



📢 转载信息
原文链接:https://martinfowler.com/articles/exploring-gen-ai/sdd-3-tools.html
原文作者:Birgitta Böckeler

本文是“探索生成式AI(Exploring Gen AI)”系列的一部分,该系列记录了Thoughtworks技术专家使用生成式AI技术进行软件开发的探索心得。
2025年10月15日
我一直在努力理解最新的AI编码热门词汇之一:“规格驱动开发”(Spec-Driven Development, SDD)。我研究了三个自称为SDD的工具,并试图梳理出当前它究竟意味着什么。
定义:规格驱动开发的内涵
与这个快速发展的领域中许多新兴术语一样,“规格驱动开发”(SDD)的定义仍在变化中。根据我目前观察到的用法,可以归纳如下:规格驱动开发是指在编写代码(与AI协作)之前先编写一个“规格”(即“文档先行”)。该规格成为人类和AI的真值来源。
GitHub的观点:“在这个新世界中,维护软件意味着演进规格。[...] 开发的通用语言提升到了更高的层面,代码只是最后的实现步骤。”
Tessl的观点:“一种开发方法,其中规格(而非代码)是主要的产物。规格使用结构化、可测试的语言描述意图,智能体(Agent)生成代码以匹配这些规格。”
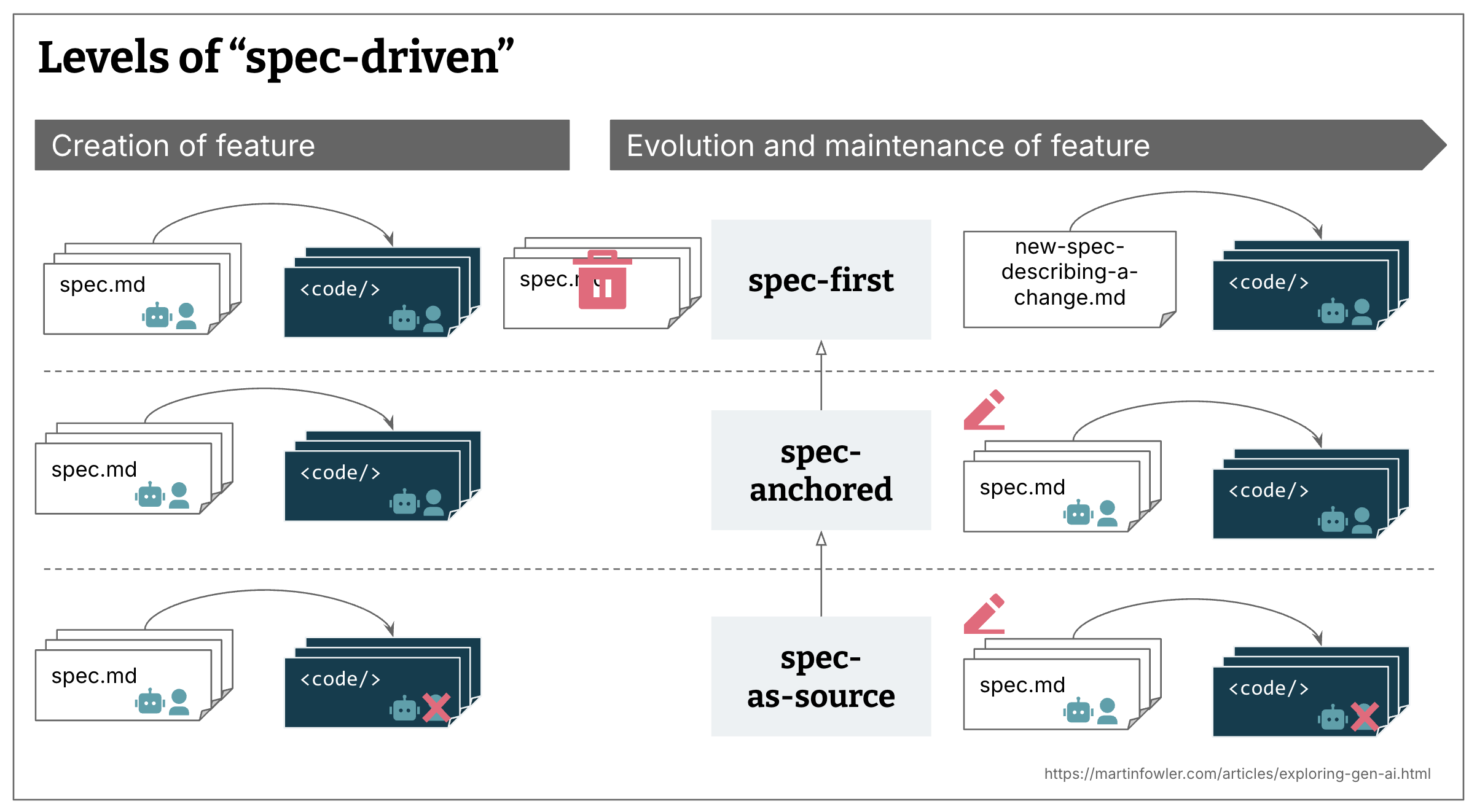
在考察了该术语的用法以及声称实现SDD的工具后,我认为实际上存在多个实施层面:
- 规格先行(Spec-first):首先编写一个经过深思熟虑的规格,然后在手头的任务中用于AI辅助的开发工作流程。
- 规格锚定(Spec-anchored):任务完成后,规格仍被保留,以便在后续的演进和维护中使用。
- 规格即源(Spec-as-source):规格是随时间推移的主要源文件,人类只编辑规格,从不直接触碰代码。
我找到的所有SDD方法和定义都是“规格先行”的,但并非都致力于成为“规格锚定”或“规格即源”。而且,关于规格随时间推移的维护策略,往往说得模糊不清或完全没有提及。
什么是规格(Spec)?
