



📢 转载信息
原文链接:https://blogs.nvidia.com/blog/mixture-of-experts-frontier-models/
原文作者:Shruti Koparkar
- 排名前10的最智能的开源模型都采用了专家混合(MoE)架构。
- Kimi K2 Thinking、DeepSeek-R1、Mistral Large 3等模型在NVIDIA GB200 NVL72上的运行速度提升了10倍。
纵观当今几乎任何前沿模型的内部结构,都会发现一种专家混合(MoE)模型架构,它模仿了人脑的效率。
正如人脑会根据任务激活特定区域一样,MoE模型将工作分配给专业的“专家”,对每一个AI Token只激活相关的专家。这带来了更快、更高效的Token生成,而计算量却没有相应增加。
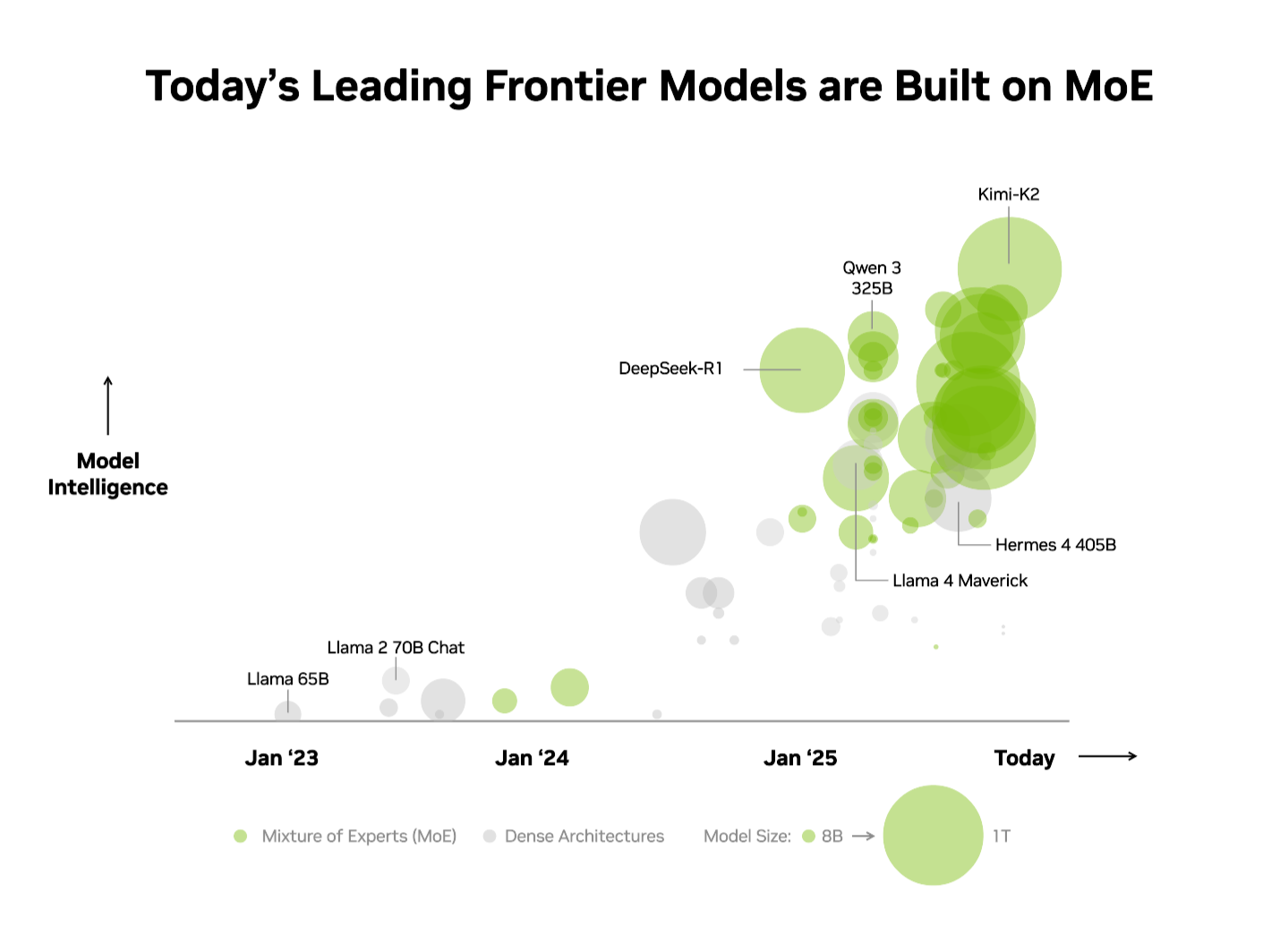
业界已经认识到了这一优势。