



📢 转载信息
原文作者:Bruno Pistone, Giuseppe Angelo Porcelli, Chen Wu, and Yin Song
人工智能(AI)的快速发展对能够执行复杂推理任务的专业模型产生了前所未有的需求,特别是在竞技编程领域,模型必须通过算法推理而非模式记忆来生成可用的代码。强化学习(RL)通过根据实际代码执行接收奖励,使模型能够通过试错进行学习,这使得它特别适合在算法领域培养真正的解决问题能力。
然而,为代码生成实施分布式 RL 训练带来了重大的基础设施挑战,例如协调多个异构组件、跨节点并行代码编译,以及维护长期运行流程的容错性。Ray 是解决这些挑战的分布式工作负载框架之一,因为它拥有处理整个 AI 管道、以 GPU 为先的架构以及与 Hugging Face Transformers 和 PyTorch 等工具的无缝集成。
可以通过使用 Ray on Amazon SageMaker Training jobs 解决方案,在 SageMaker 训练作业中使用 Ray 框架运行工作负载。该解决方案将 Ray 的分布式计算框架与 SageMaker 的完全托管基础设施相结合。此解决方案自动处理 Ray 集群初始化、多节点协调和分布式资源管理,使开发人员能够专注于模型开发,同时受益于 SageMaker 的企业级功能。
在本文中,我们将演示如何使用 Group Relative Policy Optimization (GRPO) 结合 veRL 来训练 CodeFu-7B,这是一个专门用于竞技编程的 70 亿参数模型。veRL 是一个灵活高效的 LLM 训练库,支持轻松扩展各种 RL 算法,并与现有 LLM 基础设施无缝集成,所有这些都在由 SageMaker 训练作业管理的分布式 Ray 集群中进行。我们将介绍完整的实施过程,涵盖数据准备、分布式训练设置和全面的可观测性,展示这种统一的方法如何为复杂的 RL 训练工作负载提供计算规模和开发者体验。
关于 CodeFu-7B
CodeFu-7B-v0.1 是一个 7B 参数语言模型,专门用于解决竞技编程(CP)问题。它基于 DeepSeek-R1-Distill-Qwen-7B 基础模型构建,CodeFu 展示了强化学习如何培养算法推理和高效 C++ 代码生成能力,超越传统的监督微调方法。
该模型使用来自 DeepMind CodeContest 数据集中的问题进行训练,训练过程中不访问真实解,迫使模型仅根据代码执行反馈通过试错学习。这种方法有助于培养真正的解决问题能力,而非模式记忆。
CodeFu 已在 HuggingFace 上公开提供,并根据 MIT 许可发布,对有兴趣进行代码生成和算法推理的研究人员和实践者开放。该模型的训练方法展示了将强化学习技术应用于复杂推理任务的潜力,而不仅仅局限于竞技编程。
SageMaker 训练作业中的 Ray 解决方案
Ray on Amazon SageMaker Training jobs 是一个解决方案,它可以在 SageMaker 的托管训练环境中实现使用 Ray 进行分布式数据处理和模型训练。该解决方案提供了关键功能,包括用于自动 Ray 集群设置的通用启动器架构、带有智能协调的多节点集群管理、用于混合实例类型的异构集群支持,以及通过 Ray Dashboard、Prometheus、Grafana 和 Amazon CloudWatch 集成实现的综合可观测性。
该解决方案使用现代 ModelTrainer API 与 SageMaker Python SDK 无缝集成。这个在 GitHub 上公开的解决方案使开发人员能够在利用 Ray 的分布式计算能力的同时,受益于 SageMaker 的托管基础设施,非常适合需要复杂分布式协调和资源管理的强化学习训练等复杂工作负载。
解决方案概述
使用 veRL 和 Ray 在 SageMaker 训练作业中训练 CodeFu 7B 的工作流程,如图所示,包括以下步骤:
- 数据准备:上传预处理后的 DeepMind CodeContest 数据集和训练配置。
- 训练作业提交:通过 SageMaker Python SDK 的 ModelTrainer 类提交 SageMaker 训练作业 API 请求。
- 监控和可观测性:通过 Ray Dashboard 实时监控训练进度,并可选地使用 Prometheus 指标收集、Grafana 可视化和实验跟踪。
- 自动清理:训练完成后,SageMaker 自动将训练好的模型保存到 S3,将训练日志上传到 CloudWatch,并退役计算集群。

这种简化的架构提供了一个完全托管的强化学习训练体验,使开发人员能够专注于模型开发,而 SageMaker 和 Ray 则在按需付费模式下处理复杂的分布式基础设施编排,该模式只对实际的计算时间收费。
先决条件
在运行 notebook 之前,必须完成以下先决条件:
- 对 SageMaker AI 提出以下配额增加请求。对于此用例,请求至少 2 个
