




📢 转载信息
原文链接:http://bair.berkeley.edu/blog/2025/04/08/plaid/
原文作者:BAIR

PLAID 是一种多模态生成模型,通过学习蛋白质折叠模型的潜在空间,同时生成蛋白质的一维序列和三维结构。
2024年诺贝尔化学奖授予AlphaFold2,标志着人工智能在生物学领域的重要里程碑。那么,在蛋白质折叠之后,下一步会是什么?
在PLAID中,我们开发了一种方法,可以学习从蛋白质折叠模型的潜在空间中采样,以生成新的蛋白质。它可以接受组成性功能和生物体提示,并且可以在仅包含序列的数据库上进行训练,这些数据库的规模比结构数据库大2到4个数量级。与许多早期的蛋白质结构生成模型不同,PLAID解决了多模态联合生成的问题:同时生成离散的序列和连续的全原子结构坐标。
从结构预测到现实世界的药物设计
尽管最近的研究表明扩散模型在生成蛋白质方面具有潜力,但现有模型仍然存在一些局限性,使其在现实世界中的应用并不实用,例如:
- 全原子生成:许多现有的生成模型只生成骨架原子。要生成全原子结构并放置侧链原子,我们需要知道序列。这造成了一个需要同时生成离散和连续模态的多模态生成问题。
- 生物体特异性:用于人体使用的生物制剂需要被“人类化”,以避免被人体免疫系统破坏。