在独立的Artificial Analysis (AA) 排行榜上,排名前10的最智能的开源模型都采用了MoE架构,其中包括DeepSeek AI的DeepSeek-R1、月之暗面(Moonshot AI)的Kimi K2 Thinking、OpenAI的gpt-oss-120B以及Mistral AI的Mistral Large 3。
然而,在生产环境中扩展MoE模型同时保持高性能是出了名地困难。NVIDIA GB200 NVL72系统的极端协同设计将硬件和软件优化相结合,以实现最大的性能和效率,使得扩展MoE模型变得实用且直接。
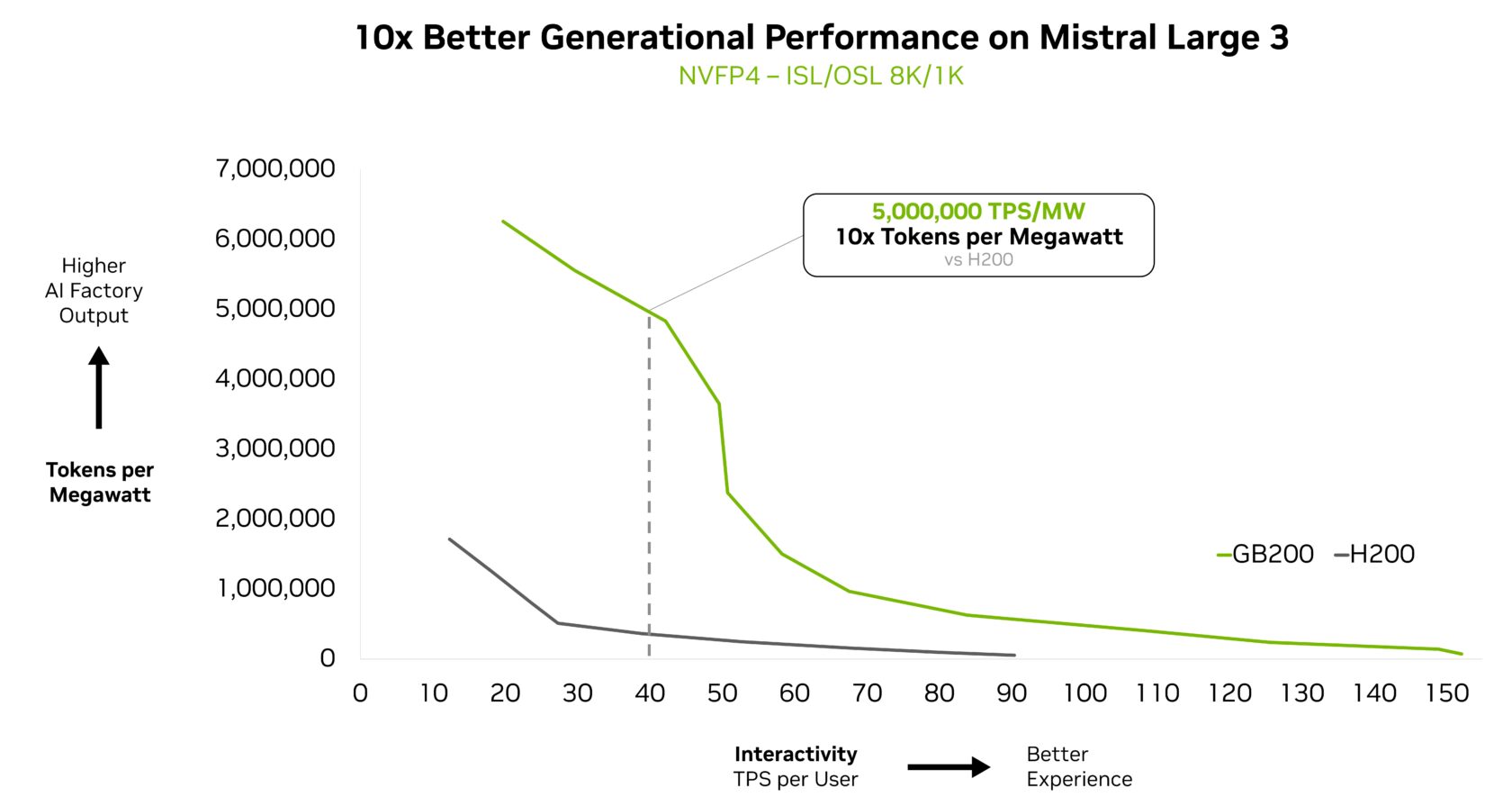
Kimi K2 Thinking MoE模型——在AA排行榜上被评为最智能的开源模型——与NVIDIA HGX H200相比,在NVIDIA GB200 NVL72机架级系统上实现了10倍的性能飞跃。基于DeepSeek-R1和Mistral Large 3 MoE模型所实现的性能突破,这凸显了MoE正成为前沿模型架构的首选——以及为什么NVIDIA的全栈推理平台是释放其全部潜力的关键。
什么是MoE,它为何成为前沿模型的标准?