定义中的关键问题是:规格到底是什么?目前似乎没有一个通用的定义,我见过的最接近一致的定义是将其比作“产品需求文档”(Product Requirements Document)。
这个术语目前被过度使用,以下是我试图定义规格的尝试:
规格是一个结构化的、面向行为的产物——或一组相关的产物——用自然语言书写,表达软件功能,并作为AI编码智能体的指导。每种规格驱动开发变体都定义了其对规格结构、细节级别以及这些产物如何在项目中组织的具体方法。
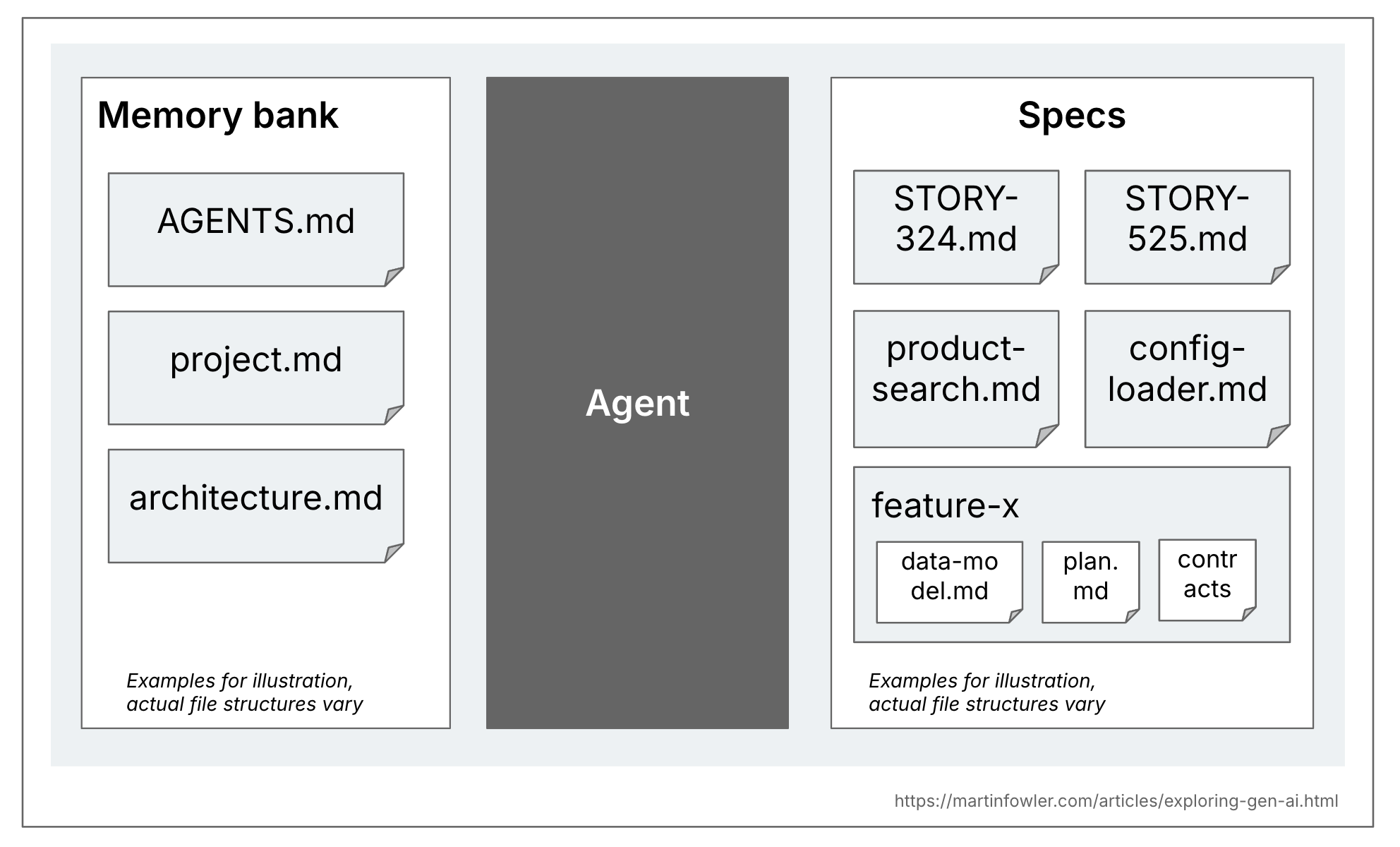
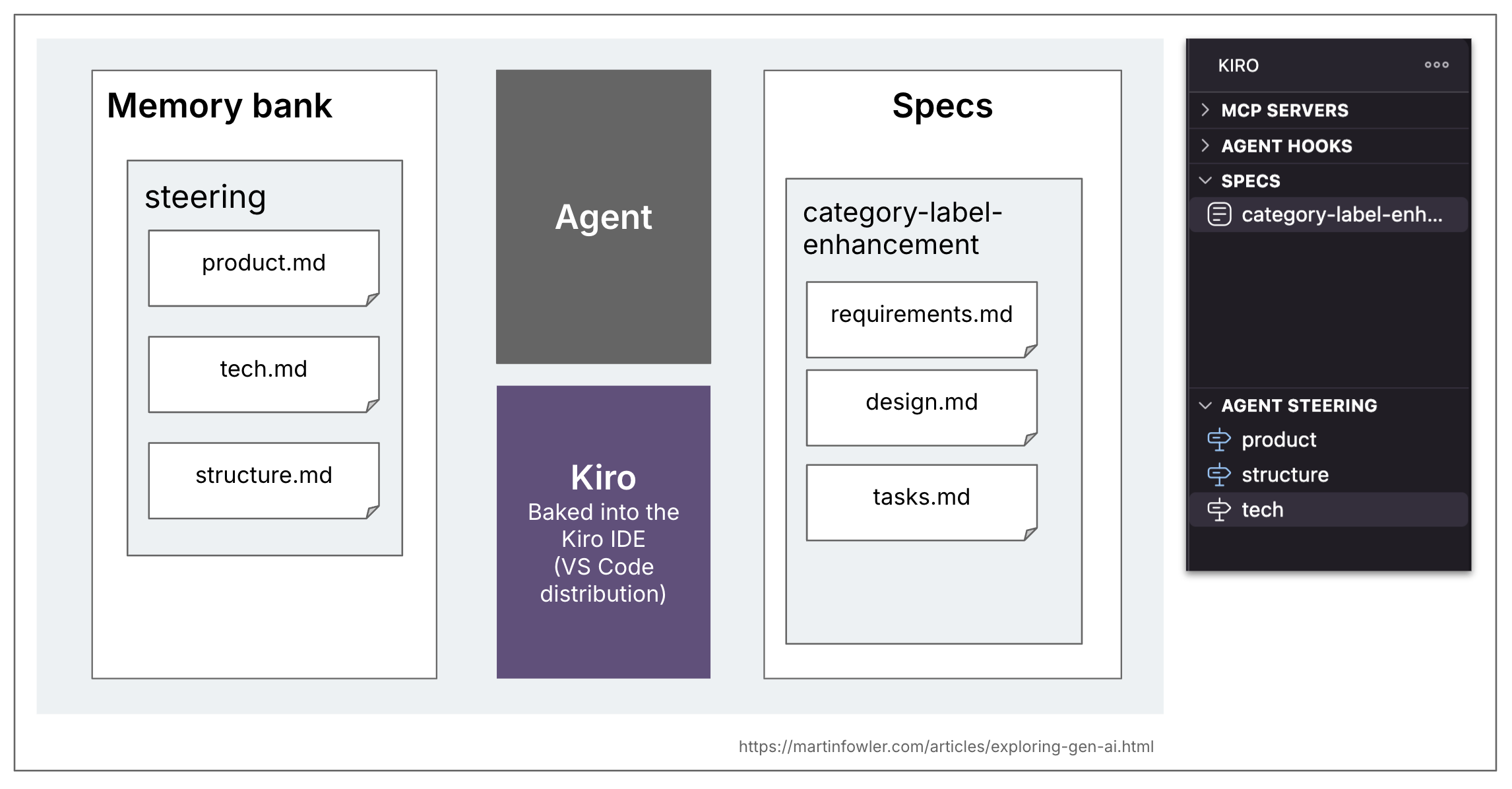
我认为有必要区分规格(spec)和代码库的更一般性上下文文档。这种一般性上下文是规则文件,或代码库和产品的高层描述。一些工具称之为记忆库(memory bank),所以我将在此处沿用此术语。这些文件与代码库中所有AI编码会话相关,而规格只与实际创建或更改特定功能的任务相关。
评估SDD工具的挑战
事实证明,以接近真实使用的方式评估SDD工具和方法非常耗时。你需要针对不同规模的问题、新项目(greenfield)和现有项目(brownfield)进行尝试,并真正花时间审阅和修改中间产物,而不仅仅是走马观花地看一眼。正如GitHub关于spec-kit的博客文章所说:“至关重要的是,你的角色不仅仅是引导。而是要验证。在每个阶段,你都要反思和完善。”