- 控制规范:药物发现并将其交付给患者是一个复杂的过程。我们如何指定这些复杂的约束?例如,即使解决了生物学问题,你也可能决定片剂比小瓶更容易运输,这为溶解性增加了一个新的约束。
生成“有用”的蛋白质
简单地生成蛋白质不如控制生成以获得有用的蛋白质那么重要。这种接口可能是什么样子的?

为了获得灵感,让我们考虑如何通过组成性文本提示控制图像生成(示例来自Liu et al., 2022)。
在PLAID中,我们为控制规范镜像了这种接口。最终目标是通过文本界面完全控制生成,但在这里,我们首先考虑两个轴的组成性约束作为概念验证:功能和生物体:
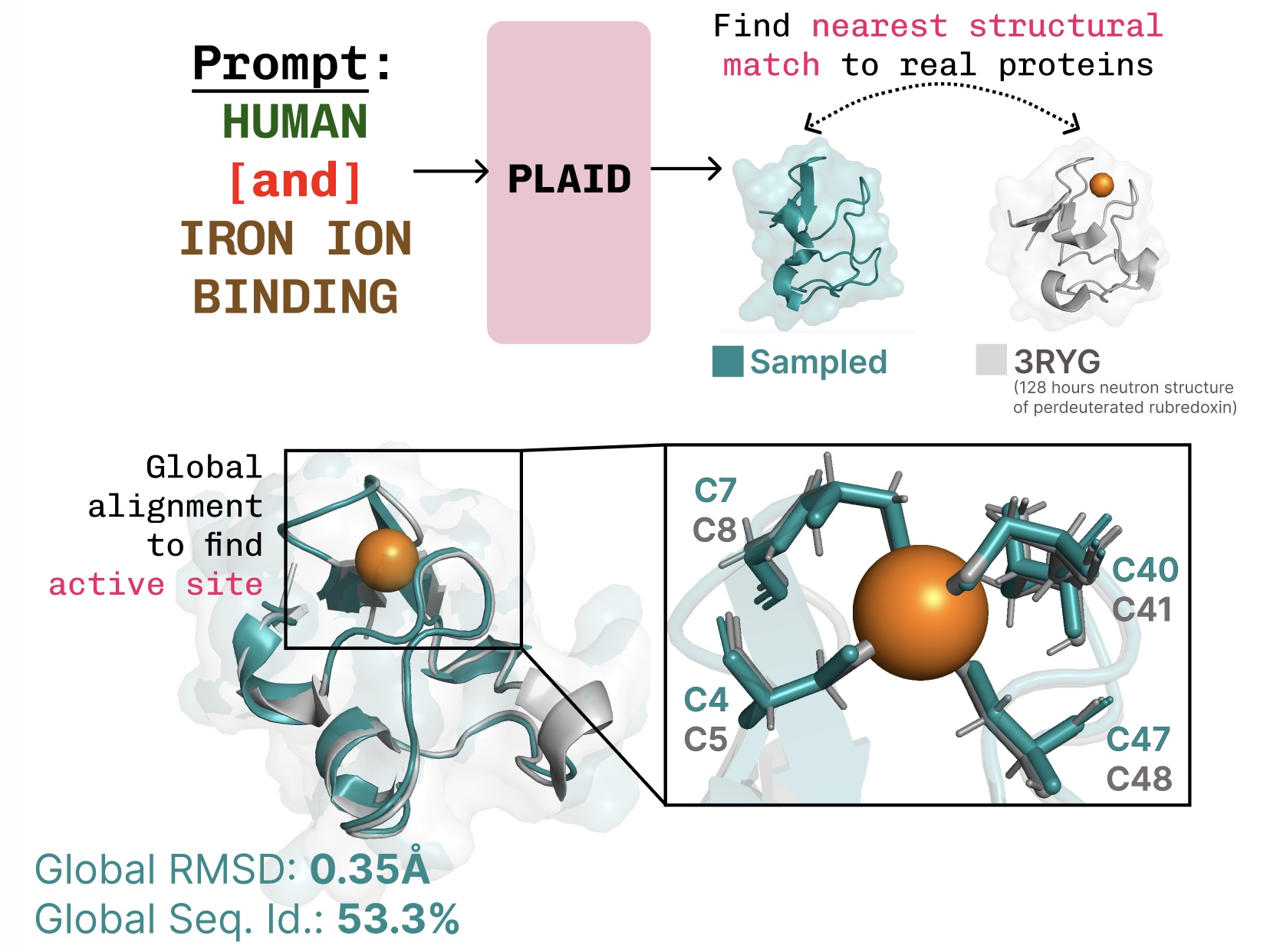
学习功能-结构-序列连接。 PLAID学习了金属蛋白中常见的四面体半胱氨酸-Fe2+/Fe3+配位模式,同时保持高水平的序列多样性。
使用仅序列的训练数据进行训练
PLAID模型的另一个重要方面是,我们仅需要序列来训练生成模型!生成模型学习由其训练数据定义的概率分布,而序列数据库比结构数据库大得多,因为与实验结构相比,序列更容易获得。
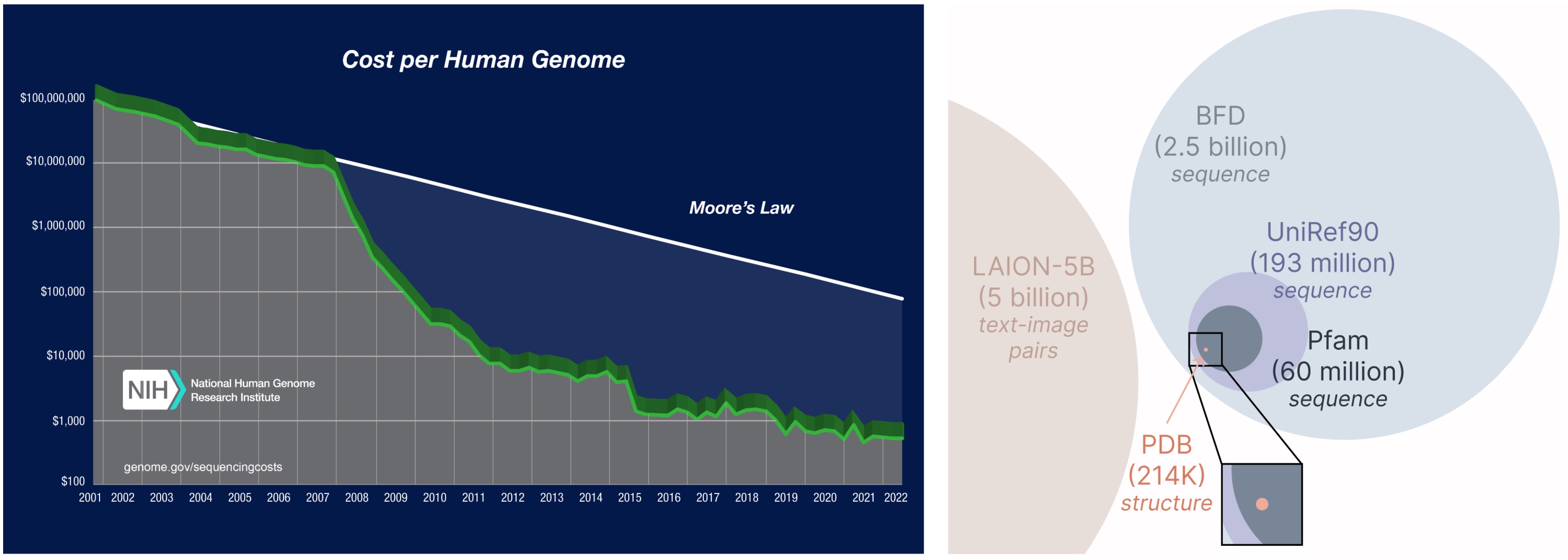
从更大、更广泛的数据库中学习。 获取蛋白质序列的成本远低于实验表征结构,并且序列数据库比结构数据库大2到4个数量级。
它是如何工作的?