p4de.24xlarge实例(带有 8 个 NVIDIA A100 GPU),并根据您的用例的训练时间和训练成本权衡扩展到更多的p4de.24xlarge实例。也支持 P5 实例(带有 8 个 NVIDIA H100 GPU)。在 Service Quotas 控制台中,请求以下 SageMaker AI 配额:- 用于训练作业使用的 p4de 实例 (
p4de.24xlarge):2
- 用于训练作业使用的 p4de 实例 (
- 创建一个 AWS Identity and Access Management (IAM) 角色,并附带托管策略
AmazonSageMakerFullAccess、AmazonS3FullAccess和AmazonSSMFullAccess,以授予 SageMaker AI 运行示例所需的访问权限。 - 将以下策略作为创建的 IAM 角色的信任关系:
{
"Version":"2012-10-17",
"Statement":[
{
"Sid":"",
"Effect":"Allow",
"Principal":{
"Service":
"sagemaker.amazonaws.com"
},
"Action":"sts:AssumeRole"
}
]
}- (可选)创建一个 Amazon SageMaker Studio 域(参考使用快速设置设置 Amazon SageMaker AI),以便访问 Jupyter notebooks 来运行训练代码。或者,可以在本地设置或另一个 Python 开发环境中使用 JupyterLab 来执行 notebook 并提交 SageMaker 训练作业。
注意:这些权限授予广泛的访问权限,不建议在生产环境中使用。请参阅SageMaker 开发者指南以获取定义更精细权限的指导
代码示例可以在这个 GitHub 仓库中找到:此 GitHub 仓库。
准备数据集
数据准备管道将原始 DeepMind CodeContest 数据集转换为适合强化学习训练的格式。我们应用系统性过滤器来识别合适的问题,删除 Codeforces 评级低于 800 的问题,并实施质量验证检查,以剔除缺失的测试用例、格式错误的描述和无效的约束。
我们将问题分为三个难度级别:简单(800-1000 分)、困难(1100-2200 分)和专家(2300-3500 分)。本文仅使用简单数据集进行训练。每个问题都格式化为两个组成部分:包含问题陈述的用户提示,以及包含测试用例、时间限制和内存限制的 reward_model 规范。至关重要的是,ground_truth 字段不包含解决方案代码——只有测试用例,这迫使模型通过奖励信号学习,而不是记忆解决方案。
{
"data_source": "code_contests",
"prompt": [
{
"role": "user",
"content": "Write a C++ solution for this problem: ..."
}
],
"ability": "coding-cp",
"reward_model": {
"style": "rule",
"ground_truth": {
"name": "problem 1",
"public_tests": {
"input": ["test input 1", "test input 2"],
"output": ["expected output 1", "expected output 2"]
},
"private_tests": {
"input": ["private input 1", "private input 2"],
"output": ["private output 1", "private output 2"]
},
"time_limit": 2.0,
"memory_limit_bytes": 268435456,
"cf_rating": 1200
}
}
}
对于本文,我们在代码示例中提供了一个预处理后的简单难度数据集子集,以便简化训练示例,可以从 GitHub 仓库访问。
使用 veRL 进行 GRPO 训练
训练过程使用 Ray 来编排 vLLM 滚动、奖励评估(代码编译和执行)、FSDP 模型并行和 Ulysses 序列并行化的分布式执行和同步。我们将序列并行度设置为 4,以处理长篇推理和代码生成。
veRL 框架通过其 main_ppo.py 编排器实现了一个复杂的组件多架构,该编排器协调三种主要的分布式工作负载类型:用于策略推理和滚动的 ActorRolloutRefWorker、用于值函数估计的 CriticWorker,以及用于对生成解决方案进行评分的 RewardModelWorker。
GRPO 算法通过使用组相对基线计算优势来增强传统的 近端策略优化 (PPO),这有助于通过减少策略梯度估计中的方差来稳定训练。
我们通过使用 Ray 来管理和分发奖励函数计算,扩展了 TinyZero 代码仓库。这使得能够在整个集群上并行进行 C++ 代码编译和评估,以解决代码执行的计算密集型和延迟限制特性。整个管道作为在 ml.p4de.24xlarge 实例上运行的 SageMaker 训练作业执行。训练管道由以下步骤组成,如下面的架构所示:
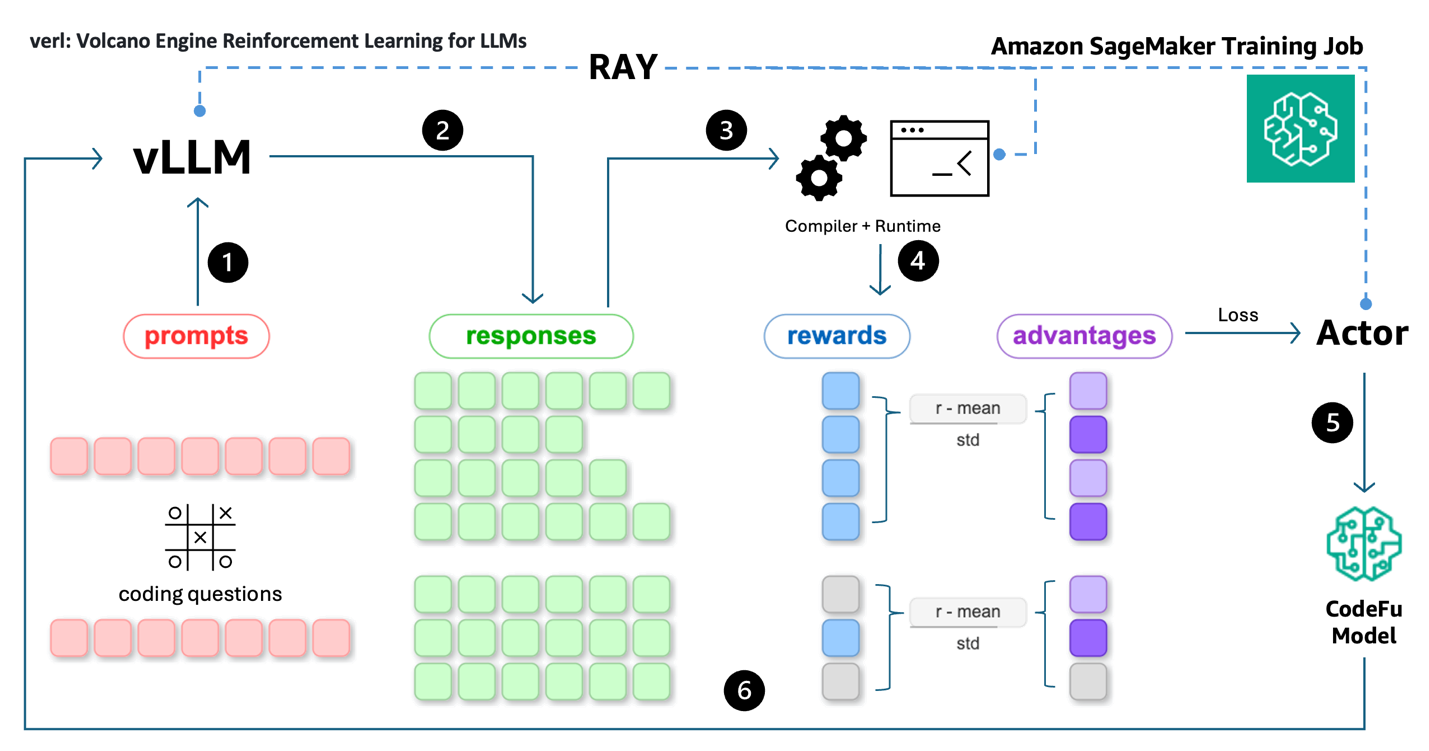
- 滚动 (Rollout):将编码问题提示输入到 vLLM 推理引擎中,以滚动生成潜在的解决方案。
- 响应生成:vLLM 为每个提示生成多个响应(推理 + 代码)。
- 代码执行:从响应中提取代码解决方案,并通过 Ray 管理的分布式工作负载(编译器和运行时)进行编译和执行。
- 奖励计算:执行结果用于计算奖励(即测试用例通过率),并使用组相对基线计算优势。
- 策略更新:Actor 使用优势和 Token 概率来计算 PPO 损失,该损失用于通过梯度下降来更新 CodeFu 的参数。
- 迭代:该过程与一批提示-响应-奖励循环重复进行,Ray 管理跨管道的分布式采样、执行和训练同步。
训练过程的编排涉及在多个模块中实现的几个关键组件。核心 veRL 训练循环实现在 main_ppo.py 中,该文件初始化 Ray 工作负载并管理分布式训练过程:
@ray.remote
def main_task(config):
# Initialize tokenizer and download model
local_path = copy_local_path_from_hdfs(config.actor_rollout_ref.model.path)
tokenizer = hf_tokenizer(local_path)
# Define distributed worker roles
role_worker_mapping = {
Role.ActorRollout: ray.remote(ActorRolloutRefWorker),
Role.Critic: ray.remote(CriticWorker),
Role.RefPolicy: ray.remote(ActorRolloutRefWorker),
}
# Initialize reward manager for code execution
reward_fn = RewardManager(tokenizer=tokenizer, num_examine=0)
# Create and start trainer
trainer = RayPPOTrainer(
config=config,
tokenizer=tokenizer,
role_worker_mapping=role_worker_mapping,
resource_pool_manager=resource_pool_manager,
reward_fn=reward_fn,
)
trainer.init_workers()
trainer.fit()奖励评估系统通过 Ray 远程函数实现并行代码执行,处理 C++ 编译和测试用例执行:
@ray.remote
def process_reward_item(idx, valid_response_length, sequences_str, data_source, reward_model_data):
# Extract and compile C++ code from model response
ground_truth = json.loads(reward_model_data)["ground_truth"]
# Select appropriate scoring function based on data source
if data_source == "code_contests":
compute_score = code_contests.compute_score
# Execute code against test cases and calculate pass ratio
score = compute_score(solution_str=sequences_str, ground_truth=ground_truth)
return idx, score, valid_response_length, sequences_str, data_source并行测试用例执行系统通过采样测试用例并使用进程池来优化评估效率:
def run_test_cases_parallel(
bin_file: str, test_inputs: List[str], test_outputs: List[str], prob_name: str, execution_timeout: float,
max_test_cases: int = 100, max_workers: int = 100) -> Tuple[int, int]:
# Sample test cases if too many available
if len(test_inputs) > max_test_cases:
random_indices = np.random.choice(len(test_inputs), size=max_test_cases, replace=False)
test_inputs = test_inputs[random_indices]