对于我尝试的三个工具中的两个来说,将它们引入现有代码库似乎工作量更大,这使得评估它们对现有项目(brownfield)的有用性更加困难。在听到有人在“真实”代码库上长期使用它们的报告之前,我对它在现实生活中如何运作仍有许多疑问。
尽管如此,让我们深入了解这三个工具。我将首先介绍它们的工作原理(或者说我所认为的工作原理),并将我的观察和疑问留到最后。请注意,这些工具发展非常快,所以自从我九月份使用它们以来,它们可能已经有所变化了。
Kiro:轻量级的工作流
Kiro是这三者中最简单(或最轻量级)的一个。它似乎主要是“规格先行”的,我找到的所有示例都将其用于一个任务或一个用户故事,没有提及如何随着时间的推移,在多个任务中以“规格锚定”的方式使用需求文档。
工作流程: 需求(Requirements)→ 设计(Design)→ 任务(Tasks)
每个工作流程步骤都由一个Markdown文档表示,Kiro引导您在其基于VS Code的发行版中完成这三个步骤。
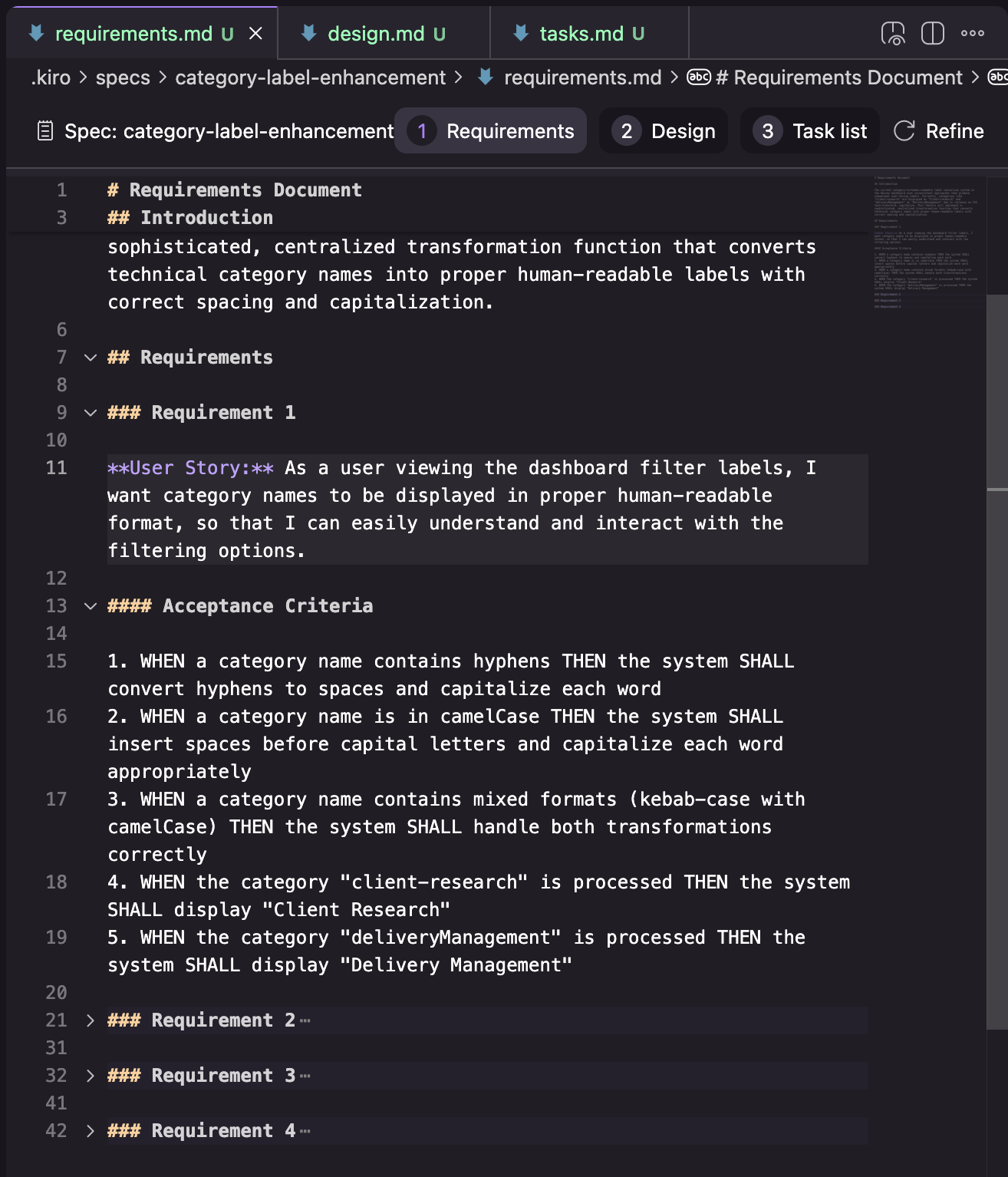
