



📢 转载信息
原文链接:https://www.ifanr.com/1641130?utm_source=rss&utm_medium=rss&utm_campaign=
原文作者:ifanr
在当今的AI时代,用户体验常常呈现出两极分化:简单问题秒回但敷衍了事,复杂问题需要深度思考,却导致响应延迟和Token(计算资源)的急剧消耗。对于企业而言,高Token消耗直接意味着成本的飙升,这已成为整个AI行业面临的严峻痛点。
AI时代的“不可能三角”:效果、延迟与成本的博弈
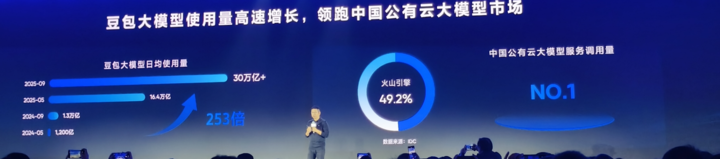
随着AI应用的激增,Token消耗量正以惊人的速度增长。例如,豆包大模型的日均Token调用量已突破30万亿+。这使得企业陷入两难境地:要么牺牲效果采用轻量模型,要么咬牙烧钱使用顶级模型以保证质量。
10月16日,在武汉举办的FORCE LINK AI创新巡展上,火山引擎带来了四款新品,意图彻底解决这一难题,让用户不必再做选择。
根据IDC报告,火山引擎已占据中国公有云大模型服务市场近一半份额,稳居市场第一,意味着每两家使用云端大模型的企业中,就有一家在使用火山引擎的服务。

尽管深度思考模式能将效果提升31%,但由于其带来的高延迟和高Token消耗,实际应用占比仅为18%。企业渴望深度能力,但难以承受其成本。
豆包大模型1.6:首创“思考变速器”
为解决这一核心痛点,火山引擎发布了全面升级的**豆包大模型1.6**,它原生支持 **Minimal、Low、Medium、High** 四档思考长度调节,成为国内首个支持“分档调节思考长度”的模型。
这相当于为AI装上了一个“变速器”:对于简单查询,使用Minimal档位可以高效节省Token;对于复杂推理,则切换至High档位以确保最佳效果。企业可以根据实际场景灵活调配效果、时延和成本,大幅提升思考效率。
以低思考档位为例,相比升级前的单一模式,总输出Token量直接削减了77.5%,思考时间暴降84.6%,而效果保持不变。Token成本的精确控制,使得使用越多,节省越多。
豆包1.6 Lite:效果提升,成本腰斩
同时,火山引擎还推出了更轻量、推理速度更快的**豆包大模型1.6 lite**。在效果上,它超越了豆包1.5 Pro,在企业级场景测评中提升了14%。
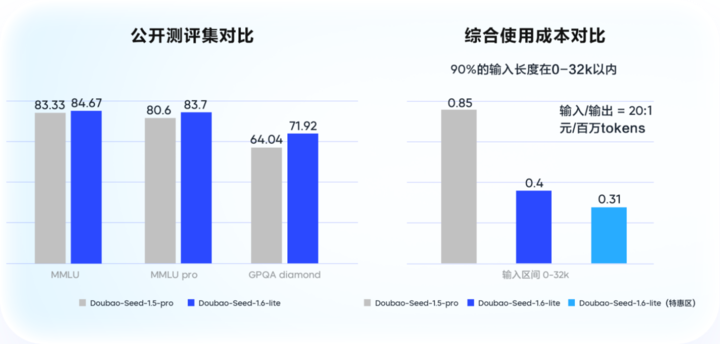
在成本层面,对于0-32k的输入区间,其综合使用成本较豆包1.5 Pro狂降53.3%。这种“单位Token价值密度”的提升,确保了每一分钱都花在刀刃上。
语音模型突破:复杂公式也能精准朗读
此外,发布会上还推出了**豆包语音合成模型2.0**和**声音复刻模型2.0**。语音正成为AI应用的核心交互方式,而这次的升级重点在于解决了一个长期存在的技术难题——**准确朗读复杂公式和数学符号**。
市场上同类模型的朗读准确率普遍低于50%,而新模型经过针对性优化后,在中小学全学科复杂公式朗读中的准确率直接飙升至90%。

这得益于基于豆包大语言模型的新语音合成架构,使声音具备了深度语义理解能力和上下文推理功能。AI不再是无脑转码,而是先“理解”内容再进行“精准情感表达”。用户可以通过自然语言(如“来点温柔的感觉”或“读得激动点”)实时控制语速、情绪和风格,可控性大大增强。
在现场演示中,结合豆包图像创作模型Seedream 4.0,成功创作并演绎了以青头潜鸭为主题的儿童绘本。
自首发以来,豆包语音模型家族已覆盖语音合成、识别、复刻、翻译等7大领域,接入超4.6亿台智能终端。

智能模型路由(SMR):AI自主选择最优方案
火山引擎高管谭待指出了全球AI大模型三大趋势:深度思考与多模态融合、视频/图像/语音模型生产化、企业级Agent成熟。但如何为具体任务选择最具性价比的模型,是企业的灵魂拷问。
为此,火山引擎发布了**智能模型路由(Smart Model Router)**,这是国内首个针对模型智能选择的解决方案,现已在火山方舟上线,支持“平衡模式”、“效果优先模式”和“成本优先模式”。

智能模型路由的本质是让AI自行判断“这个任务值得消耗多少Token”。例如,客服查询只需轻量模型,而医疗诊断则必须调用最强模型。该路由目前支持豆包大模型、DeepSeek、Qwen、Kimi等主流模型。
实测数据显示,在使用DeepSeek时,在效果优先模式下,智能路由后模型效果提升14%;而在成本优先模式下,在达到相似效果的前提下,综合成本最高可下降超70%。
模型选择被AI接管后,形成了一个良性循环:更强能力解锁新场景 → 消耗增长倒逼智能路由优化 → 成本下降释放更多需求弹性 → 需求增长进一步催生模型迭代。这让人联想到爱迪生时代的“千瓦时”,如今,Token正成为AI时代的“千瓦时”,推动着生产力的蓬勃发展。
最终目标是提供卓越的用户体验:告别在“快”与“好”之间的纠结。分档思考让简单问题秒回精准,复杂问题深度高效;智能路由无需用户操心模型选择;自然语言即可精准控制语音模型。这些技术迭代的最终目的,是让用户用得起、更要用得好,这或许才是人工智能应有的形态。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区