test_outputs = test_outputs[random_indices]
# Execute test cases in parallel using ProcessPoolExecutor
with ProcessPoolExecutor(max_workers=min(max_workers, len(test_inputs))) as executor:
results = list(executor.map(_process_test_case, args_list))
total_matches = sum(results)
return total_matches, len(test_inputs)此实现通过分离关注点,实现了高效的分布式训练:main_ppo.py 编排器管理 Ray 工作负载协调,而奖励系统通过跨 SageMaker 集群的并行编译和执行,提供了可扩展的代码评估能力。
以下是用于训练竞技编程编码模型的奖励计算的伪代码。奖励函数是强化学习中最重要的部分,因为它定义了模型被鼓励实现什么以及应该避免什么。此实现使用分层惩罚系统,首先检查基本的代码执行问题,对不可执行的代码分配严厉的惩罚(-1),对编译失败分配中等的惩罚(-0.5)。提取的代码解决方案会受到严格的时间限制执行——超出问题指定时间限制的代码将获得零奖励,从而为现实的竞技编程条件提供了便利。对于成功执行的 C++ 解决方案,其奖励是根据通过的私有测试用例的比例计算的线性函数,鼓励模型尽可能多地解决私有测试用例,同时避免对公开可见的测试用例产生过拟合。这种设计优先考虑代码的正确性和执行有效性,私有测试性能作为学习最佳编码解决方案的唯一信号。
def compute_reward(code_output, ground_truth):
# Handle execution failures (same for both stages)
if not is_executable(code_output):
return -1
if compilation_failed(code_output):
return -0.5
if exceeds_time_limit(code_output):
return 0
# Primary reward signal: correctness on hidden test cases # Run code against private test cases
passed_private, total_private = run_private_tests(code_output, ground_truth, max_test_cases=1000)
return passed_private / total_private有关完整的 Python 代码,请参阅 scripts/verl/utils/reward_score/code_contests.py。在生产环境中执行生成的代码需要适当的沙箱。在此受控演示设置中,我们执行代码作为快速示例,以评估其正确性并分配奖励。
带有 SageMaker 训练作业的 Ray 工作负载
要在 SageMaker 训练作业上使用 veRL 和 Ray 训练 CodeFu-7B,我们使用 SageMaker Python SDK 中的 ModelTrainer 类。首先,通过以下步骤设置分布式训练工作负载:
- 选择训练作业的实例类型和容器镜像:
instance_type = "ml.p4de.24xlarge"
instance_count = 2 account_id = sts.get_caller_identity()["Account"]
region = sagemaker_session.boto_session.region_name
repo_name = "codefu-pytorch"
tag = "latest"
image_uri = f"{account_id}.dkr.ecr.{region}.amazonaws.com/{repo_name}:{tag}"训练使用自定义 Docker 容器,其中包含 veRL、Ray 以及分布式 RL 训练所需的依赖项。有关完整的容器定义和构建说明,请参阅GitHub 仓库。
- 创建 ModelTrainer 以封装基于 Ray 的训练设置:
ModelTrainer 类通过其 SourceCode 配置提供灵活的执行选项,允许用户使用不同框架和启动器自定义其训练工作流程。指定 entry_script 用于直接 Python 脚本执行,或使用 command 参数用于自定义执行命令,从而实现与专门框架(如 Ray、Hugging Face Accelerate 或自定义分布式训练解决方案)的集成。
... args = [ "--entrypoint", "train.py", "--config", "/opt/ml/input/data/config/args.yaml",