需求(Requirements): 结构为需求列表,每个需求代表一个“用户故事”(采用“As a…”格式),并附带验收标准(采用“GIVEN… WHEN… THEN…”格式)。
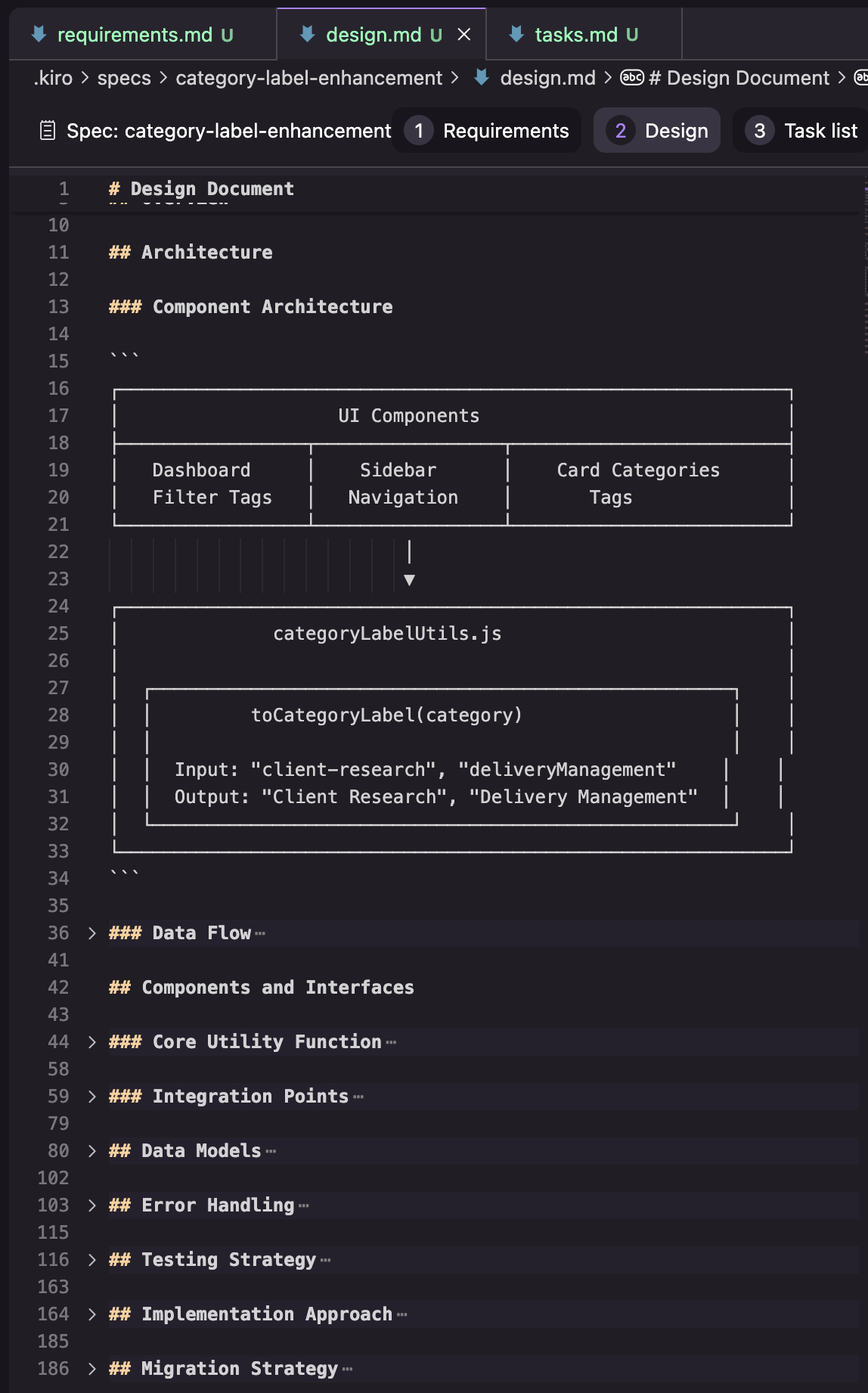
设计(Design): 在我的尝试中,设计文档由下面的截图中看到的章节组成。我只保留了其中一次尝试的结果,所以我不确定这是否是一个一致的结构,或者它是否会根据任务而变化。
任务(Tasks): 一个任务列表,追溯到需求编号,并包含一些额外的UI元素,用于逐个运行任务并审查每个任务的更改。
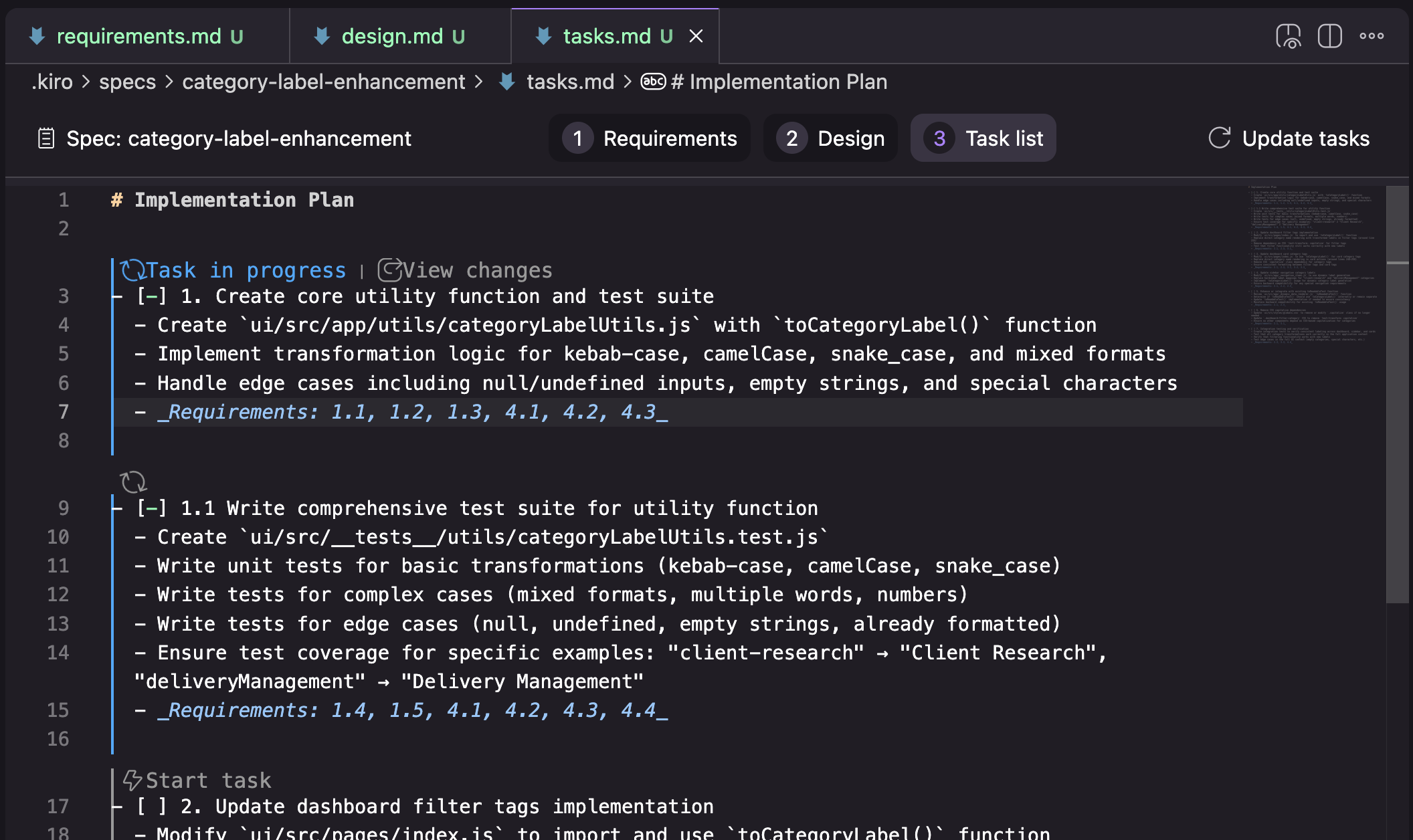
Kiro也有一个记忆库的概念,他们称之为“引导”(steering)。其内容是灵活的,并且它们的工作流程似乎不依赖于任何特定文件的存在(在我发现“引导”部分之前就进行了使用尝试)。Kiro在你要求它生成引导文档时创建的默认拓扑结构是 `product.md`, `structure.md`, `tech.md`。
Spec-kit:GitHub 的方法
Spec-kit是GitHub版本的SDD。它作为一个CLI分发,可以为各种常见编码助手创建工作区设置。设置好结构后,您可以通过编码助手中的斜杠命令与spec-kit交互。由于其所有产物都直接放入工作区,因此它是这里讨论的三种工具中最可定制的一个。
