



📢 转载信息
原文作者:Bashir Mohammed, Bala Krishnamoorthy, Greg Fina, David Stewart, Matthew Persons
本文由 Oumi 的 David Stewart 和 Matthew Persons 联合撰写。
对开源大语言模型 (LLM) 进行微调,常常在实验和生产之间陷入停滞。训练配置、构件管理和可扩展部署都需要不同的工具,在从快速实验转向安全、企业级环境时会产生阻碍。
在本文中,我们将展示如何使用 Oumi 在 Amazon EC2 上微调 Llama 模型(可以选择使用 Oumi 创建合成数据),将构件存储在 Amazon S3 中,并通过 自定义模型导入 部署到 Amazon Bedrock 进行托管推理。虽然本教程中使用的是 EC2,但微调也可以在其他计算服务上完成,例如 Amazon SageMaker 或 Amazon Elastic Kubernetes Service,具体取决于您的需求。
Oumi 和 Amazon Bedrock 的优势
Oumi 是一个开源系统,可简化基础模型的生命周期,从数据准备和训练到评估。您无需为每个阶段组装不同的工具,只需定义一个配置,并在运行之间重复使用它。
此工作流程的关键优势包括:
- 驱动式训练:一次定义您的配置,并在实验中重复使用,减少样板代码并提高可复现性。
- 灵活的微调:根据您的约束选择完全微调或参数高效方法,如 LoRA。
- 集成评估:使用基准测试或 LLM 作为裁判来评估检查点,无需额外工具。
- 数据合成:当生产数据有限时,生成任务特定的数据集。
Amazon Bedrock 通过提供托管、无服务器推理来补充这一点。使用 Oumi 微调后,您可以通过 自定义模型导入 分三步导入模型:上传到 S3,创建导入作业,然后调用。无需管理推理基础设施。下图展示了这些组件如何协同工作。
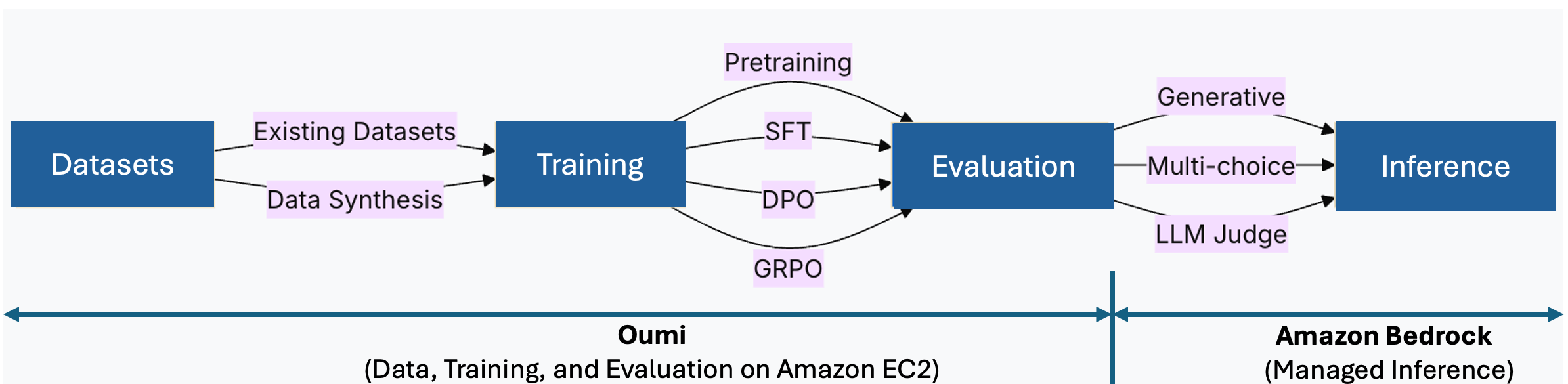
图 1:Oumi 在 EC2 上管理数据、训练和评估。Amazon Bedrock 通过自定义模型导入提供托管推理。
解决方案概述
此工作流程包含三个阶段:
- 使用 EC2 上的 Oumi 进行微调:启动 GPU 优化实例(例如,g5.12xlarge 或 p4d.24xlarge),安装 Oumi,并使用您的配置运行训练。对于更大的模型,Oumi 支持跨多 GPU 或多节点设置的分布式训练,支持 Fully Sharded Data Parallel (FSDP)、DeepSpeed 和 Distributed Data Parallel (DDP) 策略。
- 在 S3 上存储构件:上传模型权重、检查点和日志以实现持久存储。
- 部署到 Amazon Bedrock:创建一个指向您的 S3 构件的 自定义模型导入作业。Amazon Bedrock 会自动配置推理基础设施。客户端应用程序使用 Amazon Bedrock Runtime API 调用导入的模型。
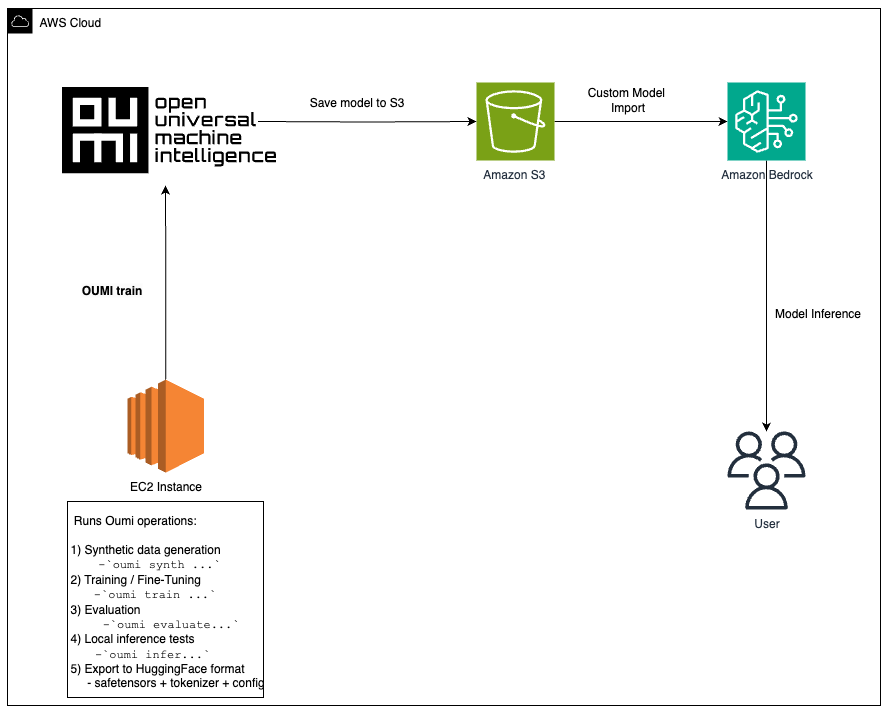
该架构解决了将微调模型投入生产中常见的挑战:
| 挑战 | Oumi 和 Amazon Bedrock 解决方案 |
| 迭代速度 | Oumi 的模块化配方支持跨配置的快速实验。 |
| 可复现性 | S3 存储版本化的检查点和训练元数据。 |
| 可扩展推理 | Amazon Bedrock 自动扩展,无需手动配置 GPU。 |
| 安全与合规 | AWS Identity and Access Management (IAM)、Amazon Virtual Private Cloud (VPC) 和 AWS Key Management Services (KMS) 原生集成。 |
| 成本优化 | 训练使用 Amazon EC2 Spot Instances;推理使用 Amazon Bedrock 定制模型的 5 分钟间隔 定价。 |
技术实现
让我们以 meta-llama/Llama-3.2-1B-Instruct 模型为例,进行一次实际操作。虽然我们选择这个模型是因为它与在 AWS g6.12xlarge EC2 实例上进行微调效果很好,但相同的流程可以复制到许多其他开源模型上(请注意,更大的模型可能需要更大的实例或跨实例的分布式训练)。更多信息,请参阅 Oumi 模型微调配方 和 Amazon Bedrock 自定义模型架构。