我们能够仅使用序列数据训练生成模型来生成结构的原因是学习蛋白质折叠模型的潜在空间上的扩散模型。然后在推理过程中,在从有效蛋白质的潜在空间采样后,我们可以使用蛋白质折叠模型的冻结权重来解码结构。在这里,我们使用ESMFold,它是AlphaFold2模型的继承者,它用蛋白质语言模型替换了检索步骤。
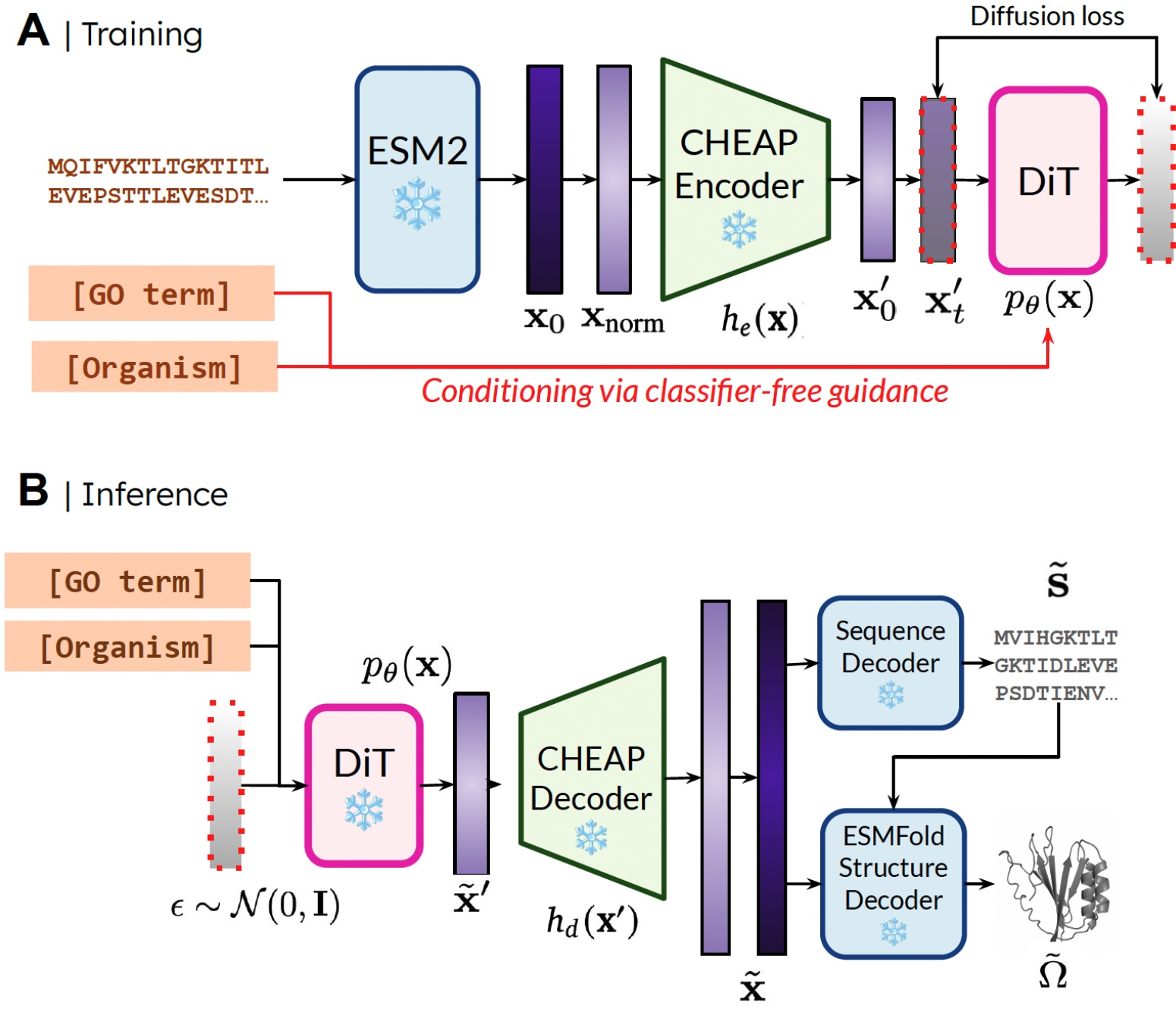
我们的方法。 训练期间,只需序列即可获得嵌入;推理期间,我们可以从采样的嵌入中解码序列和结构。❄️ 表示冻结权重。
通过这种方式,我们可以利用预训练蛋白质折叠模型中包含的结构理解信息来进行蛋白质设计任务。这类似于机器人中的视觉-语言-动作(VLA)模型如何利用在互联网规模数据上训练的视觉-语言模型(VLM)中的先验知识来提供感知、推理和理解信息。
压缩蛋白质折叠模型的潜在空间
