



📢 转载信息
原文链接:http://bair.berkeley.edu/blog/2024/03/21/xt/
原文作者:BAIR
作为计算机视觉研究人员,我们相信每一像素都能讲述一个故事。然而,在处理大型图像时,该领域似乎遇到了“写作瓶颈”。大尺寸图像已不再罕见——我们口袋里和环绕地球的卫星上的摄像头拍摄的照片如此之大、细节如此之丰富,以至于在处理时将我们当前最先进的模型和硬件推向了极限。通常情况下,我们面临的内存使用量随着图像尺寸的增大而呈二次方增长。
今天,我们在处理大型图像时面临两个次优的选择:降采样或裁剪。这两种方法都会导致图像中信息和上下文的大量丢失。我们重新审视了这些方法,并引入了 $x$T,这是一个新的框架,旨在利用当代GPU对大型图像进行端到端建模,同时有效地聚合全局上下文与局部细节。

$x$T 框架的架构。
为什么要费心处理大图像?
为什么要费心处理大图像呢?想象一下您正坐在电视前,观看您最喜欢的足球队比赛。球场上布满了球员,而动作只发生在屏幕的一小部分区域。但是,如果您只能看到球当前所在区域的微小范围,您会满意吗?或者,如果以低分辨率观看比赛,您会满意吗?每一个像素都在讲述一个故事,无论它们相距多远。这在所有领域都是如此,从您的电视屏幕到病理学家查看一张千兆像素的玻片以诊断微小的癌症区域。这些图像是信息的宝库。如果我们因为工具无法处理地图而无法充分探索其财富,那还有什么意义呢?

如果你知道发生了什么,体育运动才有趣。
这正是目前的困境所在。图像越大,我们就越需要同时“缩小”以查看全貌,并“放大”以查看细枝末节,这使得同时掌握“森林和树木”变得很困难。大多数现有方法都强迫我们在两者之间做出选择:要么失去对森林的视野,要么错过对树木的细节,而这两种选择都不理想。
$x$T 如何尝试解决这个问题
想象一下尝试解一个巨大的拼图。你不会试图一次性解决整个拼图,因为那会让人不知所措,而是从较小的部分开始,仔细查看每个部分,然后弄清楚它们如何融入更大的画面。这基本上就是我们用 $x$T 处理大型图像所做的事情。
$x$T 将这些巨大的图像分层地切成更小、更容易处理的片段。但这不仅仅是让事情变小。它是关于理解每个片段本身,然后,使用一些巧妙的技术,弄清楚这些片段如何在更大的尺度上连接起来。这就像与图像的每个部分进行“对话”,了解它的故事,然后与其他部分分享这些故事,以获得完整的叙述。
嵌套分词(Nested Tokenization)
$x$T 的核心在于嵌套分词的概念。简单来说,在计算机视觉领域,分词就像将图像切成模型可以消化和分析的片段(即“令牌”)。然而,$x$T 更进一步,在过程中引入了层次结构——因此被称为“嵌套”。
想象一下,您的任务是分析一张详细的城市地图。您不会试图一次性看完全图,而是将其分解为各个区,然后是这些区内的街区,最后是这些街区内的街道。这种分层分解使得管理和理解地图的细节变得更容易,同时又能跟踪所有内容在更大图景中的位置。这就是嵌套分词的精髓——我们将图像分割成不同的区域,根据视觉骨干网络(我们称之为区域编码器)期望的输入大小,每个区域可以进一步细分为子区域,然后才被切块以供该区域编码器处理。这种嵌套方法使我们能够在局部提取不同尺度的特征。
协调区域编码器和上下文编码器
一旦图像被整齐地划分为令牌后,$x$T 采用两种类型的编码器来理解这些片段:区域编码器和上下文编码器。每种编码器在拼凑出图像的完整故事中都扮演着独特的角色。
区域编码器是一个独立运作的“局部专家”,它将独立的区域转换为详细的表示。但是,由于每个区域都是隔离处理的,图像之间不会共享任何信息。区域编码器可以是任何最先进的视觉骨干网络。在我们的实验中,我们使用了分层视觉Transformer,如Swin和Hiera,以及像ConvNeXt这样的CNN!