] # Define the script to be run with Ray launcher source_code = SourceCode( source_dir="./scripts", requirements="requirements.txt", command=f"python launcher.py {' '.join(args)}",
) # Define the compute configuration compute_configs = Compute( instance_type=instance_type, instance_count=instance_count, keep_alive_period_in_seconds=1800,
) job_name = "train-codefu-verl-ray"
output_path = f"s3://{bucket_name}/{job_name}"
model_trainer = ModelTrainer(
training_image=image_uri,
source_code=source_code,
base_job_name=job_name,
compute=compute_configs,
stopping_condition=StoppingCondition(max_runtime_in_seconds=3600 * 24 * 5),
output_data_config=OutputDataConfig(s3_output_path=output_path),
checkpoint_config=CheckpointConfig(
s3_uri=output_path + "/checkpoint",
local_path="/opt/ml/checkpoints"
),
environment={
"RAY_PROMETHEUS_HOST": "<PROMETHEUS_HOST>",
"RAY_GRAFANA_HOST": "<GRAFANA_HOST>",
"RAY_PROMETHEUS_NAME": "prometheus",
"BASE_MODEL": "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B",
"RUN_NAME": "sagemaker-training-run",
...
},
role=get_execution_role(),
).with_remote_debug_config(RemoteDebugConfig(enable_remote_debug=True))launcher.py 脚本作为通用入口点,用于检测 SageMaker 环境(单节点或多节点,同构或异构集群),使用适当的头/工作节点协调来初始化 Ray 集群,并在 Ray 集群上下文中执行您的自定义训练脚本。launcher.py 的关键功能包括:
- Ray 集群设置:自动检测集群环境,并使用适当的头节点选择来初始化 Ray。
- 节点协调:管理 SageMaker 实例上头节点和工作节点之间的通信。
- 脚本执行:在 Ray 集群上下文中执行指定的
--entrypoint脚本(train.py)。 - Prometheus 和 Grafana 连接:配置 Ray 以导出指标,并建立与由
RAY_PROMETHEUS_HOST和RAY_GRAFANA_HOST指定的外部 Prometheus 和 Grafana 服务器的连接,以实现全面的集群监控。有关附加信息,请参阅Ray on SageMaker training jobs – Observability with Prometheus and Grafana。
有关 Ray 集群设置与 SageMaker 训练作业的完整实现,请参阅launcher.py。
train.py 脚本作为实际的训练编排器,它执行以下操作:
- 从提供的 YAML 文件加载 veRL 配置
- 使用适当的 tokenizer 和模型初始化来设置分布式训练环境
- 使用必要的参数构建并执行 veRL 训练命令
- 处理 Ray 工作负载和 NVIDIA Collective Communications Library (NCCL) 通信的环境变量配置
- 管理从数据加载到模型检查点的完整训练生命周期
有关入口点脚本的完整实现,请参阅train.py。
- 通过从 S3 存储桶路径创建
InputData对象来设置 ModelTrainer 的输入通道:
... train_input = InputData(
channel_name="train",
data_source=S3DataSource(
s3_data_type="S3Prefix",
s3_uri=train_dataset_s3_path,
s3_data_distribution_type="FullyReplicated",
),
)
config_input = InputData(
channel_name="config",
data_source... [内容被截断]🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区