_revenue FROM ( SELECT to_char(created_at::date, 'YYYY-MM') AS month, sum(purchase_amt) AS monthly_revenue FROM amazon_purchases WHERE purchase_amt > 0 GROUP BY to_char(created_at::date, 'YYYY-MM') ORDER BY to_char(created_at::date, 'YYYY-MM') ) t ORDER BY t.month ASC;PostgreSQL通过窗口函数取得了优越的性能,其中框架规范ROWS BETWEEN 2 PRECEDING AND CURRENT ROW精确定义了滚动窗口。 to_char()函数将日期格式化为年月字符串以进行分组。
接下来是MySQL解决方案:
SELECT t.`month`, AVG(t.monthly_revenue) OVER( ORDER BY t.`month` ROWS BETWEEN 2 PRECEDING AND CURRENT ROW ) AS avg_revenue FROM ( SELECT DATE_FORMAT(created_at, '%Y-%m') AS month, sum(purchase_amt) AS monthly_revenue FROM amazon_purchases WHERE purchase_amt > 0 GROUP BY DATE_FORMAT(created_at, '%Y-%m') ORDER BY DATE_FORMAT(created_at, '%Y-%m') ) t ORDER BY t.`month` ASC;MySQL的实现以相同的方式处理窗口函数,但它使用DATE_FORMAT()函数而不是to_char()。
请注意,此引擎有一个特定的语法要求,以避免关键字冲突,因此month周围使用了反引号。
最后,SQLite的解决方案是:
SELECT t.month, AVG(t.monthly_revenue) OVER( ORDER BY t.month ROWS BETWEEN 2 PRECEDING AND CURRENT ROW ) AS avg_revenue FROM ( SELECT strftime('%Y-%m', created_at) AS month, SUM(purchase_amt) AS monthly_revenue FROM amazon_purchases WHERE purchase_amt > 0 GROUP BY strftime('%Y-%m', created_at) ORDER BY strftime('%Y-%m', created_at) ) t ORDER BY t.month ASC;日期格式化在SQLite中需要使用strftime(),并且该引擎支持与PostgreSQL和MySQL相同的窗口函数语法(在版本3.25+中)。对于中小数据集,性能相当。
// 优化查询
窗口函数使用起来可能计算成本很高。
对于PostgreSQL,请考虑在created_at上创建索引,如果此查询频繁运行,可以为月度聚合创建物化视图。
MySQL受益于包含created_at和purchase_amt的覆盖索引。
对于SQLite,您需要使用3.25或更高版本才能获得窗口函数支持。
// 回答面试题 #4: 共同朋友的朋友
继续下一个面试题,这个问题要求你计算每个用户的朋友中,也是该用户其他朋友的朋友的数量(本质上是网络中的共同连接)。目标是输出用户ID以及这些共同朋友的朋友关系的计数。
数据表: google_friends_network:包含朋友关系,有user_id和friend_id。