现在,请看上下文编码器,这位“全局专家”。它的工作是将来自区域编码器的详细表示缝合在一起,确保一个令牌的见解能够被考虑到其他令牌的上下文中。上下文编码器通常是一个长序列模型。我们实验了Transformer-XL(以及我们称之为Hyper的变体)和Mamba,尽管您也可以使用Longformer以及该领域其他最新的进展。尽管这些长序列模型通常是为语言设计的,但我们证明了可以将它们有效地用于视觉任务。
$x$T 的魔力在于这些组件——嵌套分词、区域编码器和上下文编码器——是如何组合在一起的。通过首先将图像分解成可管理的片段,然后在孤立和结合的情况下系统地分析这些片段,$x$T 设法在在当代GPU上实现超大图像的端到端拟合的同时,保持了原始图像细节的保真度,并整合了长距离上下文和总体上下文。
结果
我们评估了 $x$T 在具有挑战性的基准任务上的表现,这些任务涵盖了公认的计算机视觉基线和严格的大图像任务。具体来说,我们实验了用于细粒度物种分类的iNaturalist 2018、用于上下文依赖分割的xView3-SAR以及用于检测的MS-COCO。
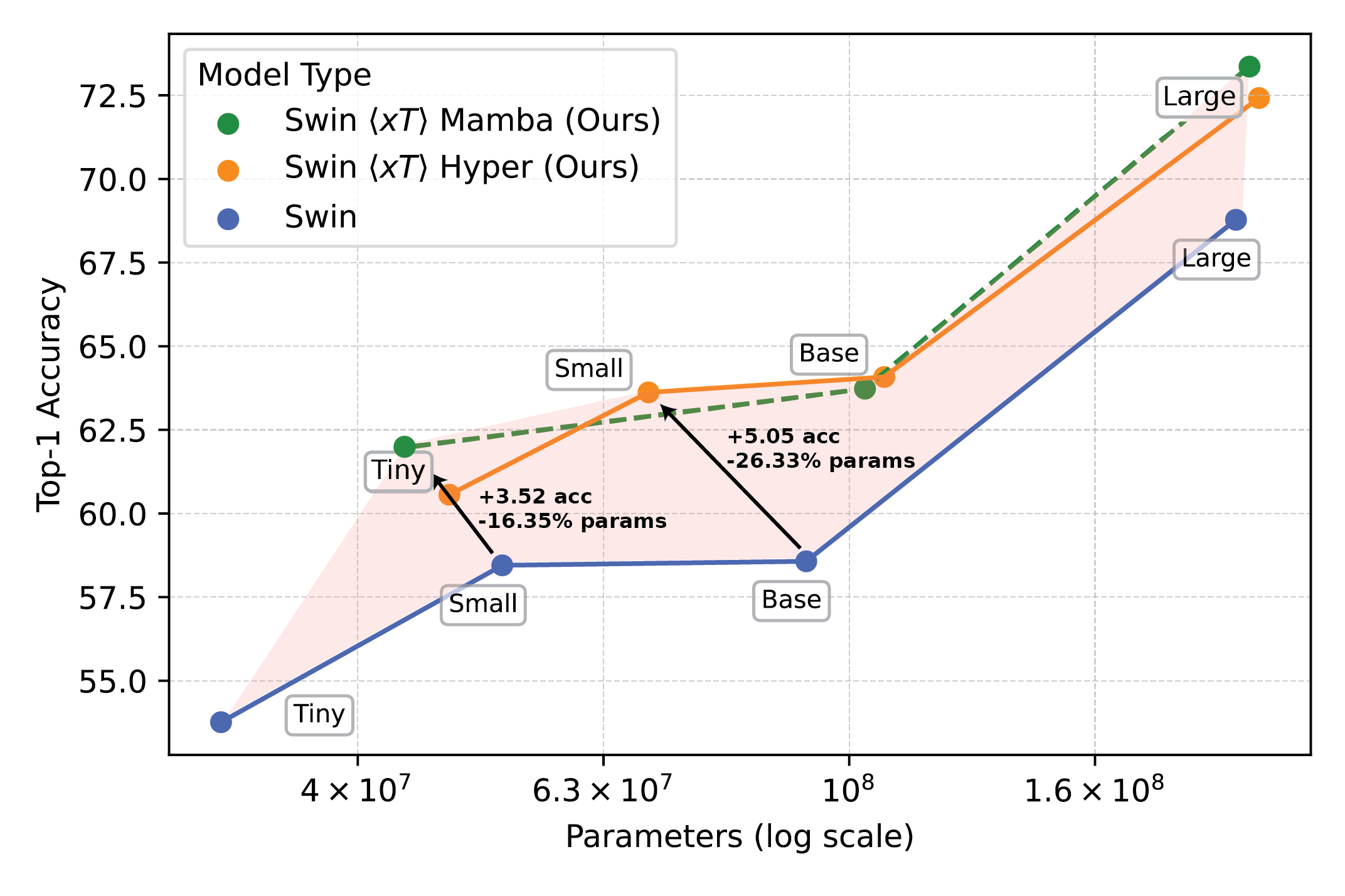
使用 $x$T 的强大视觉模型在细粒度物种分类等下游任务上开创了新前沿。
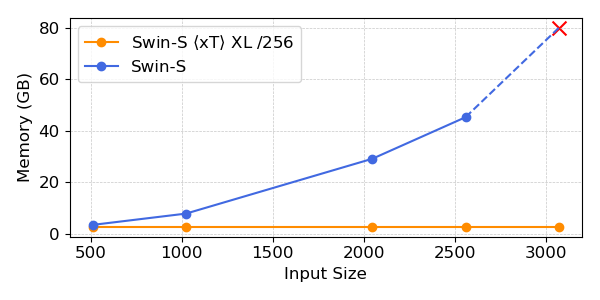
我们的实验表明,与最先进的基线相比,$x$T 能够在更少的参数下,以更少的每区域内存,在所有下游任务上实现更高的准确性*。我们能够在 40GB 的 A100 GPU 上对大至 29,000 x 25,000 像素的图像进行建模,而可比较的基线在仅 2,800 x 2,800 像素时就已耗尽内存。
使用 $x$T 的强大视觉模型在细粒度物种分类等下游任务上开创了新前沿。
*取决于您对上下文模型的选择,例如 Transformer-XL。
