



Image by Editor (click to enlarge)
# 引言
大型语言模型(LLMs)的能力非常广泛。它们可以生成看起来连贯的文本,可以用人类语言回答问题,还可以分析和组织来自其他来源的文本,等等。但是,LLMs是否能够以有意义的方式分析和报告其自身的内部状态——跨其复杂组件和层的激活情况呢?换句话说,LLMs能够内省吗?
本文概述和总结了关于LLM对其自身内部状态进行内省(即内省意识)的新兴研究,并提供了一些额外的见解和最终结论。特别是,我们将概述并反思研究论文《大型语言模型中内省意识的涌现》。
注意:本文使用第一人称代词(我、我的)来指代本帖的作者,而除非另有说明,“作者们”指的是论文的原研究人员(J. Lindsey 等人)。
# 关键概念解释:内省意识
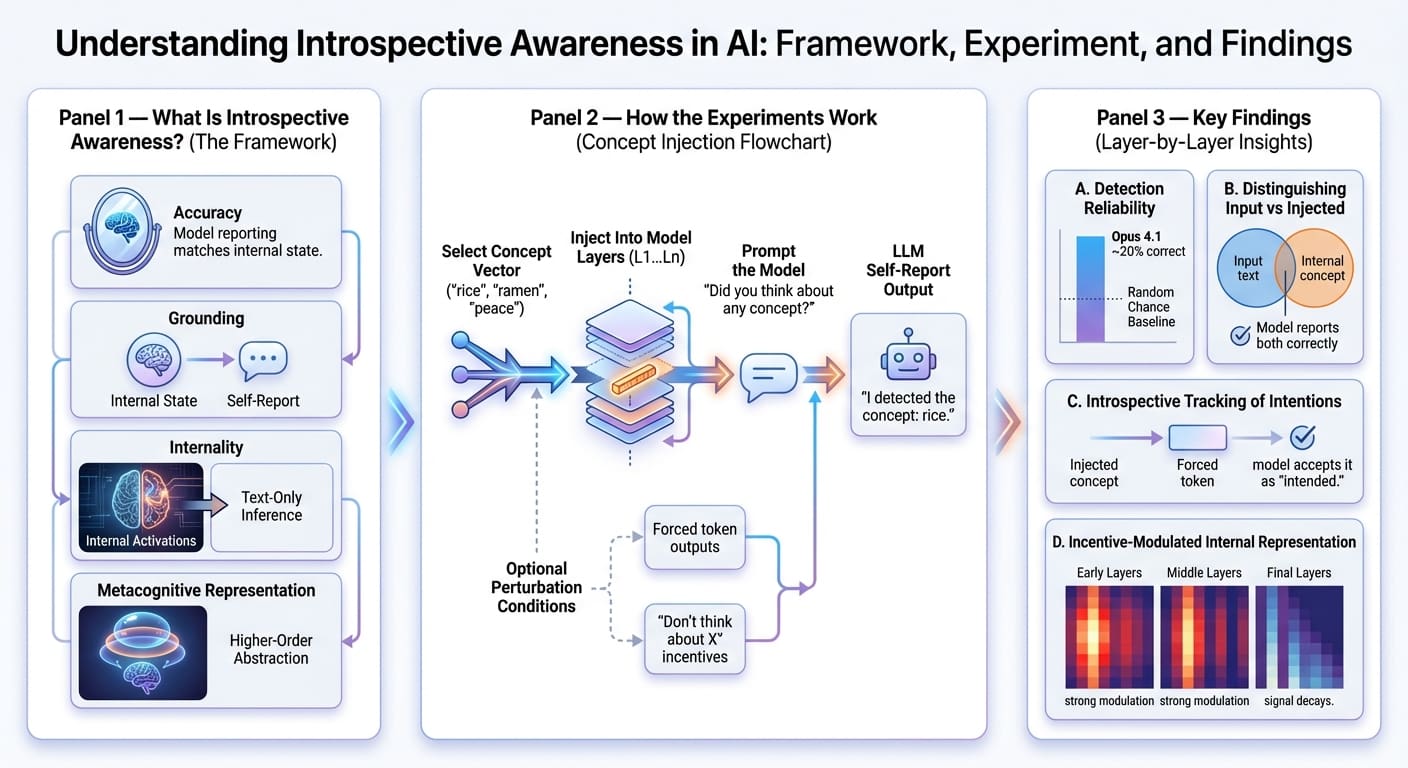
研究的作者们基于四个标准来定义模型内省意识的概念——该概念在其他相关工作中曾以细微不同的解释被定义过。
但首先,了解什么是LLM的自我报告是很有价值的。它可以被理解为模型对自己认为在生成回应时刚刚进行的“内部推理”(或更技术性地说,神经激活)所做的口头描述。正如您可能猜到的那样,这可以被视为模型可解释性的微妙行为体现,在我看来,这足以证明该研究主题的相关性。
现在,让我们来看看定义LLM内省意识的四个标准:
- 准确性 (Accuracy):内省意识要求模型的自我报告应能准确反映其内部状态的激活或操作。
- 基础性 (Grounding):自我报告的描述必须在因果上依赖于内部状态,导致内部状态发生变化时,自我报告相应地发生更新。
- 内部性 (Internality):应使用内部激活来进行自我报告,而不是仅仅从生成的文本中推断出来。
- 元认知表征 (Metacognitive representation):模型应能形成一个更高阶的内部表征,而不仅仅是所达到状态的直接翻译。这是一个特别复杂且难以证明的属性,超出了作者本次研究的范围。
# 研究方法和主要发现
作者们对Claude系列模型的多个版本(例如Opus、Sonnet、Haiku等)进行了一系列实验,旨在探究LLMs是否能够内省。研究方法的一个基石技术是概念注入,用作者自己的话来说,它包括“操纵模型的内部激活情况,并观察这些操纵如何影响其对自身心理状态问题的回应”。