工作流程: 章程(Constitution)→ 𝄆 指定(Specify)→ 计划(Plan)→ 任务(Tasks)𝄇
Spec-kit的记忆库概念是规格驱动方法的前提。他们称之为章程(constitution)。章程应该包含“不可变的”高层原则,这些原则应始终应用于任何更改。它基本上是一个非常强大的规则文件,被工作流程大量使用。
在每个工作流程步骤(指定、计划、任务)中,spec-kit借助Bash脚本和一些模板实例化一组文件和提示。然后工作流程大量使用文件中的清单(checklists),以跟踪必要的_用户澄清_、_章程违规_、_研究任务_等。它们就像每个工作流程步骤的“完成定义”(尽管由AI解释,因此不能100%保证它们会被遵守)。
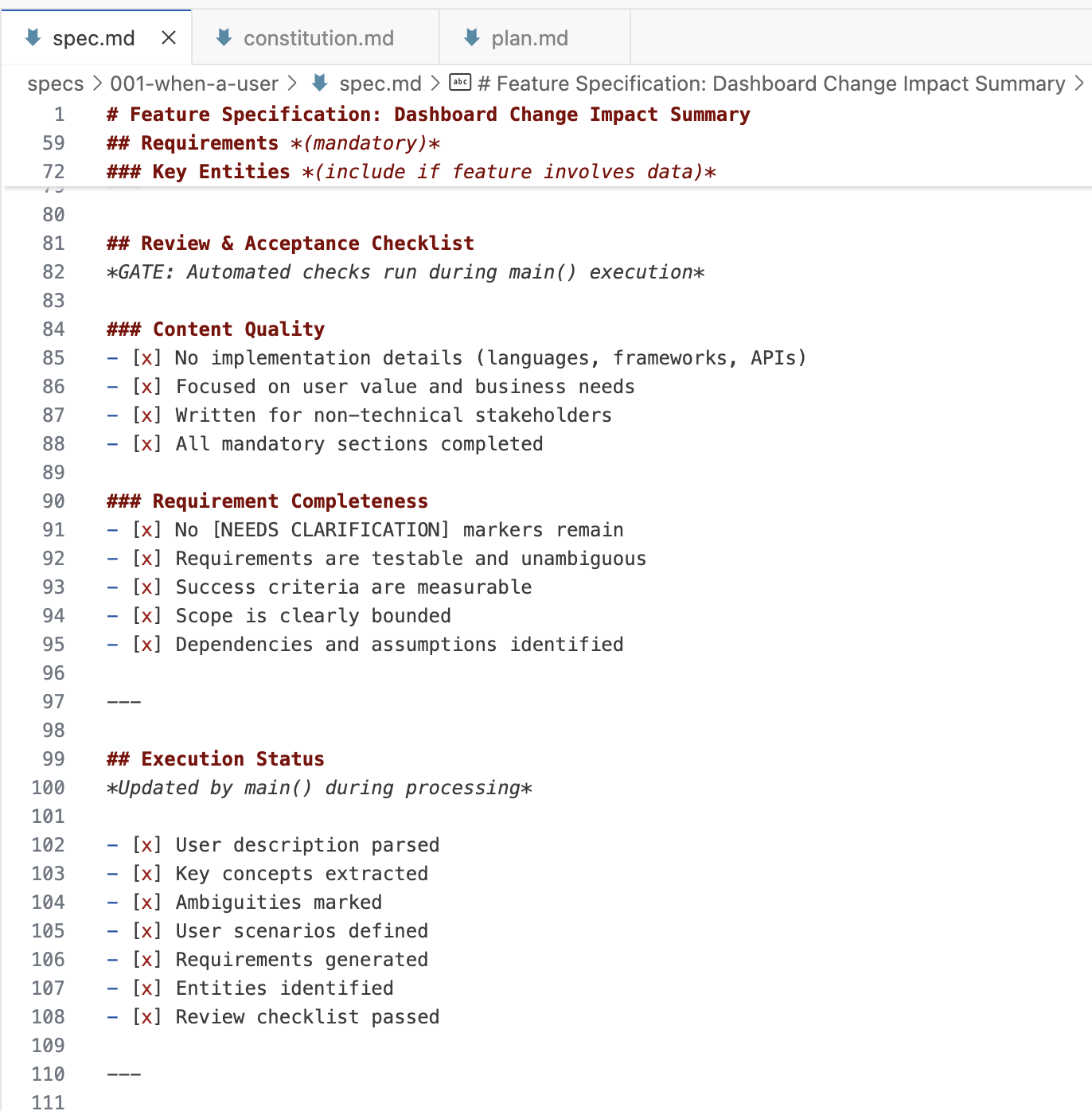
下面是一个概述图,说明我在spec-kit中看到的文件的拓扑结构。请注意,一个规格是如何由许多文件组成的。
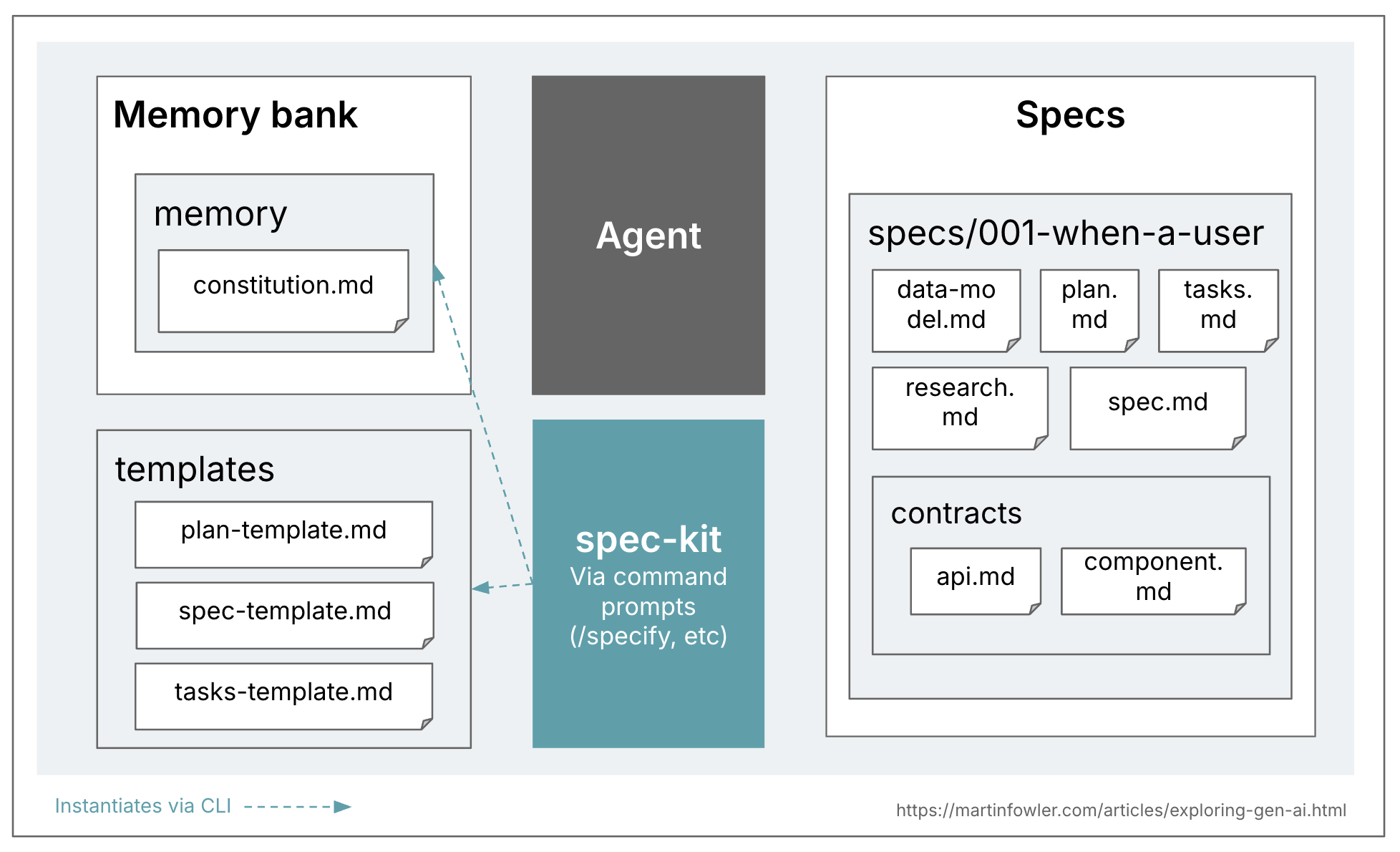
乍一看,GitHub似乎有志于采用“规格锚定”方法(“这就是为什么我们正在重新思考规格——不是作为静态文档,而是作为随项目发展的、可执行的产物。规格成为共享的真值来源。