为什么这比你想象的更重要
这种方法不仅仅很酷;它是必需的。对于跟踪气候变化或诊断疾病的科学家来说,它是一个改变游戏规则的技术。它意味着创建能够理解完整故事的模型,而不仅仅是零碎的片段。例如,在环境监测中,能够同时看到广阔区域的宏观变化和特定区域的细节,有助于理解气候影响的全貌。在医疗保健中,这可能意味着早期发现疾病与否的区别。
我们并非声称一举解决了世界上所有的问题。我们希望 $x$T 为我们开启了可能的大门。我们正在迈入一个新时代,在这个时代,我们不必在视觉的清晰度或广度上妥协。$x$T 是我们朝着能够轻松处理大规模图像的复杂性迈出的重要一步。
还有很多工作要做。研究将会发展,希望我们处理更大、更复杂图像的能力也会随之发展。事实上,我们正在研究 $x$T 的后续版本,这将进一步拓展这一前沿领域。
总结
如需了解这项工作的完整介绍,请查看 arXiv 上的论文。项目页面 http://ai-climate.berkeley.edu/xt-website/ 包含我们已发布的代码和权重链接。如果您觉得这项工作有用,请引用如下:
@article{xTLargeImageModeling, title={xT: Nested Tokenization for Larger Context in Large Images}, author={Gupta, Ritwik and Li, Shufan and Zhu, Tyler and Malik, Jitendra and Darrell, Trevor and Mangalam, Karttikeya}, journal={arXiv preprint arXiv:2403.01915}, year={2024} } 🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区