



📢 转载信息
原文作者:Iván Palomares Carrascosa
在本文中,您将了解五种实用的提示词压缩(prompt compression)技术,它们可以在不牺牲任务质量的情况下,减少大型语言模型(LLM)的令牌数量并加速其生成过程。
我们将涵盖的主题包括:
- 什么是语义摘要(semantic summarization)及其使用时机
- 结构化提示(structured prompting)、相关性过滤(relevance filtering)和指令引用(instruction referencing)如何削减令牌数量
- 模板抽象(template abstraction)的适用位置及其如何保持一致性地应用
让我们来探索这些技术。
提示词压缩以优化LLM生成和降低成本
图片来源:Editor
引言
大型语言模型(LLMs)主要经过训练,用于对用户的查询或提示词生成文本回复。其复杂的推理过程不仅涉及通过预测输出序列中的每个下一个令牌来进行语言生成,还包含对用户输入文本周围语言模式的深入理解。
由于较大的用户提示词和上下文窗口导致推理缓慢且耗时,提示词压缩技术在最近的LLM领域受到了广泛关注。这些技术旨在帮助减少令牌使用量、加速令牌生成并降低总体计算成本,同时尽可能保持任务结果的质量。
本文将介绍并描述五种常用的提示词压缩技术,以加速在具有挑战性场景下的LLM生成。
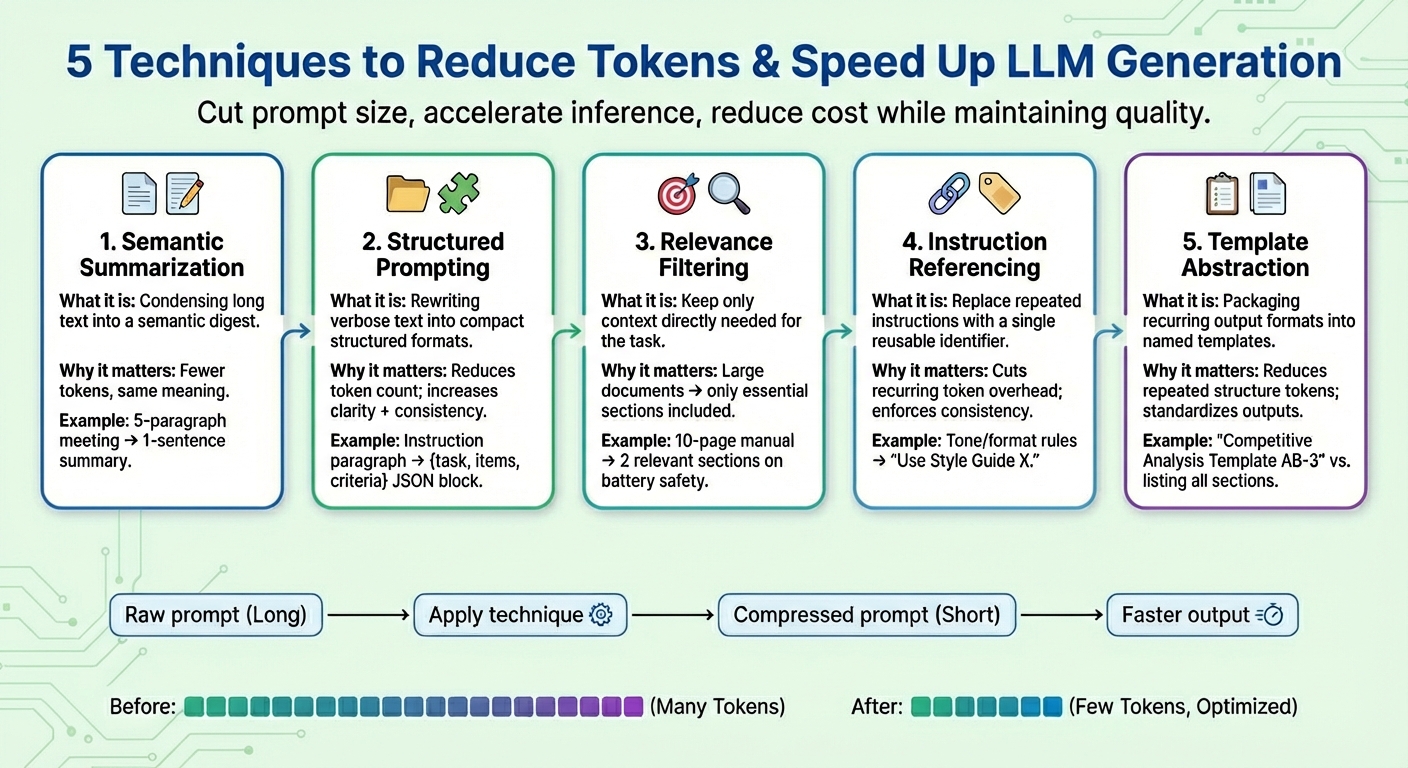
1. 语义摘要
语义摘要是一种将冗长或重复的内容提炼成更简洁版本,同时保留其基本语义的技术。不是将整个对话或文本文档迭代地喂给模型,而是传递一个只包含关键信息的摘要。其结果是,模型需要“阅读”的输入令牌数量降低了,从而加速了下一令牌的生成过程,并在不丢失关键信息的情况下降低了成本。
假设有一个很长的提示词上下文,其中包含会议纪要,例如:“在昨天的会议中,Iván审查了季度数据……”,共计五段。经过语义摘要后,缩短后的上下文可能看起来像:“摘要:Iván审查了季度数据,强调了第四季度销售下滑,并提出了节约成本的措施。”
2. 结构化(JSON)提示
这项技术侧重于将冗长、流畅的文本信息表达为紧凑的半结构化格式,如JSON(即键值对)或项目符号列表。结构化提示的目标格式通常需要减少令牌数量。这有助于模型更可靠地解释用户指令,从而提高模型的一致性并减少歧义,同时也减少了提示词的长度。
