



📢 转载信息
原文链接:https://www.kdnuggets.com/tpot-automating-ml-pipelines-with-genetic-algorithms-in-python
原文作者:Kanwal Mehreen
# 引言
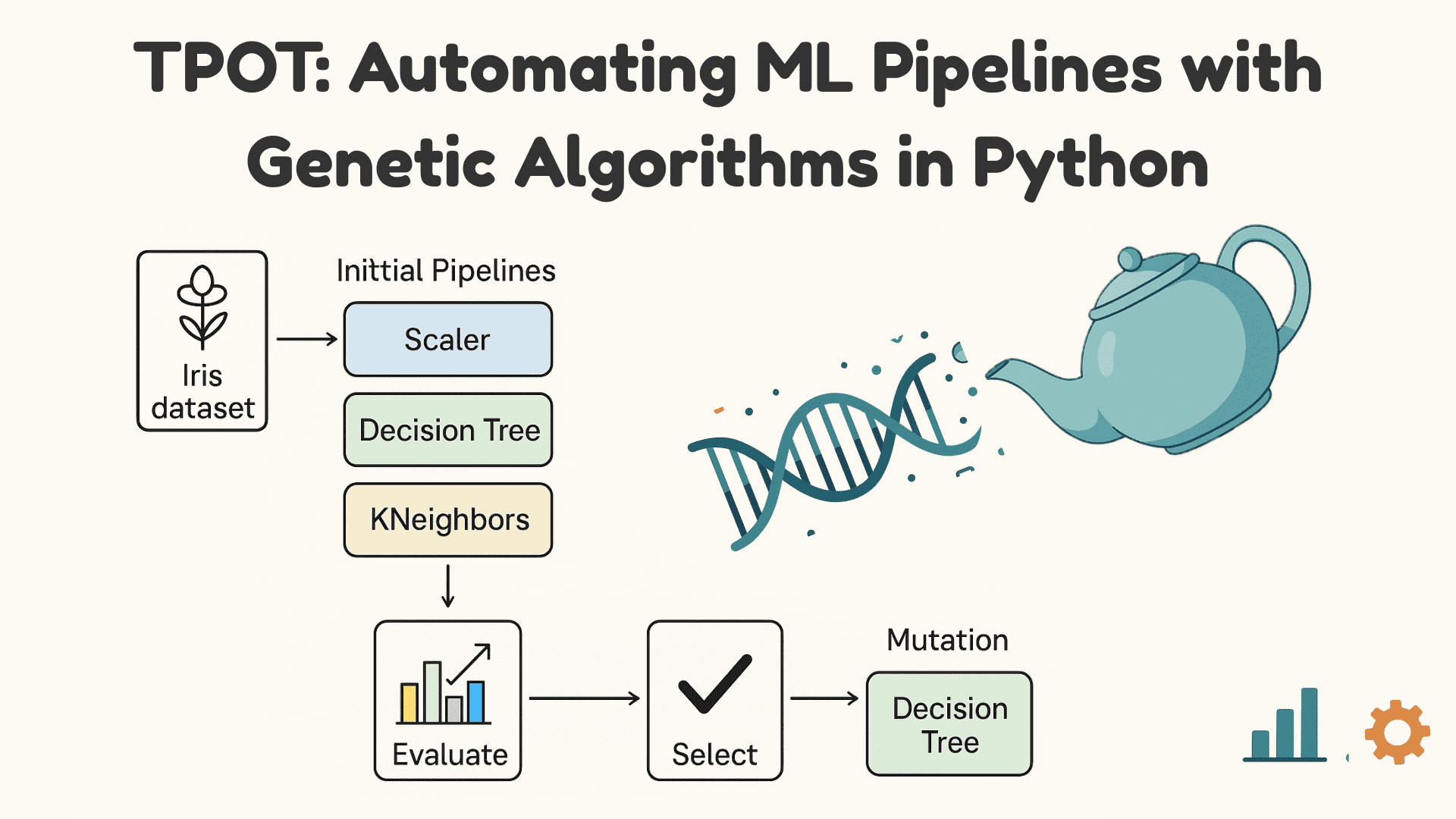
手动构建一个机器学习模型涉及一长串的决策。这其中包含许多步骤,例如清洗数据、选择正确的算法以及调整超参数以获得良好的结果。这种反复试验的过程往往需要数小时甚至数天。然而,使用树形管道优化工具(Tree-based Pipeline Optimization Tool),即TPOT,可以解决这个问题。
TPOT是一个Python库,它使用遗传算法自动搜索最佳的机器学习管道。它将管道视为自然界中的一个种群:它尝试许多组合,评估它们的性能,并在多代中“进化”出最佳的组合。这种自动化使您能够专注于解决问题,而TPOT则负责处理模型选择和优化的技术细节。
# TPOT的工作原理
TPOT利用遗传编程(Genetic Programming,GP)。这是一种受生物界自然选择启发的进化算法类型。GP不是进化生物体,而是进化计算机程序或工作流来解决问题。在TPOT的上下文中,被进化的“程序”就是机器学习管道。
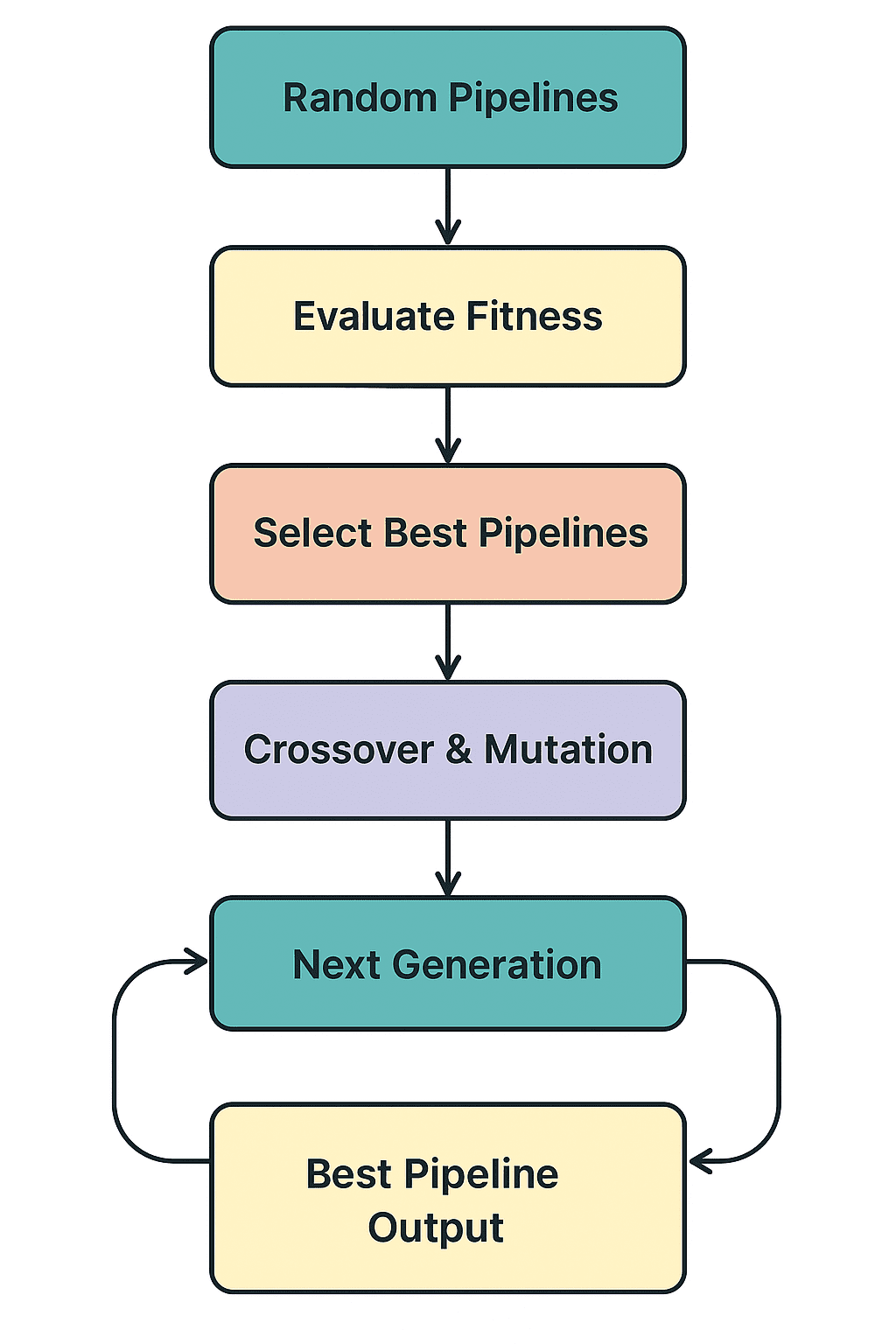
TPOT主要通过以下四个步骤工作:
- 生成管道: 它从一个随机的机器学习管道种群开始,其中包括预处理方法和模型。
- 评估适应度: 对每个管道进行训练和评估,以衡量其性能。
- 选择与进化: 选择表现最佳的管道进行“繁殖”,通过交叉(crossover)和变异(mutation)产生新的管道。
- 迭代世代: 这个过程会重复多代,直到TPOT识别出性能最佳的管道。
该过程如下图所示:
接下来,我们将研究如何在Python中设置和使用TPOT。
# 1. 安装TPOT
要安装TPOT,请运行以下命令:
pip install tpot
# 2. 导入库
导入所需的库:
from tpot import TPOTClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 3. 加载和划分数据
我们将使用流行的鸢尾花(Iris)数据集作为示例:
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
load_iris()函数提供了特征X和标签y。train_test_split函数会保留一个测试集,以便您可以衡量模型在未见数据上的最终性能。这为管道评估搭建了环境。所有管道都在训练部分上进行训练并进行内部验证。
注意: TPOT在适应度评估期间使用内部交叉验证。
# 4. 初始化TPOT
按如下方式初始化TPOT:
tpot = TPOTClassifier( generations=5, population_size=20, random_state=42 )
您可以控制TPOT搜索良好管道的时长和范围。例如:
- generations=5 意味着TPOT将运行五个进化周期。在每个周期中,它会根据上一代创建一组新的候选管道。
- population_size=20 意味着每代中有20个候选管道。
- random_state 确保结果是可重现的。
# 5. 训练模型
通过运行以下命令来训练模型:
tpot.fit(X_train, y_train)
当您运行tpot.fit(X_train, y_train)时,TPOT开始搜索最佳管道。它创建一个候选管道组,训练每一个管道以查看其性能如何(通常使用交叉验证),并保留表现最佳的管道。然后,它混合并轻微改变这些管道以生成新的一组。此循环会根据您设置的代数重复进行。TPOT始终会记住到目前为止表现最好的管道。
输出:
# 6. 评估准确率
这是您对所选管道在未见数据上表现的最终检查。您可以按如下方式计算准确率:
y_pred = tpot.fitted_pipeline_.predict(X_test)
acc = accuracy_score(y_test, y_pred)
print("Accuracy:", acc)
输出:
Accuracy: 1.0
# 7. 导出最佳管道
您可以将管道导出到文件中以供将来使用。请注意,我们必须首先从Joblib导入dump:
from joblib import dump
dump(tpot.fitted_pipeline_, "best_pipeline.pkl")
print("Pipeline saved as best_pipeline.pkl")
joblib.dump()将整个拟合模型存储为best_pipeline.pkl。
输出:
Pipeline saved as best_pipeline.pkl
您可以稍后按如下方式加载它:
from joblib import load
model = load("best_pipeline.pkl")
predictions = model.predict(X_test)
这使得您的模型可重用且易于部署。
# 总结
在本文中,我们了解了如何使用遗传编程自动化机器学习管道,并演示了在Python中实现TPOT的实际示例。如需进一步探索,请参阅文档。
Kanwal Mehreen 是一名机器学习工程师和技术作家,对数据科学以及人工智能与医学的交叉领域抱有深厚的热情。她是电子书《Maximizing Productivity with ChatGPT》的合著者。作为2022年亚太地区谷歌一代学者,她倡导多样性和学术卓越。她还被认定为Teradata技术多样性学者、Mitacs全球研究学者和哈佛WeCode学者。Kanwal是变革的热心倡导者,她创立了FEMCodes来赋能STEM领域的女性。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区