更具体地说,研究人员提取与已知概念(如“米饭”或“拉面”)或抽象名词(如“和平”或“鲜味”)相关的激活向量或概念向量,并将它们注入到模型某一层计算层流出的残差流中,然后再传送到下一层。之后,向模型发送一个提示,要求它自我报告是否注入了某种想法或概念,如果是,具体是哪一个。对考虑的每个模型,该实验在不同的扰动程度、跨整个模型架构的不同层级中重复进行。
主要发现如下:
- 模型偶尔(例如,在Opus 4.1的案例中约20%的时间)会对自己报告“注入的想法”,并正确命名相关的概念,这暗示了在一定程度上对所发生想法的内部识别。
- 模型通常(高于随机几率)能够区分想法和输入,即能够无误地重复文本输入并报告被注入的内部想法。
- 如果模型被人工强制在生成回应的下一个词时输出某个特定词元,并且在“预填充”之前注入了一个匹配的概念向量,那么模型更倾向于接受该输出是其本意。这一发现表明,模型可能能够内省地跟踪其“自己”先前的意图。
- 当模型被要求在生成不相关输出时思考或避免思考某个词时,结果显示它可能能够根据激励来调节其信息内部表征,类似于“(不要)思考想法X,否则你会得到奖励”。然而,这种现象在到达最后一层时倾向于衰减。
# 最终思考与总结
在我看来,这是一个具有极高相关性的研究课题,值得深入研究,原因有很多:首先,也是最明显的,LLM内省可能是更好地理解LLM可解释性的关键,也是理解诸如幻觉、在解决高风险问题时推理不可靠,以及即使在最尖端的模型中也偶尔观察到的其他不透明行为等长期问题的关键。
实验费时费力且设计严谨,结果相当直观,并在模型的中间层发出了内省能力的早期但有意义的暗示,尽管结论的明确程度各不相同。实验仅限于Claude系列模型,当然,我们也很希望看到超越这些模型的架构和模型系列的更多多样性。不过,可以理解存在一些限制,例如对其他模型类型的内部激活的访问受限,或在探测专有系统时遇到的实际限制,更不用说这项研究杰作的作者们隶属于Anthropic了,这当然是情理之中!
Iván Palomares Carrascosa是人工智能、机器学习、深度学习和LLM领域的领导者、作家、演讲者和顾问。他培训和指导他人如何在现实世界中利用人工智能。
评论区