结构化提示算法可以将包含如下指令的原始提示词,如“请对产品X和产品Y进行详细比较,重点关注价格、产品特性和客户评分”,转换为结构化形式,例如:“{task: “compare”, items: [“Product X”, “Product Y”], criteria: [“price”, “features”, “ratings”]}”
3. 相关性过滤
相关性过滤遵循“关注真正重要的事情”的原则:它测量文本各个部分的相关性,并将只有与当前任务真正相关的上下文片段纳入最终的提示词中。与其将作为上下文的整个文档倾倒给模型,不如只保留与目标请求最相关的一小部分信息。这是大幅减少提示词大小的另一种方式,并有助于模型在专注度和提高预测准确性方面表现得更好(请记住,LLM的令牌生成本质上是重复进行多次的下一个词预测任务)。
例如,假设将一部10页的手机产品手册作为附件(提示词上下文)加入。应用相关性过滤后,只保留关于“电池续航”和“充电过程”的几段简短相关内容,因为用户的提示是关于设备充电时的安全影响。
4. 指令引用
许多提示词会反复出现相同类型的方向,例如“采用这种语气”、“以这种格式回复”或“使用简洁的句子”等等。指令引用为每条常见的指令(由一组令牌组成)创建一个引用,只注册一次,并将其作为单个令牌标识符重复使用。将来任何提及该已注册的“常见请求”的提示词,都会使用该标识符。除了缩短提示词外,此策略还有助于随着时间的推移保持任务行为的一致性。
一组组合指令,如“使用友好的语气。避免使用术语。保持句子简短。提供示例。”,可以简化为“使用风格指南X”,当再次指定等效指令时,就可以重复使用该引用。
5. 模板抽象
某些模式或指令经常出现在各种提示词中——例如报告结构、评估格式或分步程序。模板抽象应用了与指令引用类似的原则,但它侧重于生成输出应具有的形状和格式,将这些常见模式封装在模板名称下。然后使用模板引用,让LLM负责填充其余信息。这不仅有助于使提示词更清晰,还极大地减少了重复令牌的出现。
经过模板抽象后,提示词可能被转换为类似“使用模板AB-3生成竞争分析”的形式,其中AB-3是所请求内容部分的列表,每个部分都清晰定义。例如:
生成一份竞争分析,包含四个部分:
- 市场概览(2-3段,总结行业趋势)
- 竞争者细分(包含至少5个竞争者的表格)
- 优缺点分析(项目符号列表)
- 战略建议(3个可操作步骤)。
总结
本文介绍了五种常用的方法,通过压缩用户提示词来加速LLM的生成,这些压缩通常侧重于上下文部分。上下文往往是导致LLM减速的“提示词超载”的根源。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区