直接应用此方法的一个小难题是ESMFold的潜在空间——实际上是许多基于Transformer的模型的潜在空间——需要大量的正则化。这个空间也非常大,因此学习这个嵌入最终会映射到高分辨率图像合成。
为了解决这个问题,我们还提出了CHEAP(蛋白质的压缩沙漏嵌入适应),我们学习一个压缩模型来处理蛋白质序列和结构的联合嵌入。
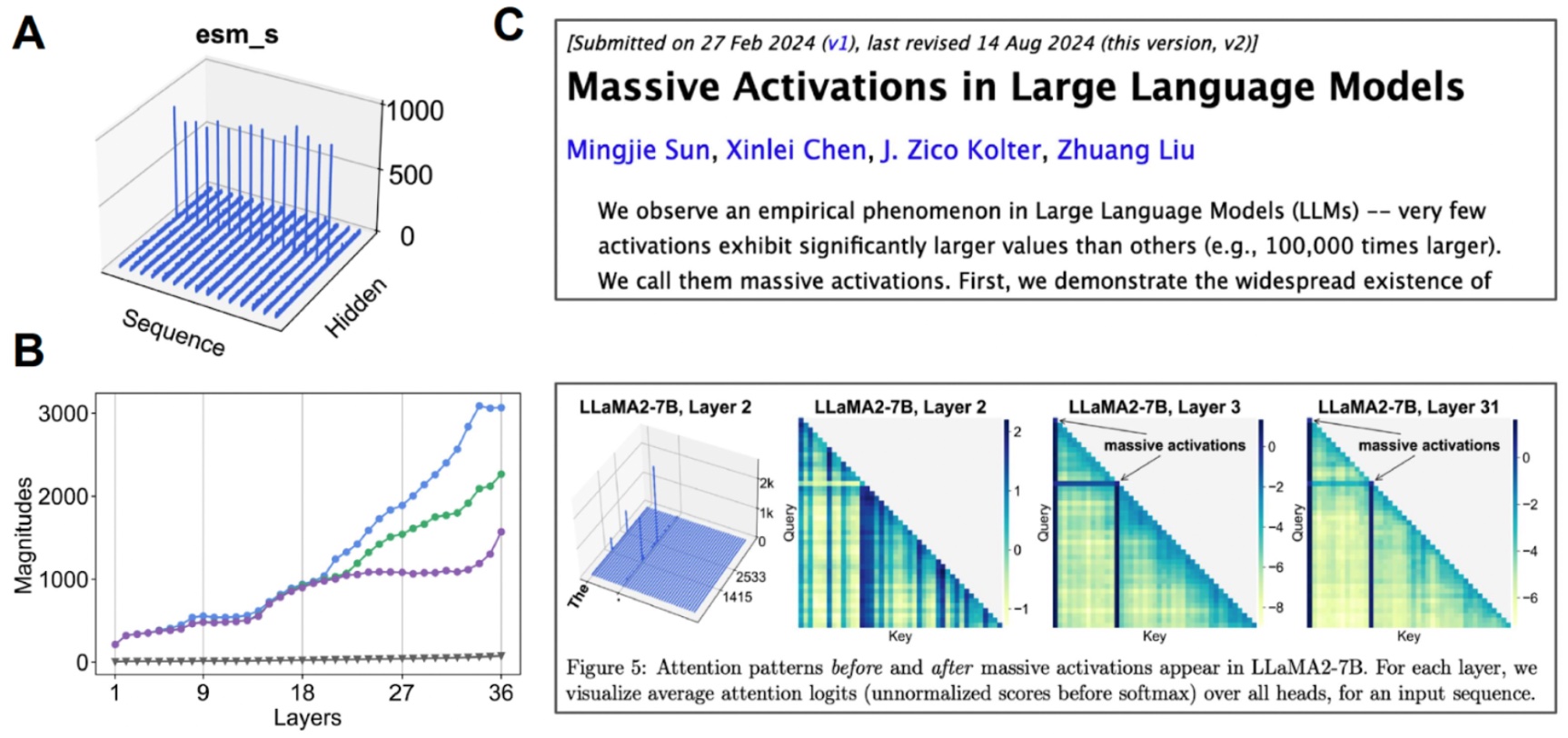
探索潜在空间。 (A) 当我们可视化每个通道的平均值时,一些通道会显示出“巨大激活”。(B) 如果我们开始检查与中值(灰色)相比的前3个激活值,我们会发现这发生在许多层中。(C) 其他基于Transformer的模型也观察到了巨大激活。
我们发现这个潜在空间实际上是高度可压缩的。通过对我们正在使用的基础模型进行一些机制可解释性研究,我们能够创建一个全原子的蛋白质生成模型。
接下来是什么?