直到最近,业界构建更智能AI的标准就是简单地构建更大、更“密集”的模型,这些模型使用其所有模型参数(对于当今最强大的模型来说通常是数千亿个)来生成每个Token。虽然功能强大,但这种方法需要巨大的计算能力和能源,使其难以扩展。
就像人脑依靠特定区域来处理不同的认知任务——无论是处理语言、识别物体还是解决数学问题一样,MoE模型由几个专门的“专家”组成。对于任何给定的Token,只有最相关的专家会被一个路由器激活。这种设计意味着,尽管整个模型可能有数千亿个参数,但生成一个Token只涉及使用其中很小一部分——通常只有几百亿。
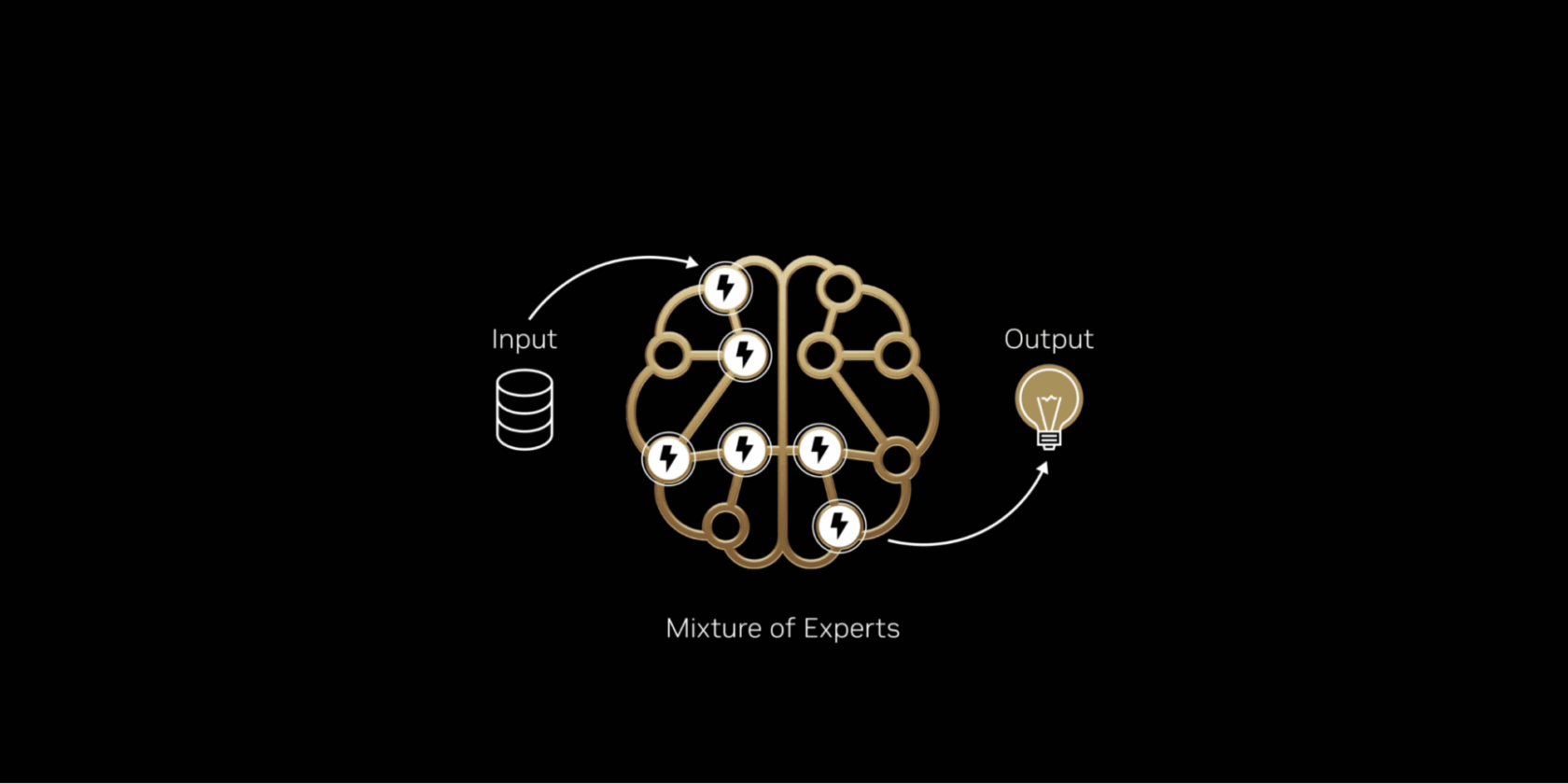
通过有选择地只启用最相关的专家,MoE模型在计算成本不成比例增加的情况下,实现了更高的智能和适应性。这使得它们成为以每美元和每瓦特性能优化的高效AI系统的基础——为每一单位的能源和资本投入产生显著更多的智能。
鉴于这些优势,MoE迅速成为前沿模型的首选架构也就不足为奇了,今年超过60%的开源AI模型发布都采用了它。自2023年初以来,它使得模型智能程度提高了近70倍,不断突破AI能力的极限。
Mistral AI的联合创始人兼首席科学家Guillaume Lample表示:“我们从两年前的Mixtral 8x7B开始,在OSS专家混合架构方面进行的开创性工作,确保了先进的智能对于广泛的应用来说既是可访问的,也是可持续的。”“Mistral Large 3的MoE架构使我们能够在显著降低能源和计算需求的同时,将AI系统的性能扩展到更高的水平并提高效率。”
