



📢 转载信息
原文链接:https://www.ithome.com/0/889/339.htm
原文作者:远洋
腾讯优图实验室今日正式开源了面向企业级应用的通用文本表示模型 Youtu-Embedding。
这款模型具有广泛的应用前景,可深度应用于企业客服、智能问答、内容推荐、知识管理等关键场景,尤其在构建先进的 RAG(检索增强生成)系统方面,表现尤为突出。
高质量嵌入的重要性:为什么传统搜索不再足够?
高质量的文本嵌入(Embedding)是驱动智能搜索、检索增强生成(RAG)以及推荐系统等应用的核心技术。
在传统的信息检索系统中,搜索主要依赖倒排索引(Inverted Index)与关键词匹配。系统通过将文本分解为词项,统计共现频率或关键词相似度来检索文档。这种方法虽然高效,但存在明显局限:它只依赖字面匹配,无法真正理解语义关系。
例如,当用户搜索“汽车保险”时,传统系统可能无法匹配到包含“车辆保障”的文档,即使两者在语义上是等价的。
Youtu-Embedding 的核心技术优势
文本嵌入(Embedding)技术通过深度神经网络将文本映射到高维向量空间,其核心目标是让语义相似的句子在该空间中距离更近。这一机制使得模型能够基于语义层面的关联而非字面重合来完成检索,从而显著提升搜索和问答系统的“理解力”。
在 RAG 场景中,高质量的文本嵌入模型能够为大语言模型(LLM)提供更准确、更上下文相关的外部知识,确保生成的答案更加精确、可控与可解释。
腾讯优图实验室开源的 Youtu-Embedding,正是为破解这一语义理解难题而生。它是一款面向企业级应用的通用文本表示模型,能够同时胜任以下六大主流任务:
- 文本检索 (IR)
- 意图理解
- 相似度判断 (STS)
- 分类聚类
- 重排序
- 通用语义表示
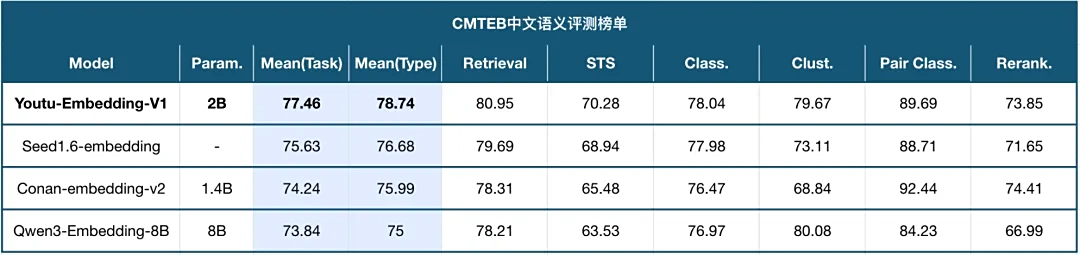
🥇 性能卓越:权威榜单名列前茅
Youtu-Embedding 在信息检索(IR)、语义相似度(STS)、聚类、重排序和分类等一系列广泛的自然语言处理任务上,均展现出卓越的性能。
🏆 顶尖性能:在权威的中文文本嵌入评测基准 CMTEB 上,以 77.46 的高分荣登榜首(截至 2025 年 09 月),证明了其强大的表征能力。
🛠️ 独家秘籍:精密的三阶段训练
Youtu-Embedding 采用精密的三阶段训练流程,系统性地将大模型的广博知识转化为专用于嵌入任务的判别能力:
- LLM 基础预训练
- 弱监督对齐
- 协同-判别式微调
✨ 创新与工程保障
⭐ 创新的微调框架:设计了统一数据格式、任务差异化损失函数和动态单任务采样机制,成功解决了多任务学习中的“负迁移”难题,实现了多任务的稳定协同训练。(该框架在多种基础编码器上进行了验证,保障其通用性和有效性)
🛠️ 精细化的数据工程:结合了基于 LLM 的高质量数据合成技术与高效的难负例挖掘策略,为模型训练提供了最坚实的数据基础。
🔥 开源详情
腾讯优图实验室此次开源了模型权重、推理代码及完整的训练框架。
首个模型版本已在 HuggingFace 上发布,这是一个拥有 20 亿(2B)参数的通用语义表示模型。源代码已在 GitHub 上开源。

Hugging Face 链接:https://huggingface.co/tencent/Youtu-Embedding
GitHub 链接:https://github.com/TencentCloudADP/youtu-embedding
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,小白也可以简单操作。
青云聚合API官网https://api.qingyuntop.top
支持全球最新300+模型:https://api.qingyuntop.top/pricing
详细的调用教程及文档:https://api.qingyuntop.top/about
评论区