尽管在这项工作中我们研究了蛋白质序列和结构生成的案例,但我们可以将此方法应用于任何存在从更丰富模态到更稀疏模态的预测器的多模态生成。随着蛋白质的序列到结构预测器开始处理越来越复杂的系统(例如,AlphaFold3也能够预测与核酸和分子配体复合物中的蛋白质),可以很容易地想象使用相同的方法对更复杂的系统进行多模态生成。如果您有兴趣合作扩展我们的方法,或在湿实验室中测试我们的方法,请联系我们!
更多链接
如果您在研究中发现我们的论文有帮助,请考虑使用PLAID和CHEAP的以下BibTeX:
@article{lu2024generating, title={Generating All-Atom Protein Structure from Sequence-Only Training Data}, author={Lu, Amy X and Yan, Wilson and Robinson, Sarah A and Yang, Kevin K and Gligorijevic, Vladimir and Cho, Kyunghyun and Bonneau, Richard and Abbeel, Pieter and Frey, Nathan}, journal={bioRxiv}, pages={2024--12}, year={2024}, publisher={Cold Spring Harbor Laboratory}
}
@article{lu2024tokenized, title={Tokenized and Continuous Embedding Compressions of Protein Sequence and Structure}, author={Lu, Amy X and Yan, Wilson and Yang, Kevin K and Gligorijevic, Vladimir and Cho, Kyunghyun and Abbeel, Pieter and Bonneau, Richard and