通过极端协同设计克服MoE扩展瓶颈
前沿MoE模型规模过大且过于复杂,无法在单个GPU上部署。要运行它们,必须将专家分布在多个GPU上,这是一种称为专家并行的技术。即使在NVIDIA H200等强大的平台上,部署MoE模型也存在瓶颈,例如:
- 内存限制:对于每个Token,GPU必须从高带宽内存中动态加载所选专家的参数,这给内存带宽带来频繁的巨大压力。
- 延迟:专家必须执行几乎瞬时的全互联(all-to-all)通信模式,以交换信息并形成最终的完整答案。然而,在H200上,将专家分散到超过八个GPU需要它们通过高延迟的扩展出(scale-out)网络进行通信,这限制了专家并行的优势。
解决方案:极端协同设计。
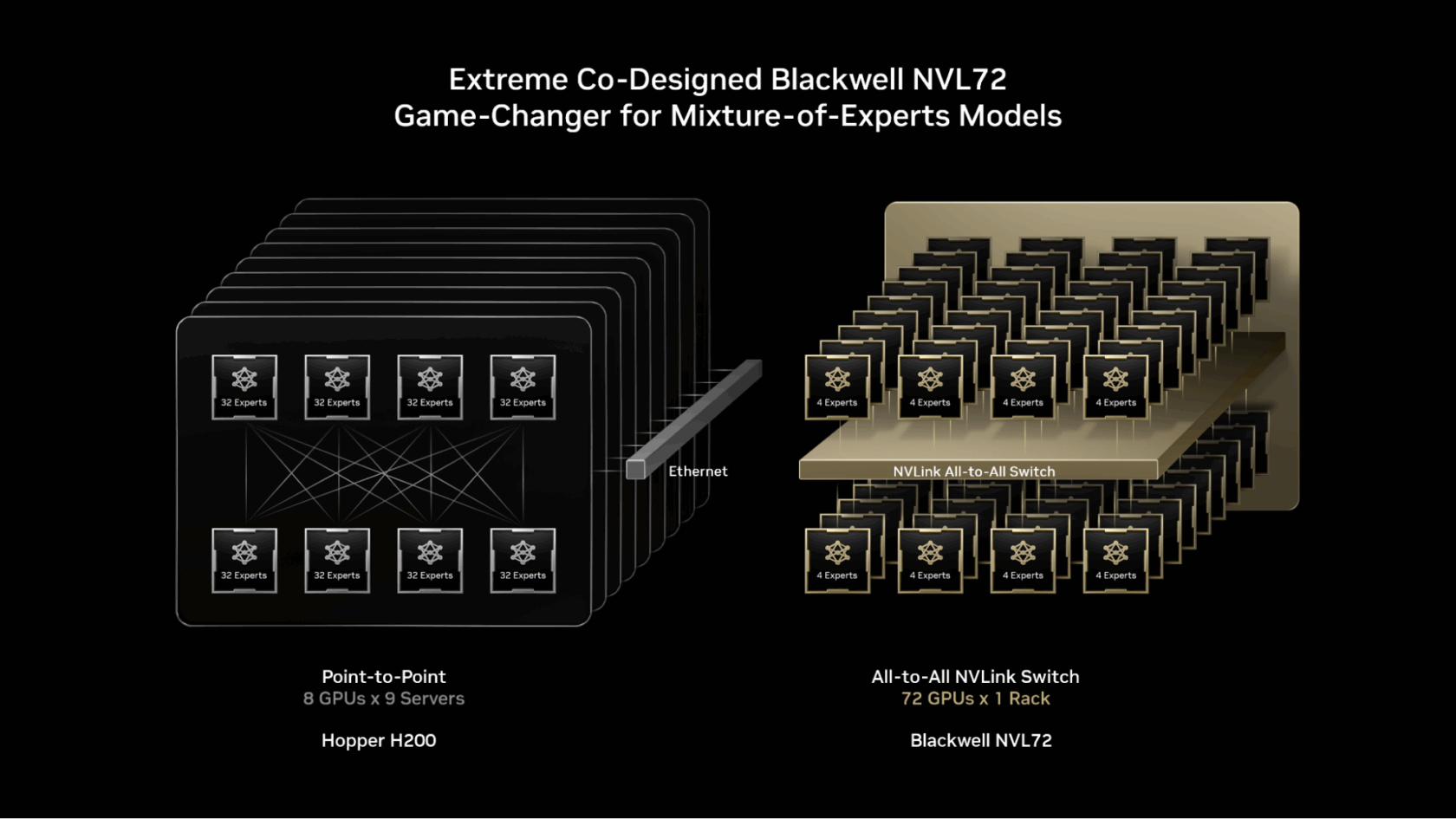
NVIDIA GB200 NVL72是一个机架级系统,拥有72个NVIDIA Blackwell GPU协同工作,如同一个整体,提供1.4艾牛(exaflops)的AI性能和30TB的快速共享内存。这72个GPU使用NVLink Switch连接成一个单一的、巨大的NVLink互连结构,允许每个GPU以130 TB/s的NVLink连接相互通信。
MoE模型可以利用这种设计,将专家并行扩展到远超以往的限制——将专家分布在多达72个GPU的更大集合上。