当事情不合理时,你回到规格;当项目变得复杂时,你改进它;当任务感觉太庞大时,你将其分解。”)。然而,spec-kit为每个创建的规格都会创建一个分支,这似乎表明他们将规格视为变更请求生命周期中的一个活动产物,而不是特性的生命周期。一个社区讨论正在讨论这种困惑。这让我想,spec-kit仍然只是我所说的“规格先行”,而不是随时间推移的“规格锚定”。
Tessl 框架
(仍处于私有Beta测试阶段)
与spec-kit一样,Tessl 框架也是作为一个CLI分发的,它可以为各种编码助手创建所有工作区和配置结构。CLI命令兼作MCP服务器。
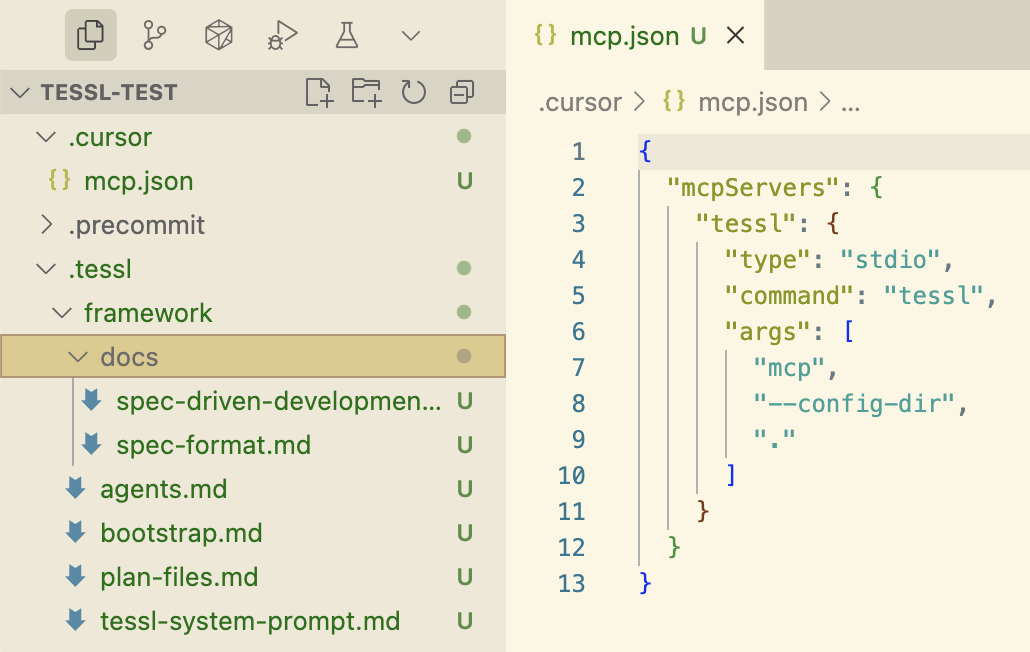
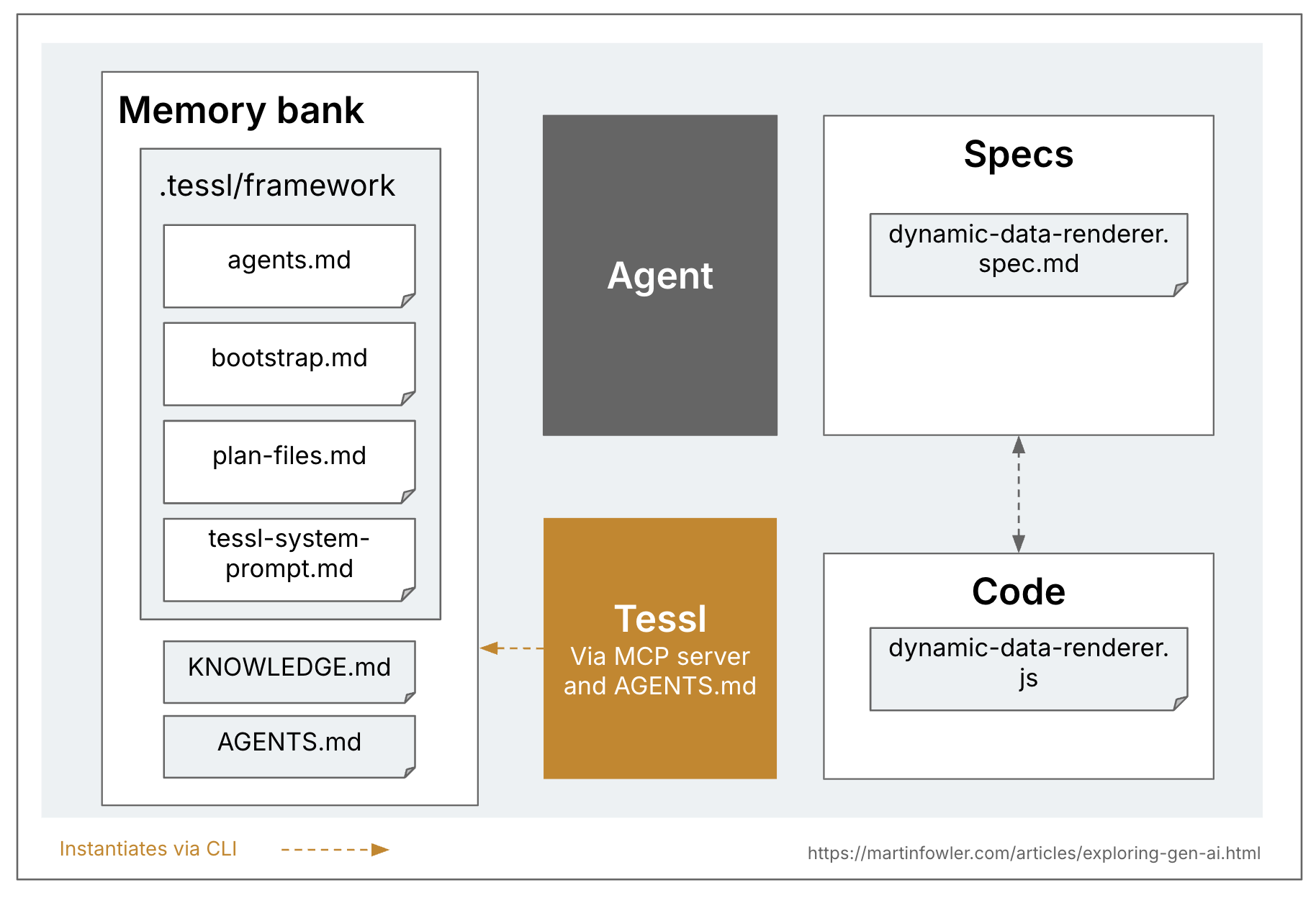
Tessl是这三个工具中唯一明确以“规格锚定”方法为目标,甚至正在探索SDD的“规格即源”层面的工具。Tessl规格可以作为被维护和编辑的主要产物,代码顶部甚至会用注释标记// GENERATED FROM SPEC - DO NOT EDIT。这目前是规格和代码文件之间的一对一映射,即一个规格转换成代码库中的一个文件。但Tessl仍处于Beta阶段,他们正在试验此方法的不同版本,所以我可以想象这种方法也可以在单个规格映射到具有多个文件的代码组件的层面上采用。最终的正式产品将支持什么,还有待观察。(Tessl团队自己认为他们的框架比他们当前的公开产品——Tessl Registry——更具前瞻性。)