Frey, Nathan}, journal={bioRxiv}, pages={2024--08}, year={2024}, publisher={Cold Spring Harbor Laboratory}
}
您还可以查看我们的预印本(PLAID, CHEAP)和代码库(PLAID, CHEAP)。
一些额外的蛋白质生成乐趣!
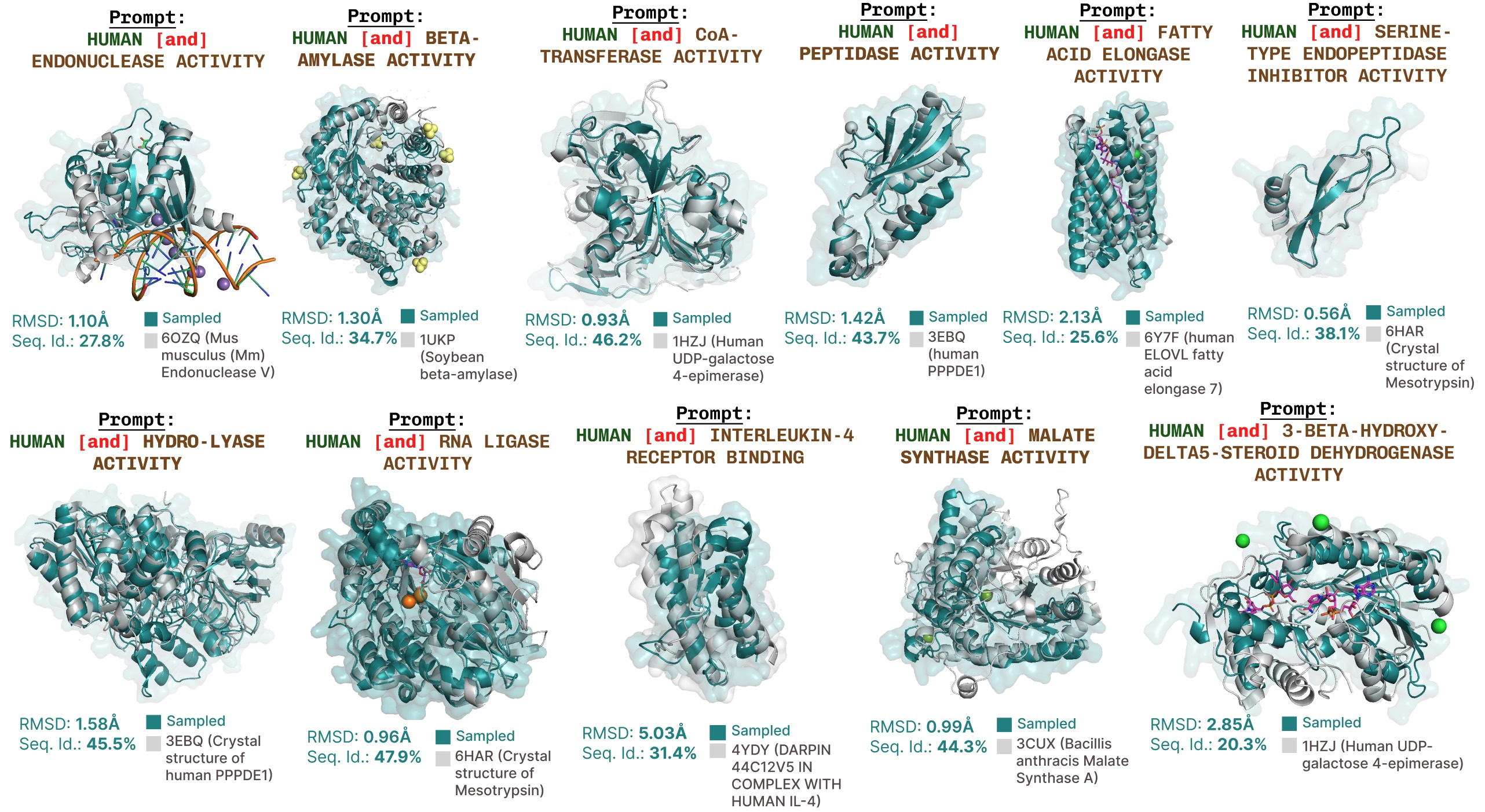
使用PLAID进行额外的功能提示生成。
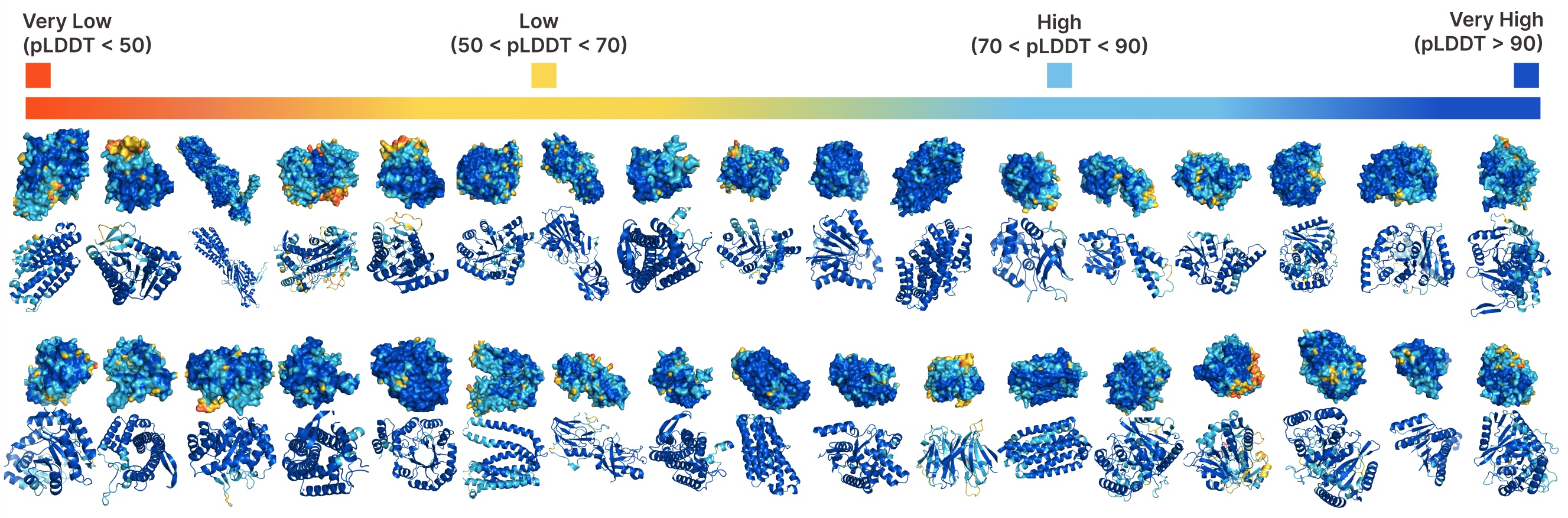
使用PLAID进行无条件生成。
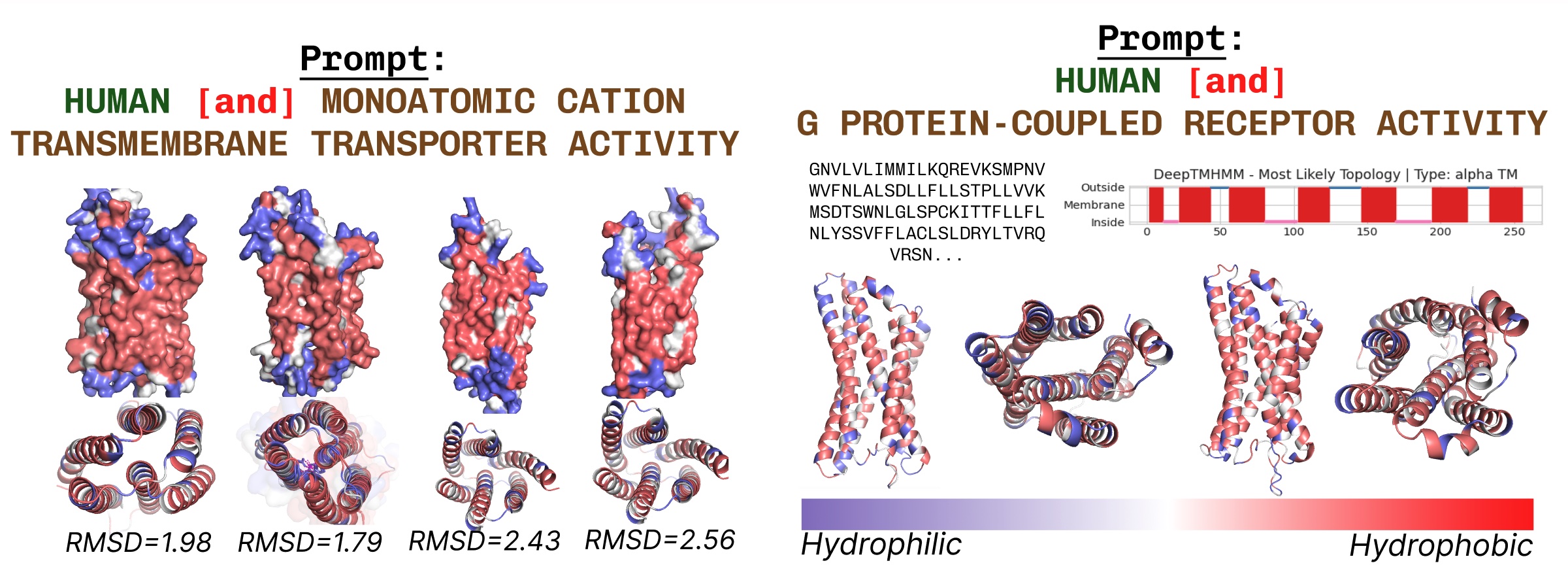
跨膜蛋白在脂肪酸层中嵌入的核心部分具有疏水残基。当使用跨膜蛋白关键词提示PLAID时,这些特征是一致观察到的。
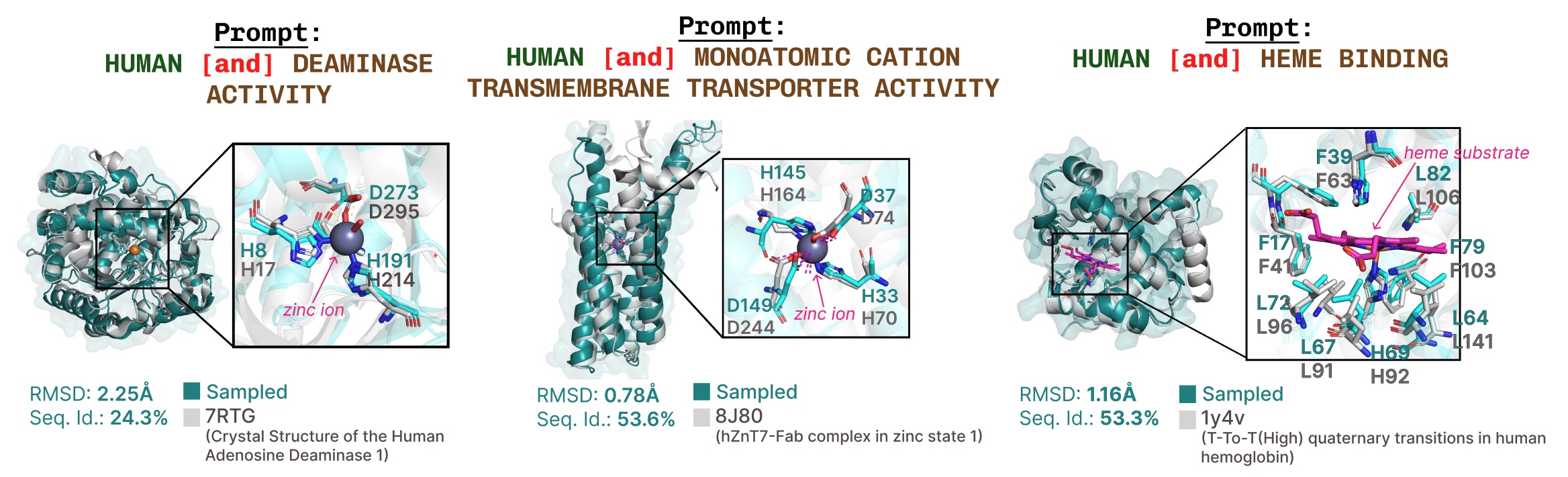
基于功能关键词提示的主动位点再现的更多示例。
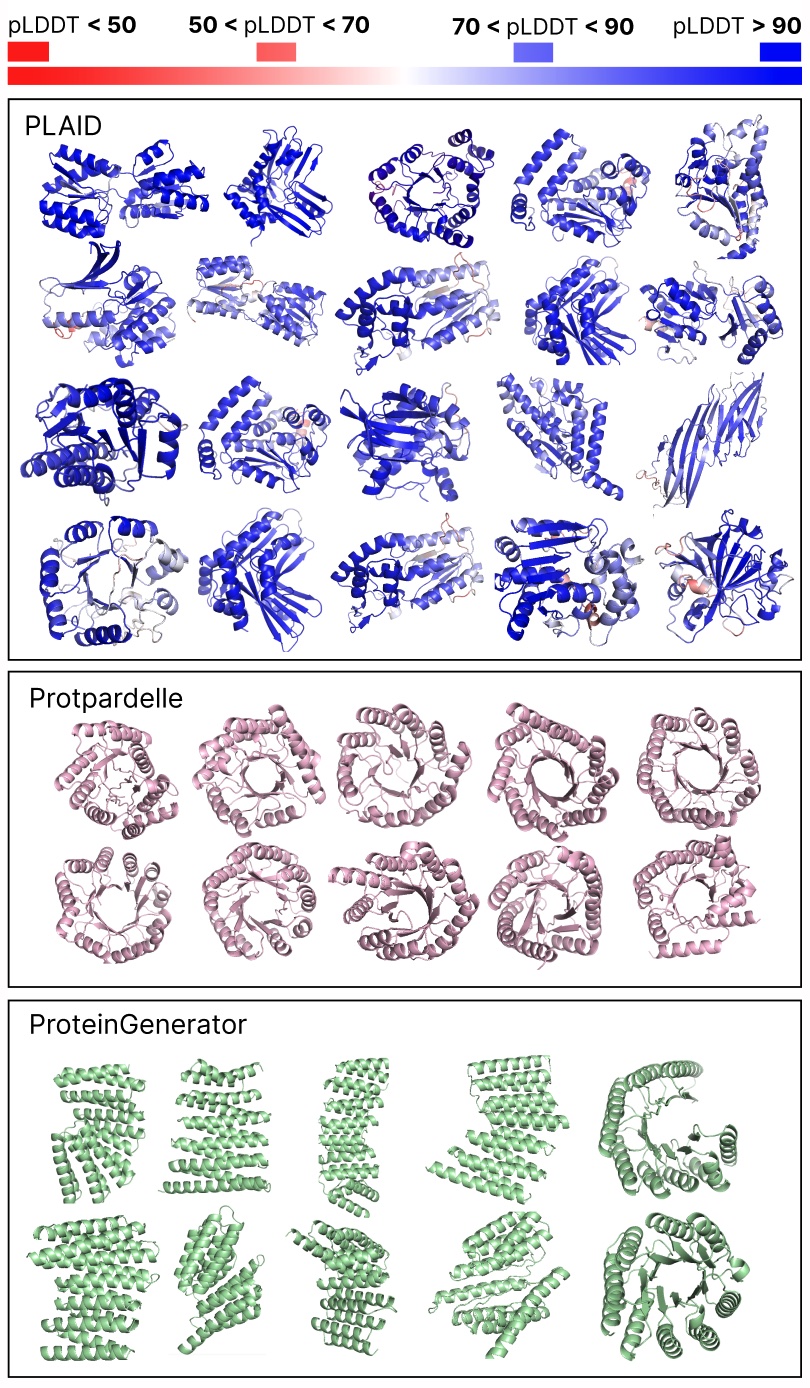
比较PLAID与全原子基线之间的样本。PLAID样本具有更好的多样性,并捕捉了对蛋白质生成模型来说更难学习的β折叠模式。
致谢
感谢Nathan Frey对本文的详细反馈,以及BAIR、基因泰克、微软研究院和纽约大学的合作作者:Wilson Yan, Sarah A. Robinson, Simon Kelow, Kevin K. Yang, Vladimir Gligorijevic, Kyunghyun Cho, Richard Bonneau, Pieter Abbeel, 和 Nathan C. Frey。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,小白也可以简单操作。
青云聚合API官网https://api.qingyuntop.top
支持全球最新300+模型:https://api.qingyuntop.top/pricing
详细的调用教程及文档:https://api.qingyuntop.top/about
评论区