这种架构方法通过以下方式直接解决了MoE扩展瓶颈:
- 减少每个GPU上的专家数量:将专家分布在多达72个GPU上,减少了每个GPU上的专家数量,从而最大限度地减少了对每个GPU高带宽内存的参数加载压力。每个GPU上的专家更少,也释放了内存空间,使每个GPU能够为更多并发用户提供服务并支持更长的输入长度。
- 加速专家通信:分布在不同GPU上的专家可以使用NVLink即时相互通信。NVLink Switch还拥有执行某些计算所需的处理能力,以合并来自各种专家的信息,从而加快最终答案的交付。
其他全栈优化也在解锁MoE模型的高推理性能方面发挥着关键作用。NVIDIA Dynamo框架通过将预填充(prefill)和解码(decode)任务分配给不同的GPU来编排分离式服务(disaggregated serving),允许解码以大的专家并行运行,而预填充则使用更适合其工作负载的并行技术。NVFP4格式有助于在进一步提高性能和效率的同时保持准确性。
NVIDIA TensorRT-LLM、SGLang和vLLM等开源推理框架都支持这些针对MoE模型的优化。特别是SGLang在在GB200 NVL72上推进大规模MoE方面发挥了重要作用,帮助验证和成熟了当今使用的许多技术。
为了将这种性能带给全球企业,主要的云服务提供商和NVIDIA云合作伙伴(包括Amazon Web Services、Core42、CoreWeave、Crusoe、Google Cloud、Lambda、Microsoft Azure、Nebius、Nscale、Oracle Cloud Infrastructure、Together AI等)正在部署GB200 NVL72。
CoreWeave的联合创始人兼首席技术官Peter Salanki表示:“在CoreWeave,我们的客户正在利用我们的平台将专家混合模型投入生产,以构建代理式工作流。”“通过与NVIDIA的紧密合作,我们能够提供一个紧密集成的平台,将MoE的性能、可扩展性和可靠性汇集一处。你只能在一个专为AI设计的云上做到这一点。”
DeepL等客户正在使用Blackwell NVL72机架级设计来构建和部署其下一代AI模型。
DeepL的研究团队负责人Paul Busch表示:“DeepL正在利用NVIDIA GB200硬件来训练专家混合模型,推进其模型架构,以提高训练和推理期间的效率,并在AI性能方面树立了新标杆。”
证据在于每瓦特的性能
NVIDIA GB200 NVL72能够高效扩展复杂的MoE模型,并实现每瓦性能提升10倍。这种性能飞跃不仅仅是一个基准测试;它使得Token收入增加10倍,改变了在电力和成本受限的数据中心中大规模AI的经济效益。
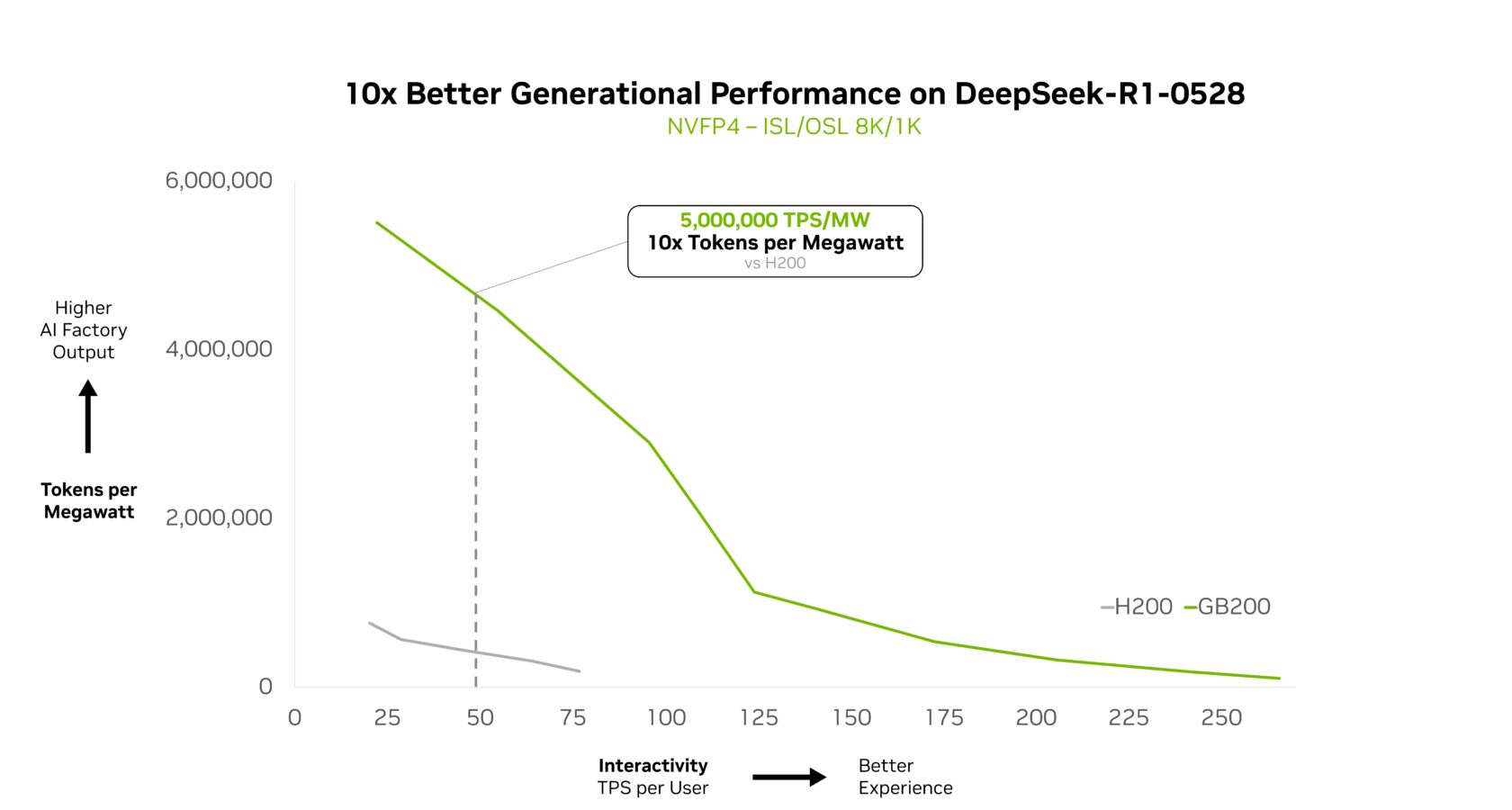
在NVIDIA GTC华盛顿特区会议上,NVIDIA创始人兼首席执行官黄仁勋强调了GB200 NVL72如何为DeepSeek-R1提供比NVIDIA Hopper高出10倍的性能,并且这种性能也延伸到了DeepSeek的其他变体。