PostgreSQL解决方案是:
WITH bidirectional_relationship AS ( SELECT user_id, friend_id FROM google_friends_network UNION SELECT friend_id AS user_id, user_id AS friend_id FROM google_friends_network ) SELECT user_id, COUNT(DISTINCT friend_id) AS n_friends FROM ( SELECT DISTINCT a.user_id, c.user_id AS friend_id FROM bidirectional_relationship a INNER JOIN bidirectional_relationship b ON a.friend_id = b.user_id INNER JOIN bidirectional_relationship c ON b.friend_id = c.user_id AND c.friend_id = a.user_id ) base GROUP BY user_id;在PostgreSQL中,这个复杂的多连接查询由其复杂的查询规划器高效处理。
初始CTE创建了一个双向的连接视图,随后进行了三次自连接,以识别三角形关系,其中A是B的朋友,B是C的朋友,C也是A的朋友。
MySQL解决方案:
SELECT user_id, COUNT(DISTINCT friend_id) AS n_friends FROM ( SELECT DISTINCT a.user_id, c.user_id AS friend_id FROM ( SELECT user_id, friend_id FROM google_friends_network UNION SELECT friend_id AS user_id, user_id AS friend_id FROM google_friends_network ) AS a INNER JOIN ( SELECT user_id, friend_id FROM google_friends_network UNION SELECT friend_id AS user_id, user_id AS friend_id FROM google_friends_network ) AS b ON a.friend_id = b.user_id INNER JOIN ( SELECT user_id, friend_id FROM google_friends_network UNION SELECT friend_id AS user_id, user_id AS friend_id FROM google_friends_network ) AS c ON b.friend_id = c.user_id AND c.friend_id = a.user_id ) base GROUP BY user_id;MySQL解决方案重复了三次UNION子查询,而不是使用单个CTE。
尽管不太优雅,但对于8.0之前的MySQL版本是必需的。现代MySQL版本可以使用PostgreSQL的方法配合CTEs,以获得更好的可读性和潜在的性能提升。
SQLite解决方案:
WITH bidirectional_relationship AS ( SELECT user_id, friend_id FROM google_friends_network UNION SELECT friend_id AS user_id, user_id AS friend_id FROM google_friends_network ) SELECT user_id, COUNT(DISTINCT friend_id) AS n_friends FROM ( SELECT DISTINCT a.user_id, c.user_id AS friend_id FROM bidirectional_relationship a INNER JOIN bidirectional_relationship b ON a.friend_id = b.user_id INNER JOIN bidirectional_relationship c ON b.friend_id = c.user_id AND c.friend_id = a.user_id ) base GROUP BY user_id;SQLite支持CTEs,并且处理此查询的方式与PostgreSQL相同。
然而,由于SQLite更简单的查询优化器和缺乏高级索引策略,性能可能会随着大型网络的处理而下降。
// 优化查询
对于所有引擎,可以在(user_id, friend_id)上创建复合索引以提高性能。在PostgreSQL中,当work_mem配置适当的情况下,可以对大型数据集使用哈希连接。
对于MySQL,请确保InnoDB缓冲池的大小合适。SQLite在处理非常大的网络时可能会遇到困难。为此,可以考虑反规范化或预先计算关系以用于生产环境。
# 性能对比
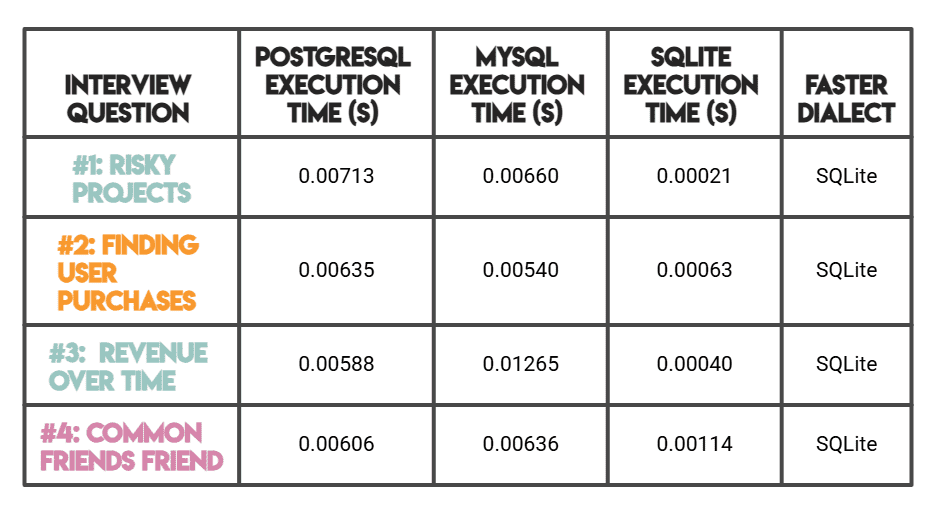
注意:如前所述,PostgreSQL和MySQL在StrataScratch平台(服务器端)上进行了基准测试,而SQLite在内存中本地进行了基准测试。
SQLite显著更快的运行时间是有道理的,这得益于其无服务器、零开销的架构(而不是卓越的查询优化)。
对于服务器到服务器的比较,MySQL在较简单的查询(#1、#2)上优于PostgreSQL,而在复杂的分析工作负载(#3、#4)上,PostgreSQL则更快。
# 分析关键性能差异
在这些基准测试中,出现了几个模式:
SQLite是所有四个问题的最快引擎,通常具有显著的优势。这主要归因于其无服务器、内存中架构,没有网络开销或客户端-服务器通信;对于小数据集,查询执行几乎是瞬时的。
然而,这种速度优势在数据集较小时最为明显。
PostgreSQL在复杂的分析查询方面表现出比MySQL更优越的性能,特别是在涉及窗口函数和多个CTE(问题#3和#4)的情况下。其复杂的查询规划器和广泛的索引选项使其成为数据仓库和分析工作负载的首选,在这些工作负载中,查询复杂性比原始简单性更重要。
MySQL在简单的中等难度查询(#1和#2)上胜过PostgreSQL,提供了具有DATEDIFF()等简单语法要求的有竞争力的性能。它的优势在于高并发事务性工作负载,尽管现代版本也能很好地处理分析查询。
简而言之,SQLite在轻量级、嵌入式用例(中小数据集)方面表现出色,PostgreSQL是处理大规模复杂分析的最佳选择,而MySQL在性能和通用可靠性之间取得了稳固的平衡。

# 结论
通过本文,您将了解PostgreSQL、MySQL和SQLite之间的一些细微差别,从而能够为您的特定需求选择合适的工具。

再次,我们看到MySQL在通用可靠性方面提供了强大的性能平衡,而PostgreSQL则在复杂的分析方面表现出色,具有先进的SQL功能。同时,SQLite为嵌入式环境提供了轻量级的简洁性。
通过了解每个引擎如何执行特定的SQL操作,您可以获得比仅仅选择“最佳”引擎更好的性能。利用MySQL的覆盖索引或PostgreSQL的部分索引等引擎特定功能,索引您的连接和过滤列,并始终使用EXPLAIN或EXPLAIN ANALYZE子句来理解查询执行计划。
通过这些基准测试,您现在应该能够就数据库选择和优化策略做出明智的决定,这些策略直接影响您实现}^{(e.g. 'a' or 'an's')}的性能。
Nate Rosidi是一位数据科学家,专注于产品战略。他还是教授分析学的兼职讲师,并且是StrataScratch的创始人,该平台通过顶尖公司的真实面试题帮助数据科学家为面试做准备。Nate撰写有关职业市场最新趋势的文章,提供面试建议,分享数据科学项目,并涵盖所有SQL相关内容。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区