这是我让Tessl CLI从现有代码库的JavaScript文件中反向工程(tessl document --code ...js)出的一个规格示例:
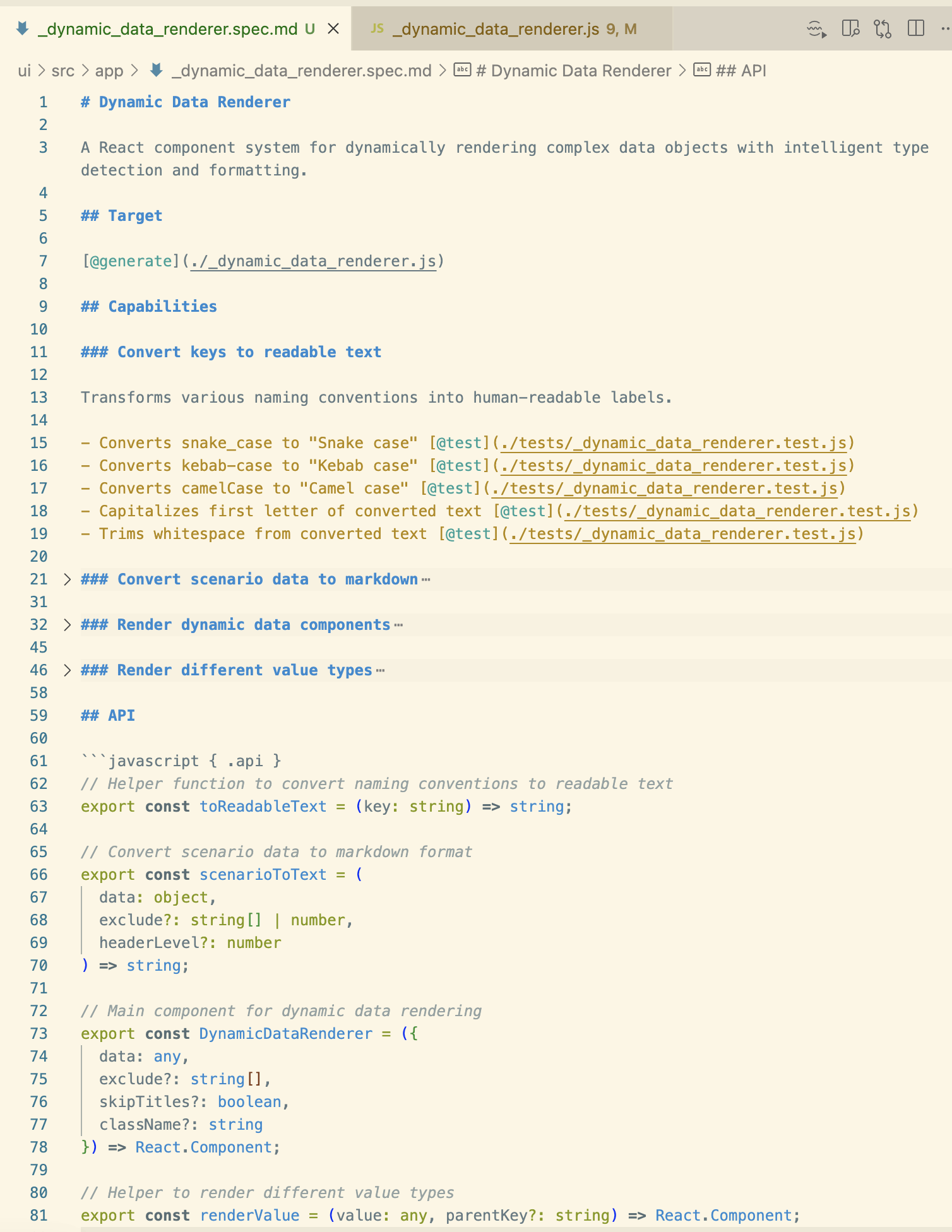
像@generate或@test这样的标签似乎告诉Tessl要生成什么。API部分展示了在规格中定义至少暴露给代码库其他部分接口的想法,以确保这些更关键的生成组件部分完全受维护者控制。运行tessl build针对此规格会生成相应的JavaScript代码文件。
将“规格即源”的规格设置在相当低的抽象级别,每个代码文件对应一个规格,可能减少了LLM必须执行的步骤和解释次数,从而减少了错误的几率。即使在这个低抽象级别上,当我从同一规格多次生成代码时,我也看到了非确定性的表现。迭代规格并使其越来越具体,以提高代码生成的重复性,这是一个有趣的练习。这个过程让我想起了编写明确无歧义和完整的规范时遇到的一些陷阱和挑战。
观察与疑问
这三个工具都将自己标记为规格驱动开发的实现,但它们彼此差异很大。因此,在谈论SDD时,首先要记住的一点是:它不仅仅指代一件事。
一个工作流程适合所有规模吗?