Together AI的联合创始人兼首席执行官Vipul Ved Prakash表示:“借助GB200 NVL72以及Together AI的定制优化,我们正在超越客户对DeepSeek-V3等MoE模型大规模推理工作负载的期望。”“性能提升来自于NVIDIA的全栈优化,以及Together AI在内核、运行时引擎和推测性解码方面的推理突破。”
这种性能优势在其他前沿模型中也很明显。
最智能的开源模型Kimi K2 Thinking是另一个佐证,在GB200 NVL72上部署时实现了10倍更好的生成性能。
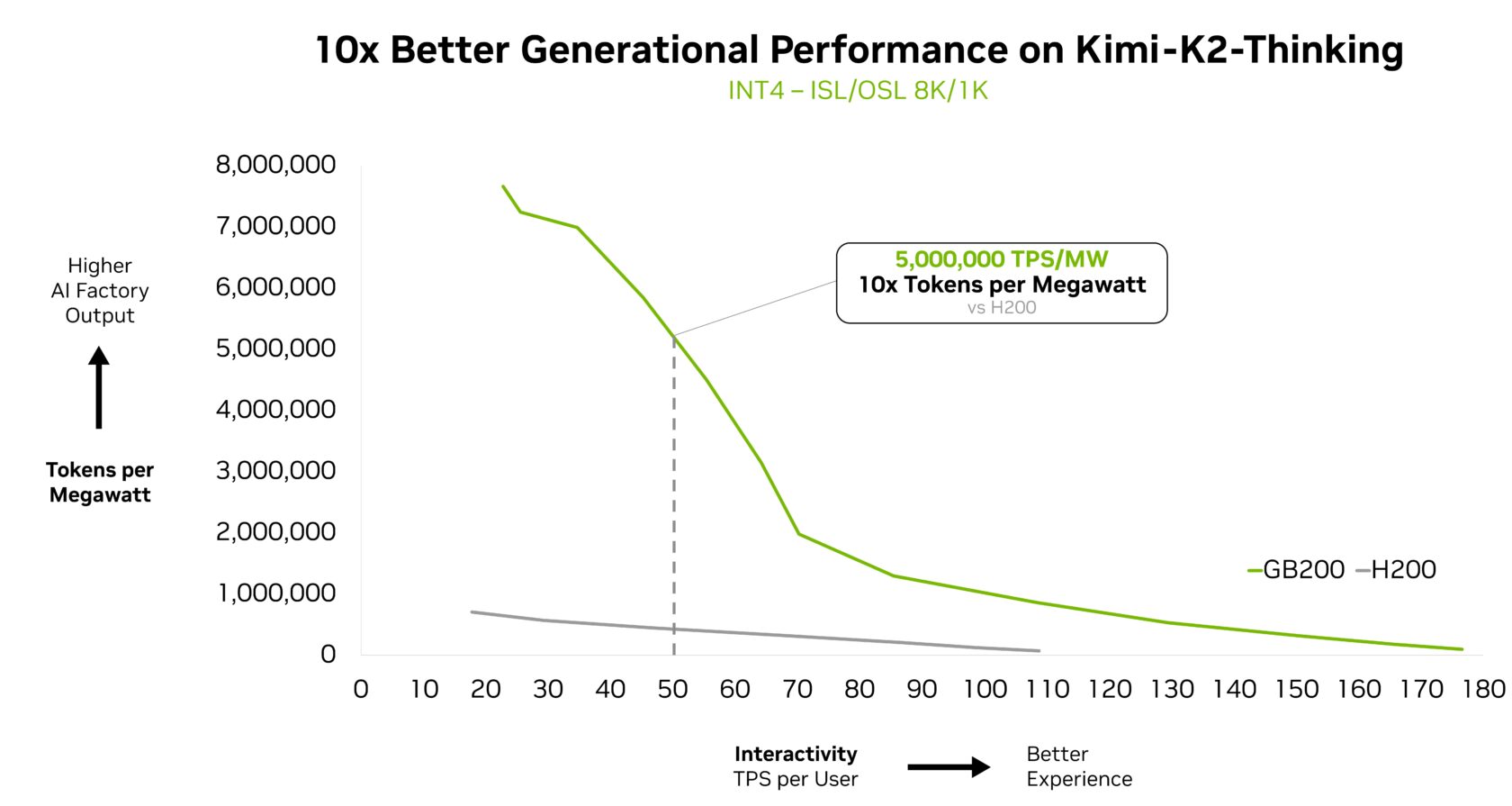
Fireworks AI目前已在NVIDIA B200平台上部署了Kimi K2,在Artificial Analysis排行榜上实现了最高的性能。
Fireworks AI的联合创始人兼首席执行官Lin Qiao表示:“NVIDIA GB200 NVL72机架级设计使MoE模型服务的效率大大提高。”“展望未来,NVL72有潜力改变我们服务大规模MoE模型的方式,与Hopper平台相比带来显著的性能提升,并为前沿模型的速度和效率设定新的标准。”
新的Kinnie模型在与上一代H200相比时,在GB200 NVL72上也实现了10倍的性能提升。这种代际提升为这款新的MoE模型带来了更好的用户体验、更低的每Token成本和更高的能源效率。