先决条件
要完成本教程,您需要:
- 一个 AWS 账户,在您的目标 AWS 区域(我们使用
us-west-2)拥有使用 EC2、S3 和 自定义模型导入 的权限。有关支持区域列表,请参阅 Amazon Bedrock 文档。 - 一个配置了凭证的 IAM 角色。该角色必须允许在 S3 中读写模型构件,并创建自定义模型导入作业。
- 已配置凭证的 AWS 命令行界面 (AWS CLI) 2.0 或更高版本,用于运行模型导入作业和调用模型。
- 一个 Hugging Face 账户和用于访问受限模型权重的 访问令牌(例如,meta-llama/Llama-3.2-1B-Instruct)。
- 配套的源代码仓库:github.com/aws-samples/sample-oumi-fine-tuning-bedrock-cmi
设置 AWS 资源
- 在此仓库的本地计算机上克隆:
git clone https://github.com/aws-samples/sample-oumi-fine-tuning-bedrock-cmi.git
cd sample-oumi-fine-tuning-bedrock-cmi- 运行设置脚本以创建 IAM 角色、S3 存储桶,并启动 GPU 优化 EC2 实例:
./scripts/setup-aws-env.sh [--dry-run]该脚本会提示您输入 AWS 区域、S3 存储桶名称、EC2 密钥对名称和安全组 ID,然后创建所有必需的资源。默认设置:g6.12xlarge 实例、带单个 CUDA 的深度学习基础 AMI(Amazon Linux 2023)以及 100 GB gp3 存储。注意:如果您没有创建 IAM 角色或启动 EC2 实例的权限,请将此仓库分享给您的 IT 管理员,并请他们完成此部分以设置您的 AWS 环境。
- 实例运行后,脚本会输出 SSH 命令和 Amazon Bedrock 导入角色 ARN(在第 5 步中使用)。SSH 进入实例并继续执行下面的第 1 步。
请参阅 iam/README.md 以获取 IAM 策略详细信息、范围指南和验证步骤。
第 1 步:设置 EC2 环境
完成以下步骤以设置 EC2 环境。
- 在 EC2 实例(Amazon Linux 2023)上,更新系统并安装基本依赖项:
sudo yum update -y
sudo yum install python3 python3-pip git -y- 克隆配套仓库:
git clone https://github.com/aws-samples/sample-oumi-fine-tuning-bedrock-cmi.git
cd sample-oumi-fine-tuning-bedrock-cmi- 配置环境变量(将值替换为设置脚本中的实际区域和存储桶名称):
export AWS_REGION=us-west-2
export S3_BUCKET=your-bucket-name export S3_PREFIX=your-s3-prefix aws configure set default.region "$AWS_REGION"- 运行设置脚本以创建 Python 虚拟环境,安装 Oumi,验证 GPU 可用性,并配置 Hugging Face 认证。有关选项,请参阅 setup-environment.sh。
./scripts/setup-environment.sh
source .venv/bin/activate- 通过 Hugging Face 进行身份验证,以访问受限模型权重。在 huggingface.co/settings/tokens 生成访问令牌,然后运行:
hf auth login第 2 步:配置训练
默认数据集是 tatsu-lab/alpaca,已在 configs/oumi-config.yaml 中配置。Oumi 会在训练期间自动下载它,无需手动下载。要使用不同的数据集,请更新 configs/oumi-config.yaml 中的 dataset_name 参数。有关支持的格式,请参阅 Oumi 数据集文档。
[可选] 使用 Oumi 生成合成训练数据:
要使用 Amazon Bedrock 作为推理后端生成合成数据,请在 configs/synthesis-config.yaml 中将 model_name 占位符更新为您有权访问的 Amazon Bedrock 模型 ID(例如,anthropic.claude-sonnet-4-6)。有关详细信息,请参阅 Oumi 数据合成文档。然后运行:
oumi synth -c configs/synthesis-config.yaml第 3 步:微调模型
使用 Oumi 内置的 训练配方 来微调 Llama-3.2-1B-Instruct 模型:
./scripts/fine-tune.sh --config configs/oumi-config.yaml --output-dir models/final [--dry-run]要自定义超参数,请编辑 oumi-config.yaml。
注意:如果您在第 2 步中生成了合成数据,请在训练前更新配置中的数据集路径。
使用 nvidia-smi 或 Amazon CloudWatch Agent 监控 GPU 利用率。对于长时间运行的作业,请配置 Amazon EC2 自动实例恢复 来处理实例中断。
第 4 步:评估模型(可选)
您可以使用标准基准来评估微调后的模型:
oumi evaluate -c configs/evaluation-config.yaml评估配置指定了模型路径和基准任务(例如,MMLU)。要进行自定义,请编辑 evaluation-config.yaml。有关 LLM 作为裁判的方法和其他基准测试,请参阅 Oumi 的 评估指南。
第 5 步:部署到 Amazon Bedrock
完成以下步骤将模型部署到 Amazon Bedrock:
- 将模型构件上传到 S3 并将模型导入 Amazon Bedrock。
./scripts/upload-to-s3.sh --bucket $S3_BUCKET --source models/final --prefix $S3_PREFIX
./scripts/import-to-bedrock.sh --model-name my-fine-tuned-llama --s3-uri s3://$S3_BUCKET/$S3_PREFIX --role-arn $BEDROCK_ROLE_ARN --wait- 导入脚本将在完成后输出模型 ARN。将
MODEL_ARN设置为此值(格式:arn:aws:bedrock:<REGION>:<ACCOUNT_ID>:imported-model/<MODEL_ID>)。 - 调用 Amazon Bedrock 上的模型
./scripts/invoke-model.sh --model-id $MODEL_ARN --prompt "Translate this text to French: What is the capital of France?"- Amazon Bedrock 会自动创建托管推理环境。有关 IAM 角色设置,请参阅 bedrock-import-role.json。
- 在存储桶上启用 S3 版本控制以支持模型修订的回滚。有关 SSE-KMS 加密和存储桶策略加固,请参阅配套仓库中的 安全脚本。
第 6 步:清理
为避免持续产生费用,请删除本教程中创建的资源:
aws ec2 terminate-instances --instance-ids $INSTANCE_ID
aws s3 rm s3://$S3_BUCKET/$S3_PREFIX/ --recursive
aws bedrock delete-imported-model --model-identifier $MODEL_ARN结论
在本文中,您学习了如何使用 Oumi 在 EC2 上微调 Llama-3.2-1B-Instruct 基础模型,并使用 Amazon Bedrock 自定义模型导入将其部署。这种方法使您能够完全控制使用自己的数据进行微调,同时利用 Amazon Bedrock 的托管推理。
配套的 sample-oumi-fine-tuning-bedrock-cmi 仓库提供了入门脚本、配置和 IAM 策略。克隆它,替换您的数据集,然后将自定义模型部署到 Amazon Bedrock。
要开始,请探索以下资源,并在 Oumi 和 AWS 上构建您自己的微调到部署管道。祝您构建愉快!
了解更多
致谢
特别感谢 Pronoy Chopra 和 Jon Turdiev 的贡献。
关于作者
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区