Kiro和spec-kit分别提供了一个固定的工作流程,但我很确定它们中的任何一个都不适合大多数现实世界的编码问题。特别是,我不太清楚它们如何能适应足够多的不同问题规模以实现普遍适用性。
当我要求Kiro修复一个小错误时(正是我过去用来测试Codex的同一个错误),很快就清楚地表明,这个工作流程就像用大锤砸核桃。需求文档将这个小错误变成了4个“用户故事”,共计16个验收标准,其中包括“用户故事:作为一个开发者,我希望转换函数能优雅地处理边缘情况,以便在新类别格式引入时系统保持健壮性”这样的精彩内容。
当我使用spec-kit时也遇到了类似的问题,我不确定应该用它来处理什么规模的问题。可用的教程通常是基于从头创建应用程序,因为这对教程来说最简单。我尝试的用例之一是一个特性,在我过去的一个团队中,它大约相当于一个3-5点的故事点。该特性依赖于大量现有代码,它本应构建一个模态窗口,总结来自现有仪表板的许多数据。鉴于spec-kit所采取的步骤数量,以及它为我创建的大量需要审查的Markdown文件,这对于问题的规模来说仍然显得小题大做了。虽然问题比我用Kiro处理的要大,但其工作流程也更加复杂。我甚至没有完成全部实现,但我认为,花在我运行和审查spec-kit结果的时间里,我本可以用“纯粹的”AI辅助编码来实现这个特性,并且我会感觉自己控制力更强。
一个有效的SDD工具至少应该为不同大小和类型的更改提供一些不同的核心工作流程的灵活性。
是审查Markdown文件,还是审查代码?
如前所述,以及您在上面工具描述中看到的,spec-kit为我创建了_大量_的Markdown文件需要审查。它们之间以及与现有代码之间存在重复。有些甚至包含代码。总的来说,它们非常冗长且审查起来很乏味。在Kiro中情况稍微好一些,因为它只提供3个文件,并且理解“需求 > 设计 > 任务”的思维模型更直观。但是,如前所述,Kiro对于我要求它修复的小错误来说也过于冗长了。
坦率地说,我宁愿审查代码,也不愿审查所有这些Markdown文件。一个有效的SDD工具必须提供非常好的规格审查体验。
失控的虚假控制感?
即使有所有这些文件、模板、提示、工作流程和清单,我也经常看到智能体最终没有遵循所有指示。是的,上下文窗口现在更大了,这通常被认为是规格驱动开发的推动因素之一。但上下文窗口变大,并不意味着AI会正确地采纳其中的所有内容。
例如:Spec-kit在计划过程中有一个研究步骤,它对现有代码和已存在的内容进行了大量研究,这很棒,因为我要求它添加一个基于现有代码的特性。但最终,智能体忽略了这些是现有类描述的注释,它只是将它们视为新的规范并重新生成了所有内容,从而创建了重复项。但我看到的不仅是忽略指令的例子,我也看到了智能体因过于热切地遵循指令而反应过度(例如,章程中的一条规定)。
过去已经表明,我们保持对正在构建的内容的控制的最佳方法是小步迭代,所以我非常怀疑大量预先的设计规格是个好主意,特别是当它过于冗长时。一个有效的SDD工具必须适应迭代方法,但小的工作包几乎与SDD的理念背道而驰。
如何有效地分离功能规格和技术规格?
在SDD中,有意识地分离功能规格和技术实现是一个常见的想法。其根本的愿望,我想是最终我们可以让人工智能来填补所有解决方案和细节,并使用相同的规格切换到不同的技术栈。
在现实中,当我尝试spec-kit时,我经常不确定何时应该停留在功能层面,何时该添加技术细节。教程和文档在这方面也不太一致,似乎对“纯功能性”到底意味着什么有不同的解释。而且,当我回想起我职业生涯中读过的许多许多没有正确分离需求和实现的“用户故事”时,我不认为我们作为一个专业群体在这方面有很好的记录。
目标用户是谁?
许多SDD工具的演示和教程都涉及定义产品和特性目标,它们甚至纳入了“用户故事”等术语。这里的想法可能是使用AI作为跨技能培养的推动者,让开发人员更深入地参与需求分析?或者让开发人员在这个工作流程中与产品人员结对工作?这些都没有明确说明,而是被当作是开发人员会进行所有这些分析的当然之举。
在这种情况下,我再次问自己,SDD的目的是针对多大和哪种类型的问题?可能不是针对仍然非常不清楚的大型特性,因为那肯定需要更多的专业产品和需求技能,以及大量的其他步骤,如研究和利益相关者参与?
规格锚定和规格即源:我们从过去吸取教训了吗?
虽然许多人将SDD与TDD或BDD进行类比,但我认为对于“规格即源”,另一个重要的借鉴对象是MDD(模型驱动开发)。在我职业生涯的开始,我参与了几个大量使用MDD的项目,当我尝试Tessl框架时,我不断地想起MDD。MDD中的模型基本上就是规格,尽管不是用自然语言,而是用例如自定义UML或文本DSL来表达的。我们构建了自定义代码生成器,将这些规格转换为代码。

最终,MDD从未在商业应用中流行起来,它处于一个尴尬的抽象层次,只是带来了过多的开销和限制。但是,LLM消除了MDD的一些开销和限制,因此有了新的希望,我们现在终于可以专注于编写规格并直接从中生成代码了。有了LLM,我们不再受预先定义和可解析的规格语言的约束,也不必构建复杂的代码生成器。为此付出的代价当然是LLM的非确定性。而且,可解析的结构也有我们现在正在失去的优点:我们可以为规格作者提供大量的工具支持,以编写有效、完整和一致的规格。我怀疑“规格即源”,甚至“规格锚定”,最终可能会兼具MDD和LLM的缺点:_缺乏灵活性_加上_非确定性_。
明确地说,我并不怀念过去使用MDD的经历,也不是说“我们不妨把它们带回来”。但是,当我们今天探索规格驱动开发时,我们应该借鉴过去从代码生成规格的尝试中吸取的教训。
结论
在我个人使用AI辅助编码的经历中,我也经常花时间仔细构建某种形式的规格先行方案,交给编码智能体。因此,“规格先行”的一般原则在许多情况下确实很有价值,而如何构建该规格的不同方法目前非常受追捧。它们是我目前从实践者那里听到的最常被问到的问题之一:“我如何构建我的记忆库?”、“我如何为AI编写好的规格和设计文档?”。
但是,“规格驱动开发”这个术语尚未被很好地定义,它已经语义扩散了。我最近甚至听到人们将“spec”基本上用作“详细提示”(detailed prompt)的同义词。
关于我尝试过的工具,我在这里列出了许多关于它们在现实世界中实用性的疑问。我怀疑其中一些工具是否试图过于字面地将我们现有的工作流程输入给AI智能体,从而最终放大了审查过载和幻觉等现有挑战。特别是对于那些创建了大量文件的更精细的方法,我忍不住想起了德语复合词“Verschlimmbesserung”:我们是否在试图改进的过程中让事情变得更糟了?
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,小白也可以简单操作。
青云聚合API官网https://api.qingyuntop.top
支持全球最新300+模型:https://api.qingyuntop.top/pricing
详细的调用教程及文档:https://api.qingyuntop.top/about
评论区