为大规模智能提供动力
NVIDIA GB200 NVL72机架级系统不仅专为MoE模型设计,还能提供强大的性能。
原因在于AI的发展方向:最新一代的多模态AI模型拥有针对语言、视觉、音频和其他模态的专业组件,只激活与当前任务相关的组件。
在代理式系统中,不同的“代理”专门负责规划、感知、推理、工具使用或搜索,一个编排器协调它们以交付单一结果。在这两种情况下,核心模式都与MoE相似:将问题中相关部分路由到最相关的专家,然后协调它们的输出以产生最终结果。
将这一原则扩展到为多个用户服务多个应用程序和代理的生产环境,可以解锁新的效率水平。与其为每个代理或应用程序复制庞大的AI模型,这种方法可以启用一个可供所有人访问的专家共享池,将每个请求路由到正确的专家。
专家混合模型是一种强大的架构,正推动行业迈向一个大规模能力、效率和规模共存的未来。GB200 NVL72在今天释放了这一潜力,而NVIDIA Vera Rubin架构的路线图将继续扩展前沿模型的视野。
通过这篇技术深入解析,了解更多关于GB200 NVL72如何扩展复杂MoE模型的信息。
本文属于Think SMART系列,重点关注领先的AI服务提供商、开发人员和企业如何利用NVIDIA全栈推理平台的最新进展来提高其推理性能和投资回报率。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区